Présentation
Netcracker est une entreprise internationale, un développeur de solutions informatiques intégrées, y compris des services pour le placement et le soutien de l'équipement client, ainsi que l'hébergement du système informatique créé pour les opérateurs de télécommunications.
Il s'agit principalement de décisions liées à l'organisation des activités opérationnelles et commerciales des opérateurs télécoms. Plus de détails peuvent être trouvés
ici .
La disponibilité continue de la solution en cours de développement est très importante. Si l'opérateur de télécommunications cesse de fonctionner pendant au moins une heure, cela entraînera d'importantes pertes financières et de réputation pour l'opérateur et le fournisseur de logiciels. Par conséquent, l'une des principales exigences de la solution est le paramètre de
disponibilité , dont la valeur varie de 99,995% à 99,95% selon le type de solution.
La solution elle-même est un ensemble complexe de systèmes informatiques monolithiques centraux, comprenant des équipements de télécommunications et des logiciels de services complexes situés dans un cloud public, ainsi que de nombreux microservices intégrés à un noyau central.
Par conséquent, il est très important pour l'équipe d'assistance de surveiller tous les systèmes matériels et logiciels intégrés dans une seule solution. Le plus souvent, l'entreprise utilise la surveillance traditionnelle. Ce processus est bien établi: nous pouvons construire un tel système de surveillance à partir de zéro et nous savons comment organiser correctement les processus de réponse aux incidents. Cependant, cette approche se heurte à plusieurs difficultés d'un projet à l'autre.
- Que surveiller
Quelle mesure est actuellement importante et laquelle le sera à l'avenir? Il n'y a pas de réponse définitive ici, alors nous essayons de tout surveiller . Difficulté numéro un - le nombre de métriques. Il y a des problèmes de performances, les tableaux de bord opérationnels ressemblent de plus en plus à un panneau de commande de vaisseau spatial.
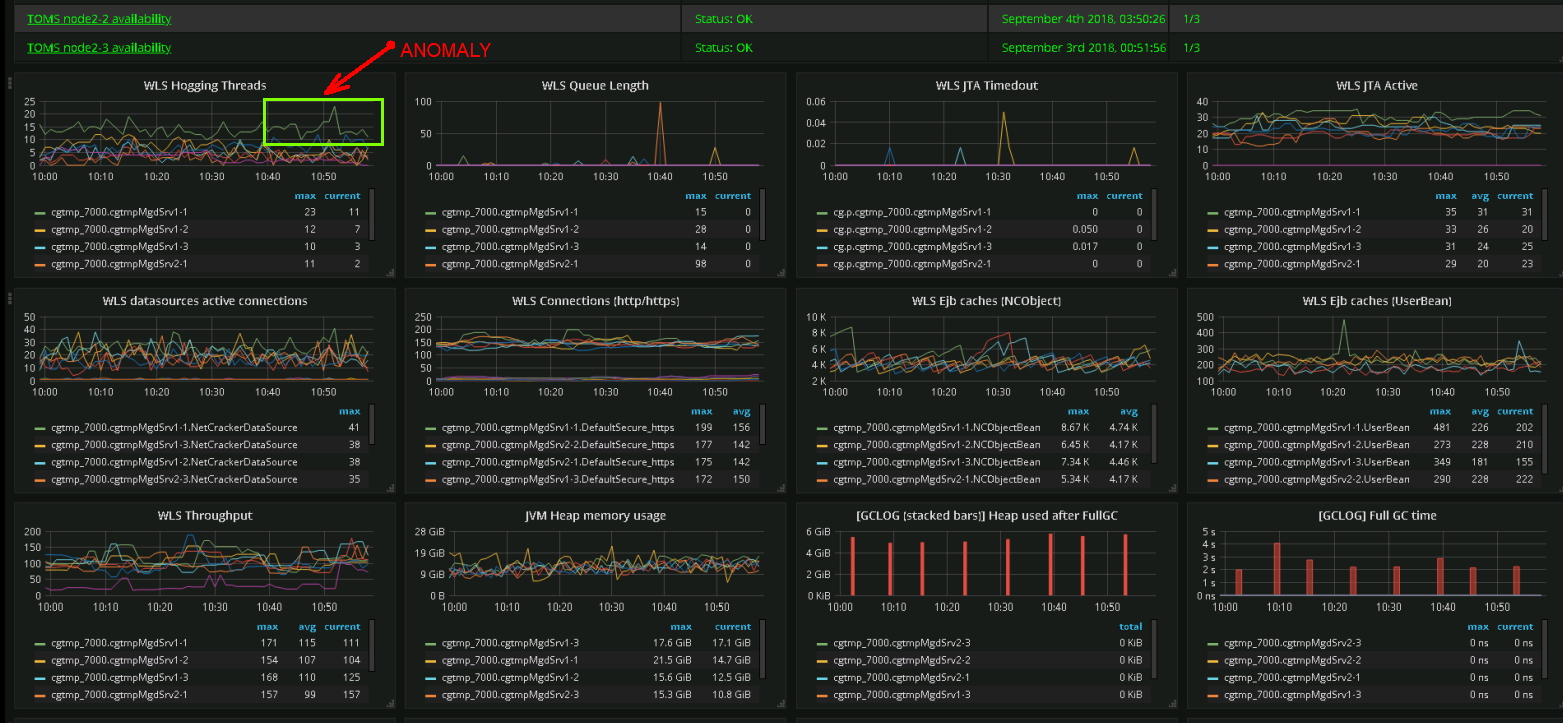
Capture d'écran d'un vrai tableau de bord. Les ingénieurs de l'équipe de support peuvent identifier les anomalies du comportement du système en fonction de leur représentation graphique
- Alerte / seuillage
Malgré le fait que nous ayons de l'expérience dans l'exploitation de nombreux systèmes de grande taille, leur surveillance reste une tâche difficile en raison des spécificités des équipements utilisés et des versions logicielles des différents fournisseurs. L'expérience et les règles prédéfinies ne peuvent souvent pas être complètement transférées d'une solution à une autre. Il existe un certain ensemble de base, dont l'amélioration se fait de manière itérative, comme l'analyse des incidents résultant du fonctionnement de la solution.
La difficulté numéro deux est le manque de règles claires pour la personnalisation. - Interprétation du résultat
Lorsqu'un incident se produit, il est très important de le localiser rapidement. Cela dépend en grande partie de l'expérience de l'équipe de support, car sous l'arbre des messages secondaires sur les échecs, vous ne pouvez pas remarquer la cause profonde des problèmes et perdre du temps sur une réponse rapide. Et c'est la complexité trois.
Grâce à des processus correctement organisés, l'équipe est en mesure de faire face aux difficultés ci-dessus, cependant, la demande moderne de changement de décision réactif - lorsque le temps pour passer d'une idée à la mise en œuvre est mesurée en jours - complique considérablement la tâche. Une formation continue en équipe est requise. Des changements constants conduisent au fait que certaines règles et relations de cause à effet perdent leur sens et, par conséquent, l'incident, qui n'est pas éliminé à temps, peut se transformer en accident.
Comment l'apprentissage automatique nous aide
La prédiction des dysfonctionnements des systèmes matériels et logiciels devient une fonction très populaire de réponse préventive ou réactive aux incidents.
NEC Corporation, notre société mère, investit massivement dans le développement de l'idée de surveillance. Un résultat de cet investissement est la technologie brevetée
System Invariant Analysis (SIAT) .
SIAT est une technologie d'apprentissage automatique qui, parmi l'ensemble de données de capteurs ou de mesures présentées sous forme de séries chronologiques, trouve à l'aide d'algorithmes ML des relations fonctionnelles constantes et construit un modèle général - un graphique de ces relations. Les détails peuvent être trouvés
ici .
Figure illustrant la relation trouvée entre les capteurs d'objets physiques
L'idée, développée à l'origine pour les systèmes informatiques, ne s'est pour l'instant répandue que pour la surveillance de complexes physiques, tels que des usines, des usines, des centrales nucléaires.
Lockheed Martin , par exemple,
implémente ces technologies dans sa division spatiale. En 2018,
Netcracker, en collaboration avec
NEC, a repensé cette idée et a créé un produit adapté à la surveillance des systèmes informatiques comme outil d'analyse supplémentaire.
Important : ce n'est qu'un ajout au système de surveillance, mais pas son remplacement.
Applications SIAT pour les systèmes informatiques
Quelle est la différence entre un complexe physique et un logiciel? Dans les systèmes logiciels, les métriques sont utilisées, dans les physiques - les capteurs. La métrique est beaucoup plus utilisée, car un capteur physique vaut toujours l'argent et il n'est placé que là où cela a du sens. Les métriques logicielles, lorsqu'elles sont correctement organisées, ne coûtent rien. De plus, les métriques de données des systèmes d'information sont beaucoup plus difficiles à interpoler correctement à l'état du système. Il est plus facile pour une personne de comprendre les capteurs liés au monde physique, tandis que les valeurs spécifiques des métriques logicielles n'ont de sens que par rapport à un matériel, une configuration et une charge spécifiques.
L'interconnexion
fonctionnelle dans le modèle suggère également que si nous remplaçons la version matérielle ou logicielle (par exemple, les correctifs du système d'exploitation) et que toutes les opérations deviennent également plus rapides ou plus lentes, cela n'entraînera pas de faux messages sur les accidents du fait que nous n'avons pas changé
seuils . Si les métriques ont cessé d'être corrélées entre elles, cela signifie un écart par rapport à la norme dans le comportement du système. De plus, la technologie
SIAT permet de détecter même de petits écarts de comportement en temps réel, y compris les soi-disant
pannes silencieuses - des dysfonctionnements qui ne sont accompagnés d'aucun message d'erreur. Et si cet écart n'est qu'un signe avant-coureur d'un échec plus important, nous avons le temps de réagir correctement.
Nous avons vérifié cette déclaration en simulant un petit serveur Web Apache sous charge, en émulant des erreurs internes à l'aide du mécanisme d'
injection de faute sur Linux .
Le résultat est présenté sous la forme d'un
score d'anomalie numérique métrique, dont la valeur est associée à ce modèle. Plus la valeur est élevée, plus l'échec est grave: plus les mesures se comportent de manière anormale. La valeur limite est 100% des métriques sont anormales, le système ne fonctionne pas. De plus, le résultat indique les mesures dont le comportement à l'heure actuelle peut être considéré comme anormal. Cela accélère considérablement l'analyse de la cause et l'identification du sous-système qui échoue actuellement dans le modèle de comportement actuel.
En général,
SIAT vous permet de réagir même à des changements de comportement mineurs qui ne sont presque pas détectables à l'aide d'une surveillance traditionnelle ou de référence.
Figure illustrant une perturbation de la relation entre les capteurs
Un avantage supplémentaire de
SIAT est l'algorithme de construction d'un modèle de comportement qui ne nécessite aucune indication de sens commercial des métriques. L'algorithme sélectionne automatiquement toutes les métriques dont le comportement est interconnecté et cette relation est constante. Les métriques isolées restantes sont soit des sous-systèmes ponctuels qui n'affectent pas la solution informatique, soit des métriques qui ne sont pas importantes pour l'état de la solution pour le moment. Si cela a du sens, la surveillance de ces métriques est mise en œuvre dans le cadre de l'approche traditionnelle basée sur l'
alerte de seuil .
Il est très important que la création d'un modèle nécessite des données liées au fonctionnement normal du système, ce qui est
beaucoup plus simple que lors de l'approche avec la formation aux accidents.
Le modèle est encore affiné et reconstruit si le comportement a changé ou si nous lui avons ajouté de nouvelles métriques.
Étant donné que le comportement normal du système est une caractéristique variable, en fonction de l'heure de la journée et d'autres conditions commerciales, pour une réponse plus précise, il est logique de créer plusieurs modèles qui décrivent le comportement du système dans certaines conditions.
À quoi ressemble le processus
Le processus d'organisation du suivi est le suivant.
- Nous commençons la surveillance traditionnelle. Le bon choix du nom des métriques est très important. Le fait est que le résultat inclut les noms des métriques dont le comportement est anormal, ce qui signifie que plus la métrique décrit avec précision le lieu et la signification, plus vite le résultat sera obtenu. Par exemple, une métrique nommée ncp. erp_netcracker _com.apps.erp. clust4.wls .jdbc. LMSDataSource . ActiveConnectionsCurrentCount indique que dans le système ERP Netcracker , une métrique nommée ActiveConnectionsCurrentCount échoue sur le quatrième cluster Weblogic pour le LMSDataSource . Pour l'expert, ces informations sont plus que suffisantes pour localiser avec précision l'anomalie.
- Ensuite, nous nous intégrons au système de stockage des données de métriques - dans notre cas, ClickHouse - et obtenons les données pour toutes les métriques pendant une certaine période du comportement normal de la solution: les meilleurs modèles sont construits sur la base de résultats de surveillance sur 30 jours. Pour obtenir des modèles plus précis, nous utilisons des données métriques par minute sans aucune agrégation.
- Nous construisons un modèle utilisant SIAT basé sur les données d'un système de surveillance. Dans le cadre du modèle construit, nous filtrons les relations fonctionnelles en fonction du degré de similitude. En bref, il s'agit du degré de déviation du comportement par rapport à une donnée, exprimé en pourcentage.
- Nous vérifions le modèle sur les données des jours précédents, où des pannes ont été détectées à l'aide de l'équipe de surveillance et d'assistance traditionnelle.
- Nous commençons la surveillance en ligne: toutes les 10 minutes, les données de toutes les métriques sont transférées vers le ou les modèles. Nous obtenons le résultat - score d'anomalie, et si le résultat n'est pas nul, nous obtenons en outre une liste de mesures dont le comportement est actuellement anormal.
- Le résultat est envoyé au système de surveillance général, où il fait partie des tableaux de bord communs et d'autres outils de surveillance traditionnels.
Test
Aucune implémentation ne se produit sans vérification. En tant que systèmes testés, nous avons choisi notre propre
ERP (monolith,
Weblogic ,
Oracle , 4500 métriques) et le système de routage de l'ensemble de notre système de surveillance, 7 millions de métriques par minute, -
carbone-c-relais (1200 métriques).
Des vidages de toutes les mesures ont été utilisés comme entrée, et les jours où les échecs ont été enregistrés ont également été indiqués. Pour évaluer le résultat, nous avons introduit les concepts suivants:
- Le nombre d'erreurs du deuxième type correspond à un système de surveillance traditionnel ou à une équipe d'assistance qui a constaté une défaillance, mais pas SIAT .
- Le nombre de détections correctes - lorsque la surveillance traditionnelle et SIAT ont détecté un problème.
- Le nombre d'erreurs du premier type - lorsque le SIAT a détecté une déviation de comportement, mais l'équipe de support ne l'a pas trouvée.
Nous n'avons trouvé aucune erreur du second type pour les deux systèmes testés. Le nombre de détections correctes - 85% du nombre total de pannes détectées par
SIAT , et en cas de panne d'équipement - une matrice RAID sur la base de données a
échoué -
SIAT a détecté une dégradation du comportement avec une indication exacte des mesures associées à la base de données, sept heures avant d'atteindre définir la valeur seuil dans le système de surveillance.
Les 15% restants des échecs
SIAT indiqués sont des erreurs du premier type - un comportement anormal que l'équipe d'assistance ne peut expliquer. Cela est probablement dû au fait que lors de la construction du modèle, ces mesures ont été automatiquement incluses qui ont une signification fonctionnelle, mais n'ont pas d'effet notable sur le comportement général du système. Après plusieurs faux positifs, un expert informatique peut marquer ces métriques comme non importantes et les supprimer du modèle, après en avoir préalablement convenu avec la
PME .
Les résultats ont montré que ce produit automatise entièrement le processus de détection des pannes (y compris les pannes cachées), la localisation rapide de l'incident et l'évaluation de son ampleur.
Et ensuite
Maintenant, nous accumulons de l'expérience dans l'exploitation du produit pour différents types de systèmes matériels et logiciels afin d'analyser l'applicabilité de cette approche à divers systèmes: périphériques réseau, périphériques
IoT , microservices cloud, etc.
À l'heure actuelle, la tâche de reconstruire le modèle est le goulot d'étranglement. Cela nécessite une puissance de calcul importante, mais, heureusement, le recomptage peut être effectué sur une machine isolée, en exportant le résultat en tant que modèle fini. La surveillance en temps réel elle-même ne nécessite pas de ressources importantes et est effectuée en parallèle avec la surveillance traditionnelle sur le même équipement.
Conclusion
Pour résumer, je tiens à noter que l'utilisation d'une combinaison de techniques de surveillance traditionnelles et d'algorithmes d'apprentissage automatique vous permet de créer un modèle simple qui vous aide à répondre à temps, à trouver l'origine du problème et à maintenir le système en état de fonctionnement.
En plus de la technologie
SIAT prometteuse, nous analysons les possibilités d'utiliser une autre technologie
NEC -
Next Generation Log Analytics . La technologie permet l'utilisation d'algorithmes d'apprentissage automatique et l'utilisation de journaux système pour déterminer les anomalies liées à l'état interne du produit qui n'affectent pas la dégradation globale du système en termes de performances.
Quelles analyses utilisez-vous pour surveiller les systèmes informatiques?