
Les outils traditionnels dans le domaine de la science des données sont des langages tels que R et Python - la syntaxe détendue et un grand nombre de bibliothèques pour l'apprentissage automatique et le traitement des données vous permettent d'obtenir rapidement des solutions de travail. Cependant, il existe des situations où les limites de ces outils deviennent un obstacle important - tout d'abord, s'il est nécessaire d'atteindre des performances élevées en termes de vitesse de traitement et / ou de travailler avec de très grands ensembles de données. Dans ce cas, le spécialiste doit se tourner à contrecœur vers l'aide du "côté obscur" et connecter des outils dans les langages de programmation "industriels": Scala , Java et C ++ .
Mais ce côté est-il si sombre? Au fil des années de développement, les outils de la Data Science «industrielle» ont parcouru un long chemin et sont aujourd'hui très différents de leurs propres versions il y a 2-3 ans. Essayons d'utiliser l'exemple de la tâche SNA Hackathon 2019 pour comprendre dans quelle mesure l'écosystème Scala + Spark peut correspondre à Python Data Science.
Dans le cadre du SNA Hackathon 2019, les participants résolvent le problème de trier le fil d'actualité d'un utilisateur d'un réseau social dans l'une des trois «disciplines»: utiliser des données de textes, d'images ou de journaux de fonctionnalités. Dans cette publication, nous verrons comment dans Spark il est possible de résoudre un problème basé sur un journal de fonctionnalités en utilisant des outils classiques d'apprentissage automatique.
Pour résoudre le problème, nous suivrons le chemin standard suivi par tout spécialiste de l'analyse de données lors du développement d'un modèle:
- Nous effectuerons une analyse des données de recherche, construirons des graphiques.
- Nous analysons les propriétés statistiques des signes dans les données, examinons leurs différences entre les ensembles d'apprentissage et de test.
- Nous procéderons à une première sélection de fonctionnalités en fonction des propriétés statistiques.
- Nous calculons les corrélations entre les signes et la variable cible, ainsi que la corrélation croisée entre les signes.
- Nous formerons l'ensemble final des fonctionnalités, formerons le modèle et vérifierons sa qualité.
- Analysons la structure interne du modèle pour identifier les points de croissance.
Au cours de notre «voyage», nous nous familiariserons avec des outils tels que le cahier interactif Zeppelin , la bibliothèque d'apprentissage automatique Spark ML et son extension PravdaML , le package graphique GraphX , la bibliothèque de visualisation Vegas et, bien sûr, Apache Spark dans toute sa splendeur: ) Tous les résultats de code et d'expérience sont disponibles sur la plate-forme de cahier collaboratif Zepl .
Chargement des données
La particularité des données présentées au SNA Hackathon 2019 est qu'il est possible de les traiter directement en utilisant Python, mais c'est difficile: les données originales sont assez efficacement compressées grâce aux capacités du format de colonne Apache Parquet et lors de la lecture en mémoire «par le front», elles sont décompressées en plusieurs dizaines de gigaoctets. Lorsque vous travaillez avec Apache Spark, il n'est pas nécessaire de charger complètement les données en mémoire, l'architecture Spark est conçue pour traiter les données en morceaux, en les chargeant à partir du disque selon les besoins.
Par conséquent, la première étape - vérifier la distribution des données par jour - est facilement réalisée par des outils en boîte:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show(train.groupBy($"date").agg( functions.count($"instanceId_userId").as("count"), functions.countDistinct($"instanceId_userId").as("users"), functions.countDistinct($"instanceId_objectId").as("objects"), functions.countDistinct($"metadata_ownerId").as("owners")) .orderBy("date"))
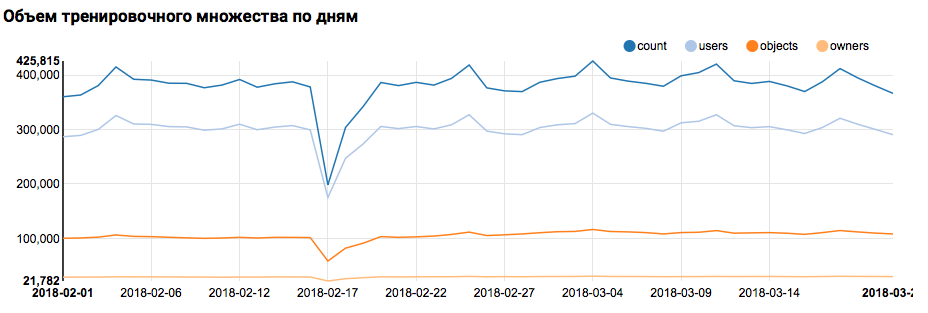
Ce que le graphique correspondant affichera dans Zeppelin:
Je dois dire que la syntaxe Scala est assez flexible, et le même code peut ressembler, par exemple, à ceci:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show( train groupBy $"date" agg( count($"instanceId_userId") as "count", countDistinct($"instanceId_userId") as "users", countDistinct($"instanceId_objectId") as "objects", countDistinct($"metadata_ownerId") as "owners") orderBy "date" )
Un avertissement important doit être fait ici: lorsque vous travaillez dans une grande équipe, où chacun aborde l'écriture du code Scala exclusivement du point de vue de son propre goût, la communication est beaucoup plus difficile. Il est donc préférable de développer un concept unifié de style de code.
Mais revenons à notre tâche. Une simple analyse de jour a montré la présence de points anormaux les 17 et 18 février; ces jours-ci, des données incomplètes ont probablement été recueillies et la distribution des caractères peut être biaisée. Cela devrait être pris en compte dans une analyse plus approfondie. De plus, il est frappant de constater que le nombre d'utilisateurs uniques est très proche du nombre d'objets, il est donc logique d'étudier la répartition des utilisateurs avec différents nombres d'objets:
z.show(filteredTrain .groupBy($"instanceId_userId").count .groupBy("count").agg(functions.log(functions.count("count")).as("withCount")) .orderBy($"withCount".desc) .limit(100) .orderBy($"count"))
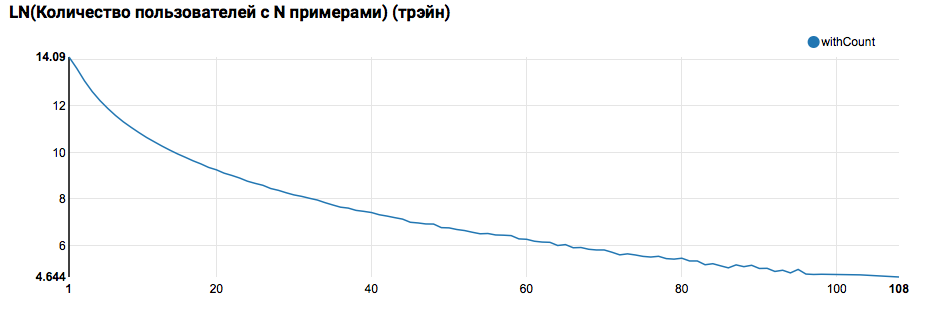
On s'attend à voir une distribution proche de l'exponentielle, avec une très longue queue. Dans de telles tâches, en règle générale, il est possible d'obtenir une amélioration de la qualité du travail en segmentant les modèles pour les utilisateurs avec différents niveaux d'activité. Afin de vérifier si cela vaut la peine, comparez la distribution du nombre d'objets par utilisateur dans l'ensemble de test:
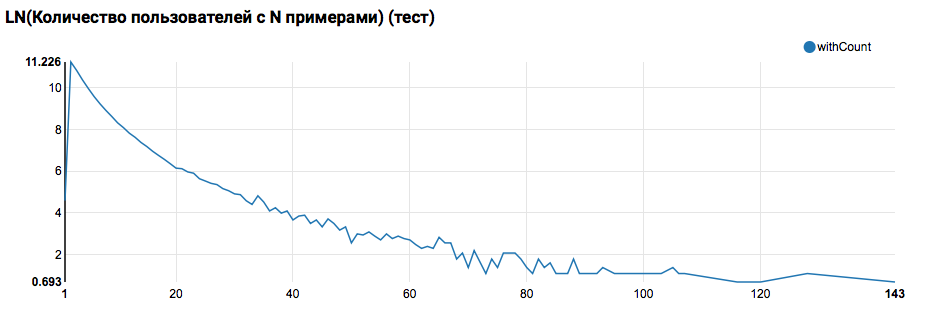
La comparaison avec le test montre que les utilisateurs du test ont au moins deux objets dans les journaux (puisque le problème de classement est résolu sur le hackathon, c'est une condition nécessaire pour évaluer la qualité). À l'avenir, je recommande de regarder de plus près les utilisateurs dans l'ensemble de formation, pour lesquels nous déclarons la fonction définie par l'utilisateur avec un filtre:
Une remarque importante doit également être faite ici: c'est du point de vue de la définition de l'UDF que l'utilisation de Spark sous Scala / Java et sous Python est très différente. Bien que le code PySpark utilise les fonctionnalités de base, tout fonctionne presque aussi rapidement, mais lorsque des fonctions remplacées apparaissent, les performances de PySpark se dégradent d'un ordre de grandeur.
Le premier pipeline ML
Dans l'étape suivante, nous essaierons de calculer les statistiques de base sur les actions et les attributs. Mais pour cela, nous avons besoin des capacités de SparkML, nous allons donc d'abord examiner son architecture générale:

SparkML est construit sur la base des concepts suivants:
- Transformer - prend un ensemble de données en entrée et retourne un ensemble modifié (transformation). En règle générale, il est utilisé pour implémenter des algorithmes de pré et post-traitement, d'extraction de fonctionnalités et peut également représenter les modèles ML résultants.
- Estimateur - prend un ensemble de données en entrée et retourne Transformer (fit). Naturellement, Estimator peut représenter l'algorithme ML.
- Pipeline est un cas particulier d'Estimator, composé d'une chaîne de transformateurs et d'estimateurs. Lorsque la méthode est appelée, fit passe par la chaîne, et s'il voit un transformateur, il l'applique aux données, et s'il voit un estimateur, il entraîne le transformateur avec lui, l'applique aux données et va plus loin.
- PipelineModel - le résultat de Pipeline contient également une chaîne à l'intérieur, mais composée exclusivement de transformateurs. En conséquence, PipelineModel lui-même est également un transformateur.
Une telle approche de la formation d'algorithmes ML permet d'obtenir une structure modulaire claire et une bonne reproductibilité - les modèles et les pipelines peuvent être enregistrés.
Pour commencer, nous allons construire un pipeline simple avec lequel nous calculons les statistiques de la répartition des actions (champ de rétroaction) des utilisateurs dans l'ensemble de formation:
val feedbackAggregator = new Pipeline().setStages(Array(
Dans ce pipeline, la fonctionnalité de PravdaML est activement utilisée - bibliothèques avec des blocs utiles étendus pour SparkML, à savoir:
- MultinominalExtractor est utilisé pour coder un caractère de type "tableau de chaînes" en un vecteur selon le principe de l'un chaud. Il s'agit du seul estimateur du pipeline (pour créer un codage, vous devez collecter des lignes uniques à partir de l'ensemble de données).
- VectorStatCollector est utilisé pour calculer des statistiques vectorielles.
- VectorExplode est utilisé pour convertir le résultat dans un format pratique pour la visualisation.
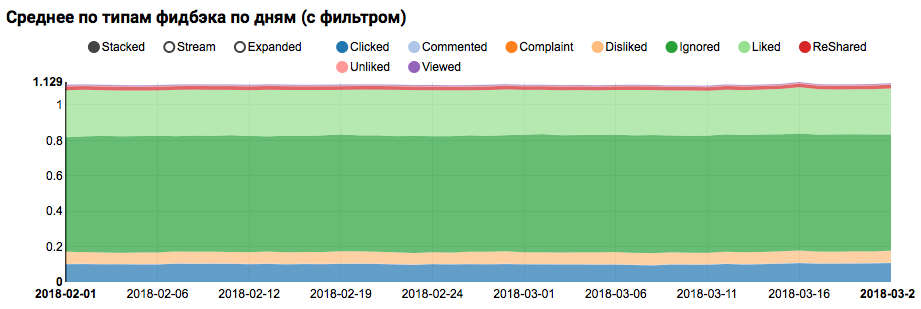
Le résultat du travail sera un graphique montrant que les classes de l'ensemble de données ne sont pas équilibrées, cependant, le déséquilibre pour la classe Aimée cible n'est pas extrême:

L'analyse d'une distribution similaire parmi les utilisateurs similaire à ceux testés (ayant à la fois "positif" et "négatif" dans les journaux) montre qu'elle est biaisée vers la classe positive:
Analyse statistique des signes
À l'étape suivante, nous effectuerons une analyse détaillée des propriétés statistiques des attributs. Cette fois, nous avons besoin d'un convoyeur plus grand:
val statsAggregator = new Pipeline().setStages(Array( new NullToDefaultReplacer(),
Puisque maintenant nous devons travailler non pas avec un champ séparé, mais avec tous les attributs à la fois, nous utiliserons deux autres utilitaires PravdaML utiles:
- NullToDefaultReplacer vous permet de remplacer les éléments manquants dans les données par leurs valeurs par défaut (0 pour les nombres, false pour les variables logiques, etc.). Si vous ne faites pas cette conversion, les valeurs NaN apparaîtront dans les vecteurs résultants, ce qui est fatal pour de nombreux algorithmes (bien que, par exemple, XGBoost puisse survivre à cela). Une alternative au remplacement par des zéros peut être le remplacement par des moyennes, ceci est implémenté dans NaNToMeanReplacerEstimator.
- AutoAssembler est un utilitaire très puissant qui analyse la disposition du tableau et sélectionne pour chaque colonne un schéma de vectorisation qui correspond au type de colonne.
En utilisant le pipeline résultant, nous calculons les statistiques pour trois ensembles (formation, formation avec filtre utilisateur et test) et enregistrons dans des fichiers séparés:
Après avoir reçu trois ensembles de données avec des statistiques d'attributs, nous analysons les choses suivantes:
- Avons-nous des signes pour lesquels il y a de grandes émissions.
- Ces signes doivent être limités ou les enregistrements aberrants doivent être filtrés. - Avons-nous des signes avec un biais important de la moyenne par rapport à la médiane.
- Un tel changement se produit souvent en présence d'une distribution d'énergie, il est logique de logarithmer ces signes. - Y a-t-il un changement dans les répartitions moyennes entre les ensembles de formation et de test.
- Comment bien rempli notre matrice de fonctionnalités.
Pour clarifier ces aspects, une telle demande nous aidera à:
def compareWithTest(data: DataFrame) : DataFrame = { data.where("date = 'All'") .select( $"features",
À ce stade, la question de la visualisation est urgente: il est difficile d'afficher immédiatement tous les aspects à l'aide des outils Zeppelin standard, et les blocs-notes avec un grand nombre de graphiques commencent à ralentir sensiblement en raison du DOM gonflé. La bibliothèque Vegas - DSL sur Scala pour la construction de spécifications vega-lite peut résoudre ce problème. Vegas offre non seulement des capacités de visualisation plus riches (comparables à matplotlib), mais les dessine également sur Canvas sans gonfler le DOM :).
La spécification du graphique qui nous intéresse ressemblera à ceci:
vegas.Vegas(width = 1024, height = 648)
Le tableau ci-dessous devrait se lire comme suit:
- L'axe des X montre le déplacement des centres de distribution entre les ensembles de test et d'apprentissage (plus près de 0, plus le signe est stable).
- Le pourcentage d'éléments non nuls est tracé le long de l'axe Y (plus il y a, plus il y a de données pour le plus grand nombre de points par attribut).
- La taille montre le déplacement de la moyenne par rapport à la médiane (plus le point est grand, plus la distribution de la loi de puissance est probable).
- La couleur indique les émissions (le plus rouge, le plus d'émissions).
- Eh bien, le formulaire se distingue par un mode de comparaison: avec un filtre utilisateur dans l'ensemble de formation ou sans filtre.
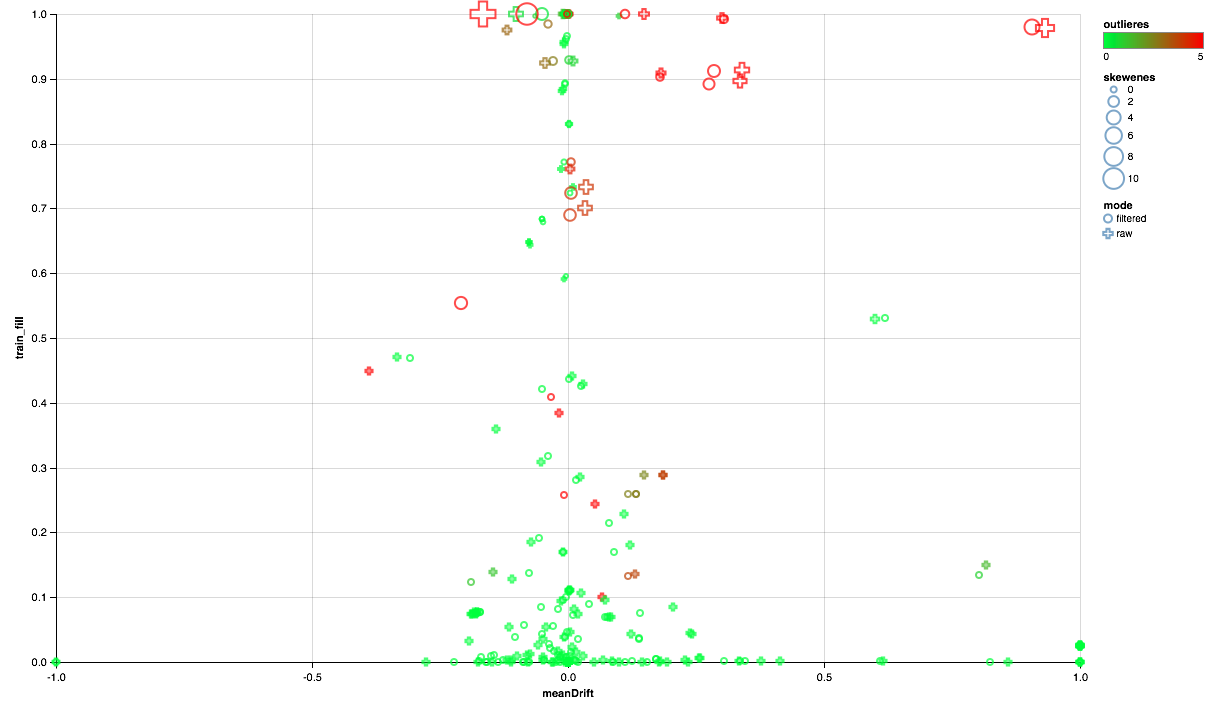
Nous pouvons donc tirer les conclusions suivantes:
- Certains panneaux nécessitent un filtre d'émission - nous limiterons les valeurs maximales pour le 90e centile.
- Certains signes montrent une distribution proche de l'exponentielle - nous prendrons le logarithme.
- Certaines fonctionnalités ne sont pas présentées dans le test - nous les exclurons de la formation.
Analyse de corrélation
Après avoir eu une idée générale de la façon dont les attributs sont distribués et de leur relation entre les ensembles d'apprentissage et de test, essayons d'analyser les corrélations. Pour ce faire, configurez l'extracteur de fonctionnalités en fonction des observations précédentes:
Parmi les nouvelles machines de ce pipeline, l'utilitaire SQLTransformer attire l'attention, ce qui permet des transformations SQL arbitraires de la table d'entrée.
Lors de l'analyse des corrélations, il est important de filtrer le bruit créé par la corrélation naturelle des caractéristiques uniques. Pour ce faire, je voudrais comprendre quels éléments du vecteur correspondent à quelles colonnes sources. Cette tâche dans Spark est effectuée à l'aide de métadonnées de colonne (stockées avec des données) et de groupes d'attributs. Le bloc de code suivant est utilisé pour filtrer les paires de noms d'attribut provenant de la même colonne de type String:
val attributes = AttributeGroup.fromStructField(raw.schema("features")).attributes.get val originMap = filteredTrain .schema.filter(_.dataType == StringType) .flatMap(x => attributes.map(_.name.get).filter(_.startsWith(x.name + "_")).map(_ -> x.name)) .toMap
Avoir sous la main un ensemble de données avec une colonne vectorielle, calculer les corrélations croisées à l'aide de Spark est assez simple, mais le résultat est une matrice, pour le déploiement de laquelle vous devrez jouer un peu dans un ensemble de paires:
val pearsonCorrelation =
Et, bien sûr, la visualisation: nous aurons encore besoin de l'aide de Vegas pour dessiner une carte thermique:
vegas.Vegas("Pearson correlation heatmap") .withDataFrame(pearsonCorrelation .withColumn("isPositive", $"corr" > 0) .withColumn("abs_corr", functions.abs($"corr")) .where("feature1 < feature2 AND abs_corr > 0.05") .orderBy("feature1", "feature2")) .encodeX("feature1", Nom) .encodeY("feature2", Nom) .encodeColor("abs_corr", Quant, scale=Scale(rangeNominals=List("#FFFFFF", "#FF0000"))) .encodeShape("isPositive", Nom) .mark(vegas.Point) .show
Le résultat est préférable de regarder dans Zepl-e . Pour une compréhension générale:
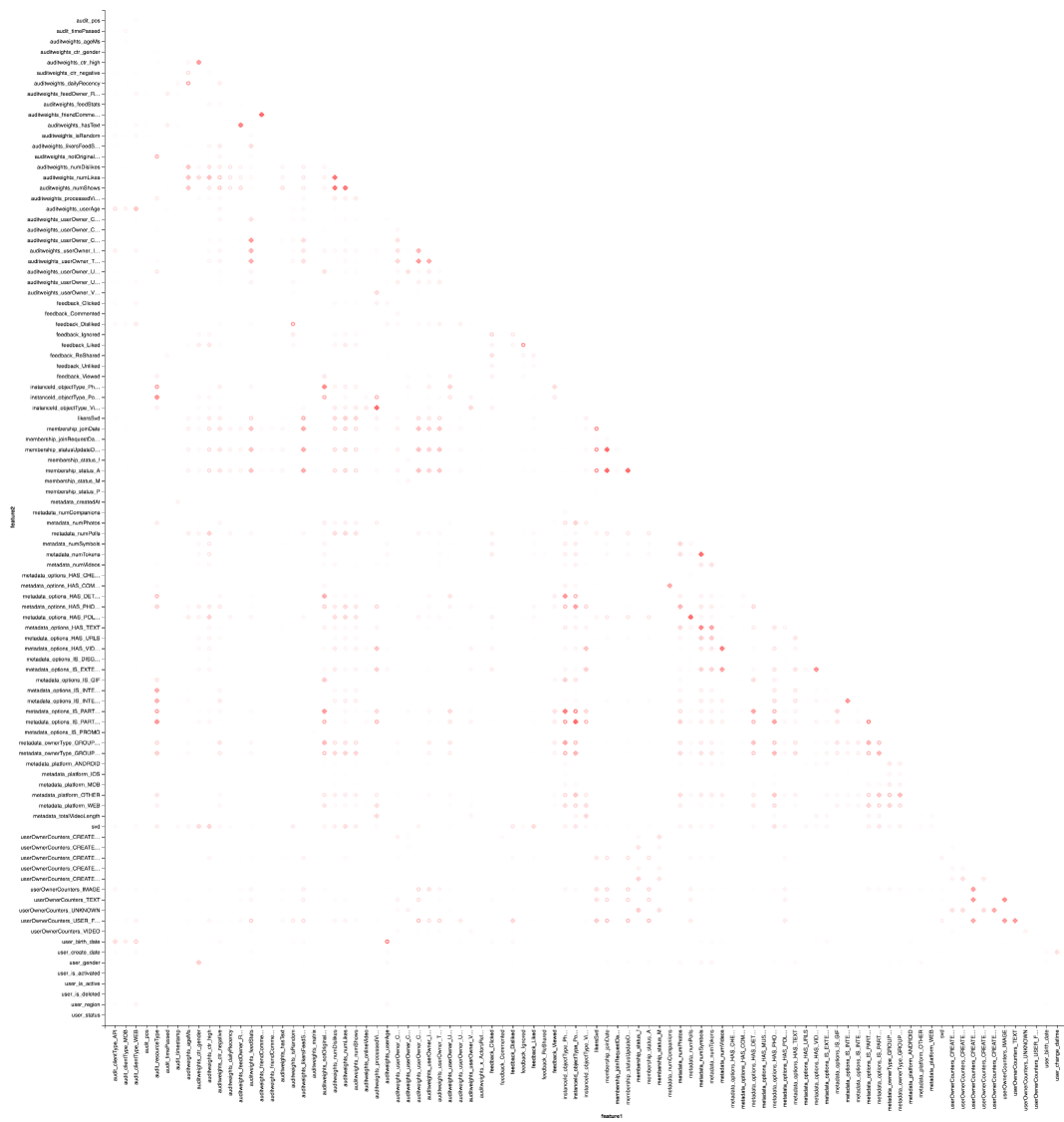
La carte thermique montre que certaines corrélations sont clairement présentes. Essayons de sélectionner les blocs des fonctionnalités les plus fortement corrélées, pour cela nous utilisons la bibliothèque GraphX : nous transformons la matrice de corrélation en graphique, filtrons les bords par poids, après quoi nous trouvons les composants connectés et ne laissons que des composants non dégénérés (à partir de plusieurs éléments). Une telle procédure est essentiellement similaire à l'application de l'algorithme DBSCAN et se présente comme suit:
Le résultat est présenté sous forme de tableau:
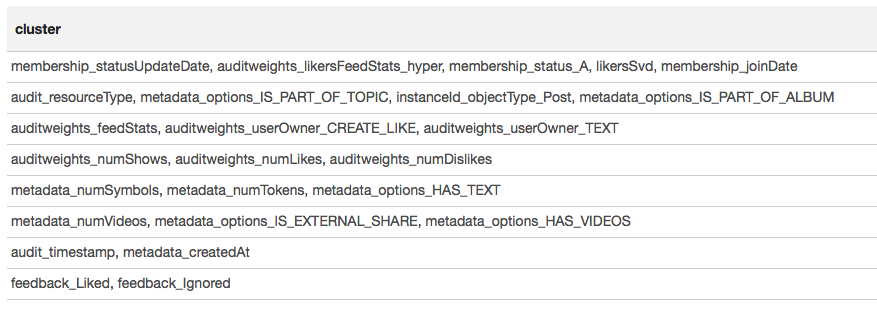
Sur la base des résultats du clustering, nous pouvons conclure que les groupes les plus corrélés se sont formés autour des signes associés à l'appartenance des utilisateurs au groupe (membership_status_A), ainsi qu'autour du type d'objet (instanceId_objectType). Pour la meilleure modélisation de l'interaction des signes, il est judicieux d'appliquer la segmentation du modèle - pour former différents modèles pour différents types d'objets, séparément pour les groupes dans lesquels l'utilisateur est et n'est pas.
Apprentissage automatique
Nous abordons la chose la plus intéressante - l'apprentissage automatique. Le pipeline pour la formation du modèle le plus simple (régression logistique) à l'aide des extensions SparkML et PravdaML est le suivant:
new Pipeline().setStages(Array( new SQLTransformer().setStatement( """SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127)))
Ici, nous voyons non seulement de nombreux éléments familiers, mais aussi plusieurs nouveaux:
- LogisticRegressionLBFSG est un estimateur à entraînement distribué de régression logistique.
- Afin d'obtenir des performances maximales à partir d'algorithmes ML distribués. les données doivent être réparties de manière optimale sur les partitions. L'utilitaire UnwrappedStage.repartition vous y aidera, en ajoutant une opération de répartition au pipeline de telle sorte qu'elle ne soit utilisée qu'au stade de la formation (après tout, lors de la création de prévisions, elle n'est plus nécessaire).
- Pour que le modèle linéaire puisse donner un bon résultat. les données doivent être mises à l'échelle, dont l'utilitaire Scaler.scale est responsable. Cependant, la présence de deux transformations linéaires consécutives (mise à l'échelle et multiplication par les poids de régression) entraîne des dépenses inutiles, et il est souhaitable de réduire ces opérations. Lorsque vous utilisez PravdaML, la sortie sera un modèle propre avec une transformation :).
- Eh bien, bien sûr, pour de tels modèles, vous avez besoin d'un membre gratuit, que nous ajoutons en utilisant l'opération Interceptor.intercept.
Le pipeline résultant, appliqué à toutes les données, donne AUC par utilisateur 0,68889 (le code de validation est disponible sur Zepl ). Il reste maintenant à appliquer toutes nos recherches: filtrer les données, transformer les entités et les modèles de segment. Le pipeline final ressemblera à ceci:
new Pipeline().setStages(Array( new SQLTransformer().setStatement(s"SELECT instanceId_userId, instanceId_objectId, ${expressions.mkString(", ")} FROM __THIS__"), new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label, concat(IF(membership_status = 'A', 'OwnGroup_', 'NonUser_'), instanceId_objectType) AS type FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label", "type","instanceId_objectType") .setOutputCol("features"), CombinedModel.perType( Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127))), numThreads = 6) ))
PravdaML — CombinedModel.perType. , numThreads = 6. .
, , per-user AUC 0.7004. ? , " " XGBoost :
new Pipeline().setStages(Array( new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), new XGBoostRegressor() .setNumRounds(100) .setMaxDepth(15) .setObjective("reg:logistic") .setNumWorkers(17) .setNthread(4) .setTrackerConf(600000L, "scala") ))
, — XGBoost Spark ! DLMC , PravdaML , ( ). XGboost " " 10 per-user AUC 0.6981.
, , , . SparkML , . PravdaML : Parquet Spark:
Parquet, PravdaML — TopKTransformer, .
Vegas ( Zepl ):
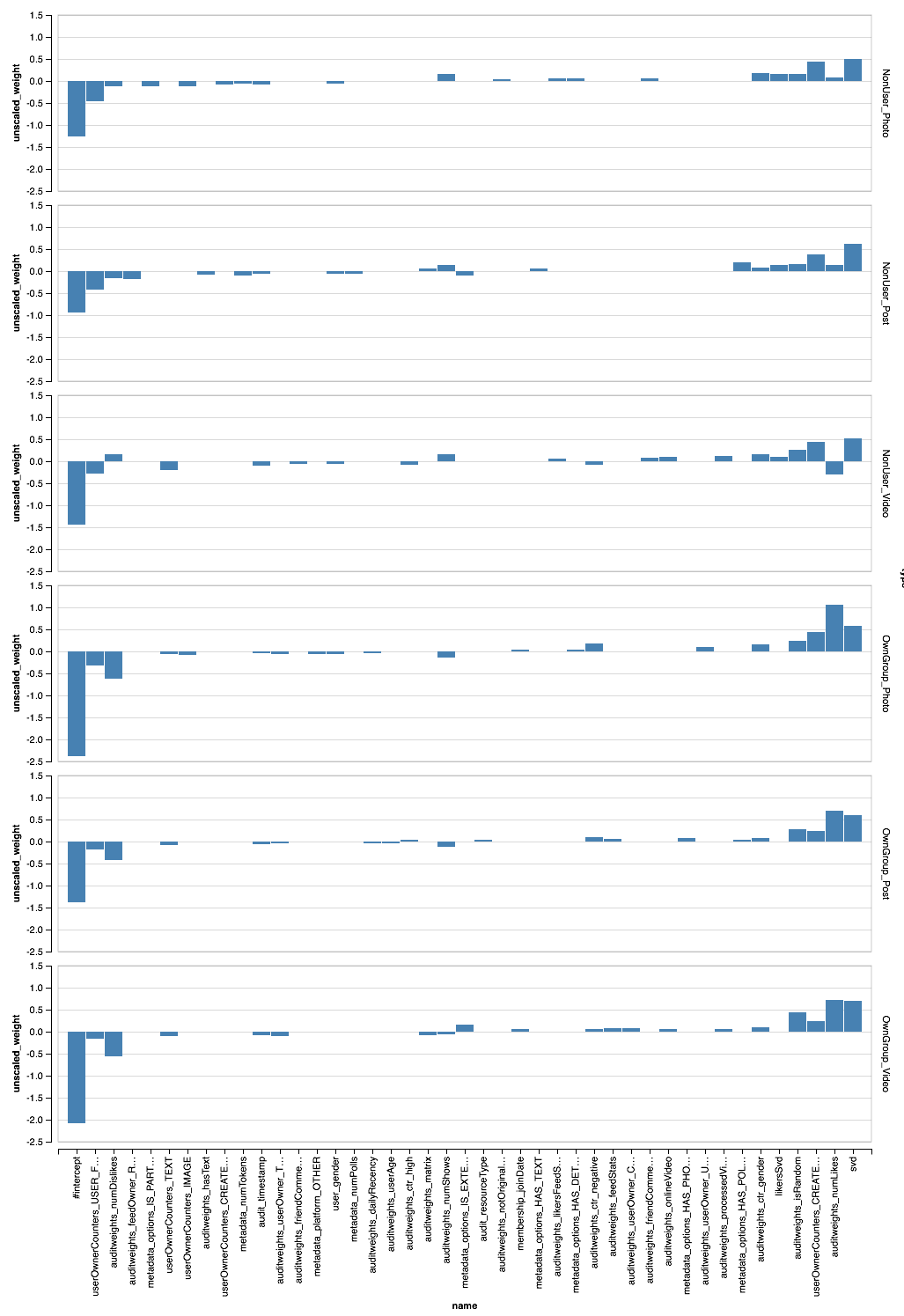
, - . XGBoost?
val significance = sqlContext.read.parquet( "sna2019/xgBoost15_100_raw/stages/*/featuresSignificance" vegas.Vegas() .withDataFrame(significance.na.drop.orderBy($"significance".desc).limit(40)) .encodeX("name", Nom, sortField = Sort("significance", AggOps.Mean)) .encodeY("significance", Quant) .mark(vegas.Bar) .show
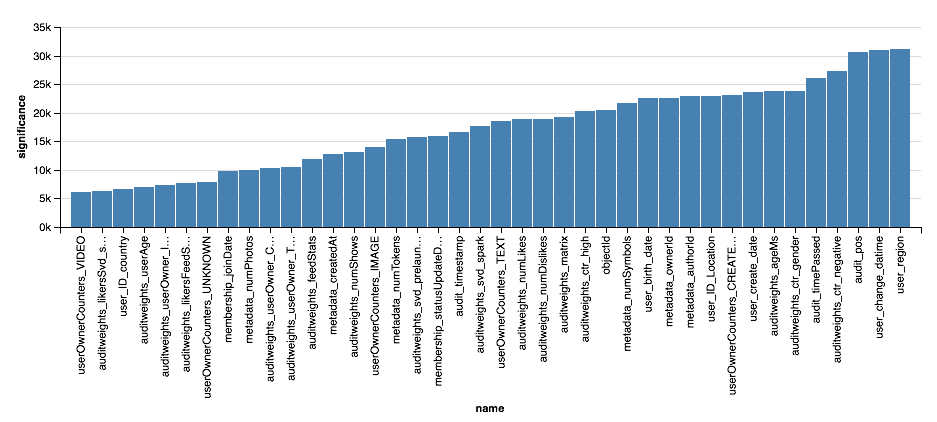
, , XGBoost, , . . , XGBoost , , .
Conclusions
, :). :
- , Scala Spark , , , , .
- Scala Spark Python: ETL ML, , , .
- , , , (, ) , , .
- , , . , , , -, .
, , , , -. , , " Scala " Newprolab.
, , — SNA Hackathon 2019 .