
Tout processus lié à la base de données rencontre tôt ou tard des problèmes de performances des requêtes vers cette base de données.
L'entrepôt de données de Rostelecom est construit sur Greenplum, la plupart des calculs (transformation) sont effectués par des requêtes SQL, qui démarrent (ou génèrent et démarrent) le mécanisme ETL. Le SGBD a ses propres nuances qui affectent considérablement les performances. Cet article est une tentative de mettre en évidence les aspects les plus critiques de travailler avec Greenplum en termes de performances et de partage d'expérience.
En bref sur GreenplumGreenplum - Serveur de base de données
MPP , dont le cœur est construit sur PostgreSql.
Représente plusieurs instances différentes du processus PostgreSql (instances). L'un d'eux est le point d'entrée pour le client et est appelé instance maître (maître), tous les autres sont appelés instances de segment (segment, instances indépendantes, chacune ayant sa propre donnée). Chaque serveur (hôte de segment) peut exécuter un à plusieurs services (segment). Ceci est fait afin de mieux utiliser les ressources du serveur et principalement les processeurs. L'assistant stocke les métadonnées, est responsable de la communication des données avec les clients et distribue également le travail entre les segments.
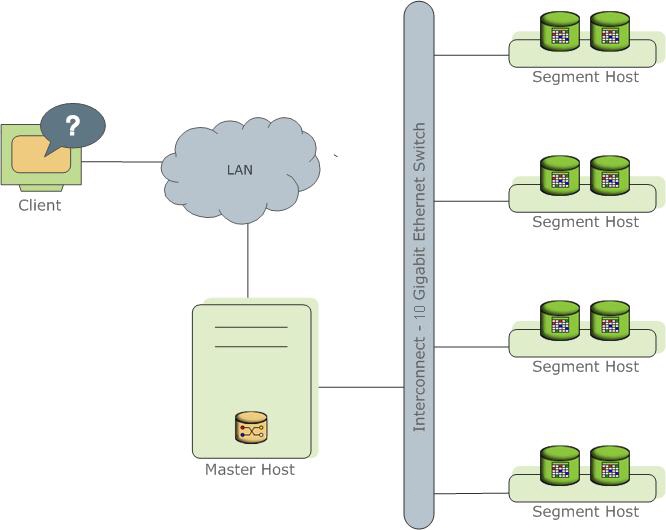
En savoir plus dans la
documentation officielle .
Plus loin dans l'article, il y aura de nombreuses références au plan de demande. Les informations pour Greenplum sont disponibles
ici .
Comment écrire de bonnes requêtes sur Greenplum (enfin, ou du moins pas vraiment triste)
Comme nous avons affaire à une base de données distribuée, il est important non seulement comment la requête SQL est écrite, mais aussi comment les données sont stockées.
1. Distribution
Les données sont stockées physiquement sur différents segments. Vous pouvez séparer les données par segments de façon aléatoire ou par la valeur de la fonction de hachage d'un champ ou d'un ensemble de champs.
Syntaxe (lors de la création d'une table):
DISTRIBUTED BY (some_field)
Ou alors:
DISTRIBUTED RANDOMLY
Le champ de distribution doit avoir une bonne sélectivité et ne pas avoir de valeurs nulles (ou avoir un minimum de telles valeurs), car les enregistrements avec ces champs seront distribués sur un segment, ce qui peut entraîner des distorsions de données.
Le type de champ est de préférence entier. Le champ est utilisé pour joindre des tables. La jointure par hachage est l'un des meilleurs moyens de joindre des tables (en termes d'exécution de requête), fonctionne mieux avec ce type de données.
Pour la distribution, il est conseillé de ne pas choisir plus de deux champs, et, bien sûr, un vaut mieux que deux. Les champs supplémentaires dans les clés de distribution, d'une part, nécessitent un temps supplémentaire pour le hachage, et d'autre part (dans la plupart des cas), ils nécessiteront un transfert de données entre les segments lors de l'exécution des jointures.
Vous pouvez utiliser une distribution aléatoire si vous ne pouvez pas sélectionner un ou deux champs appropriés, ainsi que pour les petites étiquettes. Mais nous devons tenir compte du fait qu'une telle distribution fonctionne mieux pour l'insertion de données de masse, et non pour un enregistrement. GreenPlum distribue les données selon l'algorithme
cyclique , et il démarre un nouveau cycle pour chaque opération d'insertion, à partir du premier segment, ce qui, avec de petites insertions fréquentes, conduit à des asymétries (asymétrie des données).
Avec un champ de distribution bien choisi, tous les calculs seront effectués sur le segment, sans envoyer de données à d'autres segments. De plus, pour une jointure optimale des tables (jointure), les mêmes valeurs doivent être situées sur le même segment.
Distribution en imagesBonne clé de distribution: Mauvaise clé de distribution:
Mauvaise clé de distribution: Distribution aléatoire:
Distribution aléatoire:
Le type de champs utilisé dans la jointure doit être le même dans toutes les tables.
Important: n'utilisez pas comme champs de distribution ceux qui sont utilisés pour filtrer les requêtes dans où, car dans ce cas, la charge pendant la requête ne sera pas également distribuée de manière uniforme.
2. Partitionnement
Le partitionnement vous permet de diviser de grandes tables, telles que des
faits , en morceaux logiquement séparés. Greenplum divise physiquement votre table en tables distinctes, chacune étant divisée en segments en fonction des paramètres de la p. 1.
Les tableaux doivent être divisés en sections de manière logique, à cet effet, sélectionnez le champ souvent utilisé dans le bloc where. En fait, ce sera la période. Ainsi, avec un accès approprié à la table dans les requêtes, vous ne travaillerez qu'avec une partie de la grande table entière.
En général, le partitionnement est un sujet assez bien connu, et je voulais souligner que vous ne devriez pas choisir le même champ pour le partitionnement et la distribution. Cela conduira au fait que la demande sera exécutée entièrement sur un segment.
Il est temps de passer, en fait, aux demandes. La demande sera exécutée sur des segments selon un
plan spécifique:
3. L'optimiseur
Greenplum possède deux optimiseurs, l'optimiseur hérité intégré et l'optimiseur tiers Orca: GPORCA - Orca - Pivotal Query Optimizer.
Activer GPORCA sur demande:
set optimizer = on;
En règle générale , l'optimiseur GPORCA est meilleur que le intégré. Il fonctionne plus adéquatement avec les sous-requêtes et
CTE (plus de détails
ici ).
A fait un appel à une grande table en CTE avec un filtrage maximal des données (n'oubliez pas l'élagage de partition) et une liste de champs explicitement spécifiée - cela fonctionne très bien.
Il modifie légèrement le plan de requête, par exemple, sinon affiche les partitions analysées:
Optimiseur standard: Orca:
Orca:
GPORCA permet également de mettre à jour les champs de partition / distribution. Bien qu'il existe des situations où l'optimiseur intégré fonctionne mieux. Un optimiseur tiers est très exigeant sur les statistiques, il est important de ne pas oublier d'
analyser .
Peu importe la qualité de l’optimiseur, une requête mal écrite n’étirera même pas Orca:
4. Manipulations avec des champs dans les conditions where block ou join
Il est important de se rappeler que la fonction appliquée au champ de filtre ou les conditions de la jointure sont appliquées à
chaque enregistrement.
Dans le cas du champ de partitionnement (par exemple, date_trunc au champ de partitionnement - date), même GPORCA ne peut pas fonctionner correctement dans ce cas, les
partitions de découpage ne fonctionneront pas.
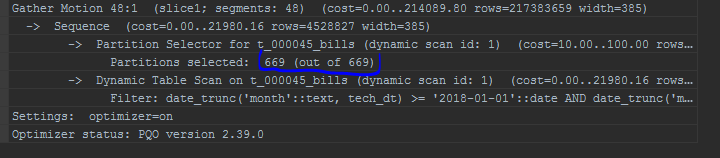
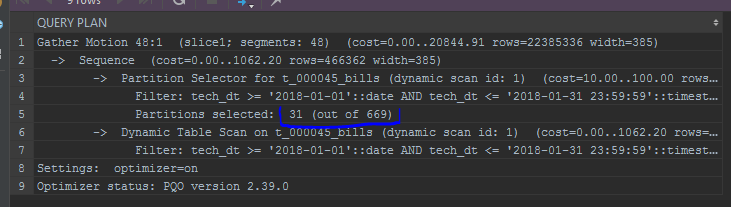 J'attire également l'attention sur l'affichage des partitions. L'optimiseur intégré affichera les partitions dans une liste:
J'attire également l'attention sur l'affichage des partitions. L'optimiseur intégré affichera les partitions dans une liste:
Appliquez soigneusement les fonctions aux constantes dans les mêmes filtres de partition. Un exemple est le même date_trunc:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))

GPORCA supportera complètement une telle feinte et fonctionnera correctement, l'optimiseur standard ne fonctionnera plus. Cependant, en faisant une conversion de type explicite, vous pouvez la faire fonctionner:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))::timestamp without time zone

Et si tout est mal fait?
5. Motions
Les mouvements sont un autre type d'opération que l'on peut observer dans
le plan de requête . Mouvements de données si marqués entre les segments:
- Rassembler le mouvement - sera affiché dans presque tous les plans, signifie combiner les résultats de l'exécution des requêtes de tous les segments en un seul flux (généralement vers le maître).
Deux tables, distribuées par une clé, qui est utilisée pour la jointure, effectuent toutes les opérations sur les segments, sans déplacer les données. Sinon, un mouvement de diffusion ou un mouvement de redistribution se produit: - Mouvement de diffusion - chaque segment envoie sa copie des données aux autres segments. Dans une situation idéale, la diffusion se produit uniquement pour les petites tables.
- Mouvement de redistribution - pour joindre de grandes tables réparties sur différentes clés, la redistribution est effectuée pour établir des connexions localement. Pour les grandes tables, cela peut être une opération assez coûteuse.
La diffusion et la redistribution sont des opérations assez désavantageuses. Ils sont exécutés à chaque exécution de la demande. Il est recommandé de les éviter. Après avoir vu de tels points dans le plan de requête, il convient de prêter attention aux clés de distribution. Des opérations distinctes et syndicales provoquent également des motions.
Cette liste n'est pas exhaustive et se fonde principalement sur l'expérience de l'auteur. Il n'a pas fonctionné de tout trouver tout de suite sur Internet en même temps. Ici, j'ai essayé d'identifier les facteurs les plus critiques affectant les performances de la demande, et de comprendre pourquoi et pourquoi cela se produit.
Cet article a été préparé par l'équipe de gestion des données de Rostelecom