Le premier article décrit le
moteur d'indexation de PostgreSQL , le second traite de
l'interface des méthodes d'accès , et maintenant nous sommes prêts à discuter de types spécifiques d'index. Commençons par l'index de hachage.
Hash
La structure
Théorie générale
De nombreux langages de programmation modernes incluent des tables de hachage comme type de données de base. À l'extérieur, une table de hachage ressemble à un tableau standard indexé avec n'importe quel type de données (par exemple, une chaîne) plutôt qu'avec un nombre entier. L'index de hachage dans PostgreSQL est structuré de la même manière. Comment ça marche?
En règle générale, les types de données ont de très grandes plages de valeurs autorisées: combien de chaînes différentes peut-on potentiellement envisager dans une colonne de type "texte"? Dans le même temps, combien de valeurs différentes sont réellement stockées dans une colonne de texte d'une table? Habituellement, pas beaucoup d'entre eux.
L'idée du hachage est d'associer un petit nombre (de 0 à
N -1,
N valeurs au total) à une valeur de n'importe quel type de données. Une telle association est appelée
fonction de hachage . Le nombre obtenu peut être utilisé comme index d'un tableau régulier où les références aux lignes de table (TID) seront stockées. Les éléments de ce tableau sont appelés
compartiments de table de hachage - un compartiment peut stocker plusieurs TID si la même valeur indexée apparaît dans différentes lignes.
Plus une fonction de hachage répartit uniformément les valeurs source par compartiments, mieux c'est. Mais même une bonne fonction de hachage produit parfois des résultats égaux pour différentes valeurs de source - c'est ce qu'on appelle
une collision . Ainsi, un compartiment peut stocker des TID correspondant à différentes clés, et par conséquent, les TID obtenus à partir de l'index doivent être revérifiés.
Par exemple: à quelle fonction de hachage pour les chaînes peut-on penser? Soit le nombre de compartiments à 256. Ensuite, par exemple pour un numéro de compartiment, nous pouvons prendre le code du premier caractère (en supposant un codage de caractères à un octet). Est-ce une bonne fonction de hachage? Évidemment, non: si toutes les chaînes commencent par le même caractère, toutes entreront dans un seul compartiment, donc l'uniformité est hors de question, toutes les valeurs devront être revérifiées, et le hachage n'aura aucun sens. Et si nous résumons les codes de tous les caractères modulo 256? Ce sera beaucoup mieux, mais loin d'être idéal. Si vous êtes intéressé par les fonctions internes d'une telle fonction de hachage dans PostgreSQL, examinez la définition de hash_any () dans
hashfunc.c .
Structure de l'index
Revenons à l'index de hachage. Pour une valeur d'un certain type de données (une clé d'index), notre tâche consiste à trouver rapidement le TID correspondant.
Lors de l'insertion dans l'index, calculons la fonction de hachage pour la clé. Les fonctions de hachage dans PostgreSQL renvoient toujours le type "entier", qui se situe dans une plage de 2
32 à 4 milliards de valeurs. Le nombre de compartiments est initialement égal à deux et augmente dynamiquement pour s'adapter à la taille des données. Le numéro de compartiment peut être calculé à partir du code de hachage à l'aide de l'arithmétique des bits. Et c'est le seau où nous mettrons notre TID.
Mais cela est insuffisant car les TID correspondant à différentes clés peuvent être placés dans le même compartiment. Que ferons-nous? Il est possible de stocker la valeur source de la clé dans un compartiment, en plus du TID, mais cela augmenterait considérablement la taille de l'index. Pour économiser de l'espace, au lieu d'une clé, le compartiment stocke le code de hachage de la clé.
Lors de la recherche dans l'index, nous calculons la fonction de hachage pour la clé et obtenons le numéro de compartiment. Il reste maintenant à parcourir le contenu du compartiment et à renvoyer uniquement les TID correspondants avec les codes de hachage appropriés. Cela se fait efficacement car les paires "code de hachage - TID" stockées sont ordonnées.
Cependant, deux clés différentes peuvent arriver non seulement pour entrer dans un seul compartiment, mais aussi pour avoir les mêmes codes de hachage à quatre octets - personne n'a éliminé la collision. Par conséquent, la méthode d'accès demande au moteur d'indexation général de vérifier chaque TID en revérifiant la condition dans la ligne du tableau (le moteur peut le faire avec la vérification de la visibilité).
Mappage des structures de données aux pages
Si nous regardons un index tel qu'il est vu par le gestionnaire de cache de tampon plutôt que du point de vue de la planification et de l'exécution des requêtes, il s'avère que toutes les informations et toutes les lignes d'index doivent être regroupées dans des pages. Ces pages d'index sont stockées dans le cache tampon et en sont supprimées exactement de la même manière que les pages de table.
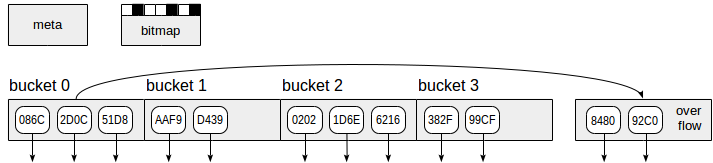
L'index de hachage, comme indiqué sur la figure, utilise quatre types de pages (rectangles gris):
- Meta page - numéro de page zéro, qui contient des informations sur ce qui se trouve à l'intérieur de l'index.
- Pages de compartiment - pages principales de l'index, qui stockent les données sous forme de paires "code de hachage - TID".
- Pages de débordement - structurées de la même manière que les pages de compartiment et utilisées lorsqu'une page est insuffisante pour un compartiment.
- Pages bitmap - qui gardent une trace des pages de débordement qui sont actuellement claires et peuvent être réutilisées pour d'autres compartiments.
Les flèches vers le bas commençant aux éléments de la page d'index représentent les TID, c'est-à-dire les références aux lignes de table.
Chaque fois que l'index augmente, PostgreSQL crée instantanément deux fois plus de compartiments (et donc de pages) que la dernière fois. Pour éviter l'allocation de ce nombre potentiellement important de pages à la fois, la version 10 a augmenté la taille plus facilement. Quant aux pages de débordement, elles sont allouées au fur et à mesure des besoins et sont suivies dans des pages bitmap, qui sont également allouées au fur et à mesure des besoins.
Notez que l'indice de hachage ne peut pas diminuer en taille. Si nous supprimons certaines des lignes indexées, les pages une fois allouées ne seront pas renvoyées au système d'exploitation, mais ne seront réutilisées pour de nouvelles données qu'après VACUUMING. La seule option pour diminuer la taille de l'index est de le reconstruire à partir de zéro à l'aide de la commande REINDEX ou VACUUM FULL.
Exemple
Voyons comment est créé l'index de hachage. Pour éviter de concevoir nos propres tables, nous utiliserons désormais
la base de
données de
démonstration du transport aérien, et cette fois-ci nous considérerons la table des vols.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN ---------------------------------------------------- Bitmap Heap Scan on flights Recheck Cond: (flight_no = 'PG0001'::bpchar) -> Bitmap Index Scan on flights_flight_no_idx Index Cond: (flight_no = 'PG0001'::bpchar) (4 rows)
L'inconvénient de l'implémentation actuelle de l'index de hachage est que les opérations avec l'index ne sont pas enregistrées dans le journal d'écriture anticipée (dont PostgreSQL avertit lorsque l'index est créé). Par conséquent, les index de hachage ne peuvent pas être récupérés après l'échec et ne participent pas aux réplications. En outre, l'indice de hachage est bien inférieur à "B-tree" en termes de polyvalence, et son efficacité est également discutable. Il n'est donc plus possible d'utiliser de tels index.
Cependant, cela changera dès cet automne (2017) une fois la version 10 de PostgreSQL publiée. Dans cette version, l'index de hachage a finalement pris en charge le journal d'écriture anticipée; en outre, l'allocation de mémoire a été optimisée et le travail simultané rendu plus efficace.
C'est vrai. Depuis PostgreSQL 10, les index de hachage ont une prise en charge complète et peuvent être utilisés sans restrictions. L'avertissement ne s'affiche plus.
Hashing sémantique
Mais pourquoi l'index de hachage a-t-il survécu presque depuis la naissance même de PostgreSQL jusqu'à 9.6 étant inutilisable? Le fait est que le SGBD utilise largement l'algorithme de hachage (en particulier, pour les jointures et les regroupements de hachage), et le système doit savoir quelle fonction de hachage s'applique à quels types de données. Mais cette correspondance n'est pas statique et ne peut pas être définie une fois pour toutes, car PostgreSQL autorise l'ajout de nouveaux types de données à la volée. Et c'est une méthode d'accès par hachage, où cette correspondance est stockée, représentée comme une association de fonctions auxiliaires avec des familles d'opérateurs.
demo=# select opf.opfname as opfamily_name, amproc.amproc::regproc AS opfamily_procedure from pg_am am, pg_opfamily opf, pg_amproc amproc where opf.opfmethod = am.oid and amproc.amprocfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_procedure;
opfamily_name | opfamily_procedure --------------------+-------------------- abstime_ops | hashint4 aclitem_ops | hash_aclitem array_ops | hash_array bool_ops | hashchar ...
Bien que ces fonctions ne soient pas documentées, elles peuvent être utilisées pour calculer le code de hachage pour une valeur du type de données approprié. Par exemple, la fonction "hashtext" si utilisée pour la famille d'opérateurs "text_ops":
demo=# select hashtext('one');
hashtext ----------- 127722028 (1 row)
demo=# select hashtext('two');
hashtext ----------- 345620034 (1 row)
Propriétés
Examinons les propriétés de l'index de hachage, où cette méthode d'accès fournit au système des informations sur lui-même. Nous avons fourni des requêtes la
dernière fois . Maintenant, nous n'irons pas au-delà des résultats:
name | pg_indexam_has_property ---------------+------------------------- can_order | f can_unique | f can_multi_col | f can_exclude | t name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t bitmap_scan | t backward_scan | t name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
Une fonction de hachage ne conserve pas la relation d'ordre: si la valeur d'une fonction de hachage pour une clé est plus petite que pour l'autre clé, il est impossible de tirer des conclusions sur la façon dont les clés elles-mêmes sont ordonnées. Par conséquent, en général, l'index de hachage peut prendre en charge la seule opération "égale":
demo=# select opf.opfname AS opfamily_name, amop.amopopr::regoperator AS opfamily_operator from pg_am am, pg_opfamily opf, pg_amop amop where opf.opfmethod = am.oid and amop.amopfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_operator;
opfamily_name | opfamily_operator ---------------+---------------------- abstime_ops | =(abstime,abstime) aclitem_ops | =(aclitem,aclitem) array_ops | =(anyarray,anyarray) bool_ops | =(boolean,boolean) ...
Par conséquent, l'index de hachage ne peut pas renvoyer les données ordonnées ("can_order", "orderable"). L'index de hachage ne manipule pas les NULL pour la même raison: l'opération "égal" n'a pas de sens pour NULL ("search_nulls").
Étant donné que l'index de hachage ne stocke pas les clés (mais uniquement leurs codes de hachage), il ne peut pas être utilisé pour l'accès uniquement à l'index ("renvoyable").
Cette méthode d'accès ne prend pas non plus en charge les index multi-colonnes ("can_multi_col").
Internes
À partir de la version 10, il sera possible de regarder dans les index internes de hachage via l'extension "
pageinspect ". Voici à quoi cela ressemblera:
demo=# create extension pageinspect;
La méta page (on obtient le nombre de lignes dans l'index et le nombre maximal de bucket utilisé):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type ---------------- metapage (1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket ---------+----------- 33121 | 127 (1 row)
Une page bucket (on obtient le nombre de tuples vivants et tuples morts, c'est-à-dire ceux qui peuvent être aspirés):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type ---------------- bucket (1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items ------------+------------ 407 | 0 (1 row)
Et ainsi de suite. Mais il est à peine possible de comprendre la signification de tous les champs disponibles sans examiner le code source. Si vous le souhaitez, vous devriez commencer par
README .
Continuez à lire .