Bonjour, je m'appelle Vladislav et je fais partie de l'équipe de développement de
Tarantool . Tarantool est à la fois un SGBD et un serveur d'applications. Aujourd'hui, je vais raconter comment nous avons mis en œuvre la mise à l'échelle horizontale dans Tarantool au moyen du module
VShard .
Quelques connaissances de base en premier.
Il existe deux types de mise à l'échelle: horizontale et verticale. Et il existe deux types de mise à l'échelle horizontale: la réplication et le partitionnement. La réplication assure la mise à l'échelle du calcul tandis que le partage est utilisé pour la mise à l'échelle des données.
Le partage est également subdivisé en deux types: le partage basé sur la plage et le partage basé sur le hachage.
Le partage basé sur la plage implique qu'une clé de fragment est calculée pour chaque enregistrement de cluster. Les clés de partition sont projetées sur une ligne droite qui est séparée en plages et affectée à différents nœuds physiques.
Le partage basé sur le hachage est moins compliqué: une fonction de hachage est calculée pour chaque enregistrement d'un cluster; les enregistrements avec la même fonction de hachage sont alloués au même nœud physique.
Je vais me concentrer sur la mise à l'échelle horizontale à l'aide du partage basé sur le hachage.
Ancienne implémentation
Tarantool Shard était notre module d'origine pour la mise à l'échelle horizontale. Il a utilisé une partition basée sur le hachage simple et des clés de partition calculées par clé primaire pour tous les enregistrements d'un cluster.
function shard_function(primary_key) return guava(crc32(primary_key), shard_count) end
Mais finalement Tarantool Shard est devenu incapable de s'attaquer à de nouvelles tâches.
Premièrement, l'une de nos éventuelles exigences est devenue la
localisation garantie
des données liées logiquement . En d'autres termes, lorsque nous avons des données liées de manière logique, nous voulons toujours les stocker sur un seul nœud physique, indépendamment de la topologie du cluster et des modifications d'équilibrage. Tarantool Shard ne peut pas garantir cela. Il a calculé les hachages uniquement avec les clés primaires, et donc le rééquilibrage pourrait entraîner la séparation temporaire des enregistrements avec le même hachage car les modifications ne sont pas effectuées de manière atomique.
Ce manque de localisation des données était le principal problème pour nous. Voici un exemple. Disons qu'il y a une banque où un client a ouvert un compte. Les informations sur le compte et le client doivent être stockées physiquement ensemble afin de pouvoir être récupérées en une seule demande ou modifiées en une seule transaction, par exemple lors d'un transfert d'argent. Si nous utilisons le partage traditionnel de Tarantool Shard, il y aura différentes valeurs de fonction de hachage pour les comptes et les clients. Les données pourraient se retrouver sur des nœuds physiques distincts. Cela complique vraiment la lecture et les transactions avec les données d'un client.
format = {{'id', 'unsigned'}, {'email', 'string'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}} box.schema.create_space('account', {format = format})
Dans l'exemple ci-dessus, les champs id des comptes et du client peuvent être incohérents. Ils sont connectés par le champ customer_id du compte et le champ id du client. Le même champ id violerait la contrainte d'unicité de la clé primaire du compte. Et Shard ne peut pas effectuer le partage d'une autre manière.
Un autre problème était
le rééchantillonnage lent , qui est le problème fondamental de tous les fragments de hachage. L'essentiel est que lors du changement de composants de cluster, la fonction de partition change car elle dépend généralement du nombre de nœuds. Ainsi, lorsque la fonction change, il est nécessaire de parcourir tous les enregistrements du cluster et de recalculer la fonction. Il peut également être nécessaire de transférer certains enregistrements. Et pendant le transfert de données, nous ne savons même pas si l'enregistrement requis? Dans la demande, les données ont déjà été transférées ou sont en cours de transfert. Ainsi, lors du nouveau partage, il est nécessaire de faire des demandes de lecture avec les anciennes et les nouvelles fonctions de partition. Les demandes sont traitées deux fois plus lentement, ce qui est inacceptable.
Un autre problème avec Tarantool Shard était la faible disponibilité des lectures en cas de défaillance d'un nœud dans un jeu de réplicas.
Nouvelle solution
Nous avons créé
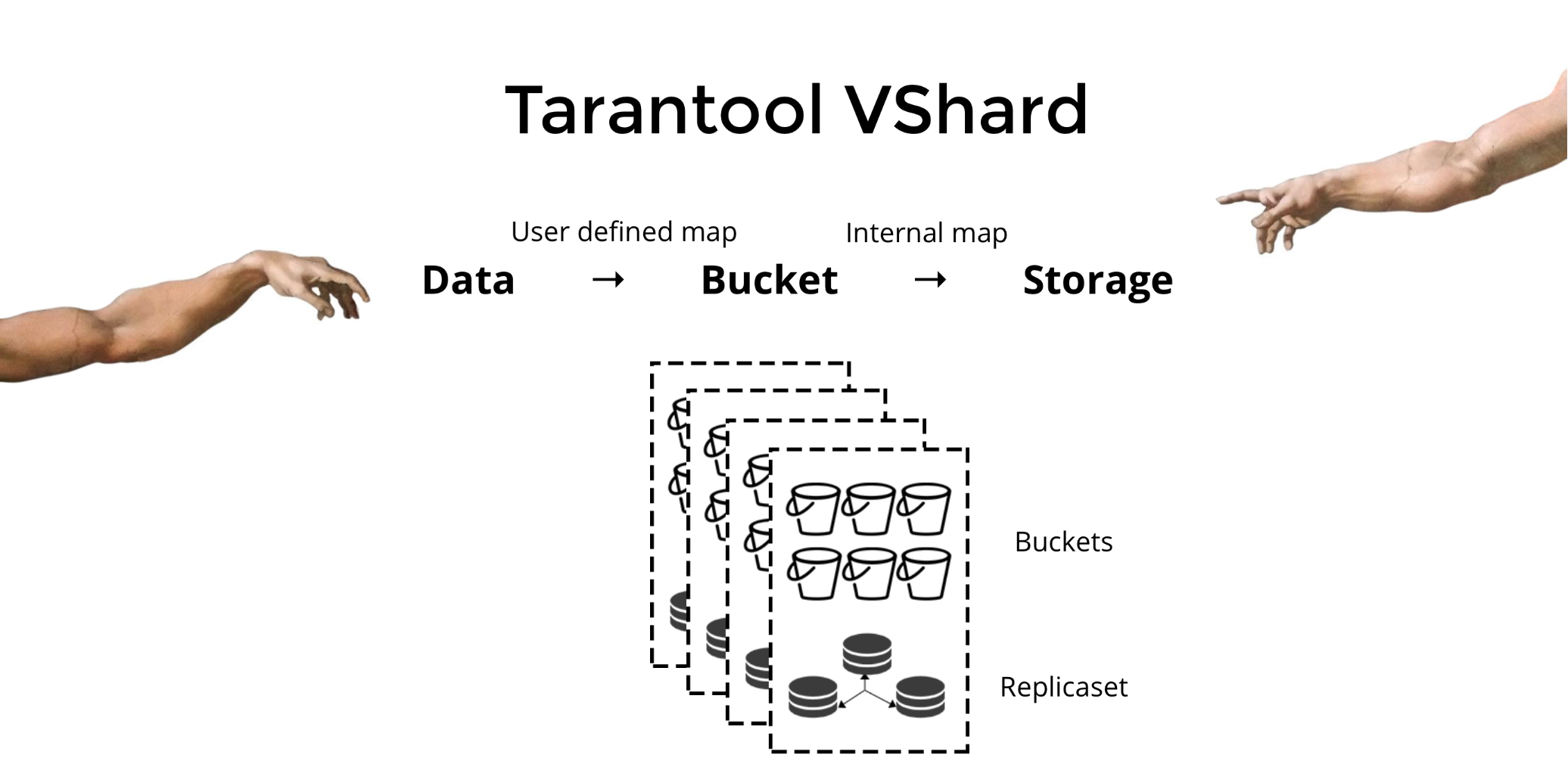
Tarantool VShard pour résoudre les trois problèmes mentionnés ci-dessus. Sa principale différence est que son niveau de stockage de données est virtualisé, c'est-à-dire que les stockages physiques hébergent des stockages virtuels et que les enregistrements de données sont alloués sur les virtuels. Ces stockages sont appelés
seaux . L'utilisateur n'a pas à se soucier de ce qui se trouve sur un nœud physique donné. Un compartiment est une unité de données atomique indivisible, comme un tuple dans le partage traditionnel. VShard stocke toujours un compartiment entier sur un nœud physique et lors du nouveau partage, il migre toutes les données d'un compartiment de manière atomique. Cette méthode garantit la localisation des données. Nous plaçons simplement les données dans un seul compartiment, et nous pouvons toujours être sûrs qu'elles ne seront pas séparées lors des changements de cluster.

Comment regrouper les données dans un seul compartiment? Ajoutons un nouveau champ d'ID de compartiment à la table pour notre client bancaire. Si cette valeur de champ est la même pour les données liées, tous les enregistrements seront dans un seul compartiment. L'avantage est que nous pouvons stocker des enregistrements avec le même identifiant de compartiment dans différents espaces, et même dans différents moteurs. La localisation des données basée sur l'id du compartiment est garantie quelle que soit la méthode de stockage.
format = {{'id', 'unsigned'}, {'email', 'string'}, {'bucket_id', 'unsigned'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}, {'bucket_id', 'unsigned'}} box.schema.create_space('account', {format = format})
Pourquoi est-ce si important? Lors de l'utilisation du partitionnement traditionnel, les données s'étendraient à divers stockages physiques existants. Pour notre exemple de banque, nous devons contacter chaque nœud lors de la demande de tous les comptes d'un client donné. On obtient donc une complexité de lecture O (N), où N est le nombre de stockages physiques. C'est incroyablement lent.
L'utilisation de compartiments et de la localité par identifiant de compartiment permet de lire les données nécessaires à partir d'un nœud à l'aide d'une seule demande, quelle que soit la taille du cluster.

Dans VShard, vous calculez votre identifiant de compartiment et vous l'affectez. Pour certaines personnes, c'est un avantage, tandis que d'autres le considèrent comme un inconvénient. Je crois que la possibilité de choisir votre propre fonction pour le calcul de l'identifiant du compartiment est un avantage.
Quelle est la principale différence entre le sharding traditionnel et le sharding virtuel avec des godets?
Dans le premier cas, lorsque nous modifions les composants d'un cluster, nous avons deux états: l'ancien (l'ancien) et le nouveau à implémenter. Dans le processus de transition, il est nécessaire non seulement de migrer les données, mais également de recalculer la fonction de hachage pour chaque enregistrement. Ce n'est pas très pratique car à un moment donné, nous ne savons pas si les données requises ont déjà été migrées ou non. En outre, cette méthode n'est pas fiable et les modifications ne sont pas atomiques, car la migration atomique de l'ensemble d'enregistrements avec la même valeur de fonction de hachage nécessiterait un stockage persistant de l'état de migration au cas où une récupération serait nécessaire. En conséquence, il y a des conflits et des erreurs, et l'opération doit être redémarrée plusieurs fois.
Le partage virtuel est beaucoup plus simple. Nous n'avons pas deux états de cluster différents; nous n'avons que l'état du seau. Le cluster est plus flexible, il passe en douceur d'un état à un autre. Il y a maintenant plus de deux États? (peu clair). Avec la transition en douceur, il est possible de modifier l'équilibrage à la volée ou de supprimer les nouveaux stockages ajoutés. Autrement dit, le contrôle d'équilibrage a considérablement augmenté et est devenu plus granulaire.
Utilisation
Supposons que nous avons sélectionné une fonction pour notre identifiant de compartiment et que nous ayons téléchargé tant de données dans le cluster qu'il ne reste plus d'espace. Maintenant, nous aimerions ajouter des nœuds et y déplacer automatiquement les données. C'est ainsi que nous procédons dans VShard: d'abord, nous démarrons de nouveaux nœuds et y exécutons Tarantool, puis nous mettons à jour notre configuration VShard. Il contient des informations sur chaque composant de cluster, chaque réplique, jeux de réplicas, maîtres, URI attribués et bien plus encore. Maintenant, nous ajoutons nos nouveaux nœuds dans le fichier de configuration et l'appliquons à tous les nœuds de cluster à l'aide de VShard.storage.cfg.
function create_user(email) local customer_id = next_id() local bucket_id = crc32(customer_id) box.space.customer:insert(customer_id, email, bucket_id) end function add_account(customer_id) local id = next_id() local bucket_id = crc32(customer_id) box.space.account:insert(id, customer_id, 0, bucket_id) end
Comme vous vous en souvenez peut-être, lorsque vous modifiez le nombre de nœuds dans le partage traditionnel, la fonction de partition elle-même change également. Cela ne se produit pas dans VShard. Ici, nous avons un nombre fixe de stockages virtuels ou de compartiments. Il s'agit d'une constante que vous choisissez lors du démarrage du cluster. Il peut sembler que l'évolutivité est donc limitée, mais ce n'est vraiment pas le cas. Vous pouvez spécifier un grand nombre de compartiments, des dizaines et des centaines de milliers. La chose importante à savoir est qu'il devrait y avoir au moins deux ordres de grandeur de plus de compartiments que le nombre maximum de jeux de réplicas que vous aurez jamais dans le cluster.
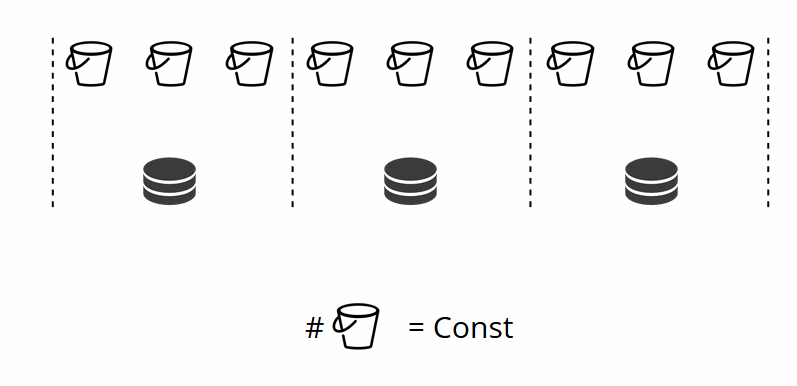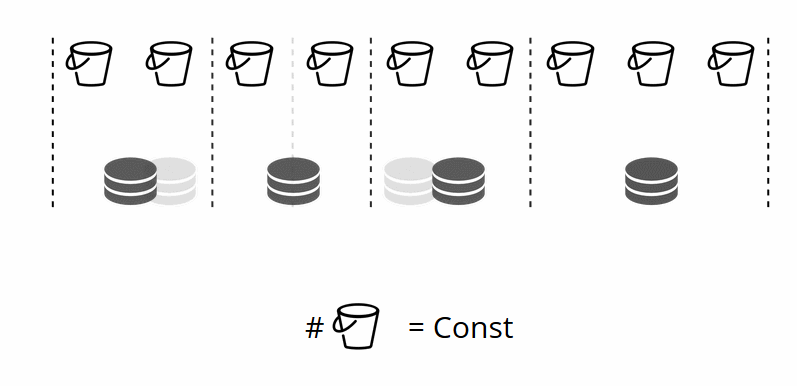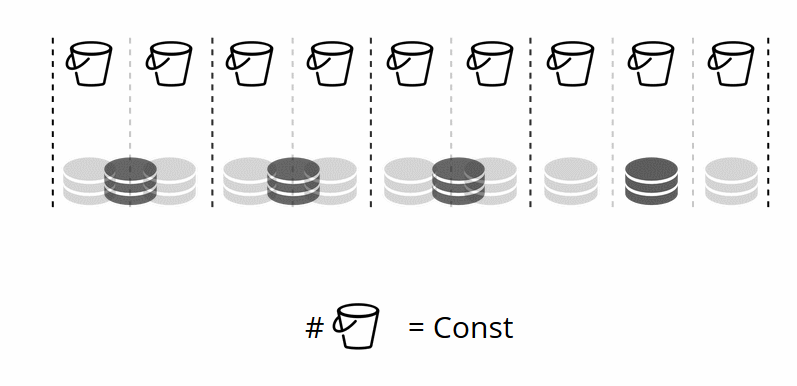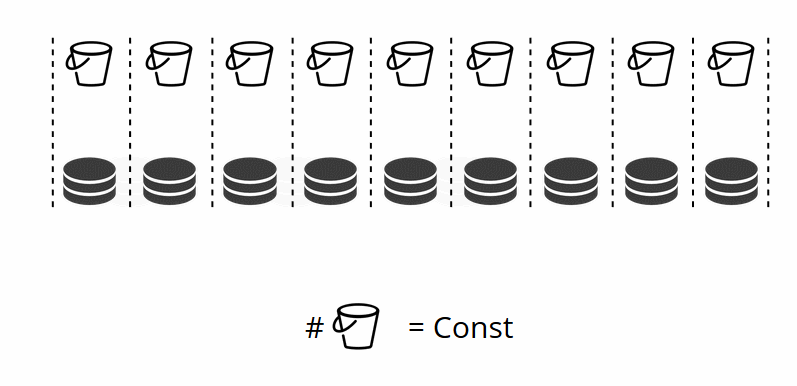
Étant donné que le nombre de stockages virtuels ne change pas et que la fonction de partition ne dépend que de cette valeur, nous pouvons ajouter autant de stockages physiques que nous le souhaitons sans recalculer la fonction de partition.
Alors, comment les compartiments sont-ils attribués aux stockages physiques? Si VShard.storage.cfg est appelé, un processus de rééquilibrage se réveille sur l'un des nœuds. Il s'agit d'un processus analytique qui calcule l'équilibre parfait pour le cluster. Le processus va à chaque nœud physique et récupère son nombre de compartiments, puis construit des itinéraires de leurs mouvements afin d'équilibrer l'allocation. Le rééquilibreur envoie ensuite les routes vers les stockages surchargés, qui à leur tour commencent à envoyer des compartiments. Un peu plus tard, le cluster est équilibré.
Dans les projets du monde réel, un équilibre parfait peut ne pas être atteint aussi facilement. Par exemple, un jeu de répliques peut contenir moins de données que l'autre car il a moins de capacité de stockage. Dans ce cas, VShard peut penser que tout est équilibré mais en fait le premier stockage est sur le point de surcharger. Pour contrer cela, nous avons fourni un mécanisme pour corriger les règles d'équilibrage au moyen de pondérations. Un poids peut être attribué à n'importe quel jeu de répliques ou stockage. Lorsque le rééquilibreur décide combien de seaux doivent être envoyés et où, il prend en compte les
relations de toutes les paires de poids.
Par exemple, si un stockage pèse 100 et l'autre 200, le second stockera deux fois plus de seaux que le premier. Veuillez noter que je parle spécifiquement des
relations de poids. Les valeurs absolues n'ont aucune influence. Vous choisissez des pondérations basées sur une distribution à 100% dans un cluster: donc 30% pour un stockage donnerait 70% pour l'autre. Vous pouvez prendre la capacité de stockage en gigaoctets comme base ou mesurer le poids du nombre de compartiments. Le plus important est de garder le ratio nécessaire.

Cette méthode a un effet secondaire intéressant: si un stockage se voit attribuer un poids nul, le rééquilibreur fera redistribuer ce stockage à tous ses compartiments. Par la suite, vous pouvez supprimer l'ensemble de réplicas complet de la configuration.
Migration du compartiment atomique
Nous avons un seau; il accepte certaines lectures et écritures, et à un moment donné, le rééquilibreur demande sa migration vers un autre stockage. Le compartiment cesse d'accepter les demandes d'écriture, sinon il serait mis à jour pendant la migration, puis à nouveau mis à jour pendant la migration de mise à jour, puis la mise à jour serait mise à jour, etc. Par conséquent, les demandes d'écriture sont bloquées, mais la lecture à partir du compartiment est toujours possible. Les données sont désormais migrées vers le nouvel emplacement. Une fois la migration terminée, le compartiment recommence à accepter les demandes. Il existe toujours dans l'ancien emplacement, mais il est marqué comme poubelle, et plus tard le garbage collector le supprime pièce par pièce.
Certaines métadonnées sont physiquement stockées sur le disque associé à chaque compartiment. Toutes les étapes décrites ci-dessus sont stockées sur le disque, et quoi qu'il arrive au stockage, l'état du compartiment sera automatiquement restauré.
Vous pouvez avoir quelques questions suivantes:
- Qu'arrive-t-il aux demandes qui fonctionnent avec le compartiment au début de la migration?
Il existe deux types de références dans les métadonnées de chaque compartiment: RO et RW. Lorsqu'un utilisateur fait une demande à un compartiment, il indique si le travail doit être en lecture seule ou en lecture-écriture. Pour chaque demande, le compteur de référence correspondant est augmenté.
Pourquoi avons-nous besoin de compteurs de référence pour les demandes d'écriture? Supposons qu'un compartiment soit en cours de migration et que, soudain, le garbage collector souhaite le supprimer. Le garbage collector reconnaît que le compteur de référence est supérieur à zéro et donc le compartiment ne sera pas supprimé. Lorsque toutes les demandes sont terminées, le garbage collector peut faire son travail.
Le compteur de référence pour les écritures garantit également que la migration du compartiment ne démarrera pas s'il y a au moins une demande d'écriture en cours. Mais là encore, les demandes d'écriture pouvaient arriver l'une après l'autre et le compartiment ne serait jamais migré. Donc, si le rééquilibreur souhaite déplacer le compartiment, le système bloque les nouvelles demandes d'écriture en attendant que les demandes en cours soient terminées pendant un certain délai. Si les demandes ne sont pas terminées dans le délai spécifié, le système recommence à accepter de nouvelles demandes d'écriture tout en différant la migration du compartiment. De cette façon, le rééquilibreur tentera de migrer le compartiment jusqu'à ce que la migration réussisse.
VShard dispose d'une API bucket_ref de bas niveau au cas où vous auriez besoin de plus que de simples capacités de haut niveau. Si vous voulez vraiment faire quelque chose vous-même, veuillez vous référer à cette API. - Est-il possible de laisser les enregistrements non bloqués?
Non. Si le compartiment contient des données critiques et nécessite un accès permanent en écriture, vous devrez bloquer complètement sa migration. Nous avons une fonction bucket_pin pour faire exactement cela. Il épingle le compartiment au jeu de réplicas actuel afin que le rééquilibreur ne puisse pas migrer le compartiment. Dans ce cas, les godets adjacents pourront cependant se déplacer sans contraintes.

Un verrou de jeu de répliques est un outil encore plus puissant que bucket_pin. Cela ne se fait plus dans le code mais plutôt dans la configuration. Un verrou de jeu de réplicas désactive la migration de tout compartiment entrant / sortant du jeu de réplicas. Ainsi, toutes les données seront disponibles en permanence pour les écritures.

VShard.router
VShard se compose de deux sous-modules: VShard.storage et VShard.router. Nous pouvons les créer et les mettre à l'échelle indépendamment sur une seule instance. Lors de la demande d'un cluster, nous ne savons pas où se trouve un compartiment donné, et VShard.router le recherchera par identifiant de compartiment pour nous.
Revenons à notre exemple, le cluster bancaire avec les comptes clients. Je voudrais pouvoir obtenir tous les comptes d'un certain client du cluster. Cela nécessite une fonction standard pour la recherche locale:

Il recherche tous les comptes du client par son identifiant. Maintenant, je dois décider où je dois exécuter la fonction. Dans ce but, je calcule l'id du bucket par identifiant client dans ma demande et demande à VShard.router d'appeler la fonction dans le stockage où se trouve le bucket avec l'id du bucket cible. Le sous-module possède une table de routage qui décrit les emplacements des compartiments dans les jeux de réplicas. VShard.router redirige ma demande.
Il peut certainement arriver que l'éclatement commence à ce moment précis et que les godets commencent à bouger. Le routeur en arrière-plan met progressivement à jour la table en gros morceaux en demandant les tables de compartiment actuelles aux stockages.
Nous pouvons même demander un compartiment récemment migré, par lequel le routeur n'a pas encore mis à jour sa table de routage. Dans ce cas, il demandera l'ancien stockage, qui redirigera le routeur vers un autre stockage, ou répondra simplement qu'il ne dispose pas des données nécessaires. Ensuite, le routeur passera par chaque stockage à la recherche du compartiment requis. Et nous ne remarquerons même pas une erreur dans la table de routage.
Lire le basculement
Rappelons nos problèmes initiaux:
- Aucune localité de données. Résolu au moyen de seaux.
- Processus de resharding s'enlisant et retenant tout. Nous avons implémenté le transfert de données atomiques au moyen de seaux et nous sommes débarrassés du recalcul de la fonction des fragments.
- Lire le basculement.
Le dernier problème est résolu par VShard.router, pris en charge par le sous-système de basculement de lecture automatique.
De temps en temps, le routeur envoie un ping aux stockages spécifiés dans la configuration. Supposons par exemple que le routeur ne puisse pas envoyer une requête ping à l'un d'eux. Le routeur dispose d'une connexion de sauvegarde à chaud à chaque réplique, donc si la réplique actuelle ne répond pas, elle passe simplement à une autre. Les demandes de lecture seront traitées normalement car nous pouvons lire sur les répliques (mais pas écrire). Et nous pouvons spécifier la priorité des répliques comme facteur pour que le routeur choisisse le basculement pour les lectures. Cela se fait par zonage.

Nous attribuons un numéro de zone à chaque réplique et à chaque routeur et spécifions une table où nous indiquons la distance entre chaque paire de zones. Lorsque le routeur décide où envoyer une demande de lecture, il sélectionne une réplique dans la zone la plus proche.
Voici à quoi cela ressemble dans la configuration:

En général, vous pouvez demander n'importe quelle réplique, mais si le cluster est volumineux, complexe et hautement distribué, le zonage peut être très utile. Différents racks de serveurs peuvent être sélectionnés comme zones afin que le réseau ne soit pas surchargé par le trafic. Alternativement, des points géographiquement isolés peuvent être sélectionnés.
Le zonage est également utile lorsque les répliques présentent des comportements différents. Par exemple, chaque jeu de réplicas possède un réplica de sauvegarde qui ne doit pas accepter les demandes mais ne doit stocker qu'une copie des données. Dans ce cas, nous le plaçons dans une zone éloignée de tous les routeurs du tableau afin que le routeur n'adresse pas cette réplique à moins que cela ne soit absolument nécessaire.
Écriture de basculement
Nous avons déjà parlé du basculement en lecture. Qu'en est-il du basculement en écriture lors du changement de maître? Dans VShard, l'image n'est pas aussi rose qu'auparavant: la sélection principale n'est pas implémentée, nous devrons donc la faire nous-mêmes. Lorsque nous avons en quelque sorte désigné un maître, l'instance désignée devrait maintenant prendre le relais en tant que maître. Ensuite, nous mettons à jour la configuration en spécifiant master = false pour l'ancien master et master = true pour le nouveau, appliquons la configuration au moyen de VShard.storage.cfg et la partageons avec chaque stockage. Tout le reste se fait automatiquement. L'ancien maître cesse d'accepter les demandes d'écriture et démarre la synchronisation avec le nouveau, car il se peut que des données aient déjà été appliquées sur l'ancien maître mais pas sur le nouveau. Après cela, le nouveau maître est en charge et commence à accepter les demandes, et l'ancien maître est une réplique. Voici comment fonctionne le basculement en écriture dans VShard.
replicas = new_cfg.sharding[uud].replicas replicas[old_master_uuid].master = false replicas[new_master_uuid].master = true vshard.storage.cfg(new_cfg)
Comment suivons-nous ces différents événements?
VShard.storage.info et VShard.router.info suffisent.
VShard.storage.info affiche des informations dans plusieurs sections.
vshard.storage.info() --- - replicasets: <replicaset_2>: uuid: <replicaset_2> master: uri: storage@127.0.0.1:3303 <replicaset_1>: uuid: <replicaset_1> master: missing bucket: receiving: 0 active: 0 total: 0 garbage: 0 pinned: 0 sending: 0 status: 2 replication: status: slave Alerts: - ['MISSING_MASTER', 'Master is not configured for ''replicaset <replicaset_1>']
La première section concerne la réplication. Vous pouvez voir ici l'état du jeu de réplicas où la fonction est appelée: son décalage de réplication, ses connexions disponibles et indisponibles, sa configuration principale, etc.
Dans la section des compartiments, vous pouvez voir en temps réel le nombre de compartiments migrés vers / depuis le jeu de réplicas actuel, le nombre de compartiments fonctionnant en mode normal, le nombre de compartiments marqués comme des ordures et le nombre de compartiments épinglés.
La section Alertes affiche les problèmes que VShard a pu déterminer lui-même: "le maître n'est pas configuré", "le niveau de redondance est insuffisant", "le maître est là, mais toutes les répliques ont échoué", etc.
Et la dernière section (q: est-ce "statut"?) Est une lumière qui devient rouge quand tout va mal. C'est un nombre de zéro à trois, un nombre plus élevé étant pire.
VShard.router.info a les mêmes sections, mais leur signification est quelque peu différente.
vshard.router.info() --- - replicasets: <replicaset_2>: replica: &0 status: available uri: storage@127.0.0.1:3303 uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7 bucket: available_rw: 500 uuid: <replicaset_2> master: *0 <replicaset_1>: replica: &1 status: available uri: storage@127.0.0.1:3301 uuid: 8a274925-a26d-47fc-9e1b-af88ce939412 bucket: available_rw: 400 uuid: <replicaset_1> master: *1 bucket: unreachable: 0 available_ro: 800 unknown: 200 available_rw: 700 status: 1 alerts: - ['UNKNOWN_BUCKETS', '200 buckets are not discovered']
La première section concerne la réplication, bien qu'elle ne contienne pas d'informations sur les retards de réplication, mais plutôt des informations sur la disponibilité: connexions du routeur à un jeu de répliques; connexion à chaud et connexion de sauvegarde en cas de défaillance du maître; le maître sélectionné; et le nombre de godets RW et de godets RO disponibles sur chaque jeu de répliques.
La section de compartiment affiche le nombre total de compartiments en lecture-écriture et en lecture seule actuellement disponibles pour ce routeur; le nombre de seaux avec un emplacement inconnu; et le nombre de compartiments avec un emplacement connu mais sans connexion au jeu de réplicas nécessaire.
La section des alertes décrit principalement les connexions, les événements de basculement et les compartiments non identifiés.
Enfin, il y a aussi le statut simple? Indicateur de zéro à trois.
De quoi avez-vous besoin pour utiliser VShard?
Vous devez d'abord sélectionner un nombre constant de compartiments. Pourquoi ne pas simplement le définir sur int32_max? Parce que les métadonnées sont stockées avec chaque compartiment, 30 octets en stockage et 16 octets sur le routeur. Plus vous disposez de compartiments, plus les métadonnées prendront de la place. Mais en même temps, la taille du compartiment sera plus petite, ce qui signifie une granularité de cluster plus élevée et une vitesse de migration plus élevée par compartiment. Vous devez donc choisir ce qui est le plus important pour vous et le niveau d'évolutivité nécessaire.
Deuxièmement, vous devez sélectionner une fonction de partition pour calculer l'ID du compartiment. Les règles sont les mêmes que lors de la sélection d'une fonction de partition dans le partage traditionnel, car un compartiment ici est le même que le nombre fixe de stockages dans le partage traditionnel. La fonction doit répartir uniformément les valeurs de sortie, sinon la croissance de la taille du compartiment ne sera pas équilibrée et VShard ne fonctionne qu'avec le nombre de compartiments. Si vous n'équilibrez pas votre fonction de partition, vous devrez migrer les données d'un compartiment à un autre et modifier la fonction de partition. Ainsi, vous devez choisir avec soin.
Résumé
VShard assure:
- localité de données
- resharding atomique
- flexibilité de cluster plus élevée
- basculement en lecture automatique
- plusieurs contrôleurs de godet.
VShard est en développement actif. Certaines tâches planifiées sont déjà en cours d'exécution. La première tâche est
l'équilibrage de charge du routeur . En cas de demandes de lecture importantes, il n'est pas toujours recommandé de les adresser au maître. Le routeur doit équilibrer les demandes de réplicas de lecture différents par lui-même.
La deuxième tâche est
la migration du compartiment sans verrouillage . Un algorithme a déjà été implémenté qui permet de garder les compartiments débloqués même pendant la migration. Le compartiment ne sera bloqué qu'à la fin pour documenter la migration elle-même.
La troisième tâche est
l'application atomique de la configuration . Il n'est pas commode ou atomique d'appliquer la configuration séparément car une partie du stockage peut être indisponible, et si la configuration n'est pas appliquée, que faisons-nous ensuite? C'est pourquoi nous travaillons sur un mécanisme de transfert automatique de configuration.