
Lors du diagnostic de problèmes dans un cluster Kubernetes, nous remarquons souvent que parfois l'un des nœuds du cluster dégouline * et, bien sûr, cela est rare et étrange. Nous sommes donc arrivés à la nécessité d'un outil qui
exécuterait un
ping de chaque nœud à chaque nœud et présenterait les résultats de son travail sous la forme
de métriques Prometheus . Nous n'aurions qu'à dessiner des graphiques dans Grafana et localiser rapidement le nœud défaillant (et, si nécessaire, en supprimer tous les pods, puis faire le travail correspondant **) ...
* Par "bruine", je comprends que le nœud peut passer en état NotReady et retourner soudainement au travail. Ou, par exemple, une partie du trafic des pods peut ne pas atteindre les pods sur les nœuds voisins.** Pourquoi de telles situations surviennent-elles? L'une des causes courantes peut être des problèmes de réseau sur le commutateur dans le centre de données. Par exemple, une fois dans Hetzner, nous avons configuré vswitch, mais à un moment merveilleux, l'un des nœuds a cessé d'être accessible sur ce port vswitch: à cause de cela, il s'est avéré que le nœud était complètement inaccessible sur le réseau local.De plus, nous aimerions
lancer un tel service directement dans Kubernetes , afin que l'ensemble du déploiement se fasse à l'aide de l'installation du Helm-chart. (Anticipation des questions - si vous utilisez le même Ansible, nous aurions à écrire des rôles pour différents environnements: AWS, GCE, bare metal ...) Ayant un peu cherché sur Internet des outils prêts à l'emploi pour la tâche, nous n'avons rien trouvé de convenable. Par conséquent, ils ont fait le leur.
Script et configs
Ainsi, le composant principal de notre solution est un
script qui surveille le changement dans tous les nœuds du champ
.status.addresses et, si un nœud a changé ce champ (c'est-à-dire qu'un nouveau nœud a été ajouté), envoie des valeurs Helm au graphique à l'aide cette liste de nœuds sous forme de ConfigMap:
--- apiVersion: v1 kind: ConfigMap metadata: name: node-ping-config namespace: kube-prometheus data: nodes.json: > {{ .Values.nodePing.nodes | toJson }}
Il
s'exécute sur chaque nœud et envoie des paquets ICMP à toutes les autres instances de cluster Kubernetes 2 fois par seconde, et les résultats sont écrits dans les fichiers texte.
Le script est inclus dans l'
image Docker :
FROM python:3.6-alpine3.8 COPY rootfs / WORKDIR /app RUN pip3 install --upgrade pip && pip3 install -r requirements.txt && apk add --no-cache fping ENTRYPOINT ["python3", "/app/node-ping.py"]
De plus, un
ServiceAccount a été créé et un rôle pour celui-ci, qui ne permet de recevoir qu'une liste de nœuds (afin de connaître leurs adresses):
--- apiVersion: v1 kind: ServiceAccount metadata: name: node-ping namespace: kube-prometheus --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kube-prometheus:node-ping rules: - apiGroups: [""] resources: ["nodes"] verbs: ["list"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kube-prometheus:kube-node-ping subjects: - kind: ServiceAccount name: node-ping namespace: kube-prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-prometheus:node-ping
Enfin, vous avez besoin de
DaemonSet , qui s'exécute sur toutes les instances du cluster:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: node-ping namespace: kube-prometheus labels: tier: monitoring app: node-ping version: v1 spec: updateStrategy: type: RollingUpdate template: metadata: labels: name: node-ping spec: terminationGracePeriodSeconds: 0 tolerations: - operator: "Exists" serviceAccountName: node-ping priorityClassName: cluster-low containers: - resources: requests: cpu: 0.10 image: private-registry.flant.com/node-ping/node-ping-exporter:v1 imagePullPolicy: Always name: node-ping env: - name: MY_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName - name: PROMETHEUS_TEXTFILE_DIR value: /node-exporter-textfile/ - name: PROMETHEUS_TEXTFILE_PREFIX value: node-ping_ volumeMounts: - name: textfile mountPath: /node-exporter-textfile - name: config mountPath: /config volumes: - name: textfile hostPath: path: /var/run/node-exporter-textfile - name: config configMap: name: node-ping-config imagePullSecrets: - name: antiopa-registry
Résumé des coups de mots:
- Résultats du script Python - c.-à-d. les fichiers texte placés sur la machine hôte dans le répertoire
/var/run/node-exporter-textfile exporter- textfile entrent dans l'exportateur de nœuds DaemonSet. Les arguments pour l'exécuter indiquent --collector.textfile.directory /host/textfile , où /host/textfile est le /host/textfile accès /host/textfile sur /var/run/node-exporter-textfile . (Vous pouvez en savoir plus sur le collecteur de fichiers texte dans l'exportateur de nœuds ici .) - En conséquence, le nœud-exportateur lit ces fichiers et Prometheus collecte toutes les données du nœud-exportateur.
Que s'est-il passé?
Maintenant - au résultat tant attendu. Lorsque de telles métriques ont été créées, nous pouvons les regarder et, bien sûr, dessiner des graphiques visuels. Voilà à quoi ça ressemble.
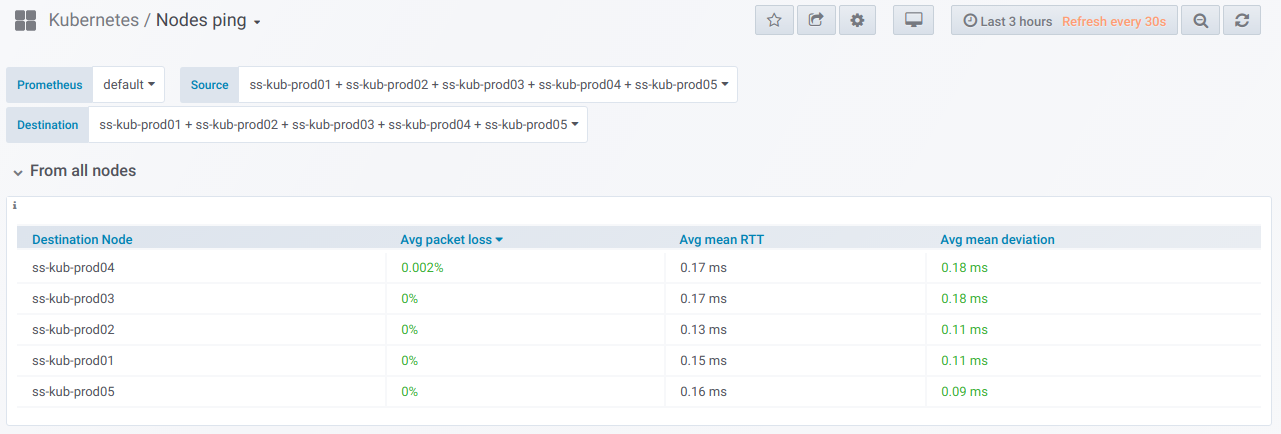
Tout d'abord, il existe un bloc général avec la possibilité (à l'aide du sélecteur) de sélectionner une liste de nœuds à
partir desquels le ping est effectué et
sur lesquels. Voici le
tableau récapitulatif du ping entre les nœuds sélectionnés pour la période spécifiée dans le tableau de bord Grafana:
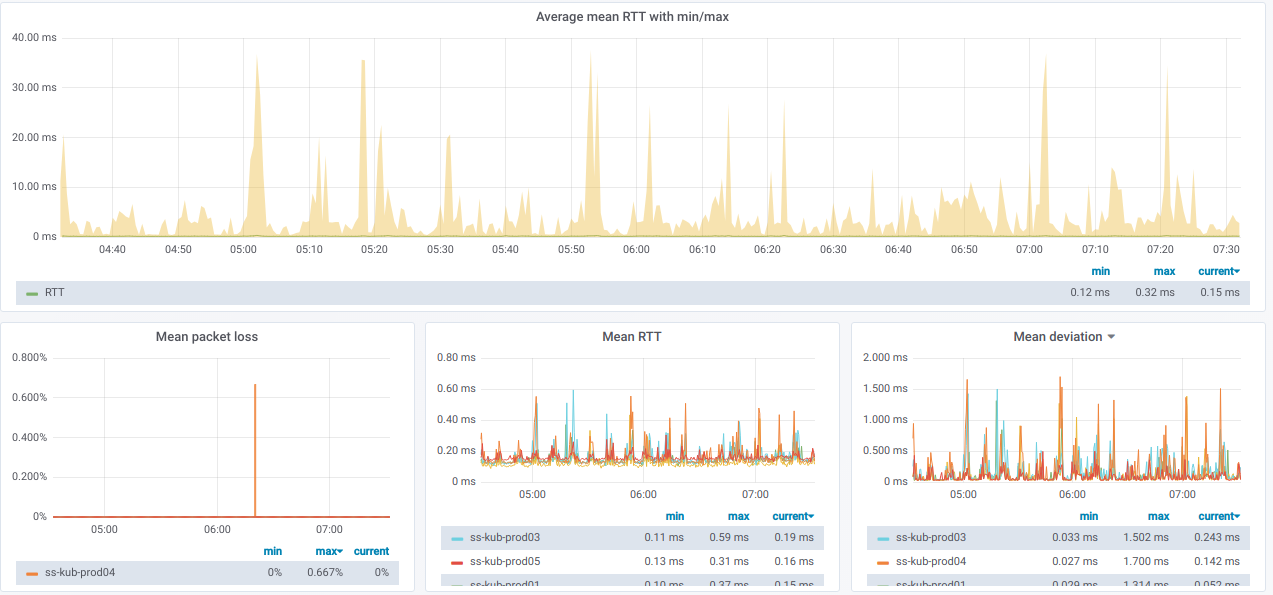
Et voici les graphiques avec des informations générales
sur les nœuds sélectionnés :
Nous avons également une liste de lignes, dont chacune est un graphique
pour un nœud distinct du sélecteur de
nœud source :

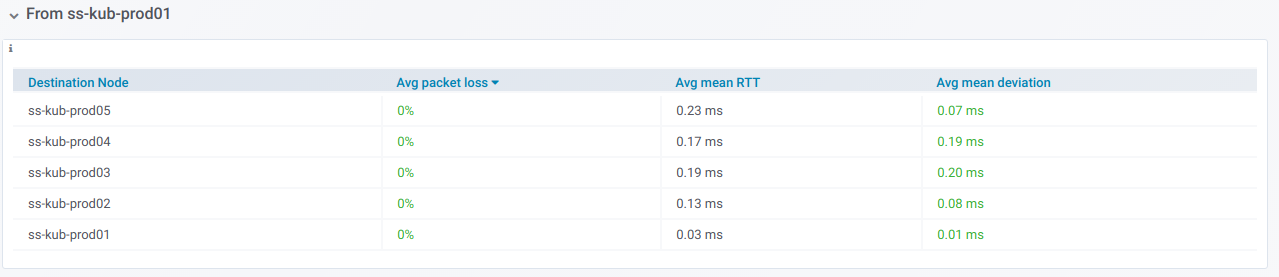
Si vous développez une telle ligne, vous pouvez voir des informations sur les pings
d'un nœud spécifique à tous les autres qui ont été sélectionnés dans le sélecteur de
nœuds de destination :
Ces informations sont dans des graphiques:
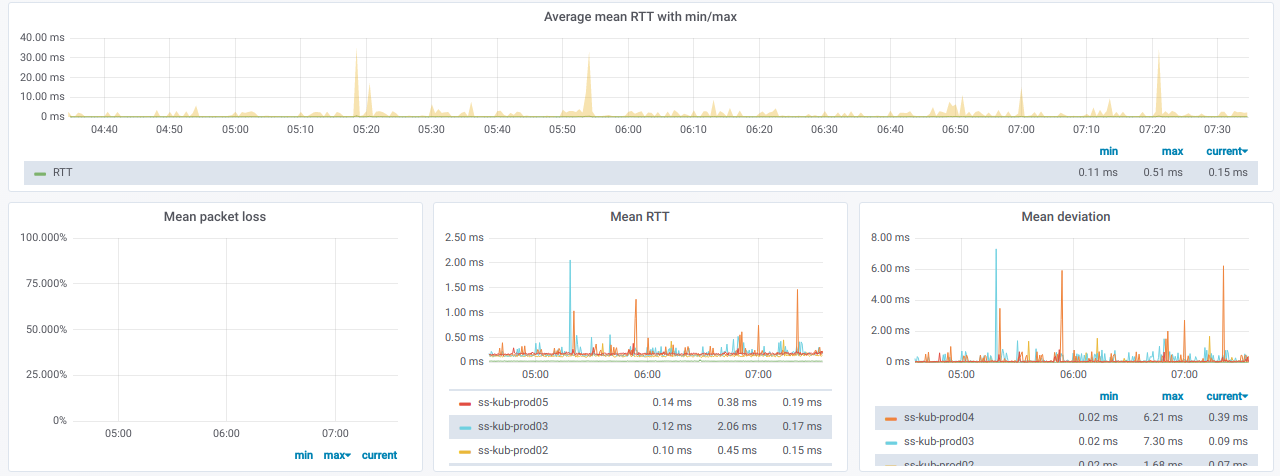
Enfin, à quoi ressembleront les graphiques chéris avec un mauvais ping entre les nœuds?
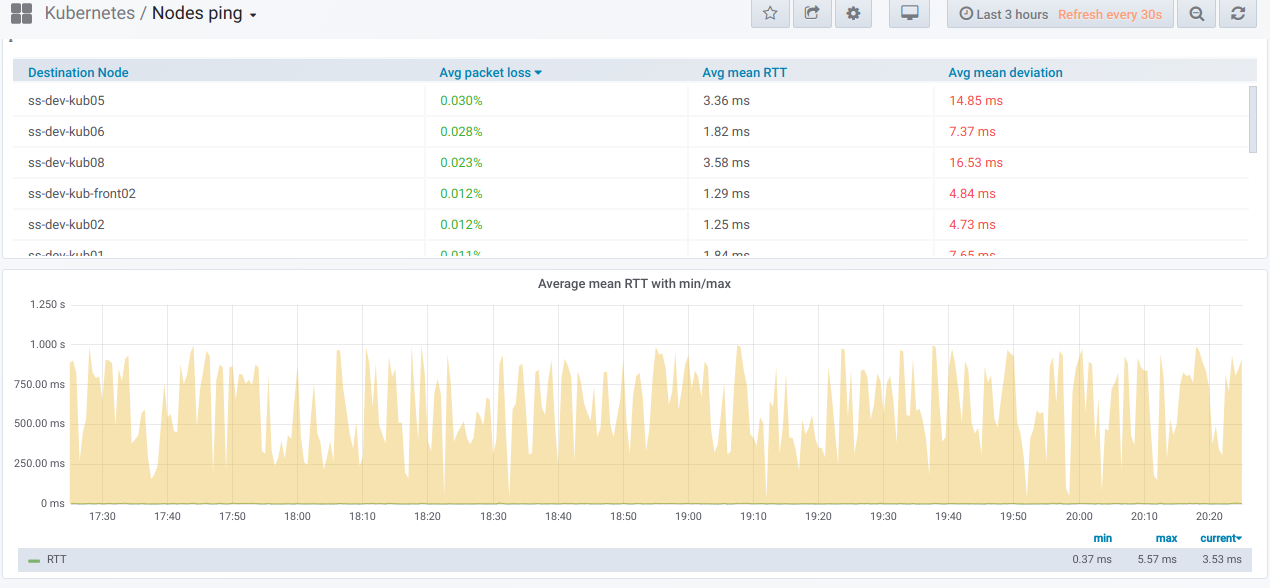
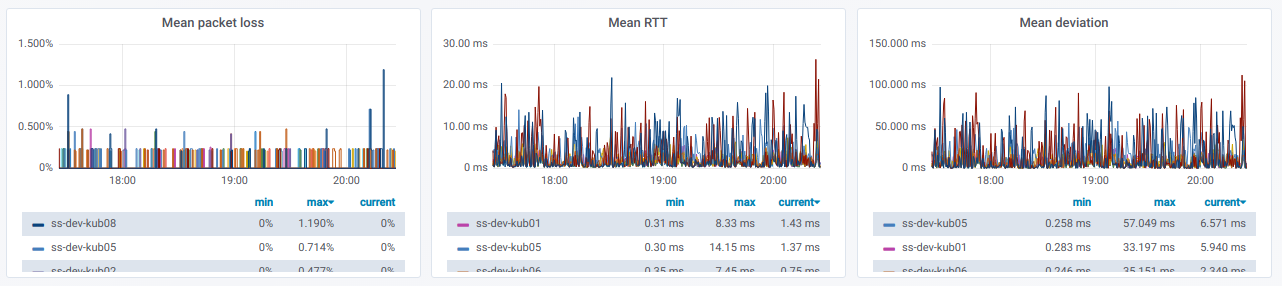
Si vous observez cela dans un environnement réel - il est temps de comprendre les raisons.
PS
Lisez aussi dans notre blog: