
De nombreux clients qui nous louent des ressources cloud utilisent des points de contrôle virtuels. Avec leur aide, les clients résolvent divers problèmes: quelqu'un contrôle l'accès du segment serveur à Internet ou publie leurs services pour nos équipements. Quelqu'un doit exécuter tout le trafic via la lame IPS, tandis que quelqu'un a besoin de Check Point comme passerelle VPN pour accéder aux ressources internes du centre de données à partir des succursales. Il y a ceux qui ont besoin de protéger leur infrastructure dans le cloud pour passer la certification selon FZ-152, mais je vais vous en parler séparément.
En service, je participe au soutien et à l'administration des points de contrôle. Aujourd'hui, je vais vous dire ce qu'il faut considérer lors du déploiement d'un cluster de points de contrôle dans un environnement virtuel. Je vais aborder des moments du niveau de virtualisation, du réseau, des paramètres de Check Point lui-même et de la surveillance.
Je ne promets pas de découvrir l'Amérique - beaucoup est dans les recommandations et les meilleures pratiques du vendeur. Mais personne ne les lit), alors ils ont conduit.
Mode cluster
Nous avons Check Points en direct dans des clusters. L'installation la plus courante est un cluster de deux nœuds en mode veille active. Si quelque chose arrive au nœud actif, il devient inactif et le nœud de secours est activé. Le passage à un nœud «de rechange» se produit généralement en raison de problèmes de synchronisation entre les membres du cluster, de l'état des interfaces, de la politique de sécurité établie, simplement en raison d'une lourde charge sur l'équipement.
Dans un cluster à deux nœuds, nous n'utilisons pas le mode actif-actif.
Si l'un des nœuds tombe, le nœud survivant peut tout simplement ne pas pouvoir résister à la double charge, et nous perdrons tout. Si vous voulez vraiment actif-actif, le cluster doit avoir au moins 3 nœuds.
Paramètres de réseau et de virtualisation
Le trafic de multidiffusion entre les interfaces SYNC des membres du cluster est autorisé sur l'équipement réseau. Si le trafic de multidiffusion n'est pas possible, le protocole de synchronisation (CCP) est utilisé en diffusion. Les nœuds du cluster Check Point se synchronisent les uns avec les autres. Les messages sur les modifications sont transmis d'un nœud à l'autre via la multidiffusion. Check Point utilise une implémentation multicast non standard (une adresse IP non multicast est utilisée). Pour cette raison, certains équipements, tels que le commutateur Cisco Nexus, ne comprennent pas ces messages et les bloquent donc. Dans ce cas, passez en diffusion.
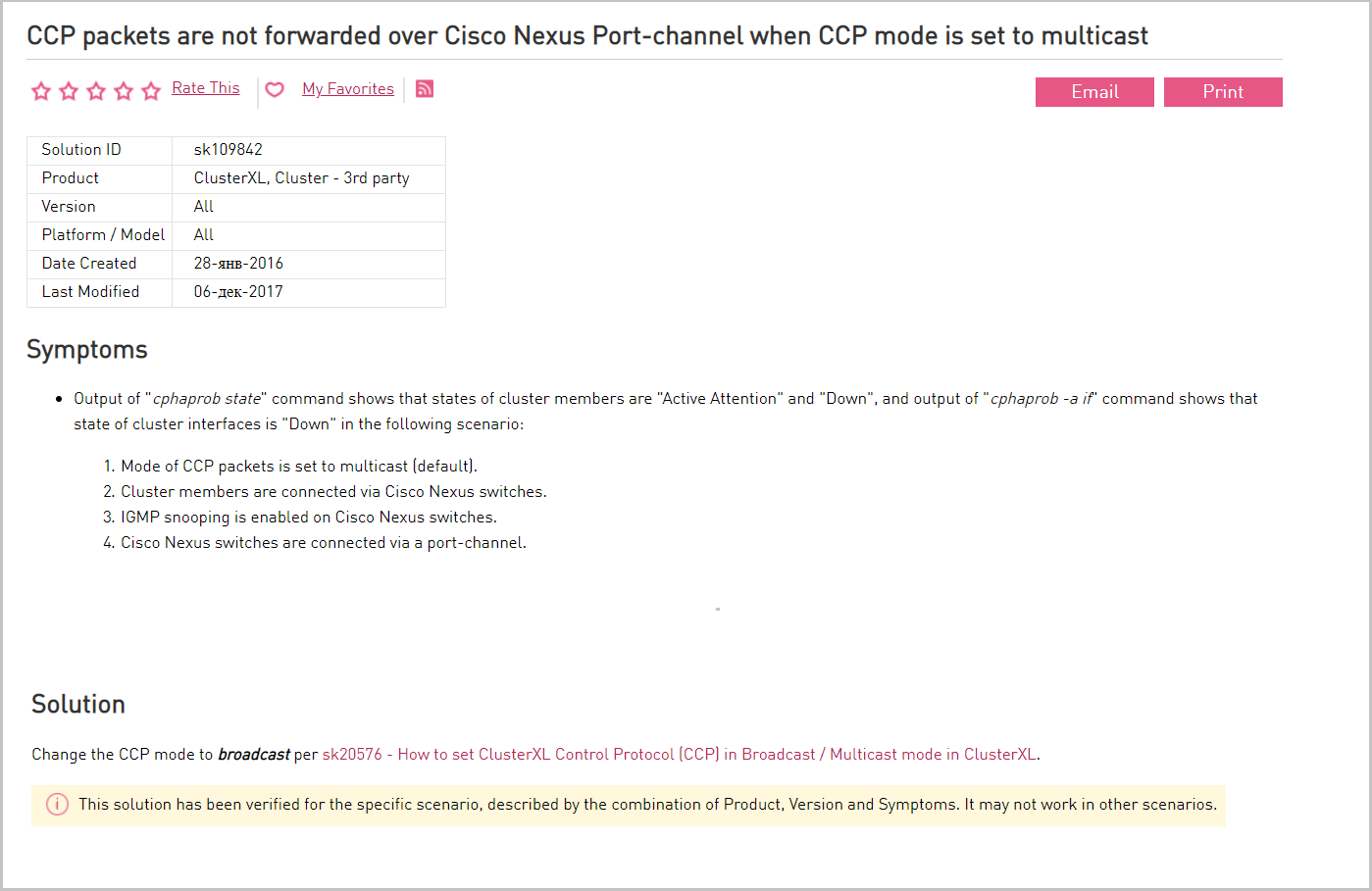 Description du problème avec Cisco Nexus et ses solutions sur le portail fournisseur.
Description du problème avec Cisco Nexus et ses solutions sur le portail fournisseur.Au niveau de la virtualisation, nous permettons également le passage du trafic multicast. Si la multidiffusion est interdite pour la synchronisation de cluster (CCP), utilisez la diffusion.
Dans la console Check Point, à l'aide de la commande cphaprob -a if, vous pouvez voir les paramètres CPP et son mode de fonctionnement (multidiffusion ou diffusion). Pour changer le mode de fonctionnement, utilisez la commande de diffusion cphaconf set_ccp.
 Les nœuds de cluster doivent se trouver sur différents hôtes ESXi.
Les nœuds de cluster doivent se trouver sur différents hôtes ESXi. Tout est clair ici: lorsque l'hôte physique tombe, le deuxième nœud continue de fonctionner. Ceci peut être réalisé en utilisant des règles anti-affinité DRS.
Dimensions de la machine virtuelle sur laquelle Check Point s'exécutera. Les recommandations du vendeur sont 2 vCPU et 6 Go, mais cela concerne une configuration minimale, par exemple, si vous avez un pare-feu avec une bande passante minimale. Dans notre expérience de mise en œuvre, lors de l'utilisation de plusieurs lames logicielles, il est conseillé d'utiliser au moins 4 processeurs virtuels, 8 Go de RAM.
Sur un nœud, nous allouons en moyenne 150 Go de disque. Lors du déploiement d'un point de contrôle virtuel, le disque est partitionné et nous pouvons ajuster la quantité d'espace alloué pour l'échange de système, la racine du système, les journaux, la sauvegarde et la mise à niveau.
Lorsque vous augmentez la racine du système, la partition de sauvegarde et de mise à niveau doit également être augmentée afin de conserver la proportion entre elles. Si la proportion n'est pas respectée, la prochaine sauvegarde peut ne pas correspondre au disque.
Provisionnement de disque - Provision épaisse mise à zéro différée. Check Point génère beaucoup d'événements et de journaux, chaque seconde 1000 entrées apparaissent. Sous eux, il vaut mieux réserver une place immédiatement. Pour ce faire, lors de la création d'une machine virtuelle, nous lui allouons un disque à l'aide de la technologie Thick Provisioning, c'est-à-dire nous réservons de l'espace sur le stockage physique au moment de la création du disque.
Réservation de ressources 100% configurée pour Check Point lors de la migration entre les hôtes ESXi. Nous vous recommandons de réserver 100% des ressources afin que la machine virtuelle sur laquelle Check Point est déployé ne soit pas en concurrence pour les ressources avec d'autres machines virtuelles sur l'hôte.
Divers Nous utilisons la version Check Point de R77.30. Pour cela, il est recommandé d'utiliser RedHat Enterprise Linux version 5 (64 bits) comme OS invité sur une machine virtuelle. Depuis les pilotes réseau - VMXNET3 ou Intel E1000.
Paramètres du point de contrôle
Les dernières mises à jour de Check Point sont installées sur les passerelles et le serveur de gestion. Vérifiez les mises à jour via CPUSE.
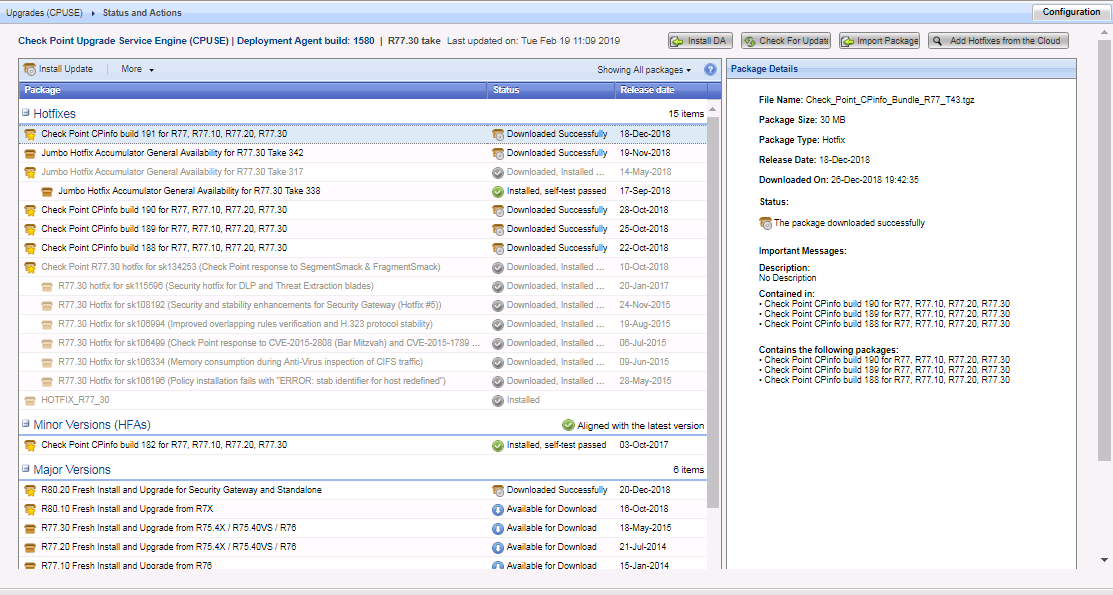
À l'aide de Verifier, nous vérifions que le service pack que nous sommes sur le point d'installer n'est pas en conflit avec le système.

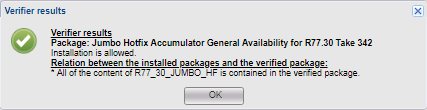
Verifier, bien sûr, est une bonne chose, mais il y a des nuances. Certaines mises à jour ne sont pas compatibles avec le module complémentaire, mais Verifier n'affichera pas ces conflits et autorisera la mise à jour. À la fin de la mise à jour, vous obtiendrez une erreur, et seulement à partir d'elle, vous découvrirez ce qui empêche la mise à jour. Par exemple, cette situation s'est produite avec le service pack MABDA_001 (Mobile Access Blade Deployment Agent), qui résout le problème du lancement du plug-in Java dans des navigateurs autres qu'IE.
Mises à jour quotidiennes de signatures automatiques configurées pour IPS et d'autres lames logicielles. Check Point publie des signatures qui peuvent être utilisées pour détecter ou bloquer de nouvelles vulnérabilités. Les vulnérabilités reçoivent automatiquement un niveau de criticité. Conformément à ce niveau et au filtre défini, le système décide de détecter ou de bloquer la signature. Il est important ici de ne pas en faire trop avec les filtres, de vérifier périodiquement et de faire des ajustements afin que le trafic légitime ne soit pas bloqué.
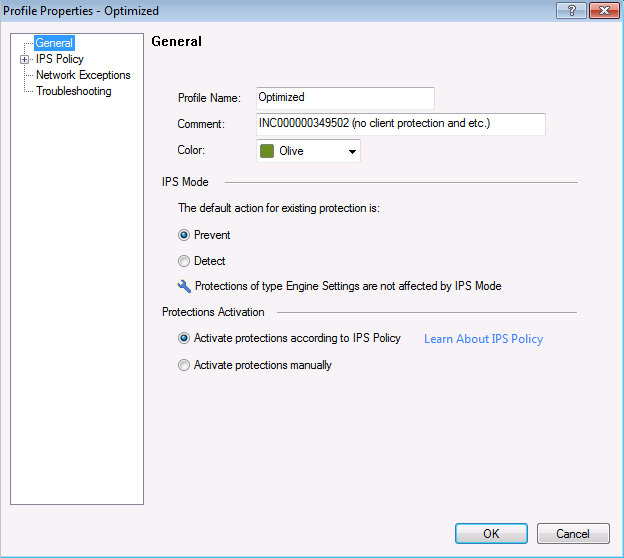 Profil IPS, où nous sélectionnons l'action par rapport à la signature en fonction de ses paramètres.
Profil IPS, où nous sélectionnons l'action par rapport à la signature en fonction de ses paramètres.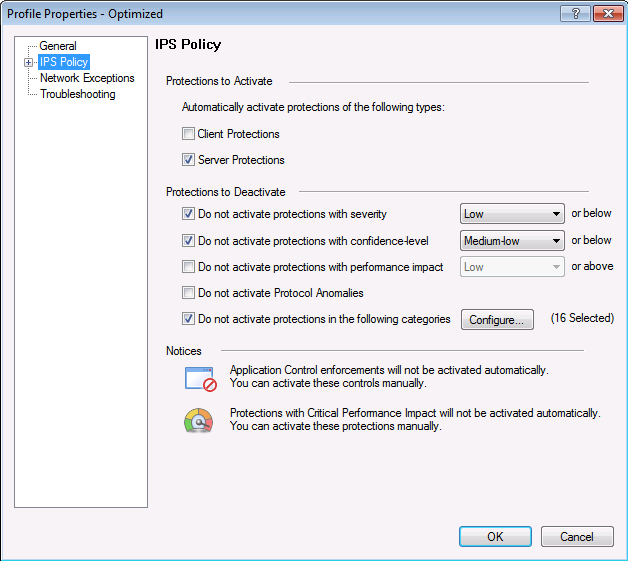 Paramètres de stratégie pour ce profil IPS en fonction des paramètres de signature: niveau de gravité, impact sur les performances, etc.Le matériel Check Point est configuré avec le protocole de synchronisation horaire NTP.
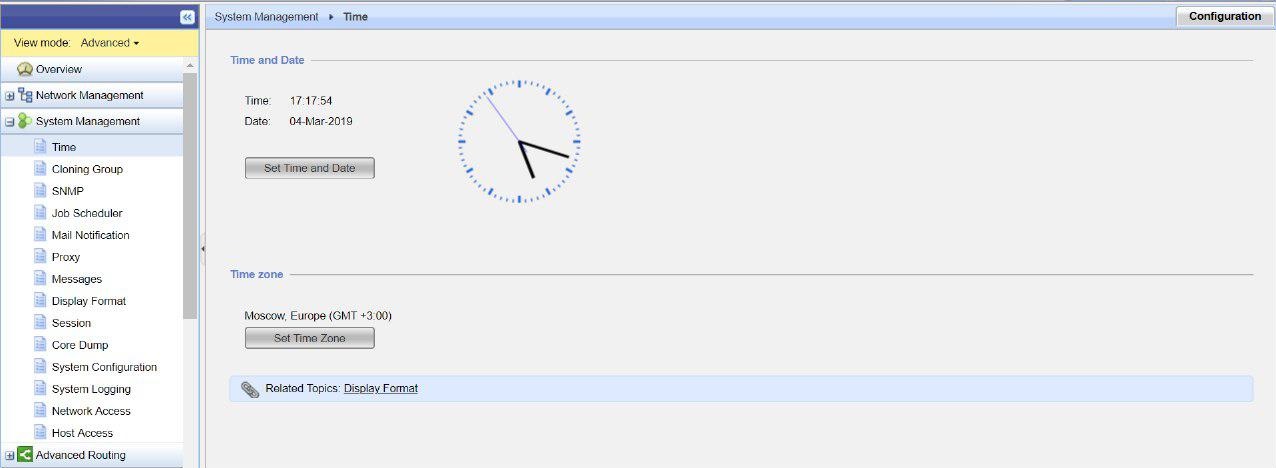
Paramètres de stratégie pour ce profil IPS en fonction des paramètres de signature: niveau de gravité, impact sur les performances, etc.Le matériel Check Point est configuré avec le protocole de synchronisation horaire NTP. Sur la base des
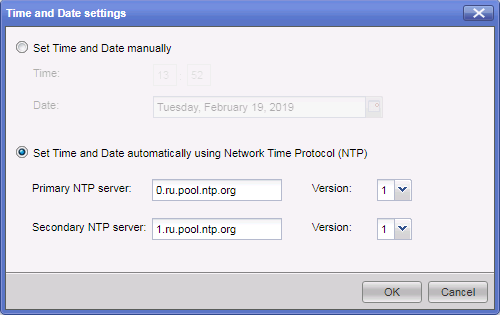
recommandations , Check Point doit utiliser un serveur NTP externe pour synchroniser l'heure sur l'équipement. Cela peut être fait via le portail web gaia.
Une heure mal définie peut entraîner une désynchronisation du cluster. Si le moment est mal choisi, il est extrêmement gênant de rechercher l'entrée de journal qui nous intéresse. Chaque entrée dans les journaux d'événements est marquée d'un soi-disant horodatage.
 Événement intelligent configuré pour les alertes sur IPS, App Control, Anti-Bot, etc.
Événement intelligent configuré pour les alertes sur IPS, App Control, Anti-Bot, etc. Il s'agit d'un module distinct avec sa propre licence. Si vous en avez un, son utilisation est pratique pour visualiser les informations sur le fonctionnement de toutes les lames et périphériques logiciels. Par exemple, les attaques, le nombre d'opérations IPS, le niveau de criticité des menaces, les applications interdites utilisées par les utilisateurs, etc.
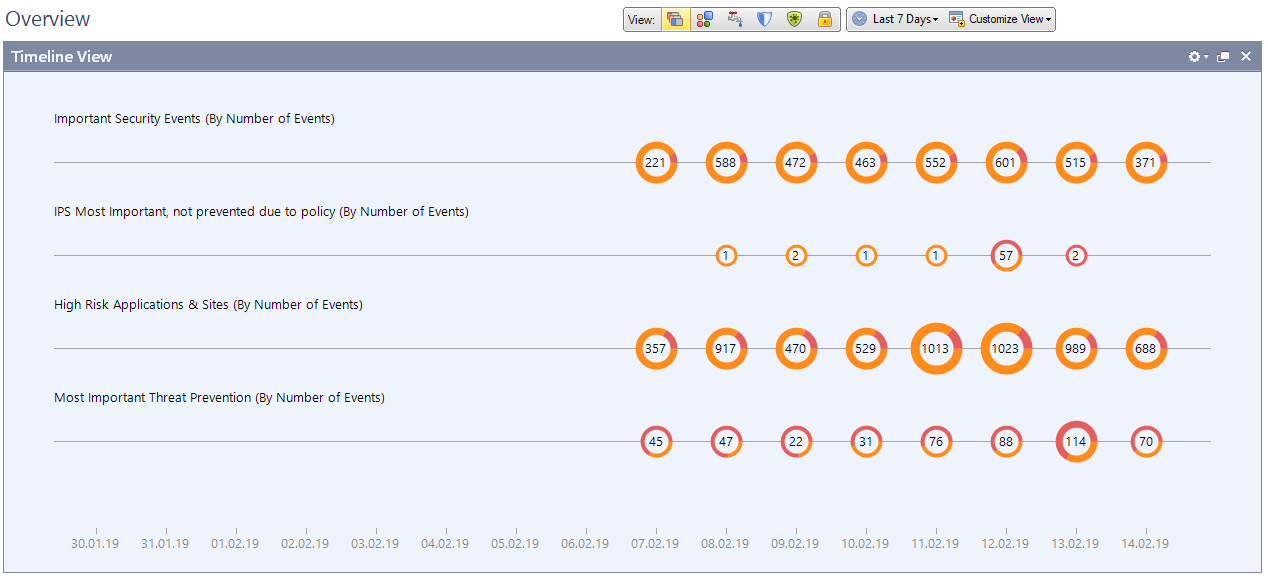
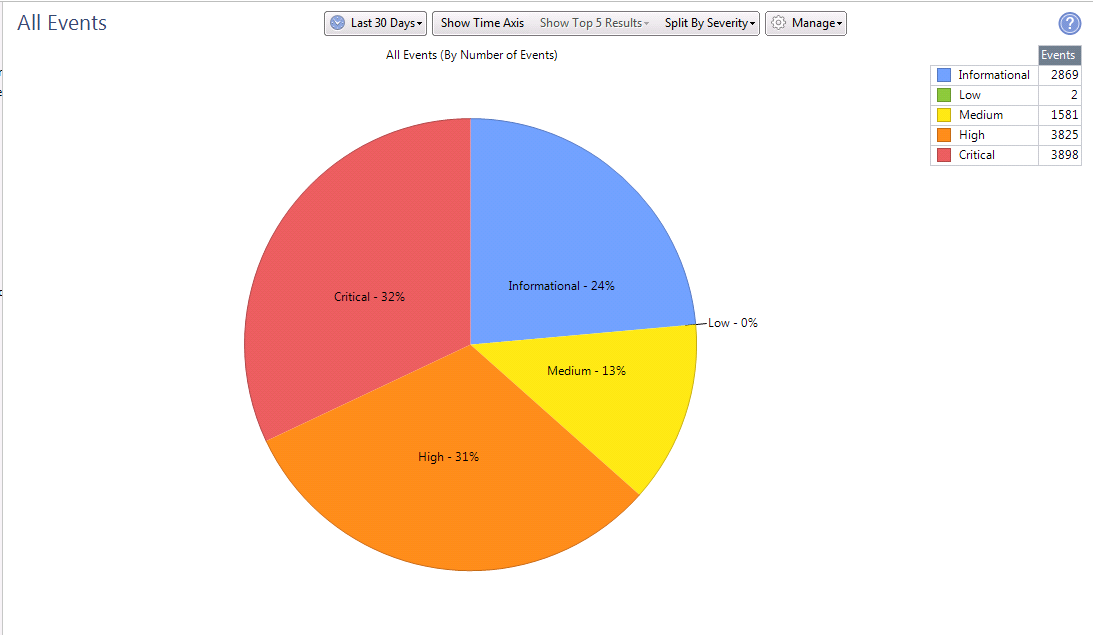 Ce sont des statistiques sur 30 jours selon le nombre de signatures et le degré de criticité.
Ce sont des statistiques sur 30 jours selon le nombre de signatures et le degré de criticité.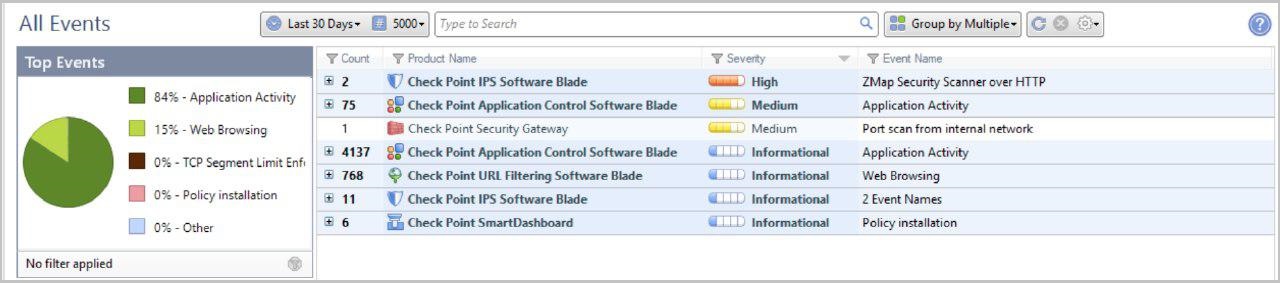 Informations plus détaillées sur les signatures détectées sur chaque lame de logiciel.
Informations plus détaillées sur les signatures détectées sur chaque lame de logiciel.Suivi
Il est important de surveiller au moins les paramètres suivants:
- état du cluster;
- disponibilité des composants Check Point;
- Charge CPU
- espace disque restant;
- mémoire libre.
Check Point dispose d'une lame logicielle distincte - Smart Monitoring (licence distincte). Vous pouvez en outre surveiller la disponibilité des composants Check Point, les charges sur les lames individuelles et les statuts de licence.
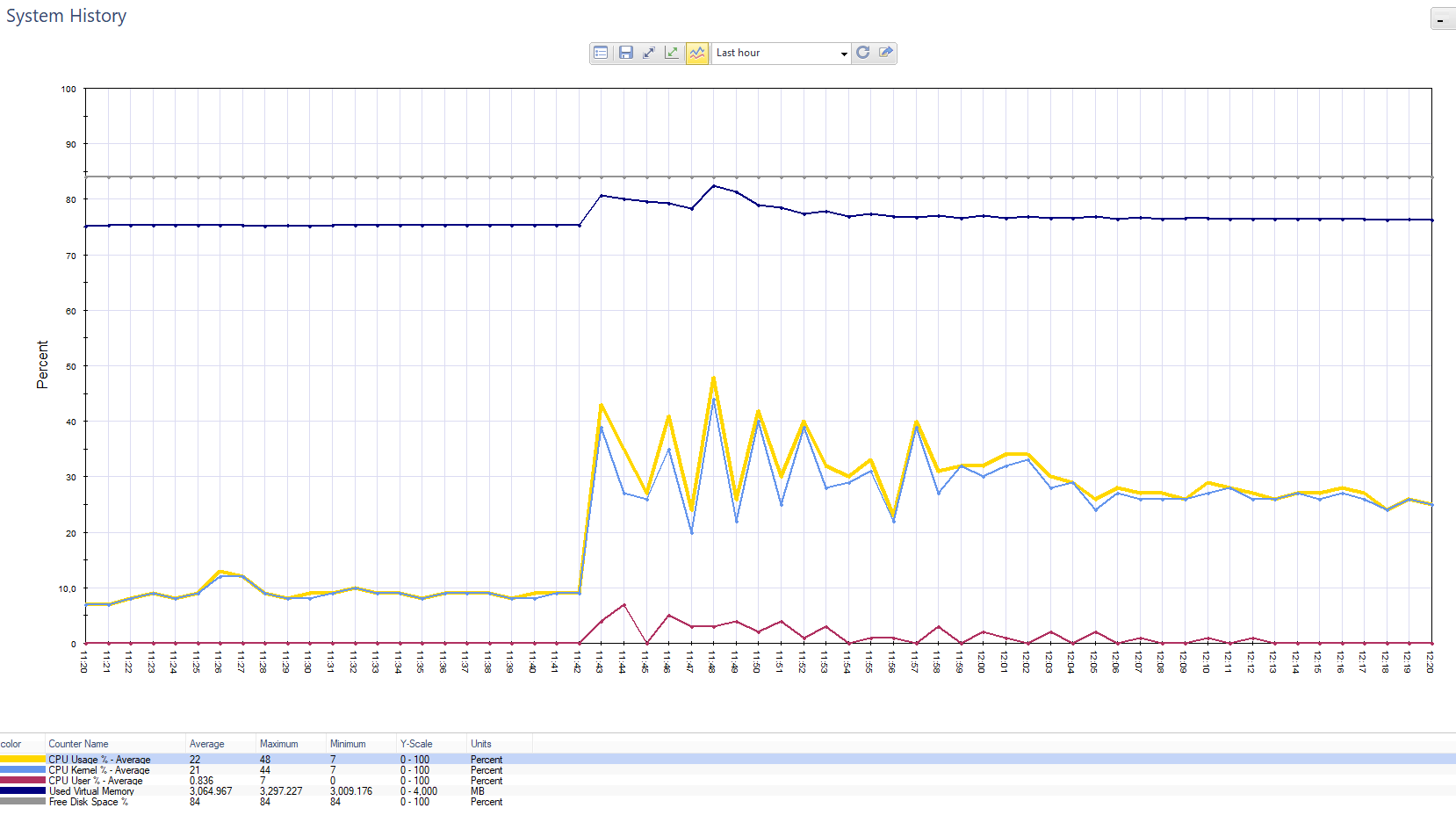 Graphique de charge de Chek Point. Splash - c'est le client qui a envoyé des notifications push à 800 000 clients.
Graphique de charge de Chek Point. Splash - c'est le client qui a envoyé des notifications push à 800 000 clients. Le graphique de la charge sur la lame de pare-feu dans la même situation.
Le graphique de la charge sur la lame de pare-feu dans la même situation.La surveillance peut également être configurée via des services tiers. Par exemple, nous utilisons également Nagios, où nous surveillons:
- disponibilité des équipements sur le réseau;
- Disponibilité des adresses de cluster
- Chargement du processeur par cœurs. Lors du téléchargement de plus de 70%, une alerte e-mail arrive. Une telle charge élevée peut indiquer un trafic spécifique (vpn, par exemple). Si cela se répète souvent, alors il n'y a peut-être pas assez de ressources et cela vaut la peine d'élargir le bassin.
- RAM libre. S'il reste moins de 80%, nous le saurons.
- chargement du disque sur certaines partitions, par exemple var / log. Si elle se bouche rapidement, il est nécessaire de s'étendre.
- Split Brain (au niveau du cluster). Nous surveillons l'état lorsque les deux nœuds deviennent actifs et la synchronisation entre eux disparaît.
- Mode haute disponibilité - nous vérifions que le cluster est en mode veille active. Nous regardons les états des nœuds - actifs, en veille, en panne.
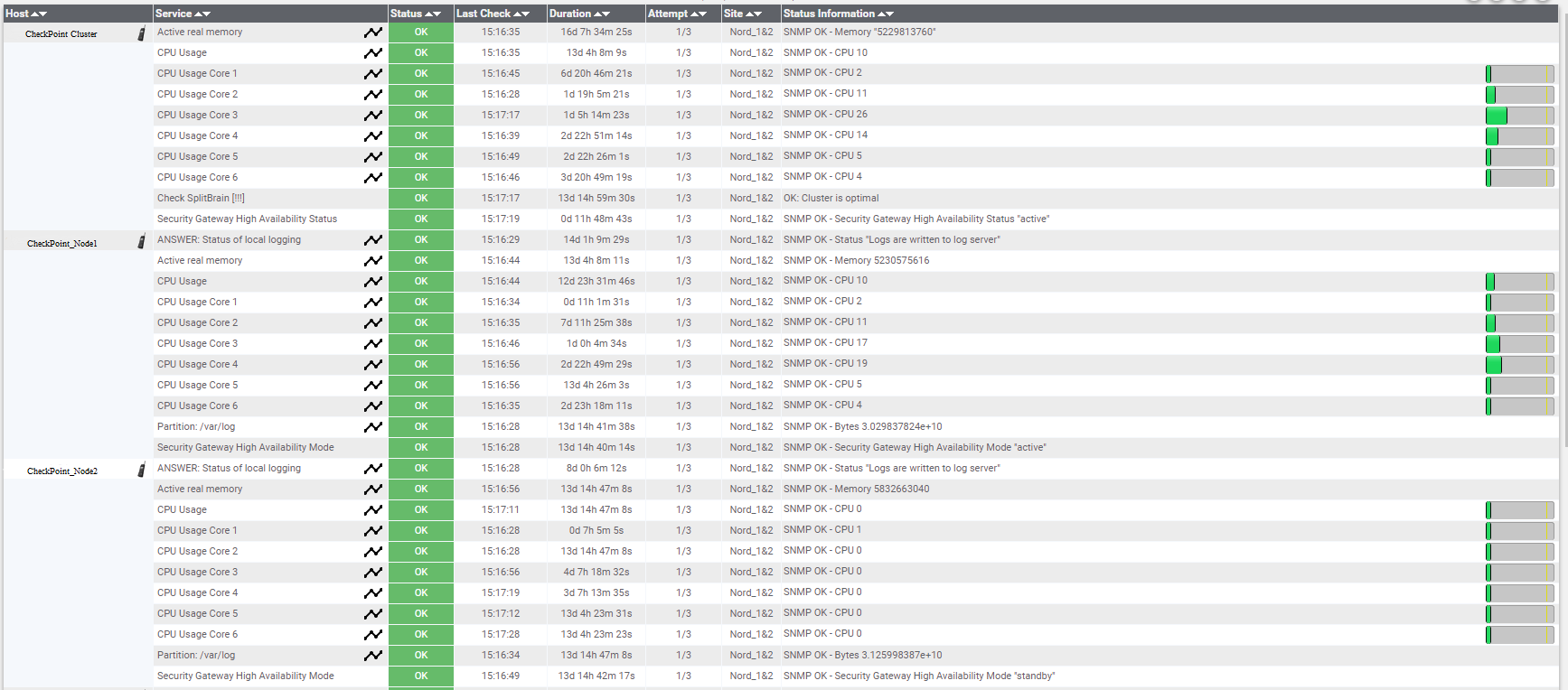 Options de surveillance dans Nagios.
Options de surveillance dans Nagios.Il convient également de surveiller l'état des serveurs physiques sur lesquels les hôtes ESXi sont déployés.
Sauvegarde
Le vendeur lui-même recommande de prendre un instantané immédiatement après l'installation de la mise à jour (Hotfixies).
Selon la fréquence des changements, une sauvegarde complète est configurée une fois par semaine ou par mois. Dans notre pratique, nous effectuons une copie incrémentielle quotidienne des fichiers Check Point et une sauvegarde complète une fois par semaine.
C’est tout. Ce sont les points les plus élémentaires à prendre en compte lors du déploiement de points de contrôle virtuels. Mais même atteindre ce minimum aidera à éviter les problèmes avec leur travail.