
Partie 1/3 ici
Partie 3/3 ici
Bonjour et bienvenue! Il s'agit de la deuxième partie de l'article sur la configuration d'un cluster Kubernetes sur du métal nu. Plus tôt, nous avons configuré le cluster Kubernetes HA à l'aide de etcd externe, maître-maître et équilibrage de charge. Eh bien, il est maintenant temps de configurer un environnement et des utilitaires supplémentaires pour rendre le cluster plus utile et aussi proche que possible de l'état de fonctionnement.
Dans cette partie de l'article, nous nous concentrerons sur la configuration de l'équilibreur de charge interne des services de cluster - ce sera MetalLB. Nous allons également installer et configurer le stockage de fichiers distribué entre nos nœuds de travail. Nous utiliserons GlusterFS pour les volumes persistants disponibles dans Kubernetes.
Après avoir terminé toutes les étapes, notre diagramme de cluster ressemblera à ceci:
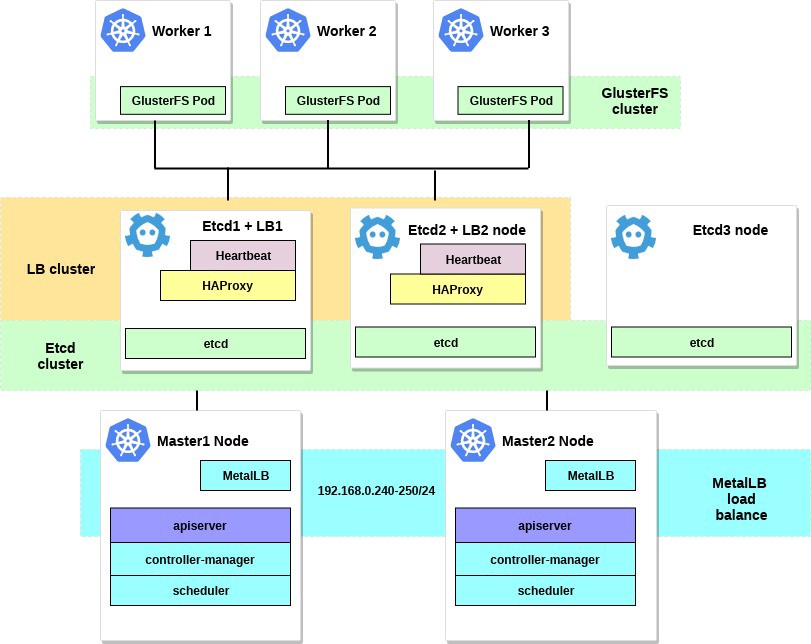
Quelques mots sur MetalLB, directement depuis la page du document:
MetalLB est une implémentation d'équilibreur de charge pour les clusters de métaux nus Kubernetes avec des protocoles de routage standard.
Kubernetes ne propose pas l'implémentation d'équilibreurs de charge réseau ( type de service LoadBalancer ) pour le métal nu. Toutes les options d'implémentation de Network LB fournies par Kubernetes sont des middlewares et accèdent à diverses plates-formes IaaS (GCP, AWS, Azure, etc.). Si vous ne travaillez pas sur une plate-forme prise en charge par IaaS (GCP, AWS, Azure, etc.), le LoadBalancer restera en état de «veille» pendant une période indéfinie lors de sa création.
Les opérateurs de serveurs BM disposent de deux outils moins efficaces pour entrer le trafic utilisateur dans leurs clusters, les services NodePort et externalIPs. Ces deux options présentent des lacunes importantes dans la production, ce qui transforme les grappes BM en citoyens de seconde classe dans l'écosystème Kubernetes.
MetalLB cherche à corriger ce déséquilibre en proposant l'implémentation Network LB, qui s'intègre à l'équipement réseau standard, de sorte que les services externes sur les clusters BM "fonctionnent" à la vitesse maximale.
Ainsi, à l'aide de cet outil, nous lançons des services dans le cluster Kubernetes à l'aide d'un équilibreur de charge, dont un grand merci à l'équipe MetalLB. Le processus d'installation est vraiment simple et direct.
Plus tôt dans l'exemple, nous avons sélectionné le sous-réseau 192.168.0.0/24 pour les besoins de notre cluster. Prenez maintenant une partie de ce sous-réseau pour le futur équilibreur de charge.
Nous entrons dans le système de la machine avec l'utilitaire kubectl configuré et exécutons :
control# kubectl apply -f https://raw.githubusercontent.com/google/metallb/v0.7.3/manifests/metallb.yaml
Cela déploiera MetalLB dans le cluster, dans l' metallb-system . Assurez-vous que tous les composants MetalLB fonctionnent correctement:
control# kubectl get pod --namespace=metallb-system NAME READY STATUS RESTARTS AGE controller-7cc9c87cfb-ctg7p 1/1 Running 0 5d3h speaker-82qb5 1/1 Running 0 5d3h speaker-h5jw7 1/1 Running 0 5d3h speaker-r2fcg 1/1 Running 0 5d3h
Configurez maintenant MetalLB à l'aide de configmap. Dans cet exemple, nous utilisons la personnalisation de la couche 2. Pour plus d'informations sur les autres options de personnalisation, consultez la documentation MetalLB.
Créez le fichier metallb-config.yaml dans n'importe quel répertoire à l'intérieur de la plage IP sélectionnée du sous-réseau de notre cluster:
control# vi metallb-config.yaml apiVersion: v1 kind: ConfigMap metadata: namespace: metallb-system name: config data: config: | address-pools: - name: default protocol: layer2 addresses: - 192.168.0.240-192.168.0.250
Et appliquez ce paramètre:
control# kubectl apply -f metallb-config.yaml
Vérifiez et modifiez configmap plus tard si nécessaire:
control# kubectl describe configmaps -n metallb-system control# kubectl edit configmap config -n metallb-system
Nous avons maintenant notre propre équilibreur de charge local configuré. Voyons comment cela fonctionne, en utilisant le service Nginx comme exemple.
control# vi nginx-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80 control# vi nginx-service.yaml apiVersion: v1 kind: Service metadata: name: nginx spec: type: LoadBalancer selector: app: nginx ports: - port: 80 name: http
Créez ensuite un déploiement de test et un service Nginx:
control# kubectl apply -f nginx-deployment.yaml control# kubectl apply -f nginx-service.yaml
Et maintenant - vérifiez le résultat:
control# kubectl get po NAME READY STATUS RESTARTS AGE nginx-deployment-6574bd76c-fxgxr 1/1 Running 0 19s nginx-deployment-6574bd76c-rp857 1/1 Running 0 19s nginx-deployment-6574bd76c-wgt9n 1/1 Running 0 19s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx LoadBalancer 10.100.226.110 192.168.0.240 80:31604/TCP 107s
Créé 3 pods Nginx, comme nous l'avons indiqué dans le déploiement plus tôt. Le service Nginx dirigera le trafic vers tous ces pods selon le schéma d'équilibrage cyclique. Et vous pouvez également voir l'adresse IP externe reçue de notre équilibreur de charge MetalLB.
Essayez maintenant de passer à l'adresse IP 192.168.0.240 et vous verrez la page Nginx index.html. N'oubliez pas de supprimer le déploiement de test et le service Nginx.
control# kubectl delete svc nginx service "nginx" deleted control# kubectl delete deployment nginx-deployment deployment.extensions "nginx-deployment" deleted
Eh bien, c'est tout avec MetalLB, passons à autre chose - nous allons configurer GlusterFS pour les volumes Kubernetes.
2. Configuration de GlusterFS avec Heketi sur les nœuds de travail.
En fait, le cluster Kubernetes ne peut pas être utilisé sans volumes à l'intérieur. Comme vous le savez, les foyers sont éphémères, c'est-à-dire ils peuvent être créés et supprimés à tout moment. Toutes les données qu'elles contiennent seront perdues. Ainsi, dans un véritable cluster, un stockage distribué est nécessaire pour assurer l'échange de paramètres et de données entre les nœuds et les applications qu'il contient.
Dans Kubernetes, les volumes sont disponibles de différentes manières; choisissez ceux que vous souhaitez. Dans cet exemple, je vais montrer comment créer un stockage GlusterFS pour toutes les applications internes, c'est comme des volumes persistants. Plus tôt, j'ai utilisé l'installation «système» de GlusterFS sur tous les nœuds de travail Kubernetes pour cela, puis j'ai simplement créé des volumes comme hostPath dans les répertoires GlusterFS.
Nous avons maintenant un nouvel outil Heketi pratique.
Quelques mots de la documentation Heketi:
Infrastructure de gestion de volume RESTful pour GlusterFS.
Heketi propose une interface de gestion RESTful qui peut être utilisée pour gérer le cycle de vie des volumes GlusterFS. Grâce à Heketi, les services cloud tels que OpenStack Manila, Kubernetes et OpenShift peuvent fournir dynamiquement des volumes GlusterFS avec tout type de fiabilité pris en charge. Heketi détermine automatiquement l'emplacement des blocs dans un cluster, en fournissant l'emplacement des blocs et de leurs répliques dans différentes zones de défaillance. Heketi prend également en charge un nombre illimité de clusters GlusterFS, permettant aux services cloud d'offrir un stockage de fichiers en ligne, et pas seulement un seul cluster GlusterFS.
Cela semble bon et, en outre, cet outil rapprochera notre cluster de machines virtuelles des grands clusters de cloud de Kubernetes. À la fin, vous pourrez créer des PersistentVolumeClaims , qui seront générés automatiquement, et bien plus encore.
Vous pouvez prendre des disques durs système supplémentaires pour configurer GlusterFS ou simplement créer des périphériques de blocs factices. Dans cet exemple, j'utiliserai la deuxième méthode.
Créez des dispositifs de blocs factices sur les trois nœuds de travail:
worker1-3# dd if=/dev/zero of=/home/gluster/image bs=1M count=10000
Vous obtiendrez un fichier d'environ 10 Go. Utilisez ensuite losetup - pour l'ajouter à ces nœuds, en tant que périphérique de bouclage:
worker1-3# losetup /dev/loop0 /home/gluster/image
Remarque: si vous possédez déjà une sorte de périphérique de bouclage 0, vous devrez choisir un autre numéro.
J'ai pris le temps et j'ai découvert pourquoi Heketi ne voulait pas fonctionner correctement. Par conséquent, pour éviter tout problème dans les configurations futures, assurez-vous d'abord que nous avons chargé le module du noyau dm_thin_pool et installé le package glusterfs-client sur tous les nœuds de travail.
worker1-3# modprobe dm_thin_pool worker1-3# apt-get update && apt-get -y install glusterfs-client
Eh bien, vous avez maintenant besoin que le fichier / home / gluster / image et le périphérique / dev / loop0 soient présents sur tous les nœuds de travail. N'oubliez pas de créer un service systemd qui démarrera automatiquement losetup et modprobe à chaque démarrage de ces serveurs.
worker1-3# vi /etc/systemd/system/loop_gluster.service [Unit] Description=Create the loopback device for GlusterFS DefaultDependencies=false Before=local-fs.target After=systemd-udev-settle.service Requires=systemd-udev-settle.service [Service] Type=oneshot ExecStart=/bin/bash -c "modprobe dm_thin_pool && [ -b /dev/loop0 ] || losetup /dev/loop0 /home/gluster/image" [Install] WantedBy=local-fs.target
Et allumez-le:
worker1-3# systemctl enable /etc/systemd/system/loop_gluster.service Created symlink /etc/systemd/system/local-fs.target.wants/loop_gluster.service → /etc/systemd/system/loop_gluster.service.
Les travaux préparatoires sont terminés et nous sommes prêts à déployer GlusterFS et Heketi dans notre cluster. Pour cela, j'utiliserai ce guide sympa. La plupart des commandes sont lancées à partir d'un ordinateur de contrôle externe, et de très petites commandes sont lancées à partir de n'importe quel nœud maître du cluster.
Tout d'abord, copiez le référentiel et créez DaemonSet GlusterFS:
control# git clone https://github.com/heketi/heketi control# cd heketi/extras/kubernetes control# kubectl create -f glusterfs-daemonset.json
Maintenant, marquons nos trois nœuds de travail pour GlusterFS; après les avoir étiquetés, des pods GlusterFS seront créés:
control# kubectl label node worker1 storagenode=glusterfs control# kubectl label node worker2 storagenode=glusterfs control# kubectl label node worker3 storagenode=glusterfs control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 1m6s glusterfs-hzdll 1/1 Running 0 1m9s glusterfs-p8r59 1/1 Running 0 2m1s
Créez maintenant un compte de service Heketi:
control# kubectl create -f heketi-service-account.json
Nous offrons à ce compte de service la possibilité de gérer les modules Gluster. Pour ce faire, créez une fonction de cluster requise pour notre compte de service nouvellement créé:
control# kubectl create clusterrolebinding heketi-gluster-admin --clusterrole=edit --serviceaccount=default:heketi-service-account
Créons maintenant une clé secrète Kubernetes qui bloque la configuration de notre instance Heketi:
control# kubectl create secret generic heketi-config-secret --from-file=./heketi.json
Créez la première source sous Heketi, que nous utilisons pour les premières opérations de configuration et supprimez ensuite:
control# kubectl create -f heketi-bootstrap.json service "deploy-heketi" created deployment "deploy-heketi" created control# kubectl get pod NAME READY STATUS RESTARTS AGE deploy-heketi-1211581626-2jotm 1/1 Running 0 2m glusterfs-5dtdj 1/1 Running 0 6m6s glusterfs-hzdll 1/1 Running 0 6m9s glusterfs-p8r59 1/1 Running 0 7m1s
Après avoir créé et démarré le service Bootstrap Heketi, nous devrons basculer vers l'un de nos nœuds principaux, là nous exécuterons plusieurs commandes, car notre nœud de contrôle externe n'est pas à l'intérieur de notre cluster, nous ne pouvons donc pas accéder aux pods de travail et au réseau interne du cluster.
Tout d'abord, téléchargeons l'utilitaire heketi-client et copions-le dans le dossier système bin:
master1# wget https://github.com/heketi/heketi/releases/download/v8.0.0/heketi-client-v8.0.0.linux.amd64.tar.gz master1# tar -xzvf ./heketi-client-v8.0.0.linux.amd64.tar.gz master1# cp ./heketi-client/bin/heketi-cli /usr/local/bin/ master1# heketi-cli heketi-cli v8.0.0
Trouvez maintenant l'adresse IP du pod heketi et exportez-la en tant que variable système:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf describe pod deploy-heketi-1211581626-2jotm For me this pod have a 10.42.0.1 ip master1# curl http://10.42.0.1:57598/hello Handling connection for 57598 Hello from Heketi master1# export HEKETI_CLI_SERVER=http://10.42.0.1:57598
Fournissons maintenant à Heketi des informations sur le cluster GlusterFS qu'il doit gérer. Nous le fournissons via un fichier de topologie. Une topologie est un manifeste JSON avec une liste de tous les nœuds, disques et clusters utilisés par GlusterFS.
REMARQUE Assurez-vous que hostnames/manage indique le nom exact, comme dans la section kubectl get node , et que hostnames/storage est l'adresse IP des nœuds de stockage.
master1:~/heketi-client# vi topology.json { "clusters": [ { "nodes": [ { "node": { "hostnames": { "manage": [ "worker1" ], "storage": [ "192.168.0.7" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker2" ], "storage": [ "192.168.0.8" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker3" ], "storage": [ "192.168.0.9" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] } ] } ] }
Téléchargez ensuite ce fichier:
master1:~/heketi-client# heketi-cli topology load --json=topology.json Creating cluster ... ID: e83467d0074414e3f59d3350a93901ef Allowing file volumes on cluster. Allowing block volumes on cluster. Creating node worker1 ... ID: eea131d392b579a688a1c7e5a85e139c Adding device /dev/loop0 ... OK Creating node worker2 ... ID: 300ad5ff2e9476c3ba4ff69260afb234 Adding device /dev/loop0 ... OK Creating node worker3 ... ID: 94ca798385c1099c531c8ba3fcc9f061 Adding device /dev/loop0 ... OK
Ensuite, nous utilisons Heketi pour fournir des volumes pour le stockage de la base de données. Le nom de l'équipe est un peu étrange, mais tout est en ordre. Créez également un référentiel heketi:
master1:~/heketi-client# heketi-cli setup-openshift-heketi-storage master1:~/heketi-client# kubectl --kubeconfig /etc/kubernetes/admin.conf create -f heketi-storage.json secret/heketi-storage-secret created endpoints/heketi-storage-endpoints created service/heketi-storage-endpoints created job.batch/heketi-storage-copy-job created
Ce sont toutes les commandes dont vous avez besoin pour exécuter à partir du nœud maître. Revenons au nœud de contrôle et continuons à partir de là; Tout d'abord, assurez-vous que la dernière commande en cours d'exécution a été exécutée avec succès:
control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-storage-copy-job-txkql 0/1 Completed 0 69s
Et le travail heketi-storage-copy-job est terminé.
S'il n'y a actuellement aucun package glusterfs-client installé sur vos nœuds de travail, une erreur se produit.
Il est temps de supprimer le fichier d'installation de Heketi Bootstrap et de faire un petit nettoyage:
control# kubectl delete all,service,jobs,deployment,secret --selector="deploy-heketi"
À la dernière étape, nous devons créer une copie à long terme de Heketi:
control# cd ./heketi/extras/kubernetes control:~/heketi/extras/kubernetes# kubectl create -f heketi-deployment.json secret/heketi-db-backup created service/heketi created deployment.extensions/heketi created control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-b8c5f6554-knp7t 1/1 Running 0 22m
S'il n'y a actuellement aucun package glusterfs-client installé sur vos nœuds de travail, une erreur se produit. Et nous avons presque terminé, maintenant la base de données Heketi est stockée dans le volume GlusterFS et n'est pas réinitialisée à chaque redémarrage du foyer Heketi.
Pour commencer à utiliser le cluster GlusterFS avec l'allocation dynamique des ressources, nous devons créer un StorageClass.
Tout d'abord, trouvons le point de terminaison de stockage Gluster, qui sera transmis à StorageClass en tant que paramètre (heketi-storage-endpoints):
control# kubectl get endpoints NAME ENDPOINTS AGE heketi 10.42.0.2:8080 2d16h ....... ... ..
Créez maintenant des fichiers:
control# vi storage-class.yml apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: slow provisioner: kubernetes.io/glusterfs parameters: resturl: "http://10.42.0.2:8080" control# vi test-pvc.yml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: gluster1 annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi
Utilisez ces fichiers pour créer de la classe et du PVC:
control# kubectl create -f storage-class.yaml storageclass "slow" created control# kubectl get storageclass NAME PROVISIONER AGE slow kubernetes.io/glusterfs 2d8h control# kubectl create -f test-pvc.yaml persistentvolumeclaim "gluster1" created control# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE gluster1 Bound pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO slow 2d8h
On peut également visualiser le volume PV:
control# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO Delete Bound default/gluster1 slow 2d8h
Nous avons maintenant un volume GlusterFS créé dynamiquement associé à PersistentVolumeClaim , et nous pouvons utiliser cette instruction dans n'importe quel sous-tracé.
Créez-en un simple sous Nginx et testez-le:
control# vi nginx-test.yml apiVersion: v1 kind: Pod metadata: name: nginx-pod1 labels: name: nginx-pod1 spec: containers: - name: nginx-pod1 image: gcr.io/google_containers/nginx-slim:0.8 ports: - name: web containerPort: 80 volumeMounts: - name: gluster-vol1 mountPath: /usr/share/nginx/html volumes: - name: gluster-vol1 persistentVolumeClaim: claimName: gluster1 control# kubectl create -f nginx-test.yaml pod "nginx-pod1" created
Naviguez sous (attendez quelques minutes, vous devrez peut-être télécharger l'image si elle n'existe pas déjà):
control# kubectl get pods NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 4d10h glusterfs-hzdll 1/1 Running 0 4d10h glusterfs-p8r59 1/1 Running 0 4d10h heketi-b8c5f6554-knp7t 1/1 Running 0 2d18h nginx-pod1 1/1 Running 0 47h
Maintenant, allez dans le conteneur et créez le fichier index.html:
control# kubectl exec -ti nginx-pod1 /bin/sh # cd /usr/share/nginx/html # echo 'Hello there from GlusterFS pod !!!' > index.html # ls index.html # exit
Vous devrez trouver l'adresse IP interne du foyer et vous y recourber à partir de n'importe quel nœud maître:
master1# curl 10.40.0.1 Hello there from GlusterFS pod !!!
Ce faisant, nous testons simplement notre nouveau volume persistant.
Certaines commandes utiles pour extraire le nouveau cluster GlusterFS sont: la heketi-cli cluster list heketi-cli volume list . Ils peuvent être exécutés sur votre ordinateur si heketi-cli est installé . Dans cet exemple, il s'agit du nœud master1 .
master1# heketi-cli cluster list Clusters: Id:e83467d0074414e3f59d3350a93901ef [file][block] master1# heketi-cli volume list Id:6fdb7fef361c82154a94736c8f9aa53e Cluster:e83467d0074414e3f59d3350a93901ef Name:vol_6fdb7fef361c82154a94736c8f9aa53e Id:c6b69bd991b960f314f679afa4ad9644 Cluster:e83467d0074414e3f59d3350a93901ef Name:heketidbstorage
À ce stade, nous avons réussi à mettre en place un équilibreur de charge interne avec stockage de fichiers, et notre cluster est maintenant plus proche de l'état opérationnel.
Dans la prochaine partie de l'article, nous nous concentrerons sur la création d'un système de surveillance de cluster et lancerons également un projet de test pour utiliser toutes les ressources que nous avons configurées.
Restez en contact et tout le meilleur!