Dans cet article, je parlerai des mines posées sous la performance, ainsi que de leur détection (de préférence avant l'explosion) et de leur élimination.
Une image pour attirer l'attention Qu'est-ce qu'une mine?
Commençons par ce qui est à l'origine de toute connaissance - avec définition. Les anciens ont dit que nommer correctement signifie comprendre correctement. Je pense que la définition d'une mine en performance est mieux exprimée en la contrastant avec une erreur évidente, par exemple, ceci:
String concat(String... strings) { String result = ""; for (String str : strings) { result += str; } return result; }
Même les développeurs débutants savent que les lignes sont immuables, et les coller ensemble dans une boucle ne signifie pas ajouter des données à la queue d'une ligne existante, mais créer une nouvelle ligne à chaque passage. Si vous vous trompez, ne vous découragez pas - l '«Idée» vous avertira immédiatement du danger, et le «Sonar» inondera sûrement votre assemblée.
Mais ce code attirera beaucoup moins d'attention, et l'idée ( avant la version 2018.2 ) sera silencieuse:
Long total = 0L; List<Long> totals = query.getResultList(); for (Long element : totals) { total += element == null ? 0 : element; }
Le problème ici est le même: les wrappers pour les types simples sont immuables, ce qui signifie ajouter 5 unités au numéro d'objet signifie créer un nouveau wrapper et y écrire le numéro 6.
La plaisanterie ici est la présence en Java de deux représentations de certains types de données - simple et objet, ainsi que leur transformation automatique au moyen du langage lui-même. Pour cette raison, de nombreux développeurs novices pensent quelque chose comme ceci: "Eh bien, l'exécution les transforme en quelque sorte par lui-même, c'est juste un nombre."
En fait, tout n'est pas si simple. Prenez la référence et essayez d'ajouter les nombres de la manière spécifiée:
Tout à coup, il est sorti très, très bon marché (ci-après JDK 11, sauf indication contraire explicite) (size) Mode Cnt Score Error Units wrapper 10 avgt 100 23,5 ± 0,1 ns/op wrapper 100 avgt 100 352,3 ± 2,1 ns/op wrapper 1000 avgt 100 4424,5 ± 25,2 ns/op wrapper 10 avgt 100 0 ± 0 B/op wrapper 100 avgt 100 1872 ± 0 B/op wrapper 1000 avgt 100 23472 ± 0 B/op
Comparez avec un type simple:
primitive 10 avgt 100 6,4 ± 0,0 ns/op primitive 100 avgt 100 39,8 ± 0,1 ns/op primitive 1000 avgt 100 252,5 ± 1,3 ns/op primitive 10 avgt 100 0 ± 0 B/op primitive 100 avgt 100 0 ± 0 B/op primitive 1000 avgt 100 0 ± 0 B/op
De là, nous dérivons l'une des définitions des mines en cours de performance - c'est un code qui n'attire pas l'attention, n'est pas détecté (au moins au moment où vous l'avez rencontré) par des analyseurs statiques, mais il peut ralentir dans certaines utilisations. Dans notre cas, alors que la somme ne dépasse pas 127 objets sont extraits du cache et Long que 4 fois plus lent que long . Cependant, pour un tableau de taille 100, la vitesse est presque 10 fois inférieure.
De grandes petites choses
Parfois, un petit changement, qui ne change presque pas le sens de l'exécution, devient dans certains cas un frein puissant.
Supposons que nous ayons un code:
À quoi ressemble la logique de la méthode?
Ne vous précipitez pas pour espionner, pensezC'est ConcurrentHashMap::computeIfAbsent !
Nous avons le "huit" et nous pouvons améliorer le code en toute tranquillité: remplacez 6 lignes par une, ce qui rend le code plus court et plus facile à comprendre. Soit dit en passant, les connaisseurs du multithreading indiqueront probablement une autre amélioration apportée par ConcurrentHashMap::computeIfAbsent , mais à ce sujet un peu plus tard;)
Réalisons une grande pensée:
Rassemblé, commencé, pleuréPour voir la taille réelle, faites un clic droit sur l'image et sélectionnez "Ouvrir l'image dans un nouvel onglet"
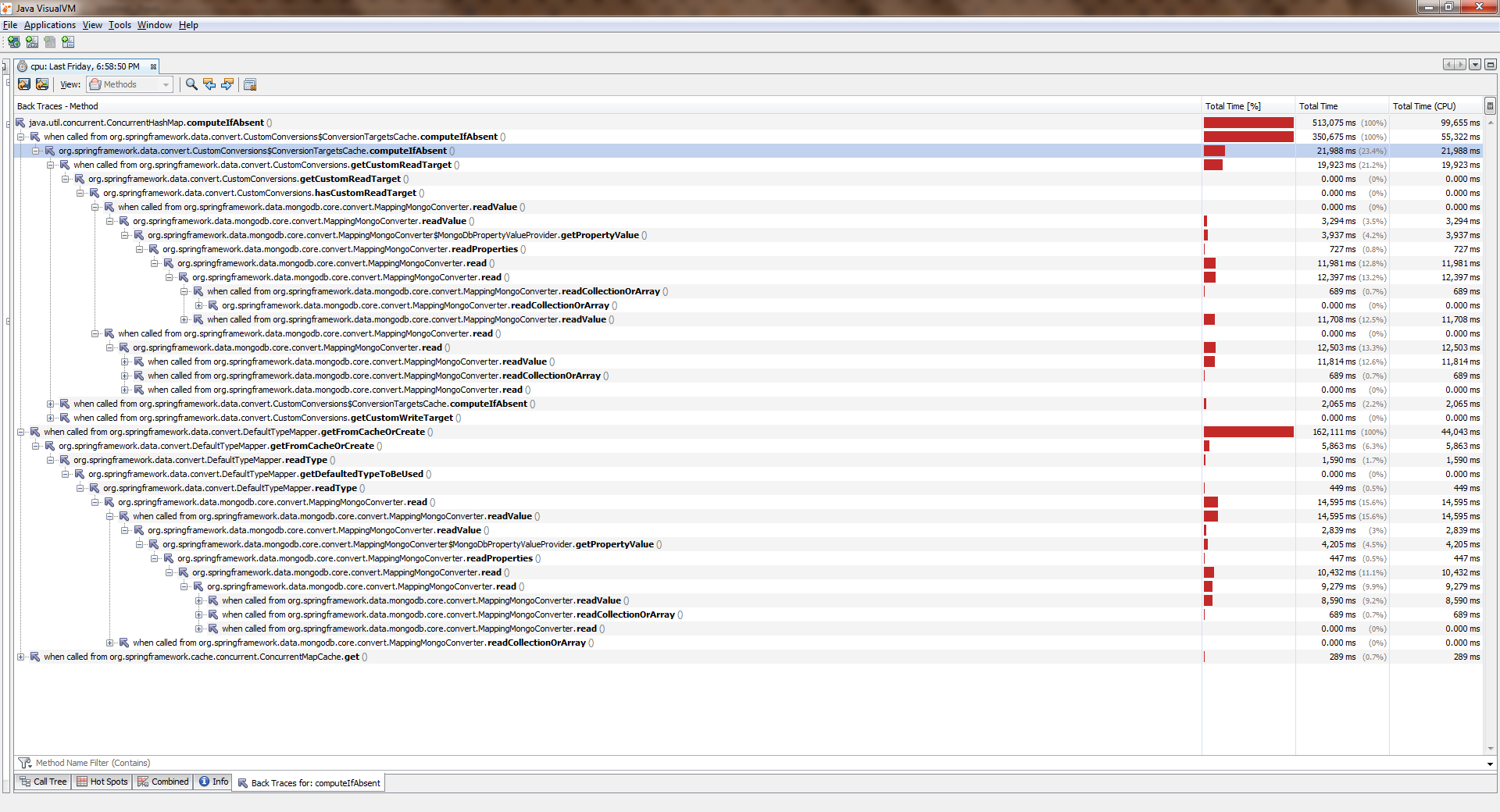
Alors que l'application fonctionnait avec un seul thread, tout était plus ou moins bon. Les flux sont devenus plus nombreux et sont devenus nettement pires. Il ConcurrentHashMap::computeIfAbsent avéré que ConcurrentHashMap::computeIfAbsent bloqué, même si la clé a déjà été ajoutée au dictionnaire . Et cela est devenu la raison de tout un bug dans Spring Date Mongo.
Vous pouvez le vérifier avec une simple mesure ("huit"). Voici sa conclusion:
Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 19,405 ± 0,411 ns/op getAndPut avgt 20 4,578 ± 0,045 ns/op 2 threads computeIfAbsent avgt 20 66,492 ± 2,036 ns/op getAndPut avgt 20 4,454 ± 0,110 ns/op 4 threads computeIfAbsent avgt 20 155,975 ± 8,850 ns/op getAndPut avgt 20 5,616 ± 2,073 ns/op 6 threads computeIfAbsent avgt 20 203,188 ± 10,547 ns/op getAndPut avgt 20 7,024 ± 0,456 ns/op 8 threads computeIfAbsent avgt 20 302,036 ± 31,702 ns/op getAndPut avgt 20 7,990 ± 0,144 ns/op
Cela peut-il être clairement considéré comme une erreur par les développeurs? À mon humble avis, non, non. La documentation dit:
Certaines opérations de mise à jour tentées sur cette carte par d'autres threads peuvent être bloquées pendant le calcul, donc le calcul doit être court et simple, et ne doit pas tenter de mettre à jour d'autres mappages de cette carte
En d'autres termes, ConcurrentHashMap::computeIfAbsent ferme la cellule contenant la clé du monde extérieur (contrairement à ConcurrentHashMap::get ), ce qui est généralement vrai, car il vous permet d'esquiver la course tout en appelant la méthode à partir de différents threads lorsque la clé n'a pas encore été ajoutée.
En revanche, dans le mode de fonctionnement le plus courant, le calcul de la valeur et sa liaison avec la clé ne se produisent qu'au premier appel, et tous les appels suivants ne renvoient que la valeur précédemment calculée. Par conséquent, il est logique de modifier la logique de sorte que le verrou ne soit défini que lors du changement. Cela a été fait ici .
Dans les éditions plus récentes (> 8), ConcurrentHashMap::computeIfAbsent devenu ConcurrentHashMap::computeIfAbsent :
JDK 11 Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 6,983 ± 0,066 ns/op getAndPut avgt 20 5,291 ± 1,220 ns/op 2 threads computeIfAbsent avgt 20 7,173 ± 0,249 ns/op getAndPut avgt 20 5,118 ± 0,395 ns/op 4 threads computeIfAbsent avgt 20 7,991 ± 0,447 ns/op getAndPut avgt 20 5,270 ± 0,366 ns/op 6 threads computeIfAbsent avgt 20 11,919 ± 0,865 ns/op getAndPut avgt 20 7,249 ± 0,199 ns/op 8 threads computeIfAbsent avgt 20 14,360 ± 0,892 ns/op getAndPut avgt 20 8,511 ± 0,229 ns/op
Faites attention à l'insidiosité de cet exemple: le contenu sémantique n'a pas beaucoup changé, car à première vue nous venons d'utiliser une syntaxe plus avancée. Dans le même temps, alors que l'application s'exécute sur un seul thread, l'utilisateur ne sent presque pas la différence! Voilà comment des changements apparemment inoffensifs le cochon le mien sous notre performance.
Pourquoi j'ai écrit «presque inchangé»ConcurrentHashMap::computeIfAbsent pas toujours interchangeable avec l'expression getAndPut , car ConcurrentHashMap::computeIfAbsent est une opération atomique. Dans le même code
private TypeInformation<?> getFromCacheOrCreate(Alias alias) { TypeInformation<?> info = cache.get(alias); if (info == null) { info = getAlias.apply(alias); cache.put(alias, info); } return info; }
en raison du manque de synchronisation externe , une course apparaît . Si la fonction passée à ConcurrentHashMap::computeIfAbsent pour la clé donnée retourne toujours la même valeur, alors c'est une course "sûre", le plus auquel nous sommes confrontés est de calculer la même valeur 2 fois ou plus. S'il n'y a pas de telles garanties, le remplacement mécanique est lourd d'échec de l'application. Faites attention!
Ces mains n'ont rien changé
Il arrive aussi que le code ne change pas du tout, mais soudain, il commence à ralentir.
Imaginez que nous sommes confrontés à la tâche de déplacer des éléments de tableau dans une collection. Le plus logique serait d'utiliser la Collection::addAll prête à l'emploi, mais voici la malchance - elle accepte la collection:
public interface Collection<E> extends Iterable<E> { boolean addAll(Collection<? extends E> c); }
Le moyen le plus simple consiste à encapsuler le tableau dans Arrays::asList . Il en résultera quelque chose comme
boolean addItems(Collection<T> collection) { T[] items = getArray(); return collection.addAll(Arrays.asList(items)); }
Lors de la relecture, des collègues soucieux de performances nous diront probablement qu'il y a deux problèmes dans ce code à la fois:
- encapsuler un tableau dans une liste (objet supplémentaire)
- créer un itérateur (un autre objet supplémentaire) et le traverser
En fait, dans l'implémentation de référence de Collection::addAll nous verrons ceci:
public abstract class AbstractCollection<E> implements Collection<E> { public boolean addAll(Collection<? extends E> c) { boolean modified = false; for (E e : c) { if (add(e)) modified = true; } return modified; } }
Un itérateur est donc créé ici et les éléments sont triés à l'aide de celui-ci. Par conséquent, des camarades expérimentés proposent leur solution:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
A l'intérieur du code, semblant à juste titre plus productif:
public static <T> boolean addAll(Collection<? super T> c, T... elements) { boolean result = false; for (T element : elements) result |= c.add(element); return result; }
Tout d'abord, un itérateur n'est pas créé. Deuxièmement, la passe se déroule dans le cycle de comptage habituel, en outre, les tableaux s'intègrent bien dans les caches, ses éléments sont situés en mémoire de manière séquentielle (ce qui signifie qu'il y aura peu de ratés de cache), et leur accès par index est très rapide. Eh bien, une liste d'encapsuleurs n'est pas créée non plus. Ça sonne bien et sain.
Enfin, mes collègues citent ultima ratio regum: documentation. Et là, gris sur blanc (ou vert sur noir) dit:
@SafeVarargs public static <T> boolean addAll(Collection<? super T> c, T... elements) {
Autrement dit, les développeurs eux-mêmes (et qui devraient-ils croire, sinon eux?) Écrivez que pour la plupart des implémentations, la méthode utilitaire fonctionne beaucoup plus rapidement. Et il est vraiment plus rapide. Parfois.
Le benchmark , que nous lancerons pour le HashSet sur le G8, permettra de HashSet :
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 155,2 ± 2,8 ns/op addAll HashSet 100 avgt 100 1884,4 ± 37,4 ns/op addAll HashSet 1000 avgt 100 17917,3 ± 298,8 ns/op collectionsAddAll HashSet 10 avgt 100 136,1 ± 0,8 ns/op collectionsAddAll HashSet 100 avgt 100 1538,3 ± 31,4 ns/op collectionsAddAll HashSet 1000 avgt 100 15168,6 ± 289,4 ns/op
Il semble que les camarades les plus expérimentés avaient raison. Presque.
Dans les éditions ultérieures (par exemple, dans 11), l'éclat de la méthode d'utilité s'estompe quelque peu:
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 143,1 ± 0,6 ns/op addAll HashSet 100 avgt 100 1738,4 ± 7,3 ns/op addAll HashSet 1000 avgt 100 16853,9 ± 101,0 ns/op collectionsAddAll HashSet 10 avgt 100 132,1 ± 1,1 ns/op collectionsAddAll HashSet 100 avgt 100 1661,1 ± 7,1 ns/op collectionsAddAll HashSet 1000 avgt 100 15450,9 ± 93,9 ns/op
On peut voir que nous ne parlons pas d'un "beaucoup plus rapide". Et si nous répétons l'expérience pour ArrayList -a, il s'avère que la méthode d'utilité commence à perdre beaucoup (plus elle est forte):
Benchmark (collection) (size) Mode Cnt Score Error Units JDK 8 addAll ArrayList 10 avgt 100 38,5 ± 0,5 ns/op addAll ArrayList 100 avgt 100 188,4 ± 7,0 ns/op addAll ArrayList 1000 avgt 100 1278,8 ± 42,9 ns/op collectionsAddAll ArrayList 10 avgt 100 62,7 ± 0,7 ns/op collectionsAddAll ArrayList 100 avgt 100 495,1 ± 2,0 ns/op collectionsAddAll ArrayList 1000 avgt 100 4892,5 ± 48,0 ns/op JDK 11 addAll ArrayList 10 avgt 100 26,1 ± 0,0 ns/op addAll ArrayList 100 avgt 100 161,1 ± 0,4 ns/op addAll ArrayList 1000 avgt 100 1276,7 ± 3,7 ns/op collectionsAddAll ArrayList 10 avgt 100 41,6 ± 0,0 ns/op collectionsAddAll ArrayList 100 avgt 100 492,6 ± 1,5 ns/op collectionsAddAll ArrayList 1000 avgt 100 6792,7 ± 165,5 ns/op
Il n'y a rien d'inattendu ici, ArrayList construit autour d'un tableau, donc les développeurs ont redéfini la Collection::addAll :
public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); modCount++; int numNew = a.length; if (numNew == 0) return false; Object[] elementData; final int s; if (numNew > (elementData = this.elementData).length - (s = size)) elementData = grow(s + numNew); System.arraycopy(a, 0, elementData, s, numNew); <--- size = s + numNew; return true; }
Revenons maintenant à nos mines. Supposons que nous ayons néanmoins accepté la solution proposée en relecture et laissé ce code:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
Pour le moment, tout va bien, mais après avoir ajouté de nouvelles fonctionnalités, la méthode devient parfois chaude et commence à ralentir. Nous ouvrons des codes source - le code n'a pas changé. La quantité de données est la même. Et les performances ont beaucoup baissé. Ceci est un autre type de mine.
Découvrez le débogueur et trouvez la belle:

Veuillez noter: nous n'avons pas changé l'algorithme, la quantité de données traitées n'a pas changé, mais leur nature a changé et un problème de performance a commencé dans notre code:
Java 8 Java 11 addAll 10 56,9 25,2 ns/op collectionsAddAll 10 352,2 142,9 ns/op addAll 100 159,9 84,3 ns/op collectionsAddAll 100 4607,1 3964,3 ns/op addAll 1000 1244,2 760,2 ns/op collectionsAddAll 1000 355796,9 364677,0 ns/op
Sur les grands tableaux, la différence entre Collections::addAll et Collection::addAll est 500 fois modeste. Le fait est que COWList ne développe pas seulement le tableau existant, mais en crée un nouveau chaque fois que des éléments sont ajoutés:
public boolean add(E e) { synchronized (lock) { Object[] es = getArray(); int len = es.length; es = Arrays.copyOf(es, len + 1); <---- es[len] = e; setArray(es); return true; } }
Qui est à blâmer?
Le problème principal ici est que la Collections::addAll accepte une interface, tandis que la méthode addAll pas de corps. Aucun corps - aucune entreprise, par conséquent, la documentation est écrite sur la base de l'implémentation existante dans AbstractCollection::addAll , qui est un algorithme généralisé applicable à toutes les collections. Cela signifie que des implémentations plus spécifiques de structures de données qui sont à un niveau d'abstraction inférieur peuvent modifier ce comportement.
Maintenant humainement Collection::addAll – AbstractCollection::addAll – <--- ArrayList::addAll HashSet::addAll – <--- COWList::addAll
En savoir plus sur les abstractions
Puisque nous parlons des niveaux d'abstraction, je vais vous parler d'un exemple tiré de la vie.
Comparons ces deux façons de sauvegarder le nième nombre d'entités dans la base de données:
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } } @Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
À première vue, les performances des deux méthodes ne devraient pas être très différentes, car
- dans les deux cas, le même nombre d'entités sera stocké dans la base de données
- si la clé est extraite de la séquence, le nombre d'appels sera le même
- la quantité de données transférées est la même
SimpleJpaRepository::saveAndFlush à la SimpleJpaRepository::saveAndFlush :
@Transactional public <S extends T> S save(S entity) { if (entityInformation.isNew(entity)) { em.persist(entity); return entity; } else { return em.merge(entity); } } @Transactional public <S extends T> S saveAndFlush(S entity) { S result = save(entity); flush(); return result; } @Transactional public void flush() { em.flush(); }
Le point noir ici est la méthode flush() . Pourquoi stupide? Il me semble que sa divulgation dans l'interface JpaRepository était une erreur des développeurs. Je vais essayer de justifier ma pensée. En règle générale, cette méthode n'est pas du tout utilisée par le développeur, car l'appel à EntityManager::flush lié à l'achèvement d'une transaction contrôlée par Spring:
Remarque: EntityManager fait partie de la spécification JPA implémentée dans Hibernate en tant que session (interface de session et classe SessionImpl, respectivement). Spring Date est un framework qui s'exécute au-dessus d'un ORM, dans ce cas, au-dessus d'Hibernate. Il s'avère que la JpaRepository::saveAndFlush nous donne accès aux niveaux inférieurs de l'API, bien que la tâche du framework soit de masquer les détails de bas niveau (la situation est quelque peu similaire à l'histoire Unsafe du JDK).
Dans notre cas, lorsque vous utilisez JpaRepository::saveAndFlush nous entrons dans les couches inférieures de l'application, cassant ainsi quelque chose.
Prenez votre temps pour jeter un coup d'œil, pensez par vous-mêmeLa capacité d'Hibernate à envoyer des données par lots est rompue, un multiple du paramètre jdbc.batch_size , qui est spécifié dans application.yml :
spring: jpa: properties: hibernate: jdbc.batch_size: 500
Le travail d'Hibernate est construit sur des événements, donc lorsque vous enregistrez 1000 entités comme celle-ci
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } }
appeler repository.save(e) ne sauvegarde pas instantanément. Au lieu de cela, un événement est créé qui est mis en file d'attente. À la fin de la transaction, les données sont fusionnées à l'aide de EntityManager::flush , qui divise les insertions / mises à jour en packs multiples de jdbc.batch_size et crée des requêtes à partir d'eux. Dans notre cas, jdbc.batch_size: 500 , donc sauver 1000 entités en réalité signifie seulement 2 requêtes.
Mais avec une décharge manuelle de la session à chaque passage du cycle
@Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
la file d'attente est effacée et l'enregistrement de 1 000 entités signifie 1 000 requêtes.
Ainsi, interférer avec les couches inférieures de l'application peut facilement devenir une mine, et pas seulement une mine de productivité (voir Dangereux et son utilisation non contrôlée).
Combien cela ralentit-il? Prenons le meilleur des cas (pour nous) - la base de données se trouve sur le même hôte que l'application. Ma mesure montre l'image suivante:
(entityCount) Mode Cnt Score Error Units bulkSave 10 ss 500 16,613 ± 1,714 ms/op bulkSave 100 ss 500 31,371 ± 1,453 ms/op bulkSave 1000 ss 500 35,687 ± 1,973 ms/op bulkSaveUsingFlush 10 ss 500 32,653 ± 2,166 ms/op bulkSaveUsingFlush 100 ss 500 61,983 ± 6,304 ms/op bulkSaveUsingFlush 1000 ss 500 184,814 ± 6,976 ms/op
De toute évidence, si la base de données est située sur un hôte distant, le coût du transfert de données dégradera de plus en plus les performances à mesure que le volume de données augmente.
Ainsi, travailler au mauvais niveau d'abstraction peut facilement créer une bombe à retardement. Soit dit en passant, dans l' un de mes articles précédents, j'ai parlé d'une curieuse tentative d'amélioration de StringBuilder -a: là, j'ai échoué juste en essayant d'entrer dans un niveau de code plus abstrait.
Frontières de champs de mines
Jouons un sapeur? Trouvez le mien:
Vous l'avez trouvé? Vérifiez la bonne réponse. "Vous plaisantez?", S'exclame le critique. "Mais n'y a-t-il qu'un collage de deux lignes? Qu'est-ce que cela signifie dans un sanglant E.?" Permettez-moi d'attirer votre attention sur le fait que j'ai mis en évidence non seulement le collage de cordes, mais aussi le nom de la classe et le nom de la méthode. En effet, le danger de coller des chaînes ne réside pas dans le collage lui-même, mais dans ce qui se passe dans la méthode qui crée les clés du cache, c'est-à-dire que dans certains scénarios, nous aurons beaucoup d'appels à cette méthode, ce qui signifie beaucoup de lignes d'ordures.
Par conséquent, un message d'erreur doit être créé uniquement lorsque cette erreur est réellement levée:
Ainsi, les champs de mines ont des limites - c'est la quantité de données, la fréquence d'accès à la méthode, etc. des indicateurs quantitatifs, lorsqu'ils atteignent et dépassent, où un léger inconvénient devient statistiquement significatif.
D'un autre côté, c'est la caractéristique jusqu'à ce que l'intersection qui complique le code ne donne pas une amélioration significative (mesurable).
C'est une autre conclusion pour le développeur: dans la plupart des cas, la tromperie est mauvaise, conduisant à une complication insignifiante du code. Dans 99 cas sur 100, nous ne gagnons rien.
Il ne faut pas oublier qu'il y a toujours
Le centième cas
Voici le code que Nitzan Wakart donne dans son article The volatile read surprise :
@BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) @State(Scope.Thread) public class LoopyBenchmarks { @Param({ "32", "1024", "32768" }) int size; byte[] bunn; @Setup public void prepare() { bunn = new byte[size]; } @Benchmark public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) {
Lorsque nous mettrons en place l'expérience, nous découvrirons une différence incroyable entre les deux façons d'itérer sur un tableau:
Benchmark (size) Score Score error Units goodOldLoop 32 46.630 0.097 ns/op goodOldLoop 1024 1199.338 0.705 ns/op goodOldLoop 32768 37813.600 56.081 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Ici, un développeur inexpérimenté peut tirer une conclusion aussi évidente et étayée: passer à travers un tableau en utilisant la nouvelle syntaxe fonctionne plus rapidement qu'un cycle de comptage. C'est la mauvaise conclusion, car cela vaut la peine de changer un goodOldLoop méthode goodOldLoop :
@Benchmark public void goodOldLoopReturns(Blackhole fox) { byte[] sunn = bunn;
et ses performances sont comparables à celles de la méthode sweetLoop «plus rapide»:
Benchmark (size) Score Score error Units goodOldLoopReturns 32 19.306 0.045 ns/op goodOldLoopReturns 1024 476.493 1.190 ns/op goodOldLoopReturns 32768 14292.286 16.046 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Blackhole::consume :
, , . goodOldLoop this.bunn , for-each , (, Java Concurrency In Practice " "). .
: " ? , Blackhole::consume — JMH . , , ?"
:
byte[] bunn; public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
? ? , :
E[] bunn; public void forEach(Consumer<E> fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
Iterable::forEach ! , , , ( JDK 13):
, . , Collections.nCopies()::forEach :
@Override public void forEach(final Consumer<? super E> action) { Objects.requireNonNull(action); for (int i = 0; i < this.n; i++) { action.accept(this.element); } }
, . . this.n this.element :
private static class CopiesList<E> extends AbstractList<E> implements RandomAccess, Serializable { final int n; final E element; CopiesList(int n, E e) { assert n >= 0; this.n = n; element = e; }
, , @Stable .
: 99 100 , , 1 100, . , .
" volatile".
, :
- , ( java.lang.Integer , java.lang.Long , java.lang.Short , java.lang.Byte , java.lang.Character ). , ,
Integer intgr = Integer.valueOf(42);
.
:
Integer intgr = new Integer(42);
, , Integer::valueOf .
: . , , "" ( ). , , Integer::valueOf . " " .
. , . , . , , .