Traduction de démystifier les réseaux de neurones convolutifs . Réseaux de neurones convolutifs.
Réseaux de neurones convolutifs.Au cours de la dernière décennie, nous avons assisté à des avancées étonnantes et sans précédent en vision par ordinateur. Aujourd'hui, les ordinateurs peuvent reconnaître des objets dans des images et des trames de vidéo avec une précision de 98%, déjà devant une personne avec ses 97%. Ce sont les fonctions du cerveau humain qui ont inspiré les développeurs à créer et à améliorer les techniques de reconnaissance.
Une fois, les neurologues ont mené des expériences sur des chats et ont découvert que les mêmes parties de l'image activaient les mêmes parties du cerveau du chat. Autrement dit, lorsque le chat regarde le cercle, la zone alpha est activée dans son cerveau, et quand il regarde le carré, la zone bêta est activée. Les chercheurs ont conclu que dans le cerveau des animaux, il existe des zones de neurones qui répondent à des caractéristiques spécifiques de l'image. En d'autres termes, les animaux perçoivent l'environnement à travers l'architecture neuronale multicouche du cerveau. Et chaque scène, chaque image passe à travers un bloc particulier de sélection de signes, et alors seulement elle est transmise aux structures plus profondes du cerveau.
S'inspirant de cela, les mathématiciens ont développé un système dans lequel sont émulés des groupes de neurones qui opèrent sur différentes propriétés d'image et interagissent les uns avec les autres pour former une image commune.
Récupération des propriétés
L'idée d'un groupe de neurones activés qui sont fournis avec des données d'entrée spécifiques a été transformée en une expression mathématique d'une matrice multidimensionnelle qui joue le rôle d'un déterminant d'un ensemble de propriétés - on l'appelle un filtre ou un noyau. Chacun de ces filtres recherche une particularité dans l'image. Par exemple, il peut y avoir un filtre pour définir les limites. Les propriétés trouvées sont ensuite transférées vers un autre ensemble de filtres qui peuvent déterminer les propriétés de niveau supérieur de l'image, par exemple les yeux, le nez, etc.
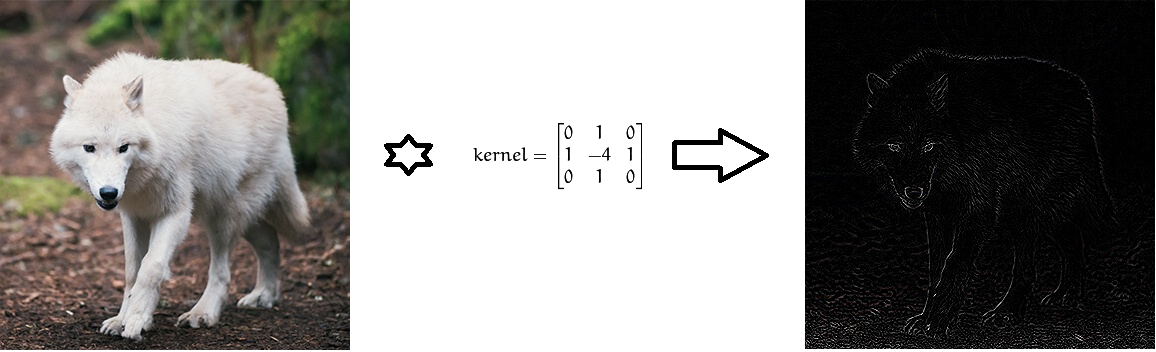 Convolution de l'image à l'aide de filtres de Laplace pour déterminer les limites.
Convolution de l'image à l'aide de filtres de Laplace pour déterminer les limites.Du point de vue des mathématiques, entre l'image d'entrée, présentée sous la forme d'une matrice d'intensité de pixels, et le filtre, nous effectuons une opération de convolution, aboutissant à une soi-disant carte des propriétés (carte des caractéristiques). Cette carte servira d'entrée à la prochaine couche de filtre.
Pourquoi une convolution?
La convolution est un processus dans lequel le réseau tente de baliser le signal d'entrée en le comparant avec des informations précédemment connues. Si le signal d'entrée ressemble à des images précédentes de chats, réseaux déjà connus, alors le signal de référence «chat» sera minimisé - mélangé - avec le signal d'entrée. Le signal résultant est transmis à la couche suivante. Dans ce cas, le signal d'entrée signifie une représentation tridimensionnelle de l'image sous la forme d'intensités de pixels RVB, et le signal de référence «chat» est appris par le noyau pour reconnaître les chats.
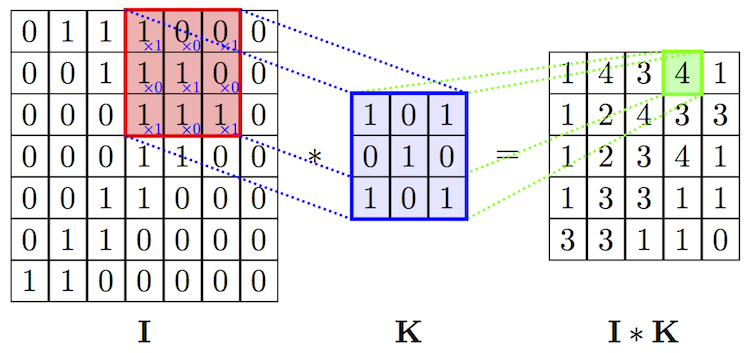 Opération de convolution d'image et filtre. Source
Opération de convolution d'image et filtre. SourceL'opération de convolution a une excellente propriété - invariant de translation. Cela signifie que chaque filtre de convolution reflète un certain ensemble de propriétés, par exemple les yeux, les oreilles, etc., et l'algorithme de réseau neuronal convolutionnel apprend à déterminer quel ensemble de propriétés correspond à la référence, par exemple, d'un chat. L'intensité du signal de sortie ne dépend pas de l'emplacement des propriétés, mais de leur présence. Par conséquent, le chat peut être représenté dans diverses poses, mais l'algorithme peut toujours le reconnaître.
Pooling
En suivant le principe du cerveau biologique, les scientifiques ont pu développer un appareil mathématique pour extraire des propriétés. Mais après avoir évalué le nombre total de couches et de propriétés qui doivent être analysées pour suivre des formes géométriques complexes, les scientifiques ont réalisé que les ordinateurs n'auraient pas assez de mémoire pour stocker toutes les données. De plus, la quantité de ressources informatiques requises croît de façon exponentielle avec l'augmentation du nombre de propriétés. Pour résoudre ce problème, une technique de mutualisation a été développée. Son idée est très simple: si une certaine zone contient des propriétés prononcées, alors nous pouvons refuser de rechercher d'autres propriétés dans cette zone.
 Exemple de mise en commun de la valeur maximale.
Exemple de mise en commun de la valeur maximale.L'opération de mise en commun permet non seulement d'économiser de la mémoire et de la puissance de traitement, mais aide également à éliminer les images du bruit.
Couche entièrement collée
D'accord, pourquoi un réseau neuronal serait-il utile s'il ne peut définir que des ensembles de propriétés d'image? Nous devons en quelque sorte lui apprendre à classer les images. Et l'approche traditionnelle de la formation de réseaux de neurones nous y aidera. En particulier, les cartes de propriétés obtenues sur les couches précédentes peuvent être collectées dans une couche qui est entièrement associée à toutes les étiquettes que nous avons préparées pour la catégorisation. Cette dernière couche attribuera les probabilités de faire correspondre chaque classe. Et sur la base de ces probabilités finales, nous pouvons attribuer l'image à une certaine catégorie.
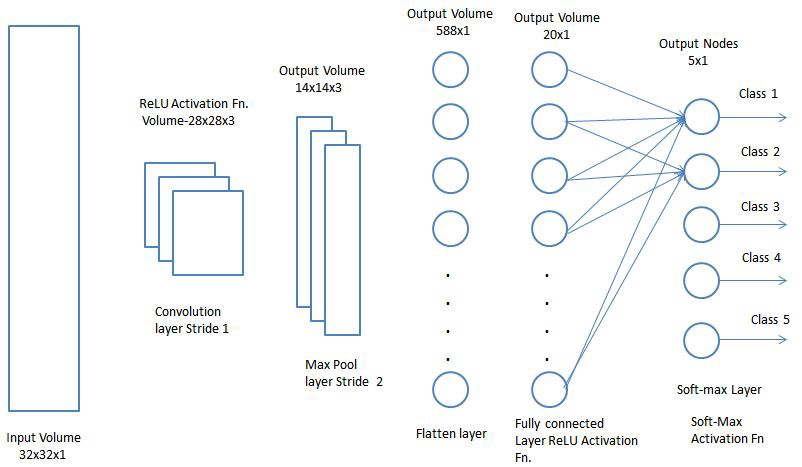 Couche entièrement collée. Source
Couche entièrement collée. SourceArchitecture finale
Maintenant, il ne reste plus qu'à combiner tous les concepts étudiés par le réseau dans un cadre unique - le réseau de neurones convolutionnels (Convolution Neural Network, CNN). CNN se compose d'une série de couches convolutives qui peuvent être combinées avec des couches de mise en commun pour générer une carte de propriétés qui est transmise aux couches entièrement connectées pour déterminer les probabilités de correspondance avec toutes les classes. En ramenant les erreurs que nous obtenons, nous pouvons former ce réseau de neurones jusqu'à obtenir des résultats précis.
Maintenant que nous comprenons les perspectives fonctionnelles de CNN, examinons de plus près les aspects de l'utilisation de CNN.
Réseaux de neurones convolutifs
 Couche convolutionnelle.
Couche convolutionnelle.La couche convolutionnelle est le principal élément constitutif de CNN. Chacune de ces couches comprend un ensemble de filtres indépendants, chacun recherchant son propre ensemble de propriétés dans l'image entrante.
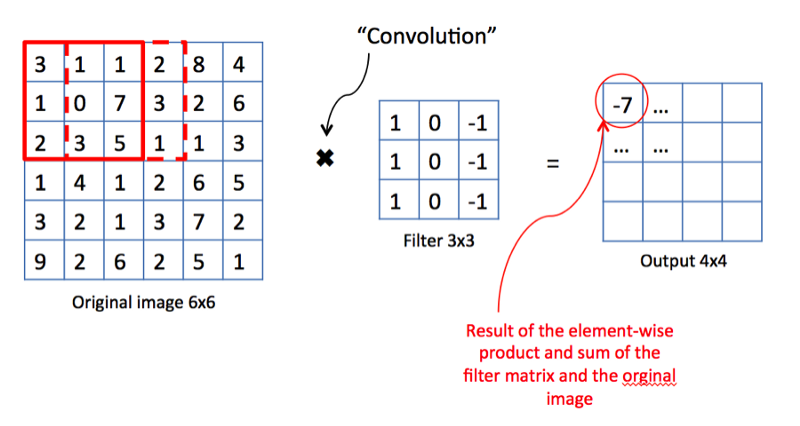 Opération de convolution. Source
Opération de convolution. SourceDu point de vue des mathématiques, nous prenons un filtre de taille fixe, le superposons à l'image et calculons le produit scalaire du filtre et un morceau de l'image d'entrée. Les résultats des travaux sont placés dans la carte de propriété finale. Ensuite, nous déplaçons le filtre vers la droite et répétons l'opération, en ajoutant également le résultat du calcul à la carte des propriétés. Après convolution de l'image entière à l'aide d'un filtre, nous obtenons une carte des propriétés, qui est un ensemble de signes explicites et est alimentée en entrée dans la couche suivante.
Foulées
Stride est la quantité de décalage du filtre. Dans l'illustration ci-dessus, nous décalons le filtre d'un facteur 1. Mais parfois, vous devez augmenter la taille du décalage. Par exemple, si les pixels voisins sont fortement corrélés entre eux (en particulier sur les couches inférieures), il est logique de réduire la taille de la sortie en utilisant la foulée appropriée. Mais si la foulée est trop importante, alors beaucoup d'informations seront perdues, alors faites attention.
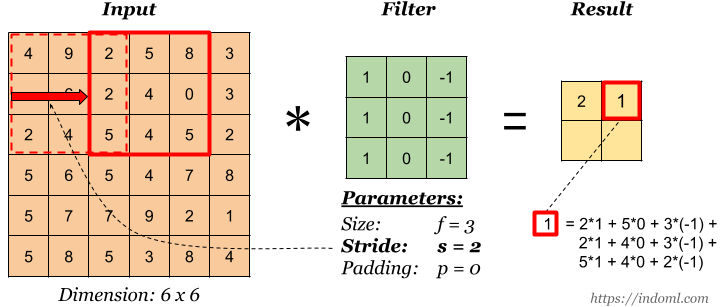 Stride est 2. Source .
Stride est 2. Source .Rembourrage
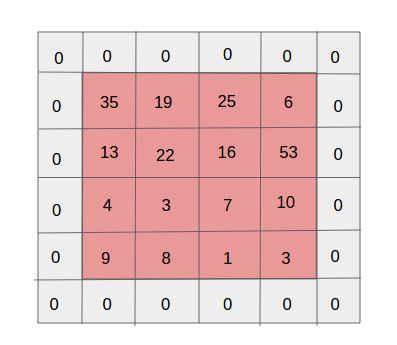 Rembourrage simple couche. Source
Rembourrage simple couche. SourceL'un des effets secondaires de la foulée est la diminution constante de la carte des propriétés à mesure que de nouvelles convolutions sont effectuées. Cela peut être indésirable car la «réduction» signifie la perte d'informations. Pour le rendre plus clair, faites attention au nombre de fois que le filtre est appliqué à la cellule au milieu et dans le coin. Il s'avère que pour aucune raison les informations dans la partie centrale sont plus importantes que sur les bords. Et pour extraire des informations utiles des calques antérieurs, vous pouvez entourer la matrice de calques de zéros.
Partage de paramètres
Pourquoi avons-nous besoin de réseaux convolutionnels si nous avons déjà de bons réseaux neuronaux d'apprentissage en profondeur? Il est à noter que si nous utilisons des réseaux d'apprentissage profond pour classer les images, le nombre de paramètres sur chaque couche sera mille fois supérieur à celui du réseau neuronal convolutionnel.
 Partage des paramètres dans un réseau neuronal convolutif.
Partage des paramètres dans un réseau neuronal convolutif.