Dans l'industrie, les exigences du LAN deviennent de plus en plus ICS prend de plus en plus de fonctionnalités et la perte de données peut entraîner des coûts importants.
Par exemple, dans le secteur de l'énergie, si les données des transducteurs de mesure n'atteignent pas la borne de relais à temps, cela peut conduire à un court-circuit se propageant aux sections adjacentes du réseau électrique, ce qui entraînera des pertes beaucoup plus graves qu'en cas de déconnexion opportune de la section du court-circuit. Par conséquent, souvent dans les projets énergétiques, vous pouvez répondre à l'exigence "Temps de récupération inférieur à 1 ms".
La redondance du réseau basée sur des protocoles à l'échelle de l'industrie tels que RSTP, MRP, DLR et similaires, est basée sur un changement de topologie en cas de dysfonctionnement dans le transfert de données. La modification de la topologie prend un certain temps (de quelques millisecondes à quelques secondes, selon le protocole), appelé "temps de récupération". Pendant ce temps, il n'y a pas de communication avec une partie du réseau et, par conséquent, les données sont perdues. C'est-à-dire les technologies classiques de redondance en anneau ne permettent pas des temps de récupération inférieurs à 1 ms.
Dans ce contexte, les technologies de redondance dites «sans couture» - PRP et HSR - gagnent en popularité. La redondance basée sur PRP et HSR est effectuée, contrairement aux protocoles ci-dessus, non pas en reconstruisant la topologie, mais en dupliquant les trames. Chaque trame est dupliquée par l'expéditeur, et les deux trames sont transmises de différentes manières, et le nœud de réception traite la trame entrée en premier et rejette la seconde. Ce principe de fonctionnement ne nécessite pas de restructuration de la topologie et, par conséquent, ce protocole fonctionne presque «de manière transparente». Sous la coupe, vous trouverez des détails sur la mise en œuvre de ces protocoles.
Structure du réseau
La redondance transparente est implémentée sur les nœuds d'extrémité, pas sur les composants réseau. C'est l'une des principales différences entre PRP et HSR par rapport à d'autres protocoles de sauvegarde tels que RSTP ou MRP. Tenez compte des caractéristiques de la structure du réseau pour PRP et HSR.
PRP - structure du réseau
Le nœud d'extrémité a deux interfaces Ethernet qui se connectent à deux réseaux isolés l'un de l'autre, fonctionnant en parallèle et ayant une topologie indépendante (c'est-à-dire que les topologies de ces deux réseaux peuvent être identiques ou différentes). Les réseaux doivent être isolés de sorte que tout dysfonctionnement et arrêt de la transmission de données dans un réseau n'affectent pas le second, c'est-à-dire même l'alimentation réseau est fournie par différentes sources. Il ne devrait pas y avoir de connexion directe entre ces réseaux.
 Structure du réseau PRP
Structure du réseau PRPCes deux réseaux sont généralement appelés LAN A et LAN B. Comme déjà indiqué, ils peuvent avoir des topologies différentes ainsi que des performances différentes. Les retards dans la transmission des données peuvent également varier.
Le réseau peut contenir les éléments suivants:
- DAN (Dual Attached Node) - un nœud qui se connecte aux deux réseaux et envoie / reçoit des trames en double.
- SAN (Single Attached Node) - un nœud qui se connecte à un seul réseau (LAN A ou LAN B) et envoie / reçoit des trames normales.
- Dans le cas où il est nécessaire de connecter de manière redondante un appareil qui possède une interface Ethernet et ne prend pas en charge le protocole PRP au réseau RPR, le soi-disant Redundancy Box (généralement RedBox) est utilisé. Sur RedBox, le paquet de l'appareil est dupliqué et transmis au réseau PRP, comme si les données étaient transmises depuis le DAN. De plus, l'appareil derrière RedBox est considéré comme un DAN pour d'autres appareils. Un tel nœud est appelé DAN virtuel ou VDAN (Virtual DAN).
 Principe de fonctionnement de RedBox
Principe de fonctionnement de RedBoxHSR - structure du réseau
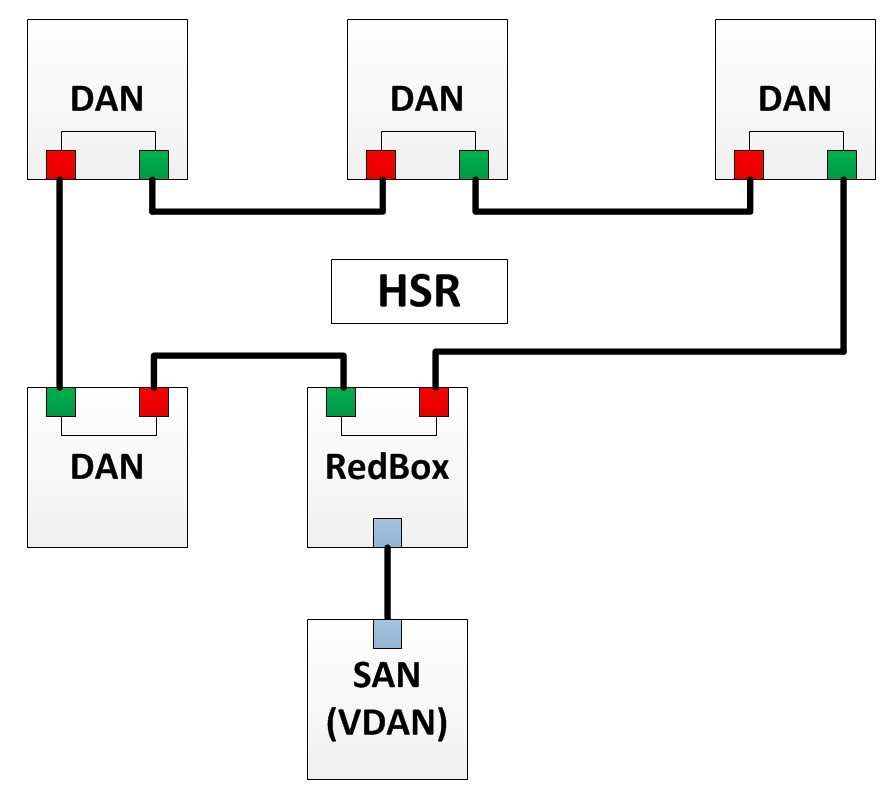 Structure du réseau HSR
Structure du réseau HSRLe principe de fonctionnement de HSR est que tous les appareils sont combinés en anneau et tous les messages, ainsi que dans PRP, sont dupliqués. L'appareil envoie les deux images à travers l'anneau: une copie dans le sens horaire, l'autre dans le sens antihoraire. Le récepteur reçoit les deux copies, mais traite uniquement la première et supprime la seconde. Si quelque chose arrive à l'un des liens et que l'un des cadres dupliqués ne vient pas, alors l'autre est simplement accepté. Tous les périphériques HSR ont deux interfaces Ethernet - le port A et le port B.
Selon le protocole HSR, les éléments suivants peuvent exister dans un réseau:
- SAN est un nœud qui n'a qu'une seule interface Ethernet. Un tel nœud peut être connecté au réseau HSR exclusivement via RedBox.
- DAN - un nœud qui peut échanger des données à l'intérieur d'un anneau HSR (peut envoyer / recevoir des trames en double).
- RedBox - tout comme dans PRP, RedBox vous permet de connecter un appareil doté d'une interface Ethernet à un réseau HSR. L'appareil derrière RedBox est considéré comme un DAN pour d'autres appareils. Un tel nœud est appelé DAN virtuel ou VDAN (Virtual DAN).
- QuadBox - HSR présente également un nouvel élément - QuadBox. Cet appareil possède quatre ports HSR. Il vous permet de combiner deux anneaux HSR. Dans chaque anneau, la QuadBox agit comme un DAN et peut transférer des données d'un anneau à un autre.
 Exemple QuadBox
Exemple QuadBoxStructure DAN
Pour PRP et HSR, la structure DAN est similaire. Chaque DAN possède deux interfaces fonctionnant en parallèle et connectées au niveau supérieur d'une pile de communication via la couche dite LRE - entité de redondance de liaison. À ce niveau, toutes les fonctions de sauvegarde sont exécutées.
Les deux interfaces DAN ont la même adresse MAC et une seule adresse IP. Cela vous permet de rendre la réservation transparente au plus haut niveau. Particulièrement important est le fait que cela permet l'utilisation d'ARP pour DAN ainsi que pour tout nœud non redondant.
Cependant, bien sûr, il existe des nuances dans la structure DAN pour PRP et HSR.
PRP - Structure DAN
Lorsqu'une trame est envoyée à partir du niveau supérieur, le LRE la duplique et envoie les deux paquets via les ports presque simultanément. Les deux trames sont transmises en parallèle via deux réseaux avec des retards différents. Dans une situation idéale, ils sont livrés au nœud de destination avec un décalage horaire minimum. A la réception du LRE, le récepteur envoie la première trame reçue à la couche supérieure et rejette la seconde.
LRE crée des trames en double lors de l'envoi et les traite dès réception. Ce niveau, par rapport au niveau supérieur, représente l'interface habituelle d'une carte réseau non redondante. LRE effectue deux tâches: gérer les trames en double et gérer la redondance. Pour implémenter le contrôle, LRE ajoute une remorque de contrôle de redondance (RCT) 32 bits à chaque trame et la supprime lorsque la trame est reçue.
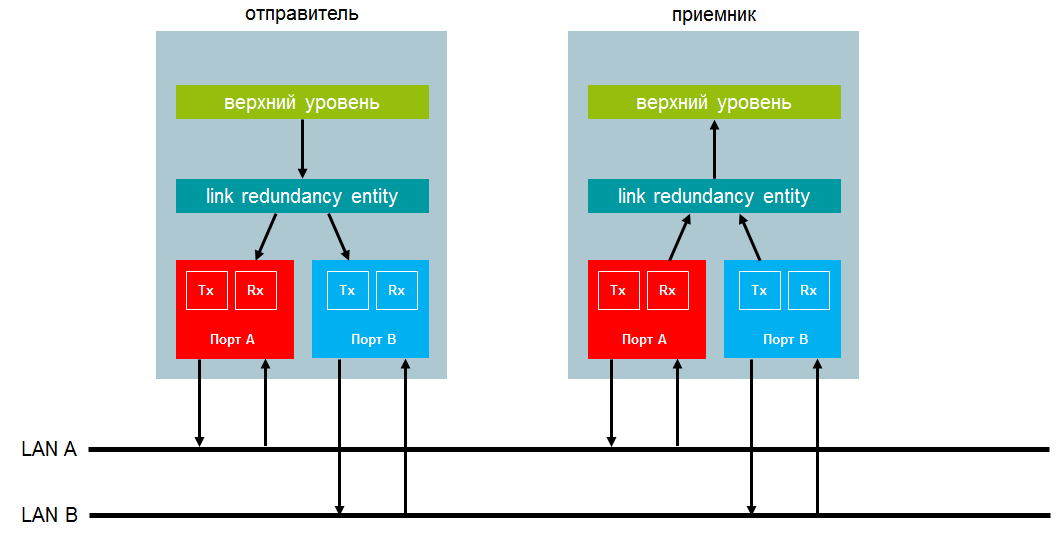 Transfert de données entre deux DAN dans PRP
Transfert de données entre deux DAN dans PRPHSR - Structure DAN
Une trame envoyée depuis la couche supérieure est dupliquée par la couche LRE, et les paquets sont envoyés via le port A et le port B presque simultanément. (1 et 2 sur le schéma).
À la réception de la trame, le récepteur la transfère au niveau LRE, la redirige également vers un autre port et la transmet plus loin dans l'anneau. (3, 4).
Si une trame arrive à l'expéditeur, alors cette trame n'est pas transmise plus loin, mais détruite (5, 6).
Les deux trames arrivent au niveau LRE, mais celle qui a été envoyée plus rapidement est transférée au niveau supérieur et la trame dupliquée est supprimée.
LRE ajoute une balise HSR 48 bits à chaque trame (semblable à l'ajout d'une balise VLAN) et supprime cette balise à la réception.
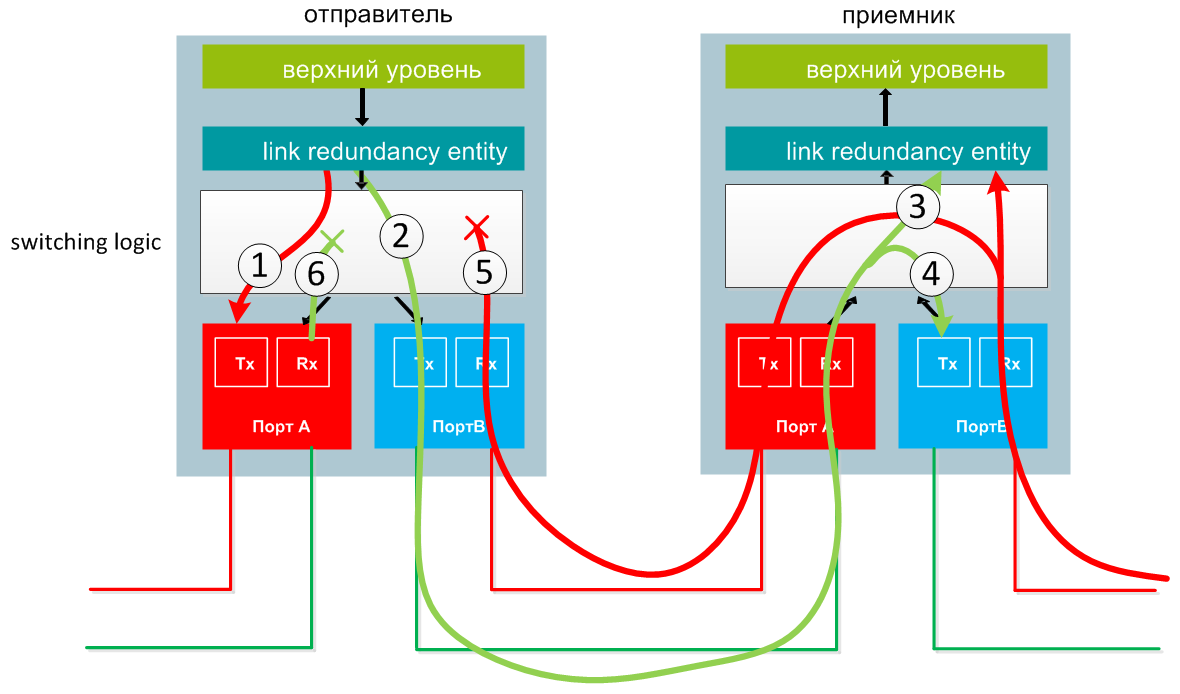 Transfert de données entre deux DAN dans un HSR
Transfert de données entre deux DAN dans un HSRInteropérabilité entre SAN et DAN
Dans PRP, un SAN peut être connecté à n'importe quel réseau - LAN A ou LAN B, mais un tel nœud ne prend pas en charge les fonctions de sauvegarde. Par conséquent, un SAN connecté à un réseau ne peut pas communiquer avec un autre nœud similaire connecté à un deuxième réseau. Pour interagir avec SAN, DAN génère des trames spéciales. Ce besoin est dû au fait que le SAN dans la trame normale du périphérique redondant doit ignorer le RCT, ce qui n'est pas possible, car le SAN ne peut pas distinguer le RCT du bloc de données IEEE 802.3 normal. À son tour, le DAN comprend qu'il envoie la trame au SAN et n'ajoute pas de RCT à la trame. Il transfère simplement une trame du niveau supérieur à l'interface à laquelle le SAN est connecté. En d'autres termes, si le DAN ne peut pas déterminer ce qui échange des données avec un autre DAN, il n'ajoute pas RCT à la trame.
Dans HSR, un SAN ne peut pas être connecté directement au réseau. Il peut être connecté exclusivement via RedBox.
Modes DAN
Lorsque vous travaillez avec des trames en double reçues sur les deux interfaces (si elles sont utilisables), le DAN doit accepter l'une des trames et éliminer la seconde. Il existe deux méthodes de traitement dans PRP:
- L'acceptation en double est une méthode dans laquelle les deux trames entrantes sont reçues et redirigées vers le niveau supérieur.
- Duplicate discard - une méthode dans laquelle le nœud récepteur lit les informations du RCT de la trame entrante afin de déterminer la trame à rejeter.
Pour HSR, considérez les modes U et X les plus populaires.
Accepter en double
Un DAN fonctionnant dans ce mode ne supprime aucune trame lors du traitement au niveau de la couche liaison de données.
Les trames sont envoyées au LAN A et au LAN B sans RCT. Le LRE du récepteur redirige simplement les deux trames vers la couche supérieure, en supposant qu'une transmission ultérieure détruira les doublons (IEEE 802.1D indique clairement que les protocoles de couche supérieure doivent être capables de gérer les trames en double).
Par exemple, TCP et UDP ont un haut niveau de résilience aux trames en double.
Cette méthode est très simple à mettre en œuvre, mais présente un sérieux inconvénient - elle ne fournit aucune capacité de contrôle du réseau, car la réception des deux trames n'est en aucun cas surveillée.
Rejet en double au niveau du canal
Lors de l'utilisation de la deuxième méthode, un champ composé de quatre octets est ajouté à la trame - RCT (remorque de contrôle de redondance). Une bande-annonce est ajoutée au niveau LRE lorsque la trame est reçue du niveau supérieur. RCT se compose des paramètres suivants:
- Numéro de séquence de 16 bits;
- Identifiant de réseau 4 bits, 1010 (0xA) pour LAN A et 1011 (0xB) pour LAN B;
- Taille d'image 12 bits.
En raison de l'ajout d'une remorque RCT au châssis, sa taille est supérieure à la taille maximale du châssis définie dans la norme IEEE 802.3-2005. Pour transmettre des données au sein du réseau avec PRP, l'équipement doit être configuré pour transmettre des données d'une taille de 1496 octets. Pour cette raison, tous les commutateurs ne conviennent pas à une utilisation sur LAN A ou LAN B.
 Cadre avec RCT ajouté
Cadre avec RCT ajoutéChaque fois que la couche liaison envoie une trame à une adresse spécifique, l'expéditeur augmente le numéro de séquence du nœud correspondant et envoie des trames identiques via les deux interfaces.
Le nœud récepteur doit déterminer les doublons sur la base des informations provenant du RCT.
Algorithme de méthode de suppression des doublons
Le récepteur suppose que les trames envoyées à partir de n'importe quelle source utilisant le protocole PRP sont envoyées séquentiellement avec un nombre sans cesse croissant. Le numéro de séquence attendu pour la trame suivante est stocké dans les variables ExpectedSeqA et, en conséquence, ExpectedSeqB.
À la réception, l'exactitude de la séquence peut être vérifiée en comparant la valeur de ExpectedSeqA (ExpectedSeqB) avec le numéro de séquence de la trame reçue, stocké dans la variable currentSeq dans RCT. Si le résultat est positif, la variable ExpectedSeq est définie sur un de plus que currentSeq afin qu'il soit possible d'effectuer un contrôle correct sur cette ligne.
 Intervalle de dépôt de trame (fenêtre de dépôt)
Intervalle de dépôt de trame (fenêtre de dépôt)Pour les deux interfaces, il existe un intervalle de chute de trame dynamique pour les numéros de séquence appariés. La limite supérieure de cet intervalle est ExpectedSeq (le prochain numéro de séquence attendu sur cette interface), à l'exclusion de la valeur donnée elle-même, et la limite inférieure de cet intervalle est startSeq (le plus petit numéro de séquence auquel la trame dupliquée avec ce numéro de séquence est ignorée).
Après avoir vérifié le numéro de séquence, le récepteur décide de rejeter la trame ou non. Supposons que le LAN A ait une taille d'intervalle de chute de trame non nulle (Fig. 5). Une trame du LAN B dont le numéro se situe dans cet intervalle sera rejetée. Toutes les autres trames du LAN B seront acceptées et envoyées au niveau supérieur.
La suppression d'une trame du LAN B réduit la taille du LAN A, car après avoir reçu cette trame, aucune trame avec un nombre inférieur sur cette interface n'est attendue. Par conséquent, startSeqA est défini sur un de plus que currentSeqB. Dans ce cas, la taille de l'intervalle de suppression de la trame LAN B est réinitialisée à 0 (startSeqB = attenduSeqB), car De toute évidence, les trames LAN B sont «derrière» le LAN LAN et aucune trame du LAN A ne doit être supprimée.
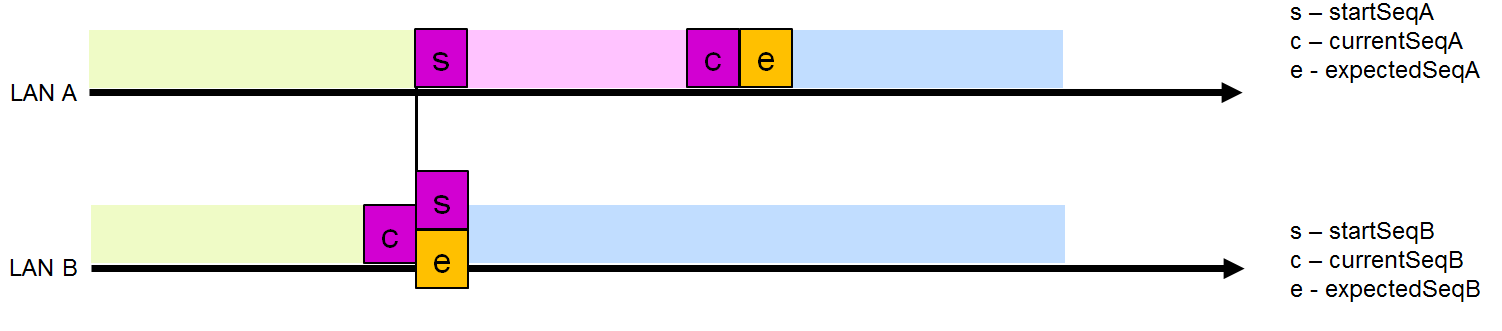 Diminuez l'intervalle LAN A après la suppression de la trame du LAN B
Diminuez l'intervalle LAN A après la suppression de la trame du LAN BDans la situation de la figure 7, lorsque plusieurs trames du LAN A viennent en ligne, mais que rien ne vient du LAN B, elles sont acceptées, car leur currentSeq est en dehors de l'intervalle de rejet de la trame LAN B et l'intervalle LAN A est augmenté d'une position. Si les trames du LAN A continuent d'arriver, mais que rien ne vient toujours du LAN B, lorsque la taille d'intervalle maximale est atteinte, startSeqA commence également à augmenter d'une unité.
Lorsque la trame reçue est en dehors de l'intervalle de suppression de la trame d'un autre LAN, cette trame est enregistrée et la taille de l'intervalle de cette interface est définie sur 1, ce qui signifie que seule une trame d'un autre LAN avec le même numéro de séquence sera ignorée, tandis que la fenêtre de dépôt de l'autre interface est réglé sur 0, ce qui signifie qu'aucune trame ne sera supprimée (Fig. 7).
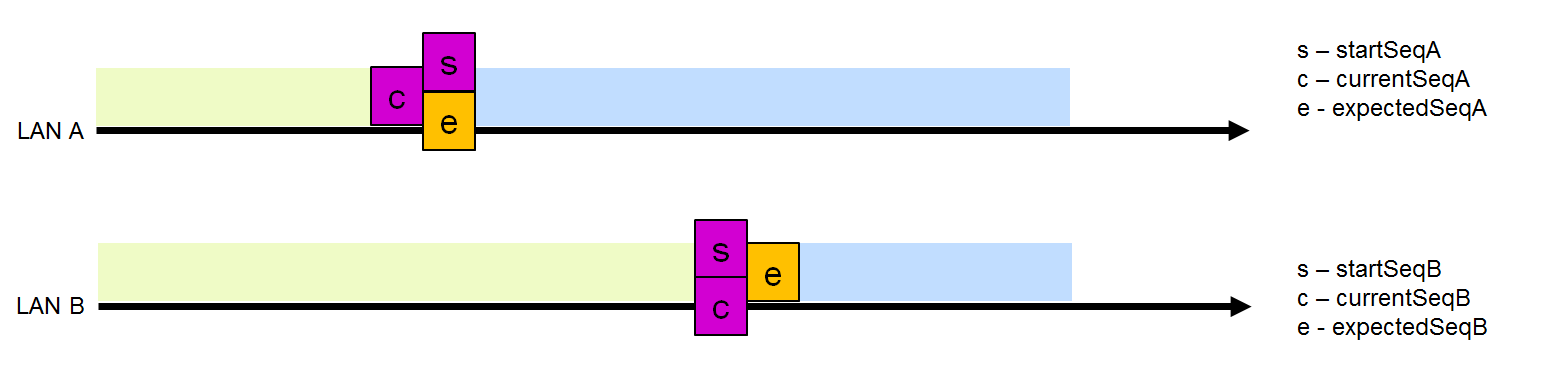
La trame du LAN B n'a pas été supprimée
La situation la plus courante est lorsque les deux interfaces sont synchronisées et que la taille des deux intervalles est 0 (Fig.8), ce qui signifie que la trame de l'interface qui vient en premier sera acceptée et l'intervalle de cette interface sera augmenté à 1, ce qui permettra à la trame d'être supprimée d'une autre interface avec même numéro de séquence.
 LAN synchronisé
LAN synchroniséEn raison de la présence d'un identifiant LAN dans RCT, les trames en double diffèrent d'un bit (et ont des sommes de contrôle différentes). Le récepteur vérifie que la trame appartient à l'interface (c'est-à-dire qu'il vérifie que la trame avec l'identifiant LAN A est arrivée à l'interface A). Le récepteur ne laissera pas tomber cette trame, car il peut contenir des informations utiles dans le bloc de données, mais dans ce cas, le compteur cntWrongLanA ou cntWrongLanB sera augmenté d'une unité. Ces erreurs n'étant pas ponctuelles (mélangées par LAN A et LAN B), le compteur augmentera constamment.
Lier le trafic HSR
Lors du transfert de données au sein du réseau HSR, une balise HSR est ajoutée à chaque trame.
La balise HSR comprend les paramètres suivants:
- Type d'éther HSR 16 bits
- Indicateur de chemin 4 bits
- Taille d'image 12 bits
- Numéro de séquence 16 bits
L'expéditeur insère les mêmes numéros de séquence dans les trames en double envoyées, puis incrémente le numéro de séquence pour chaque message envoyé à partir de ce nœud.
Le récepteur surveille les numéros de séquence de toutes les trames de chaque source à partir de laquelle il reçoit des données (il distingue les sources par adresse MAC). Si les trames proviennent de différentes lignes et ont la même source et le même numéro de séquence, l'une d'elles est acceptée et la seconde est rejetée.
Pour contrôler le réseau, chaque périphérique conserve une table de tous les nœuds du réseau à partir desquels il reçoit des données. Cela vous permet de détecter la disparition des nœuds et les erreurs sur le bus.
Le nœud définit la trame qu'il a envoyée par source et par numéro de séquence.
 Cadre avec étiquette HSR ajoutée
Cadre avec étiquette HSR ajoutéeUn nœud HSR ne rejette jamais une trame qu'il n'a pas reçue précédemment. Le nœud définit presque toutes les trames dupliquées, mais s'il y en a peu, il ne les supprime pas, c'est-à-dire le cadre traverse tout l'anneau et est détruit sur l'expéditeur.
Dans la norme, l'algorithme de détermination des trames en double n'est pas défini. Comme méthodes possibles, des tables de hachage, des files d'attente et le suivi des numéros de séquence peuvent être utilisés.
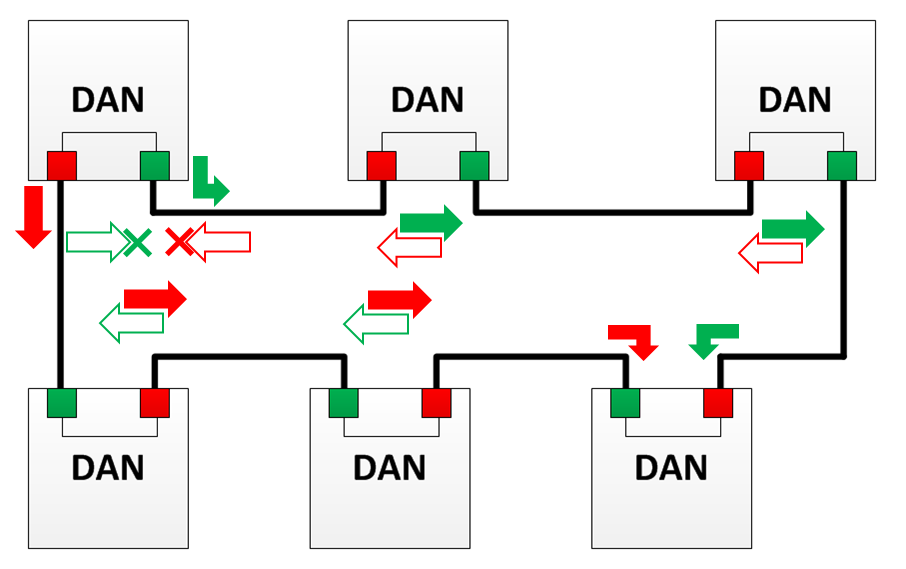
Mode U
Dans ce mode, le nœud qui reçoit la trame détruit le doublon et ne lui permet pas de se propager davantage. Si la trame a néanmoins été transférée plus loin, elle est détruite sur les nœuds suivants. Ce mode vous permet de décharger l'anneau du trafic Unicast.
Dans le diagramme, les flèches rouges indiquent les paquets avec la balise HSR envoyés depuis le port "A" (ci-après - trame "A").
Les flèches vertes indiquent les paquets avec une étiquette HSR envoyés depuis le port "B" (ci-après - trame "B").
Les flèches vides indiquent une baisse de trafic, c.-à-d. les trames qui seraient transmises pendant le fonctionnement normal, mais dans ce mode ont été rejetées.
La croix indique la suppression du trafic sur le ring (en tout cas).
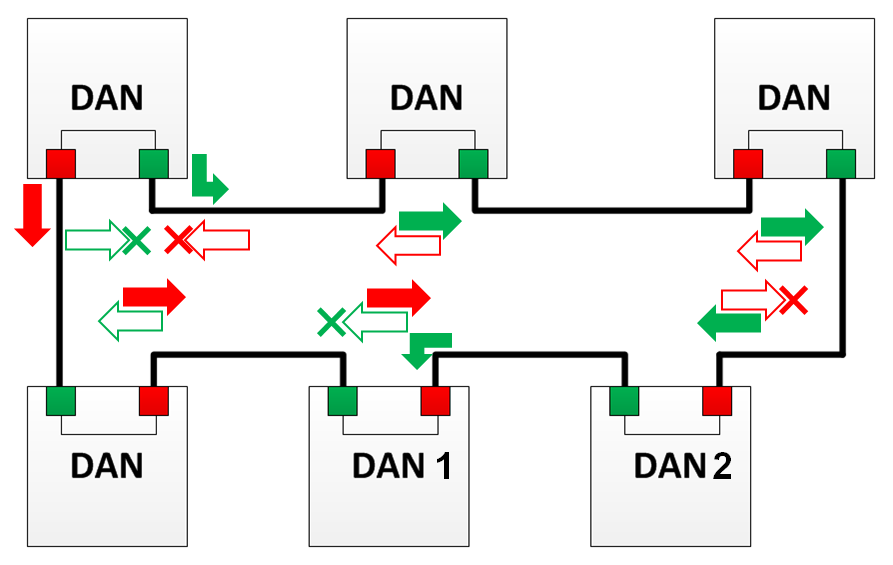
Mode X
Dans ce mode, le nœud ne transmet pas la trame plus loin et la rejette si une telle trame a été reçue d'une autre direction.
Par exemple, DAN 1 dans l'image ne fera pas avancer l'image "B" plus loin, car il a déjà reçu la trame "A", et DAN 2 ne transmettra plus la trame "A", car déjà reçu la trame «B».
Dans le cas où une erreur s'est produite quelque part dans l'algorithme et que les trames ont été transmises plus loin, elles seront rejetées sur les nœuds suivants ou sur le nœud sur lequel elles ont été créées.
Le mode X n'est pas applicable pour les messages PTP et pour la transmission de trame de supervision.
Contrôle réseau
PRP
Le récepteur vérifie que toutes les trames arrivent séquentiellement et sont correctement reçues sur les deux canaux. Il prend en charge les compteurs d'erreurs qui peuvent être lus, par exemple, via SNMP.
Tous les appareils prennent en charge les tables de nœuds avec lesquelles ils échangent des données. Ces tableaux contiennent des informations sur l'heure à laquelle la dernière trame a été envoyée ou reçue d'un nœud particulier et d'autres informations concernant le protocole PRP.
En même temps, ces tableaux permettent de détecter des composés dans lesquels il est nécessaire de synchroniser des numéros de séquence, ainsi que de détecter des séquences cassées et des nœuds manquants.
Le diagnostic est basé sur le fait que chaque DAN envoie périodiquement une trame de diagnostic (trame de supervision), qui vous permet de vérifier l'intégrité du réseau et la présence de nœuds. Dans le même temps, ces trames vous permettent de vérifier quels périphériques agissent en tant que DAN, de déterminer leurs adresses MAC et dans quel mode ils fonctionnent - dupliquer accepter ou dupliquer rejeter.
Hsr
Chaque nœud vérifie constamment tous les liens.
Chaque nœud envoie périodiquement une trame de diagnostic (aux deux ports) contenant des informations sur l'état du nœud. Cette trame est acceptée par tous les nœuds, y compris l'expéditeur. Lorsque l'expéditeur reçoit son propre message de diagnostic, une vérification d'intégrité du canal physique est effectuée.
L'intervalle d'envoi d'une trame de diagnostic est relativement long (quelques secondes), car il n'est pas nécessaire de fournir une redondance, mais n'est nécessaire qu'à des fins de diagnostic.
Tous les nœuds sont entrés dans la table de tous les partenaires trouvés et l'heure est enregistrée lorsque le nœud a été activé pour la dernière fois, ainsi que toutes les trames ignorées et les trames qui n'ont pas été envoyées séquentiellement.
Toutes les modifications de topologie qui se sont produites sont également enregistrées et toutes les informations peuvent être obtenues via SNMP.
HSR et PRP: avantages et inconvénients
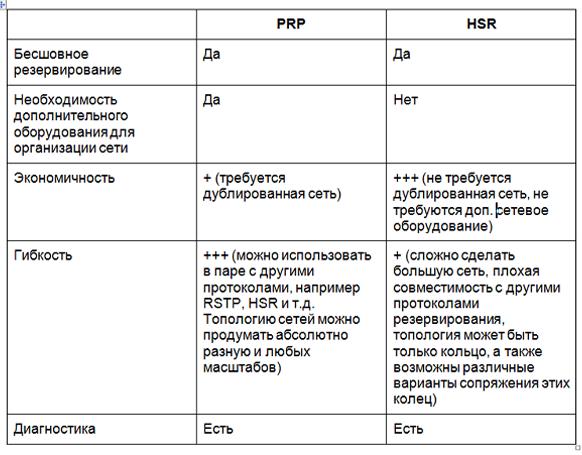
Conclusion
Cela ne veut pas dire qu'un protocole est meilleur qu'un autre - ils sont conçus un peu pour différentes applications. HSR et PRP permettent une redondance de réseau transparente, mais HSR vous permet de créer des solutions plus rentables. Mais cette rentabilité entraîne des difficultés, car un réseau HSR est difficile à mettre à l'échelle et les applications ne sont pas très flexibles. Une faible flexibilité est due à une topologie limitée (anneau, appariement d'anneaux), ainsi qu'à une mauvaise compatibilité du protocole avec d'autres technologies. Par conséquent, HSR est mieux adapté pour la redondance de petits systèmes et l'intégration dans un grand réseau. La sauvegarde HSR de l'ensemble du réseau est problématique. PRP, à son tour, est une solution plus coûteuse, mais vous permet d'organiser un réseau à assez grande échelle, qui à l'avenir peut être étendu sans problème, car
Ce protocole permet d'intégrer facilement presque toutes les technologies et de mettre en œuvre des topologies complètement différentes.Trouvez une solution