Est-il possible de déterminer par citation lequel des politiciens est son auteur? L'ONG ukrainienne
Vox Ukraine réalise le projet
VoxCheck , dans le cadre duquel elle vérifie les déclarations des politiciens les mieux notés. Récemment, ils ont publié l'intégralité de la
base de données des devis vérifiés . J'écoute simplement des cours de PNL et j'ai décidé de vérifier la précision avec laquelle l'auteur peut être identifié par le texte de la citation.
Clause de non-responsabilité . Cet article est rédigé par intérêt pour le sujet et le désir d'essayer le matériel étudié dans la pratique, sans prétendre à l'analyse la plus précise et détaillée.
Pour l'analyse, python a été utilisé, le code est disponible sur
github .
Les données
La base de données contient maintenant 1952 citations avec la distribution suivante par politique:
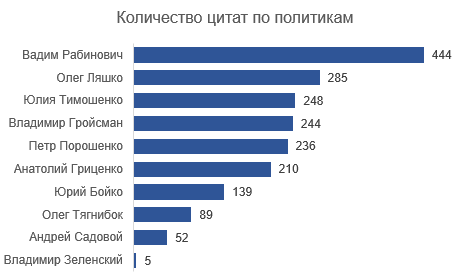
À des fins d'analyse, j'ai sélectionné des personnes avec> 200 citations. En conséquence, Yuri Boyko, Oleg Tyagnibok, Andrey Sadovoy et Vladimir Zelensky sont sortis de l'analyse. Il reste 1 667 citations dans le tableau. Sur les six orateurs restants, quatre (à l'exception de Groysman et Rabinovich) sont des candidats inscrits pour la prochaine élection présidentielle.
Les citations varient du court, environ 30 caractères (
"J'ai déjà soumis 112 factures." ) Au long, environ 1 200 caractères. La longueur moyenne d'une citation est d'environ 200 caractères (par exemple,
«Bientôt, nous devrons donner un peu moins une vache pour un musée et un dinosaure pour les enfants dans les sciences de la nature - pour le résultat de la politique politique, pour que les yaks effectuent un séjour de novice. Bétail de moins de 2 mois . " )
TF-IDF
Voyons d'abord quels mots sont plus caractéristiques de certains locuteurs. Voici les 10 premiers mots avec le TF-IDF le plus élevé pour chaque candidat:

En bref sur TF-IDFTF-IDF (terme fréquence - fréquence inverse du document) est un indicateur qui évalue l'importance d'un mot dans le contexte d'un document. Les mots TF-IDF sont proportionnels à la fréquence d'utilisation de ce mot dans le document et inversement proportionnels à la fréquence d'utilisation du mot dans tous les documents de la collection. Dans le contexte de nos données, un TF-IDF élevé signifie qu'un politicien utilise souvent ce mot, tandis que d'autres politiciens l'utilisent relativement moins.
Pour compter TF-IDF, la racine a été utilisée - amenant le mot à la base.
Ces mots que je voudrais commenter pour chaque intervenant afin de donner un peu de contexte sont surlignés en vert.
Oleg Lyashko:- Pologne: Lyashko mentionne souvent la Pologne dans le cadre de la migration de travail des Ukrainiens là-bas, et compare également les revenus en Pologne et en Ukraine
- Céréales: Lyashko dit que l'Ukraine exporte des céréales et y perd, car il pourrait être plus cher d'exporter de la farine
- Oncologie, médicaments: Lyashko est un ardent opposant à la réforme médicale actuelle et dit souvent que le coût de l'oncologie n'est presque pas couvert par l'État
Porochenko et
Gritsenko parlent beaucoup du conflit militaire, ce qui est tout à fait logique: Porochenko est le président et, par conséquent, le commandant en chef suprême, et Gritsenko est militaire et était ministre de la Défense.
Groisman est le Premier ministre et parle principalement de l'économie, y compris de la dette publique.
Les citations de
Vadim Rabinovich ne montrent pas de sujets spécifiques, peut-être parce qu’il parle beaucoup (444 de 1952, tous les autres ont moins de 300 citations).
Ioulia Timochenko parle beaucoup du réseau de transport de gaz de l'Ukraine, de la liquidation des banques, ainsi que des faibles indicateurs économiques du pays.
Classification des devis
Donc, nous obtenons 6 classes (haut-parleurs). Pour la classification, j'ai utilisé le classificateur naïf bayésien. Les mots vides des langues russe et ukrainienne sont exclus du texte (en utilisant le package de mots vides). N-grammes jusqu'à 2 sont inclus (des options d'une longueur allant jusqu'à 3 ont également été testées, mais ont montré un sur-ajustement). L'échantillon d'essai est prélevé dans une proportion de 20% du total.
La précision totale du modèle (la proportion de citations correctement classées) dans l'échantillon de formation était de
74,8% , dans l'échantillon de test -
75,7%Résultats croisés par auteurs:

La précision la plus élevée pour Vadim Rabinovich (97%) - probablement parce qu'il est le seul russophone sur six. Haute précision de classification de Groisman et Lyashko (78% et 77%).
Un peu plus de 60% sont les indicateurs de précision pour citer Porochenko et Timochenko. Le modèle définit plus souvent les deux comme Groysman. Groysman, en tant que Premier ministre, parle souvent de l'économie sous la forme d'un «rapport d'étape», et les citations incorrectement classées de Porochenko et Timochenko en parlent également (seul Porochenko en tant que représentant du gouvernement est positif, mais Timochenko a le contraire).
Par exemple, voici une citation de Porochenko définie par le modèle comme une citation de Groisman:
5 milliards d'UAH, (tobto) 4 milliards d'UAH de cette roche »et 1 milliard d'UAH de la roche entière directement pour la médecineEt aussi une citation de Timochenko, définie comme une citation de Groisman:
Dans le budget offensif pour l'utilisation des prisons, ils ont vu deux fois moins de sous, pas moins que la science, pour travailler à l'Académie des sciences d'Ukraine.La plus faible précision (57%) entre guillemets d'Anatoly Gritsenko. Son modèle est souvent défini comme Porochenko (ce qui est logique, compte tenu des sujets militaires de leurs citations), ainsi que Lyashko. Dans le cas de Lyashko, la mauvaise classification est des citations critiquant les autorités, y compris, par exemple, sur la migration:
je ne semble pas parler du même membre de votre ordre, Volodimir Borisovich, pan Klimkin disant que des millions ont quitté le pays.En général, il me semble que le résultat n'est pas mauvais pour des citations aussi courtes d'un format similaire (déclarations orales de politiciens) et de sujets (politique ukrainienne). Soit dit en passant, sur les mêmes données, j'ai essayé de faire un modèle qui définit la catégorie de citation (vrai / faux / manipulation), mais la précision était très faible. Ce qui, en principe, est logique: en regardant une citation comme «Tant d'argent a été dépensé pour cela, mais dans un tel pays, ils dépensent tellement», il est difficile de déterminer la véracité des données qu'il contient :)