Introduction du traducteur
Cet article concerne Erlang , mais tout ce qui est dit est également applicable à Elixir , un langage fonctionnel qui s'exécute au-dessus de la même machine virtuelle BEAM . Il est apparu en 2012 et se développe activement. Elixir a obtenu la syntaxe la plus familière, ainsi que de vastes capacités de métaprogrammation , tout en conservant les avantages d'Erlang.
Plus du traducteurUn article de 2016, mais il s'agit de concepts de base qui n'expirent pas.
Les références aux concepts et commentaires de ma part (le traducteur) sont situées entre crochets [] et sont marquées d'une «note du traducteur».
Si vous trouvez que certaines parties de la traduction ne sont pas suffisamment correctes, en particulier en termes de termes, ou si vous rencontrez d'autres erreurs, veuillez me le faire savoir, je le corrigerai avec plaisir.
Un merci spécial à Jan Gravshin pour son aide dans la relecture et l'édition du texte.
Ceci est une transcription gratuite (ou une longue paraphrase?) De ma présentation à la conférence ConnectDev'16 organisée par Genetec.

Je crois que la plupart des gens ici n'ont jamais programmé à Erlang. Vous en avez peut-être entendu parler ou vous connaissez le nom. Par conséquent, ma présentation n'affectera que les concepts de haut niveau d'Erlang, et de manière à être utile dans votre travail ou vos projets parallèles, même si vous ne rencontrez jamais cette langue.

Si vous avez déjà été intéressé par Erlang, alors vous avez entendu parler de la devise "Let it crash" [ "Let it fall" - env. traducteur ]. Ma première rencontre avec lui m'a fait me demander de quoi il s'agissait. Erlang était censé être idéal pour l'exécution multithread et la tolérance aux pannes, mais ici, ils suggèrent que je laisse tout tomber: l'exact opposé du comportement du système que je veux vraiment. La proposition est surprenante, mais, néanmoins, le Zen d'Erlang y est directement lié.

Dans un sens, utiliser "Let it Crash" pour Erlang est aussi amusant que "Blow it up" [ " Blow it !" - env. traducteur ] pour la science des fusées. "Faire sauter" est peut-être la dernière chose que vous voulez en science des fusées, et la catastrophe du Challenger en est un rappel vivant. D'un autre côté, si vous regardez la situation différemment, les fusées et tout leur système de propulsion sont confrontés à des carburants dangereux qui peuvent et vont exploser (et c'est un moment risqué), mais de manière tellement contrôlée qu'ils peuvent être utilisés pour organiser l'espace voyager ou envoyer des charges utiles en orbite.
Et le point ici est vraiment en contrôle; vous pouvez essayer de considérer la science des fusées comme un moyen d'apprivoiser correctement les explosions - ou du moins leur puissance - pour faire ce que vous voulez avec elles. À son tour, vous pouvez regarder "Let it crash" sous le même angle: il s'agit de la tolérance aux pannes. L'idée n'est pas dans les échecs non contrôlés répandus, c'est de transformer les échecs, les exceptions et les plantages en outils utilisables.

Automne imminent [Automne imminent - env. traducteur ] et le recuit contrôlé est un véritable exemple de lutte contre le feu par le feu. Au Saguenay-lac-Saint-Jean, la région d'où je viens, les bleuetières sont régulièrement brûlées de façon contrôlée afin de stimuler et de reprendre leur croissance. Très souvent, vous pouvez voir des zones malsaines de la forêt nettoyées par le feu pour éviter les incendies de forêt, de sorte que cela se produise sous une supervision et un contrôle appropriés. L'objectif principal est d'éliminer les matériaux combustibles afin qu'un feu naturel ne puisse pas se propager davantage.
Dans toutes ces situations, la puissance destructrice du feu qui balaie les cultures ou les forêts est utilisée pour soigner les cultures ou empêcher la destruction incontrôlée beaucoup plus importante des forêts.
Je pense que la signification de "Let it crash" est exactement cela. Si nous pouvons tirer parti des échecs, des plantages et des exceptions, et en faire un moyen gérable, alors ils cesseront d'être cet événement effrayant qui doit être évité, et en retour se transformera en un élément de construction puissant pour assembler de grands systèmes fiables.

Ainsi, la question devient de savoir comment garantir que les échecs soient plus constructifs que destructeurs. La puce principale à Erlang est le processus. Les processus Erlang sont complètement isolés et ont une architecture indissociable (ne rien partager). Aucun processus ne peut ramper dans la mémoire d'un autre ou affecter le travail qu'il fait en déformant les données utilisées. C'est bien car cela signifie qu'un processus de mort avec une garantie à 100% gardera ses problèmes pour lui-même et fournira à votre système une très forte isolation des pannes.
Les processus d'Erlang sont également extrêmement légers, de sorte que des milliers et des milliers d'entre eux peuvent fonctionner simultanément sans problème. L'idée est d'utiliser autant de processus que nécessaire , plutôt que le plus possible . Imaginez qu'il existe un langage de programmation orienté objet dans lequel à tout moment il est permis d'avoir un maximum de 32 objets fonctionnant simultanément. Vous arriveriez rapidement à la conclusion que pour créer des programmes dessus, les restrictions sont trop strictes et plutôt ridicules. La présence de nombreux petits processus offre une plus grande variabilité des pannes. Dans un monde où nous voulons mettre le pouvoir de l'échec au service, c'est bien!
Le mécanisme des processus à Erlang peut sembler un peu étrange. Lorsque vous écrivez un programme en C, vous avez une grande fonction main() qui fait une tonne de tout. Il s'agit du point d'entrée du programme. Il n'y a rien de tel à Erlang. Aucun des processus n'est le principal. Chaque processus lance une fonction, et cette fonction joue le rôle de main() ce processus particulier.
Nous avons maintenant un essaim d'abeilles, mais il doit être très difficile de les envoyer pour renforcer la ruche si elles ne peuvent en aucun cas communiquer. Où les abeilles dansent [les abeilles dansent - env. traducteur ], Erlang traite la messagerie.

La messagerie est la forme de communication la plus intuitive dans un environnement concurrentiel. Elle est l'une des personnes les plus âgées à traiter, depuis l'époque où nous écrivions des lettres et les envoyions par des coursiers à cheval, à des mécanismes plus bizarres comme les sémaphores de Napoléon [ sémaphore optique - env. traducteur ] montré dans l'illustration. Dans ce dernier cas, vous envoyez simplement un groupe de gars dans les tours, leur donnez un message et ils agitent des drapeaux pour transmettre des données sur de longues distances de manière plus rapide que les chevaux fatigués. Peu à peu, cette méthode a été remplacée par un télégraphe, qui, à son tour, a changé le téléphone et la radio, et maintenant nous avons toutes ces technologies à la mode pour envoyer des messages très loin et très rapidement.
Un aspect extrêmement important de tous ces messages, surtout dans l'ancien temps, est que tout était asynchrone et que les messages étaient copiés. Personne ne s'est tenu sur son porche toute la journée en attendant le retour du courrier et personne (je soupçonne) n'était assis près du sémaphore, attendant une réponse. Vous avez envoyé un message et êtes retourné à votre entreprise, et au fil du temps, quelqu'un vous a informé qu'une réponse était arrivée.
C'est bien - si l'autre côté ne répond pas, vous ne serez pas coincé sur votre véranda jusqu'à votre mort. Inversement, le destinataire, en revanche, ne sera pas confronté au fait qu'un message récemment arrivé a soudainement disparu ou changé par magie si vous êtes décédé subitement. Les données doivent être copiées lors de l'envoi de messages. Ces deux principes garantissent qu'une défaillance pendant la communication ne conduit pas à un état déformé ou irréparable [ état - env. traducteur ]. Erlang implémente les deux.
Chaque processus a sa propre boîte aux lettres pour tous les messages entrants. Tout le monde peut écrire dans la boîte aux lettres de processus, mais seul le propriétaire de la boîte a la possibilité de l'examiner. Par défaut, les messages sont traités dans l'ordre où ils sont reçus, mais certaines fonctionnalités telles que la correspondance de modèle [ correspondance de modèle - env. traducteur ] vous permet de modifier les priorités et de vous concentrer constamment ou temporairement sur n'importe quel type de message.

Certains d'entre vous remarqueront l'étrangeté de ce que je dis. Je continue de répéter que l'isolement et l'indépendance sont si merveilleux que les composants du système peuvent mourir et tomber sans affecter le reste. Mais j'ai également mentionné la communication entre de nombreux processus ou agents.
Chaque fois au début du dialogue de deux processus, une dépendance implicite entre eux apparaît. Un état implicite apparaît dans le système qui les relie tous les deux. Si le processus A envoie un message au processus B et que B meurt sans répondre, A peut soit attendre une réponse indéfiniment, soit refuser de communiquer après un certain temps. La seconde est une stratégie acceptable, mais elle est très ambiguë: il est totalement difficile de savoir si le côté distant est mort ou a été occupé pendant si longtemps, et les messages sans contexte peuvent atterrir dans votre boîte aux lettres.
En retour, Erlang nous donne deux mécanismes pour résoudre ce problème: les moniteurs et la liaison [ liens - env. traducteur ].
Les moniteurs, c'est être un observateur. Vous décidez de garder un œil sur le processus, et s'il meurt pour une raison quelconque, un message vous informera de ce qui s'est passé dans votre boîte de réception. Vous pouvez y répondre et prendre des décisions en fonction des informations trouvées. Le deuxième processus ne saura jamais que vous avez fait tout cela. Par conséquent, les moniteurs sont assez bons si vous êtes un observateur. traducteur ] ou prendre soin du statut du partenaire.
Liens [ liens - env. traducteur ] - bidirectionnel, et la création de l'un combine le sort des deux processus connexes. Lorsqu'un processus meurt, tous les processus qui lui sont associés reçoivent une commande de fin [ signal de sortie - env. traducteur ]. Cette équipe, à son tour, tue les autres [ liés - env. traducteur ] processus.
Tout cela devient vraiment intéressant, car vous pouvez utiliser des moniteurs pour détecter rapidement les pannes, et vous pouvez utiliser la liaison comme une conception architecturale qui vous permet de combiner plusieurs processus afin que la panne se propage à eux dans leur ensemble. Chaque fois que mes blocs de construction indépendants deviennent dépendants les uns des autres, je peux commencer à ajouter cela au programme. Ceci est utile car il empêche le système de tomber accidentellement dans des états instables et partiellement modifiés. Les connexions garantissent aux développeurs: si quelque chose s'est cassé, alors il s'est complètement cassé, laissant derrière lui une feuille vierge, et en aucun cas affecté les composants qui n'ont pas participé à l'exercice.
Pour cette illustration, j'ai choisi l'image de grimpeurs attachés avec une corde de sécurité. Si les grimpeurs ne sont connectés que les uns aux autres, ils se retrouveront dans une position misérable. Chaque fois qu'un seul grimpeur glisse, le reste de l'équipe meurt immédiatement. Pas un bon moyen de faire des affaires.
Au lieu de cela, Erlang vous permet de spécifier que certains processus sont spéciaux et de les marquer avec le paramètre trap_exit . Ils pourront ensuite recevoir des commandes de sortie envoyées via les communications et les convertir en messages. Cela leur permettra de dépanner et éventuellement de télécharger un nouveau processus pour achever le travail du défunt. Contrairement aux grimpeurs, un processus spécial de ce type ne peut pas empêcher le processus de partenariat de tomber; c'est déjà la responsabilité du partenaire lui-même, implémentée, par exemple, en utilisant try ... catch constructions try ... catch . Le processus, qui capte les sorties, n'a toujours pas la possibilité de jouer dans la mémoire d'un autre et de le sauver, mais peut éviter la mort commune.
Cela devient une opportunité cruciale pour créer des superviseurs. Nous y parviendrons très bientôt.

Avant de passer aux superviseurs, examinons les quelques ingrédients restants qui nous permettront de préparer avec succès un système qui utilise des gouttes pour notre propre bénéfice. L'un d'eux est lié au fonctionnement du planificateur de processus. Le vrai cas auquel je voudrais faire référence est l'atterrissage sur la lune d'Apollo 11 [ Apollo 11 - env. traducteur ].
Apollo 11 est une mission qui est allée sur la lune en 1969. Dans l'image, nous voyons le module lunaire avec Buzz Aldrin et Neil Armstrong à bord, et la photo a été prise, je crois, par Michael Collins, qui est resté dans le module de commande.
Sur le chemin de l'atterrissage sur la lune, le module était contrôlé par Apollo PGNCS (système de guidage, de navigation et de contrôle principal) [ Apollo PGNCS - env. traducteur ]. Le système de contrôle a effectué plusieurs tâches avec un nombre de cycles soigneusement calculé [ CPU - env. traducteur ] chacun. La NASA a également constaté que le processeur ne devrait pas être utilisé à plus de 85% de sa capacité, avec 15% gratuits en stock.
Comme les astronautes voulaient avoir un plan de sauvegarde fiable au cas où ils devaient interrompre la mission, ils ont laissé le radar de la réunion avec le module de commande et de service allumé - cela serait utile. Cela a décemment chargé la puissance CPU restante. Dès que Buzz Aldrin a commencé à entrer des commandes, des messages ont commencé à apparaître sur la surcharge et, en fait, sur le dépassement de la puissance de calcul disponible. Si le système s'était éloigné de cela, alors il n'aurait probablement pas pu faire son travail, et tout se serait terminé avec deux astronautes morts.
Tout d'abord, la surcharge s'est produite parce que le radar avait un problème matériel connu, entraînant une inadéquation de sa fréquence avec la fréquence de l'ordinateur de contrôle, ce qui a entraîné un "vol" d'un nombre de cycles beaucoup plus important que celui qui serait utilisé autrement. Les gens de la NASA n'étaient pas des idiots, et au lieu d'utiliser de nouvelles technologies qui n'ont pas été testées dans la vie réelle pour une mission aussi importante, ils ont réutilisé des composants éprouvés, dont ils connaissaient de rares erreurs. Mais, plus important encore, ils ont proposé une planification prioritaire.
Cela signifie que lorsque ce radar, ou peut-être les commandes entrées, mettent trop de charge sur le processeur, leurs tâches ont été tuées pour donner des cycles CPU aux choses vitales qui ont une priorité plus élevée et qui en ont vraiment besoin. C'était en 1969. Aujourd'hui, il y a beaucoup plus de langages et de cadres qui n'offrent que la répartition coopérative et rien de plus.
Erlang n'est pas un langage qui devrait être utilisé pour les systèmes vitaux, il ne prend en compte que les contraintes douces en temps réel - env. traducteur ], et pas des restrictions strictes en temps réel, et donc l'utiliser pour de tels scénarios ne serait pas une bonne idée. Mais Erlang fournit une planification proactive [ elle est une planification préemptive, env. traducteur ] et priorisation des processus. Cela signifie que vous, en tant que développeur ou architecte système, n'avez pas à vous assurer que, pour éviter les gels, tout le monde calcule soigneusement la charge CPU requise pour ses composants (y compris les bibliothèques utilisées). Ils ne peuvent tout simplement pas obtenir un tel pouvoir. Et si vous souhaitez effectuer une tâche importante chaque fois que vous en avez besoin, vous pouvez également la fournir.
Cela ne ressemble pas à une demande sérieuse ou fréquente, et les gens lancent toujours des projets vraiment réussis basés uniquement sur la planification coopérative de processus parallèles, mais cela est certainement extrêmement précieux, car cela vous protège des erreurs des autres, ainsi que des vôtres. Cela ouvre également la porte à des mécanismes tels que l'équilibrage automatique de la charge, «punir les mauvais» ou «encourager les bons» processus, ou attribuer des priorités plus élevées aux processus avec plus de tâches. Tout cela rend finalement vos systèmes suffisamment adaptables aux charges et aux événements imprévus.

Le dernier élément que j'aimerais aborder dans le cadre de la garantie d'une résilience décente est la capacité de travailler sur le réseau. Dans tout système développé dans l'optique d'une activité à long terme, la capacité de fonctionner sur plusieurs ordinateurs devient rapidement une exigence obligatoire. Vous ne voulez pas vous asseoir quelque part enfermé derrière des portes en titane avec votre voiture dorée, ne pouvant pas compenser les défaillances qui affectent principalement vos utilisateurs.
Tôt ou tard, vous aurez besoin de deux ordinateurs, de sorte que l'un survit à l'échec du second, et éventuellement du troisième, si vous souhaitez déployer une partie de votre système lors de pannes.
L'avion dans l'illustration - F-82 Twin Mustang [ F-82 Twin Mustang - env. traducteur ], un avion conçu pendant la Seconde Guerre mondiale pour escorter des bombardiers sur des distances que la plupart des autres combattants ne pouvaient tout simplement pas couvrir. Il avait deux cabines, afin que les pilotes puissent contrôler l'appareil par équipes; au bon moment, il a été possible de répartir les responsabilités afin qu'un pilote puisse piloter l'avion, et le second - les radars de contrôle dans le rôle d'intercepteur. Les avions modernes ont toujours des capacités similaires; ils ont d'innombrables systèmes en double, et souvent les membres d'équipage dorment pendant le vol, de sorte qu'il y a toujours quelqu'un prêt, si nécessaire, à prendre immédiatement le contrôle de l'avion.
Quant aux langages de programmation ou aux environnements de développement, la plupart d'entre eux sont conçus sans possibilité de travail distribué, bien qu'il soit clair que lors du développement d'une pile de serveurs, vous devrez travailler avec plus d'un serveur. Néanmoins, si vous allez travailler avec des fichiers, il existe des outils pour cela dans la bibliothèque standard. Le maximum que la plupart des langues peuvent vous donner est le support de socket ou un client HTTP.
Erlang rend hommage à la réalité des systèmes distribués et propose une implémentation pour leur création, documentée et transparente. , , - [ pylyglot systems — . ].

" ". - , . "Let it crash" , , .
— .

[ supervision trees — . ] — , . — , — — , . , — "OTP", , "Erlang/OTP" [ OTP — Open Telecom Platform — . ].
— , , , , , "" . , : , , .
, , , , — .
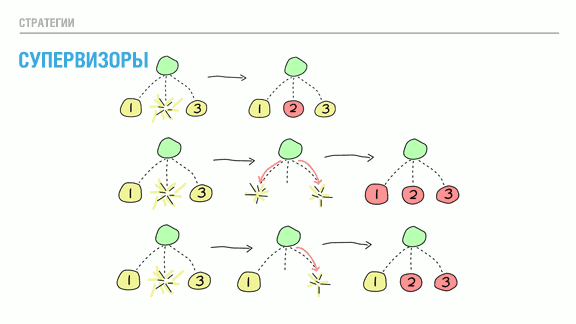
. " , ". , . .
. " " [ one for one — . *]. . , .
— " " [ one for all — . *]. , . , , . , . , . , , . , , !
, , , . , . : , .
, . — " " [ rest for one — . ]. , , . .
[ , — — . ] . 1 , 150 .

, , " , !"
. , , , . "" [ — . ] "" [ — . ], Jim Gray 1985 ( Jim Gray, !)
-, — , , . . , , . , , , , .
— , , , . , , . , , .
, , .

, — .
, . , , .
, — , , . , — ; . , , . , , , .
, , .
. , , [ Property-Based Testing Basics , Property-based testing — . ] ( ), — - , . , , , .

( ). , , .
, . , , , , . - -.
. , , , , , , .
, . Jim Gray, , , 132 , , . 131 132 , , . , , , , ; , , , 100 000 , — 10 , - .
, , .

?
, . . , . , , . , "" Facebook ( ), , , Facebook .
, , , , . , , .
, . : , , , , .
, ( ), , . , .

, , . , , , .
, , .
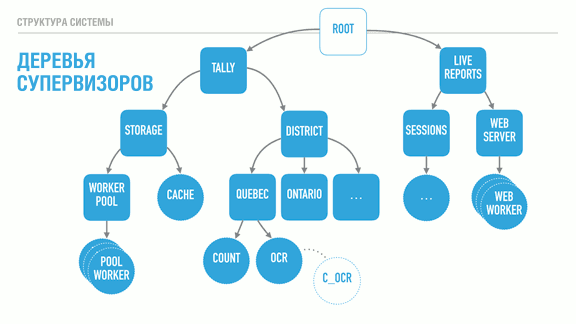
() . , : . Tally () , Live Reports ( ) .
, . District (; ) , (Storage). (Cache) ( ) (Worker pool).
[ supervision strategies — . ], , , , . , " ", , , . ( ) " ". , (OCR) , , . , , , , .
OCR , C , . , C, , , .
, , , . 10 , , , .
, , . , . — , .
, , , . OCR C , . OCR . . , , ( ). , , — , .
OCR , . , , — . — . , , , , - , .
, . , — - , - ( ) , . , — , . — let it crash!
. , if/else , switch ', try/catch . , , , . [ , — . ], .
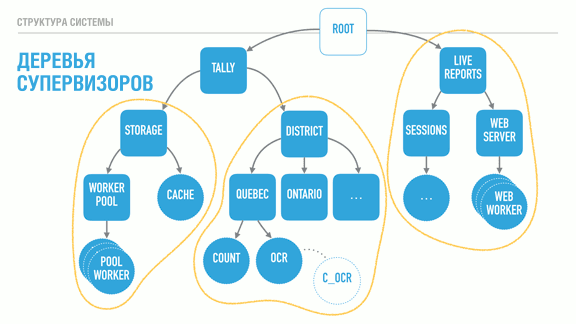
, , , , . : , .
, , , . (, SMS).
, , , , , .
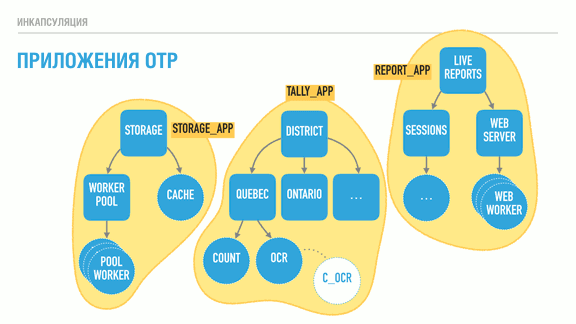
OTP. OTP- — , . , , . , , , . , , , .
, OTP- . OTP-, . [: OTP-, , ]
:
- , ;
- , , , ;
- , ;
- , , , , ;
- ( , );
- .
. , . , , . , — , , .

, ? , . , Heroku .
. (vegur) , , , . , , .
- , . , : 500 000 1 000 000 ! , . ? , , , 100 000 , ? - 1:17000 1:7000. , , , .
, . , , , . , . , , .

. .
, - : " , . , , , . , , . , ."
. .
, , , 60 . ( United 734), , , , - . , , , , ABS, .
( ), . , . , , .
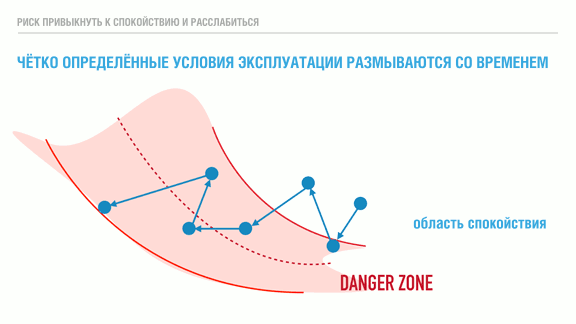
, . ( , ) Richard Cook. , YouTube, .
- . , , , .. — ( , , ..) , , - , .
, , , . , , - - .
, , , . , . , . - - , , , .

, . , , : , . . , , , .
, , , . .

, , . , , , .
. , , , - , , , , , . , .

, 'let it crash' — , , , , , — , , , . . fail-fast , , " ", .
, . , , . . , , . Let it crash.

: , , , — . , ( , !) .