Cette semaine, la NSA (
National Security Agency ) a soudainement fait un cadeau à l'humanité, ouvrant les sources de son framework de reverse engineering logiciel. La communauté des ingénieurs inversés et des experts en sécurité avec un grand enthousiasme a commencé à explorer le nouveau jouet. Selon les commentaires, c'est un outil vraiment incroyable, capable de rivaliser avec les solutions existantes, telles que IDA Pro, R2 et JEB. L'outil s'appelle Ghidra et les ressources professionnelles regorgent d'impressions de chercheurs. En fait, ils avaient une bonne raison: tous les jours, les organisations gouvernementales ne donnent pas accès à leurs outils internes. Moi-même en tant qu'ingénieur inversé professionnel et analyste de logiciels malveillants ne pouvait pas passer aussi bien. J'ai décidé de passer un week-end ou deux et d'avoir une première impression de l'outil. J'avais un peu joué avec le démontage et décidé de vérifier l'extensibilité de l'outil. Dans cette série d'articles, je vais expliquer le développement du module complémentaire Ghidra, qui charge le format personnalisé, utilisé pour résoudre la tâche CTF. Comme c'est un grand framework et que j'ai choisi une tâche assez compliquée, je vais diviser l'article en plusieurs parties.
À la fin de cette partie, j'espère configurer un environnement de développement et construire un module minimal, qui sera capable de reconnaître le format du fichier WebAssembly et proposera le bon désassembleur pour le traiter.
Commençons par la description de la tâche. L'année dernière, la société de sécurité FireEye a organisé un concours CTF, nommé flare-on. Pendant le concours, les chercheurs ont dû résoudre douze tâches liées à la rétro-ingénierie. L'une des tâches consistait à rechercher l'application Web, construite avec WebAssembly. C'est un format exécutable relativement nouveau, et pour autant que je sache, il n'y a pas d'outils parfaits pour y faire face. Pendant le défi, j'ai essayé plusieurs outils pour essayer de le vaincre. Il s'agissait de scripts simples de github et de décompilateurs connus, tels que IDA pro et JEB. Étonnamment, je me suis arrêté sur Chrome, qui fournit un assez bon démonteur et débogueur pour WebAssembly. Mon objectif est de résoudre le défi avec le ghidra. Je vais décrire l'étude aussi complètement que possible et donner toutes les informations possibles pour reproduire mes étapes. Peut-être qu'en tant que personne qui n'a pas beaucoup d'expérience avec l'instrument, je pourrais entrer dans des détails inutiles, mais c'est comme ça.
La tâche que je vais utiliser pour l'étude peut être téléchargée sur le
site du défi flareon5. Il y a le fichier 05_web2point0.7z: archive chiffrée avec un mot effrayant
infecté . Il y a trois fichiers dans l'archive: index.html, main.js et test.wasm. Ouvrons le fichier index.html dans un navigateur et vérifions le résultat:
Eh bien, c'est avec ça que je vais travailler. Commençons par l'étude html, d'autant plus que c'est la partie la plus simple du défi. Le code html ne contient rien sauf le chargement du script main.js.
<!DOCTYPE html> <html> <body> <span id="container"></span> <script src="./main.js"></script> </body> </html>
Le script ne fait rien de compliqué non plus, même s'il semble un peu plus bavard. Il charge simplement le fichier test.wasm et l'utilise pour créer une instance WebAssembly. Il lit ensuite le paramètre «q» de l'url et le passe à la correspondance de méthode, exportée par l'instance. Si la chaîne dans le paramètre est incorrecte, le script affiche l'image que nous avons vue ci-dessus, en termes de développeurs FireEye appelés "Pile of poo".
let b = new Uint8Array(new TextEncoder().encode(getParameterByName("q"))); let pa = wasm_alloc(instance, 0x200); wasm_write(instance, pa, a); let pb = wasm_alloc(instance, 0x200); wasm_write(instance, pb, b); if (instance.exports.Match(pa, a.byteLength, pb, b.byteLength) == 1) {
La solution de la tâche consiste à trouver la valeur du paramètre q qui fait que la fonction «match» renvoie «True». Pour ce faire, je vais démonter le fichier test.wasm et analyser l'algorithme de la fonction Match.
Il n'y a pas de surprise et je vais essayer de le faire à Ghidra. Mais je dois d'abord l'installer. L'installation peut (et doit) être téléchargée à partir de
https://ghidra-sre.org/ . Comme il est écrit en Java, il n'y a presque pas d'exigences particulières à l'installation, il ne nécessite aucun effort particulier pour l'installation. Tout ce dont vous avez besoin est de décompresser l'archive et d'exécuter l'application. La seule chose requise est de mettre à jour JDK et JRE vers la version 11.
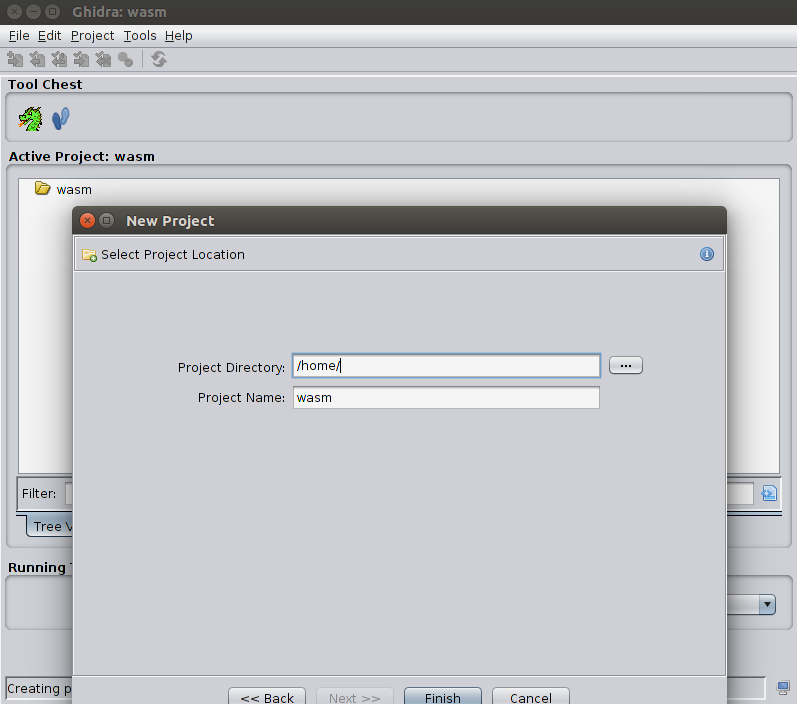
Créons un nouveau projet ghidra (
Fichier-> Nouveau projet ), et appelons-le «wasm» /
Ajoutez ensuite pour projeter le fichier test.wasm (
Fichier → Importer un fichier ) et voyez comment ghidra peut y faire face
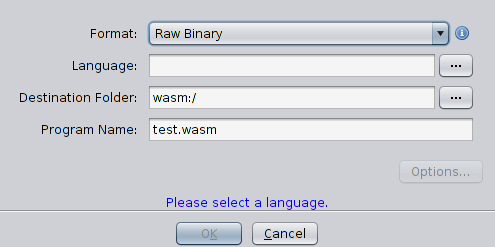
Eh bien, ça ne peut rien faire. Il ne reconnaît pas le format et ne peut rien démonter, il est donc absolument impuissant de faire face à cette tâche. Enfin, nous sommes arrivés au sujet de l'article. Il n'y a plus rien à faire, mais écrire un module, qui est capable de charger un fichier wasm, de l'analyser et de démonter son code.
J'ai tout d'abord étudié toute la documentation disponible. En fait, il n'y a qu'un seul document approprié, montrant le processus de développement des modules complémentaires: slides GhidraAdvancedDevelopment. Je vais suivre le document, en donnant une description au coup par coup.
Malheureusement, le développement de modules complémentaires nécessite l'utilisation d'Eclipse. Toute mon expérience avec eclipse est le développement de deux jeux gdx pour Android en 2012. Cela avait été deux semaines pleines de douleur et de souffrance, après quoi je l'ai effacé de mon esprit. J'espère qu'après 7 ans de développement, c'est mieux qu'avant.
Téléchargeons et installons eclipse depuis le site
officiel .
Ensuite, installez l'extension pour le développement ghidra:
Allez à l'
aide d' Eclipse
→ dans le menu
Installer un nouveau logiciel , cliquez sur le bouton
Ajouter et choisissez GhidraDev.zip dans / Extensions / Eclipse / GhidraDev /. Installez-le et redémarrez l'extension. L'extension, ajoute des modèles au nouveau menu du projet, permet de déboguer les modules de l'éclipse et de compiler le module vers le package de distribution.
Comme il résulte des documents des développeurs, les étapes suivantes doivent être effectuées pour ajouter un module de traitement du nouveau format binaire:
- Créer des classes, décrivant les structures de données
- Développer le chargeur. Le chargeur doit être hérité de la classe AbstractLibrarySupportLoader . Il lit toutes les données nécessaires du fichier, vérifie l'intégrité des données et convertit les données binaires en représentation interne, les préparant à l'analyse
- Développer l'analyseur. Analyzer est hérité de la classe AbstractAnalyzer . Il prend les structures de données préparées par le chargeur et les annote (je ne sais pas vraiment ce que cela signifie, mais j'espère comprendre pendant le développement)
- Ajoutez un processeur. Ghidra a une abstraction: Processeur. Il est écrit dans un langage déclaratif interne et décrit l'ensemble d'instructions, la disposition de la mémoire et d'autres caractéristiques architecturales. Je vais couvrir ce sujet, en écrivant le démonteur.
Maintenant, quand nous avons toute la théorie nécessaire, il est temps de créer le projet de module. Grâce à l'extension d'éclipse GhidraDev précédemment installée, nous avons le modèle de module directement dans le
menu Fichier-> Nouveau projet .
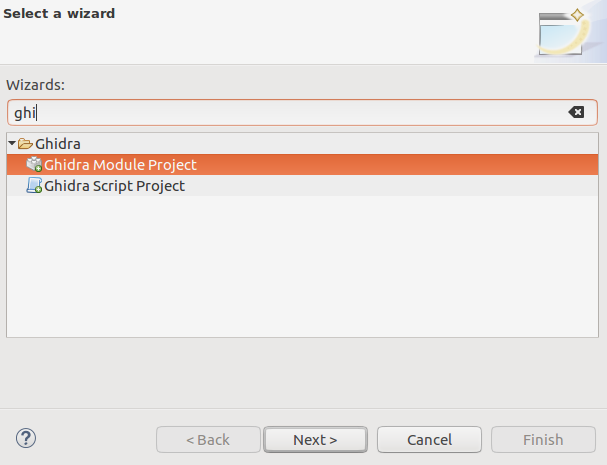
L'assistant demande quels composants sont requis. Comme cela a été décrit précédemment, nous aurions besoin de deux d'entre eux: chargeur et analyseur.
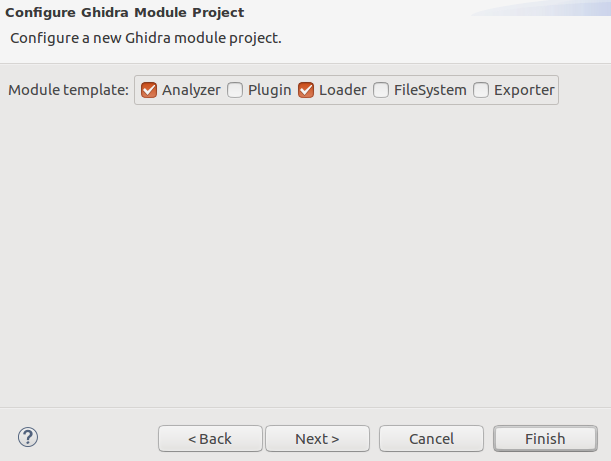
L'assistant crée le squelette du projet avec toutes les parties nécessaires: analyseur vide dans le fichier WasmAnalyzer.java, chargeur vide dans le fichier WasmLoader.java et squelette de langue dans le répertoire / data / languages.
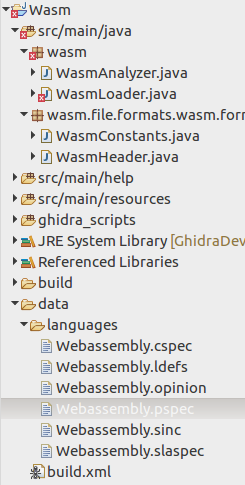
Commençons par le chargeur. Comme il a été mentionné, il doit être hérité de la classe AbstractLibrarySupportLoader et dispose de trois méthodes à surcharger:
- getName - cette méthode doit être le nom interne du chargeur. Ghidra l'utilise à divers endroits, par exemple, pour lier le chargeur au processeur
- findSupportedLoadSpecs - rappel, exécuté, lorsque l'utilisateur a choisi le fichier à importer. Dans ce rappel, le chargeur doit décider s'il est capable de traiter le fichier et de renvoyer l'instance de la classe LoadSpec, indiquant à l'utilisateur comment le fichier peut être traité
- load - rappel, exécuté, après le fichier chargé par l'utilisateur. Dans cette méthode, le chargeur analyse la structure des fichiers et les charge dans ghidra. Le décrira plus en détail dans le prochain article
La première et la méthode la plus simple est getName, elle retourne simplement le nom du chargeur
public String getName() { return "WebAssembly"; }
La deuxième méthode à implémenter est findSupportedLoadSpecs. Il est appelé par outil lors de l'importation du fichier et doit vérifier si le chargeur est capable de traiter le fichier. Si sa méthode est capable retourne l'objet de la classe
LoadSpec , indiquant quel objet est utilisé pour charger le fichier et quel processeur désassemble son code.
La méthode démarre à partir de la vérification du format. Comme il résulte de la
spécification , les huit premiers octets du fichier wasm doivent être la signature «\ 0asm» et la version.
Pour analyser l'en-tête, j'ai créé la classe WasmHeader, implémentant l'interface
StructConverter , qui est l'interface de base pour décrire les données structurées. Le constructeur du WasmHeader reçoit l'objet
BinaryReader - abstraction, utilisé pour lire les données de la source binaire en cours d'analyse. Le constructeur l'utilise pour lire l'en-tête du fichier d'entrée
private byte[] magic; private byte [] version; public WasmHeader(BinaryReader reader) throws IOException { magic = reader.readNextByteArray(WASM_MAGIC_BASE.length()); version = reader.readNextByteArray(WASM_VERSION_LENGTH); }
Le chargeur utilise cet objet pour vérifier la signature du fichier. Ensuite, en cas de succès, recherche le processeur approprié. Il appelle la requête de méthode de la classe
QueryOpinionService et lui transmet le nom du chargeur («Webassembly»). OpinionService recherche le processeur associé à ce chargeur et le renvoie.
List<QueryResult> queries = QueryOpinionService.query(getName(), MACHINE, null);
Bien sûr, il ne renvoie rien, car ghidra ne connaît pas le processeur, appelé WebAssembly et il doit le définir. Comme je l'ai déjà dit, l'assistant a créé le squelette de la langue dans le répertoire data / languages.
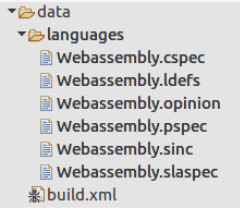
Au stade actuel, il existe deux fichiers qui pourraient être intéressants: Webassembly.opinion et Wbassembly.ldefs. Le fichier .opinon définit la correspondance entre le chargeur et le processeur.
<opinions> <constraint loader="WebAssembly" compilerSpecID="default"> <constraint primary="1" processor="Webassembly" size="16" /> </constraint> </opinions>
Il contient du xml simple avec peu d'attributs. Il est nécessaire de définir le nom du chargeur dans l'attribut «chargeur» et le nom du processeur dans l'attribut «processeur», les deux sont «Webassembly». À cette étape, je remplirai d'autres paramètres avec les valeurs aléatoires. Dès que j'en saurai plus sur l'architecture du processeur Webassembly, je les changerai en valeurs correctes.
Le fichier .ldefs décrit les fonctionnalités du processeur, qui devrait exécuter le code à partir du fichier.
<language_definitions> <language processor="Webassembly" endian="little" size="16" variant="default" version="1.0" slafile="Webassembly.sla" processorspec="Webassembly.pspec" id="wasm:LE:16:default"> <description>Webassembly Language Module</description> <compiler name="default" spec="Webassembly.cspec" id="default"/> </language> </language_definitions>
Le «processeur» d'attributs doit être le même que le processeur d'attributs du fichier .opinion. Laissons les autres champs intacts. Mais rappelez-vous la prochaine fois qu'il est possible de définir la morsure du registre (attribut "taille"), le fichier décrivant l'architecture du processeur "processorspec" et le fichier, contenant la description du code en langage déclaratif spécial "slafile". Il sera utile de travailler sur le démontage.
Maintenant, il est temps de revenir au chargeur et de retourner les spécifications du chargeur.
Tout est prêt pour le test. Le plugin pour GhidraDev a ajouté l'option d'exécution «
Exécuter → Exécuter en tant que → Ghidra » pour éclipser:
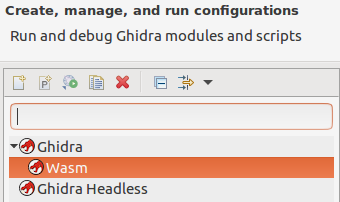
Il exécute ghidra en mode débogage et y déploie le module, offrant une excellente occasion de travailler avec l'outil et en même temps d'utiliser le débogueur pour corriger les erreurs dans le module en cours de développement. Mais à ce stade simple, il n'y a aucune raison d'utiliser un débogueur. Comme précédemment, je vais créer un nouveau projet, importer un fichier et voir si mes efforts ont porté leurs fruits. Contrairement à la dernière fois, le fichier est reconnu comme WebAssembly, et le chargeur propose le processeur correspondant pour lui. Cela signifie que tout fonctionne, et mon module est capable de reconnaître le format.
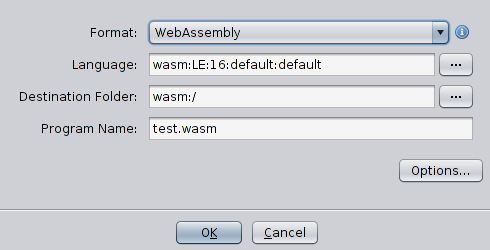
Dans le prochain article, je vais étendre le chargeur et le faire non seulement reconnaître, mais aussi décrire la structure du fichier wasm. Je pense qu'à ce stade, après la mise en place de l'environnement, ce sera facile à faire.
Le code du module est disponible sur le dépôt
github .