
Apache Spark est aujourd'hui peut-être la plate-forme la plus populaire pour analyser des données à grand volume. Une contribution considérable à sa popularité est apportée par la possibilité de l'utiliser sous Python. En même temps, tout le monde convient que, dans le cadre de l'API standard, les performances du code Python et Scala / Java sont comparables, mais il n'y a pas de point de vue unique concernant les fonctions définies par l'utilisateur (User Defined Function, UDF). Essayons de comprendre comment les frais généraux augmentent dans ce cas, en utilisant l'exemple de la tâche de vérification de la solution SNA Hackathon 2019 .
Dans le cadre du concours, les participants résolvent le problème du tri du fil d'actualité d'un réseau social et téléchargent des solutions sous forme d'un ensemble de listes triées. Pour vérifier la qualité de la solution obtenue, tout d'abord, pour chacune des listes chargées, l' ASC ROC est calculée, puis la valeur moyenne est affichée. Veuillez noter que vous devez calculer non pas une AUC ROC commune, mais une AUC personnelle pour chaque utilisateur - il n'y a pas de conception prête à l'emploi pour résoudre ce problème, vous devrez donc écrire une fonction spécialisée. Une bonne raison de comparer les deux approches dans la pratique.
Comme plate-forme de comparaison, nous utiliserons un conteneur cloud avec quatre cœurs et Spark lancés en mode local, et nous travaillerons avec lui via Apache Zeppelin . Pour comparer les fonctionnalités, nous reproduirons le même code dans PySpark et Scala Spark. [ici] Commençons par charger les données.
data = sqlContext.read.csv("sna2019/modelCappedSubmit") trueData = sqlContext.read.csv("sna2019/collabGt") toValidate = data.withColumnRenamed("_c1", "submit") \ .join(trueData.withColumnRenamed("_c1", "real"), "_c0") \ .withColumnRenamed("_c0", "user") \ .repartition(4).cache() toValidate.count()
val data = sqlContext.read.csv("sna2019/modelCappedSubmit") val trueData = sqlContext.read.csv("sna2019/collabGt") val toValidate = data.withColumnRenamed("_c1", "submit") .join(trueData.withColumnRenamed("_c1", "real"), "_c0") .withColumnRenamed("_c0", "user") .repartition(4).cache() toValidate.count()
Lors de l'utilisation de l'API standard, l'identité presque complète du code est remarquable, jusqu'au mot clé val . Le temps de fonctionnement n'est pas significativement différent. Essayons maintenant de déterminer l'UDF dont nous avons besoin.
parse = sqlContext.udf.register("parse", lambda x: [int(s.strip()) for s in x[1:-1].split(",")], ArrayType(IntegerType())) def auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores)) auc_udf = sqlContext.udf.register("auc", auc, DoubleType())
val parse = sqlContext.udf.register("parse", (x : String) => x.slice(1,x.size - 1).split(",").map(_.trim.toInt)) case class AucAccumulator(height: Int, area: Int, negatives: Int) val auc_udf = sqlContext.udf.register("auc", (byScore: Seq[Int], gt: Seq[Int]) => { val byLabel = gt.toSet val accumulator = byScore.foldLeft(AucAccumulator(0, 0, 0))((accumulated, current) => { if (byLabel.contains(current)) { accumulated.copy(height = accumulated.height + 1) } else { accumulated.copy(area = accumulated.area + accumulated.height, negatives = accumulated.negatives + 1) } }) (accumulator.area).toDouble / (accumulator.negatives * accumulator.height) })
Lors de l'implémentation d'une fonction spécifique, il est clair que Python est plus concis, principalement en raison de la possibilité d'utiliser la fonction intégrée scikit-learn . Cependant, il y a des moments désagréables - vous devez spécifier explicitement le type de la valeur de retour, alors que dans Scala, elle est automatiquement déterminée. Réalisons l'opération:
toValidate.select(auc_udf(parse("submit"), parse("real"))).groupBy().avg().show()
toValidate.select(auc_udf(parse($"submit"), parse($"real"))).groupBy().avg().show()
Le code semble presque identique, mais les résultats sont décourageants.

L'implémentation sur PySpark a fonctionné une minute et demie au lieu de deux secondes sur Scala, c'est-à-dire que Python s'est avéré 45 fois plus lent . Lors de l'exécution, top affiche 4 processus Python actifs qui s'exécutent à pleine vitesse, ce qui suggère que le verrouillage d'interprète global ne crée pas de problèmes ici. Mais! Le problème réside peut-être dans l'implémentation interne de scikit-learn - essayons de reproduire le code Python littéralement, sans recourir à des bibliothèques standard.
def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) auc_udf_modified = sqlContext.udf.register("auc_modified", auc, DoubleType()) toValidate.select(auc_udf_modified(parse("submit"), parse("real"))).groupBy().avg().show()

L'expérience montre des résultats intéressants. D'une part, avec cette approche, la productivité a été nivelée, mais d'autre part, le laconicisme a disparu. Les résultats obtenus peuvent indiquer que lorsque vous travaillez en Python à l'aide de modules C ++ supplémentaires, des frais généraux importants apparaissent pour basculer entre les contextes. Bien sûr, il y a des frais généraux similaires lors de l'utilisation de JNI en Java / Scala, cependant, je n'ai pas eu à traiter 45 fois d'exemples de dégradation lors de leur utilisation.
Pour une analyse plus détaillée, nous allons effectuer deux expériences supplémentaires: utiliser du Python pur sans Spark pour mesurer la contribution de l'invocation du package, et avec une taille de données accrue dans Spark pour amortir les frais généraux et obtenir une comparaison plus précise.
def parse(x): return [int(s.strip()) for s in x[1:-1].split(",")] def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) def sklearn_auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores))
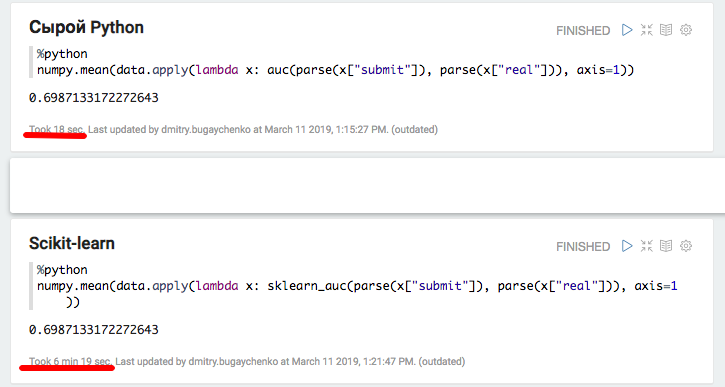
L'expérience avec Python et Pandas locaux a confirmé l'hypothèse de frais généraux importants lors de l'utilisation de packages supplémentaires - lors de l'utilisation de scikit-learn, la vitesse diminue de plus de 20 fois. Cependant, 20 n'est pas 45 - essayons de «gonfler» les données et de comparer à nouveau les performances de Spark.
k4 = toValidate.union(toValidate) k8 = k4.union(k4) m1 = k8.union(k8) m2 = m1.union(m1) m4 = m2.union(m2).repartition(4).cache() m4.count()

La nouvelle comparaison montre l'avantage de vitesse d'une implémentation Scala sur Python de 7 à 8 fois - 7 secondes contre 55. Enfin, essayons "le plus rapide qui soit en Python" - numpy pour calculer la somme du tableau:
import numpy numpy_sum = sqlContext.udf.register("numpy_sum", lambda x: float(numpy.sum(x)), DoubleType())
val my_sum = sqlContext.udf.register("my_sum", (x: Seq[Int]) => x.map(_.toDouble).sum)
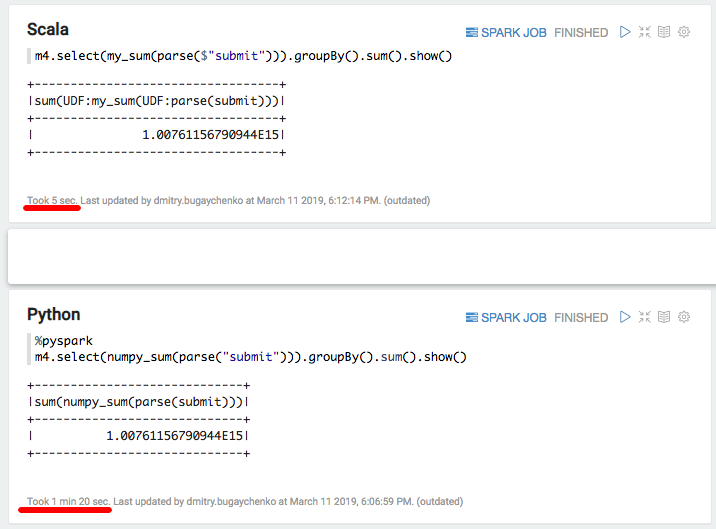
Encore un ralentissement significatif - 5 secondes de Scala contre 80 secondes de Python. En résumé, nous pouvons tirer les conclusions suivantes:
- Bien que PySpark fonctionne dans le cadre de l'API standard, sa vitesse peut vraiment être comparable à Scala.
- Lorsqu'une logique spécifique apparaît sous la forme de fonctions définies par l'utilisateur, les performances de PySpark diminuent sensiblement. Avec suffisamment d'informations, lorsque le temps de traitement d'un bloc de données dépasse plusieurs secondes, l'implémentation Python est 5-10 plus lente en raison de la nécessité de déplacer les données entre les processus et de gaspiller des ressources lors de l'interprétation de Python.
- Si l'utilisation de fonctions supplémentaires implémentées dans les modules C ++ apparaît, des coûts d'appel supplémentaires se produisent et la différence entre Python et Scala augmente jusqu'à 10 à 50 fois.
En conséquence, malgré tout le charme de Python, son utilisation en conjonction avec Spark ne semble pas toujours justifiée. S'il n'y a pas tellement de données pour rendre la surcharge Python significative, alors vous devriez vous demander si Spark est nécessaire ici? S'il y a beaucoup de données, mais que le traitement a lieu dans le cadre de l'API Spark SQL standard, Python est-il nécessaire ici?
S'il y a beaucoup de données et que vous devez souvent gérer des tâches qui dépassent les limites de l'API SQL, alors pour effectuer la même quantité de travail lorsque vous utilisez PySpark, vous devrez augmenter considérablement le cluster. Par exemple, pour Odnoklassniki, le coût des dépenses en capital du cluster Spark augmenterait de plusieurs centaines de millions de roubles. Et si vous essayez de tirer parti des capacités avancées des bibliothèques de l'écosystème Python, c'est-à-dire que le risque de ralentissement n'est pas seulement ponctuel, mais d'un ordre de grandeur.
Une certaine accélération peut être obtenue en utilisant la fonctionnalité relativement nouvelle des fonctions vectorisées. Dans ce cas, pas une seule ligne n'est envoyée à l'entrée UDF, mais un paquet de plusieurs lignes sous la forme d'un cadre de données Pandas. Cependant, le développement de cette fonctionnalité n'est pas encore terminé , et même dans ce cas, la différence sera significative .
Une alternative serait de maintenir une vaste équipe d'ingénieurs de données, capable de répondre rapidement aux besoins des scientifiques des données avec des fonctions supplémentaires. Ou pour vous immerger dans le monde Scala, car ce n'est pas si difficile: de nombreux outils nécessaires existent déjà, des programmes de formation apparaissent qui vont au-delà de PySpark.