Alexander Rubin travaille à Percona et a joué à
HighLoad ++ plus d'une fois, familier aux participants en tant qu'expert de MySQL. Il est logique de supposer qu'aujourd'hui nous parlerons de quelque chose lié à MySQL. Il en est ainsi, mais seulement en partie, car nous parlerons également de l'
Internet des objets . L'histoire sera à moitié divertissante, en particulier sa première partie, dans laquelle nous examinons l'appareil qu'Alexandre a créé pour récolter les abricots. Telle est la nature d'un véritable ingénieur - si vous voulez des fruits, vous achetez des frais.

Contexte
Tout a commencé par un simple désir de planter un arbre fruitier dans sa région. Il semblerait très simple de le faire - vous venez au magasin et achetez un semis. Mais en Amérique, la première question que se posent les vendeurs est la quantité de lumière solaire que l'arbre recevra. Pour Alexander, cela s'est avéré être un mystère géant - on ignore complètement la quantité de lumière solaire sur le site.
Pour le savoir, un élève peut sortir chaque jour dans la cour, voir combien de soleil et l'écrire dans un cahier. Mais ce n'est pas le cas - il faut tout équiper et automatiser.
Pendant la présentation, de nombreux exemples ont été présentés et joués en direct. Vous voulez une image plus complète que dans le texte, passez à regarder la vidéo.Ainsi, afin de ne pas enregistrer les observations météorologiques dans un ordinateur portable, il existe un grand nombre d'appareils pour les objets Internet - Raspberry Pi, le nouveau Raspberry Pi, Arduino - des milliers de plates-formes différentes. Mais j'ai choisi un appareil appelé
Particle Photon pour ce projet. Il est très facile à utiliser, coûte 19 $ sur le site officiel.
La bonne chose à propos du photon à particules est:
- Solution 100% cloud;
- Tous les capteurs conviennent, par exemple, à Arduino. Ils coûtent tous moins d'un dollar.
J'ai fabriqué un tel appareil et l'ai mis dans l'herbe sur le site. Il dispose d'un nuage de périphériques de particules et d'une console. Cet appareil se connecte via un point d'accès Wi-Fi et envoie des données: lumière, température et humidité. Le testeur a duré 24 heures sur une petite batterie, ce qui est plutôt bien.
De plus, je dois non seulement mesurer l'éclairage, etc., et les transférer sur le téléphone (ce qui est vraiment bien - je peux voir en temps réel le type d'éclairage que j'ai), mais aussi
stocker des données . Pour cela, naturellement, en tant que vétéran de MySQL, j'ai choisi MySQL.
Comment écrire des données dans MySQL
J'ai choisi un schéma assez compliqué:
- J'obtiens des données de la console Particle;
- J'utilise Node.js pour les écrire sur MySQL.
J'utilise l'API Particle JS, qui peut être téléchargée sur le site Web de Particle. J'établis une connexion avec MySQL et j'écris, c'est-à-dire que je fais juste INSÉRER DES valeurs. Un tel pipeline.
Ainsi, l'appareil se trouve dans la cour, se connecte via Wi-Fi au routeur domestique et à l'aide du protocole MQTT transfère les données à Particle. Ensuite, le schéma même: le programme sur Node.js s'exécute sur la machine virtuelle, qui reçoit les données de Particle et les écrit dans MySQL.
Pour commencer, j'ai construit les graphiques à partir des données brutes de R. Les graphiques montrent que la température et l'illumination augmentent pendant la journée, tombent la nuit et que l'humidité augmente - c'est naturel. Mais il y a aussi du bruit sur le graphique, ce qui est typique pour les appareils Internet of Things. Par exemple, lorsqu'un bogue rampe sur un appareil et le ferme, le capteur peut transmettre des données complètement non pertinentes. Cela sera important pour un examen plus approfondi.
Parlons maintenant de MySQL et JSON, ce qui a changé en travaillant avec JSON de MySQL 5.7 à MySQL 8. Ensuite, je vais montrer une démo pour laquelle j'utilise MySQL 8 (au moment du rapport, cette version n'était pas encore prête pour la production, une version stable a déjà été publiée).
Stockage de données MySQL
Lorsque nous essayons de stocker les données reçues des capteurs, notre première pensée est
de créer une table dans MySQL :
CREATE TABLE 'sensor_wide' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'light' int (11) DEFAULT NULL, 'temp' double DEFAULT NULL, 'humidity' double DEFAULT NULL, PRIMARY KEY ('id') ) ENGINE=InnoDB
Ici, pour chaque capteur et pour chaque type de données, il y a une colonne: lumière, température, humidité.
C'est assez logique, mais
il y a un problème - ce n'est pas flexible . Supposons que nous voulons ajouter un autre capteur et mesurer autre chose. Par exemple, certaines personnes mesurent la bière restante dans un fût. Que faire dans ce cas?
alter table sensor_wide add water level double ...;
Comment pervertir pour ajouter quelque chose à la table? Vous devez faire une table alter, mais si vous avez fait une table alter dans MySQL, alors vous savez de quoi je parle - c'est complètement difficile. Modifier la table dans MySQL 8 et MariaDB est beaucoup plus simple, mais historiquement, c'est un gros problème. Donc, si nous devons ajouter une colonne, par exemple, avec le nom de la bière, ce ne sera pas si simple.
Encore une fois, les capteurs apparaissent, disparaissent, que faire des anciennes données? Par exemple, nous cessons de recevoir des informations sur l'éclairage. Ou créons-nous une nouvelle colonne - comment stocker ce qui n'existait pas auparavant? L'approche standard est nulle, mais pour l'analyse, elle ne sera pas très pratique.
Une autre option est un magasin de clés / valeurs.
Stockage de données MySQL: clé / valeur
Il sera
plus flexible : dans la clé / valeur, il y aura un nom, par exemple, la température et en conséquence les données.
CREATE TABLE 'cloud_data' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' text DEFAULT NULL, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB
Dans ce cas,
un autre problème apparaît
- il n'y a pas de types . Nous ne savons pas ce que nous stockons dans le champ «données». Nous devrons le déclarer comme un champ de texte. Lorsque je crée mon appareil Internet des objets, je sais de quel type de capteur il s'agit et en conséquence le type, mais si vous devez stocker les données de quelqu'un d'autre dans le même tableau, je ne saurai pas quelles données sont collectées.
Vous pouvez stocker de nombreuses tables, mais la création d'une toute nouvelle table pour chaque capteur n'est pas très bonne.
Que peut-on faire? - Utilisez JSON.
Stockage de données MySQL: JSON
La bonne nouvelle est que dans MySQL 5.7, vous pouvez stocker JSON en tant que champ.
CREATE TABLE 'cloud_data_json' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' JSON, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB;
Avant l'apparition de MySQL 5.7, les gens stockaient également JSON, mais sous forme de champ de texte. Le champ JSON dans MySQL vous permet de stocker le JSON lui-même plus efficacement. De plus, basé sur JSON, vous pouvez créer des colonnes virtuelles et des index basés sur eux.
Le seul problème mineur est
que la table augmentera de taille pendant le stockage . Mais alors nous obtenons beaucoup plus de flexibilité.
Le champ JSON est meilleur pour stocker le JSON que le champ de texte car:
- Fournit une validation automatique des documents . Autrement dit, si nous essayons d'écrire quelque chose qui n'est pas valide, une erreur se produira.
- Il s'agit d'un format de stockage optimisé . JSON est stocké au format binaire, ce qui vous permet de passer d'un document JSON à un autre - ce qu'on appelle sauter.
Pour stocker des données dans JSON, nous pouvons simplement utiliser SQL: faire un INSERT, y mettre des «données» et obtenir des données de l'appareil.
… stream.on('event', function(data) { var query = connection.query( 'INSERT INTO cloud_data_json (client_name, data) VALUES (?, ?)', ['particle', JSON.stringify(data)] ) … (demo)
Démo
Pour démontrer (
ici son début dans la vidéo) l'exemple utilise une machine virtuelle dans laquelle il y a du SQL.

Voici un fragment du programme.
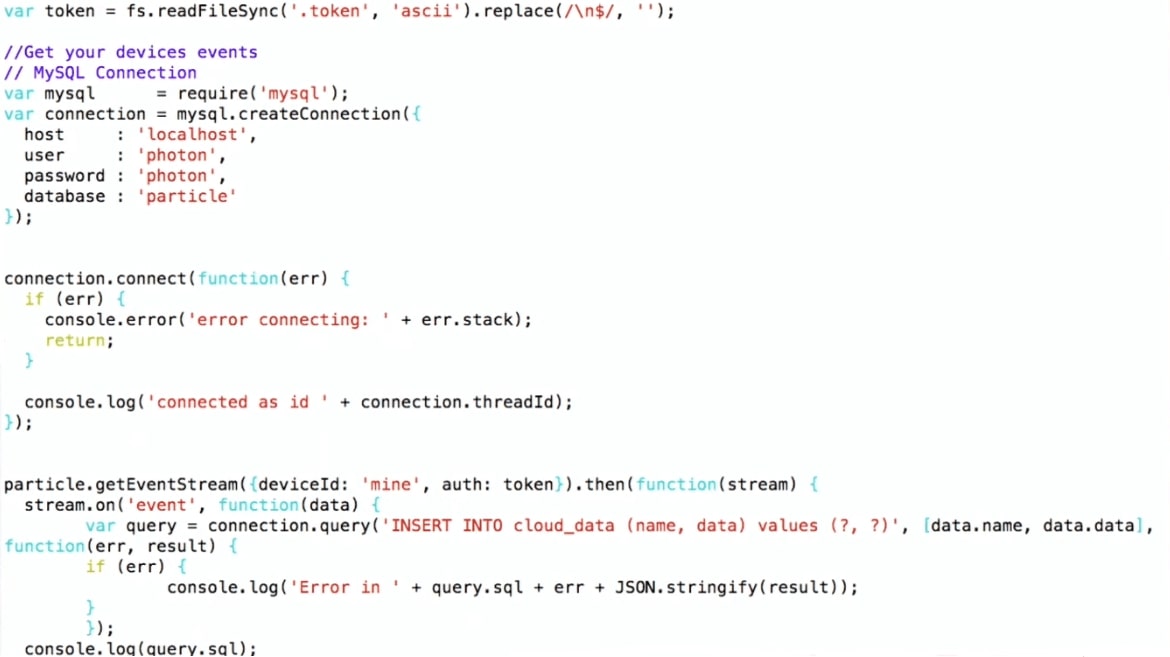
INSERT INTO cloud_data (name, data) , j'obtiens les données déjà au format JSON, et je peux les écrire directement dans MySQL tel quel, sans penser complètement à ce qu'il y a à l'intérieur.
Il s'est avéré qu'en utilisant ce nuage, vous pouvez accéder non seulement aux données de mon appareil, mais généralement à
toutes les données utilisées par cette particule. Cela semble fonctionner jusqu'à présent. Les gens qui utilisent Particle Photon dans le monde entier envoient des données: la porte du garage est ouverte, ou le reste de la bière est tel ou tel, ou autre chose. On ne sait pas où se trouvent ces appareils, mais ces données peuvent être obtenues. La seule différence est que lorsque j'obtiens mes données, j'écris quelque chose comme:
deviceId: 'mine' .
Lorsque nous exécutons le code, nous obtenons un flux de données provenant des appareils de quelqu'un d'autre qui font quelque chose.
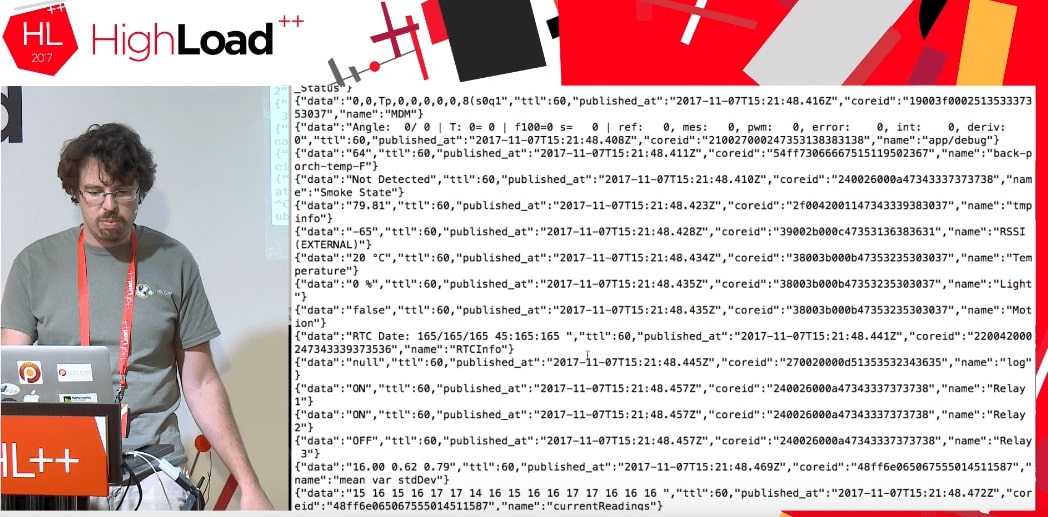
Nous ne savons absolument pas quelles sont ces données: TTL, published_at, coreid, état de la porte (porte ouverte), relais activé.
Ceci est un excellent exemple. Supposons que j'essaie de mettre cela dans MySQL dans une structure de données normale. Je devrais savoir ce que la porte est là, pourquoi elle est ouverte et quels paramètres généraux elle peut prendre. Si j'ai JSON, je l'écris directement dans MySQL en tant que champ JSON.
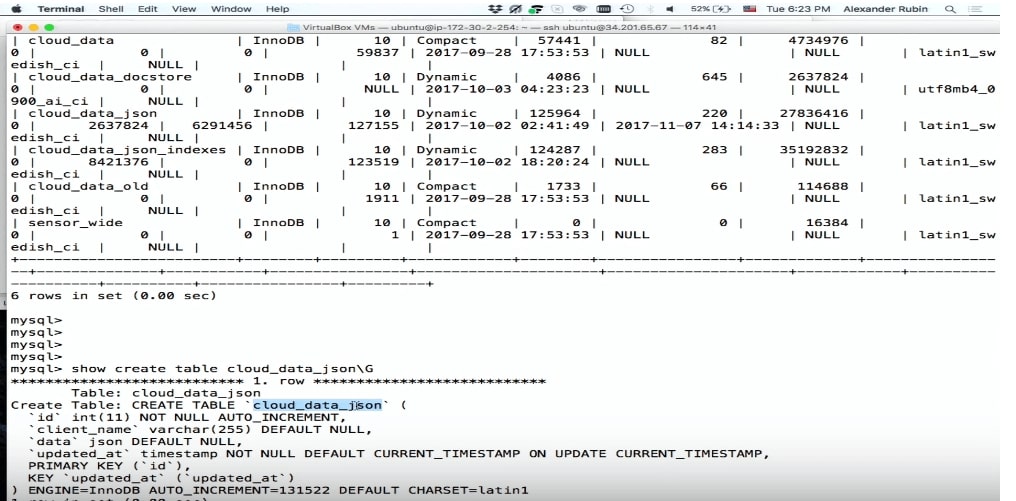
S'il vous plaît, tout a été enregistré.
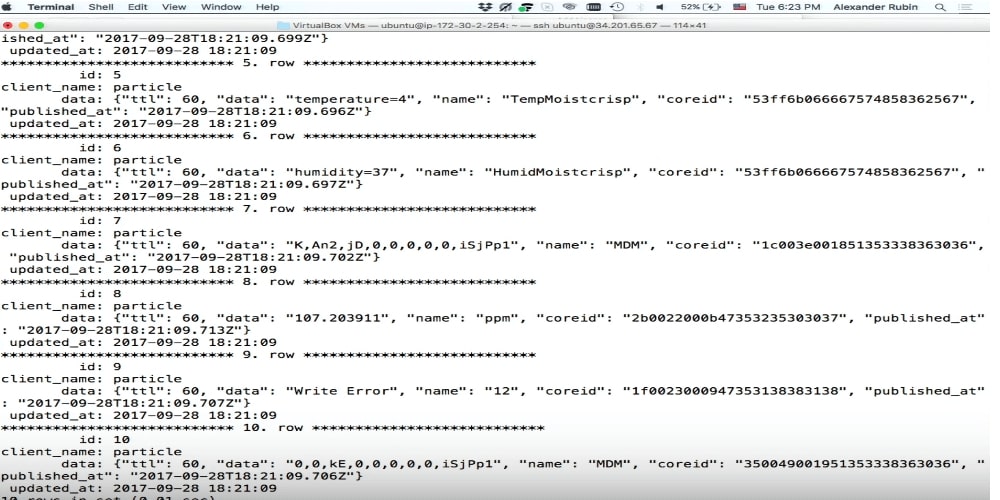
Magasin de documents
Le magasin de documents est une tentative dans MySQL de faire du stockage pour JSON. J'aime vraiment SQL, je le connais bien, je peux faire n'importe quelle requête SQL, etc. Mais beaucoup de gens n'aiment pas SQL pour diverses raisons, et le magasin de documents peut être une solution pour eux, car avec lui, vous pouvez abstraire de SQL, vous connecter à MySQL et y écrire directement JSON.

Il existe une autre possibilité qui est apparue dans MySQL 5.7: utiliser un protocole différent, un port différent et un autre pilote est également nécessaire. Pour Node.js (en fait, pour tout langage de programmation - PHP, Java, etc.), nous nous connectons à MySQL en utilisant un protocole différent et pouvons transférer des données au format JSON. Encore une fois, je ne sais pas ce que j'ai dans ce JSON - des informations sur les portes ou autre chose, je vide simplement les données dans MySQL, puis nous le découvrirons.
const mysqlx = require('@mysql/xdevapi*); // MySQL Connection var mySession = mysqlx.gctSession({ host: 'localhost', port: 33060, dbUser: 'photon* }); … session.getSchema("particle").getCollection("cloud_data_docstore") .add( data ) .execute(function (row) { }).catch(err => { console.log(err); }) .then( -Function (notices) { console.log("Wrote to MySQL") }); ...https:
Si vous voulez expérimenter cela, vous pouvez configurer MySQL 5.7 afin qu'il comprenne et écoute sur le port approprié Document store ou X DevAPI. J'ai utilisé connector-nodejs.
Ceci est un exemple de ce que j'écris là-bas: bière, etc. Je ne sais absolument pas ce qu'il y a. Maintenant, nous l'écrivons et l'analysons plus tard.

Le prochain point de notre programme est de savoir comment voir ce qu'il y a?
Stockage de données MySQL: index JSON +
Il existe une excellente fonctionnalité dans JSON et MySQL 5.7 qui peut extraire des champs de JSON. Il s'agit d'un tel sucre syntaxique sur la fonction JSON_EXTRACT. Je pense que c'est très pratique.
Dans notre cas, les données sont le nom de la colonne dans laquelle JSON est stocké et le nom est notre champ. Name, data, published_at - c'est tout ce que nous pouvons retirer de cette façon.
select data->>'$.name' as data_name, data->>'$.data' as data, data->>'$.published_at' as published from cloud_data_json order by data->'$.published_at' desc limit 10;
Dans cet exemple, je veux voir ce que j'ai écrit dans la table MySQL et les 10 derniers enregistrements. Je fais une telle demande et essaie de l'exécuter. Malheureusement,
cela fonctionnera très longtemps .
De manière logique, MySQL n'utilisera aucun index dans ce cas. Nous extrayons les données de JSON et essayons d'appliquer une sorte de filtre et de tri. Dans ce cas, nous obtenons Using filesort.
EXPLAIN select data->>'$.name' as data_name ... order by data->>'$.published_at' desc limit 10 select_type: SIMPLE table: cloud_data_json possible_keys: NULL key: NULL … rows: 101589 filtered: 100.00 Extra: Using filesort
L'utilisation de filesort est très mauvaise, c'est une sorte externe.
La bonne nouvelle est que vous pouvez prendre 2 mesures pour l'accélérer.
Étape 1. Créez une colonne virtuelle
mysql> ALTER TABLE cloud_data_json -> ADD published_at DATETIME(6) -> GENERATED ALWAYS AS (STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ")) VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
Je fais EXTRAIT, c'est-à-dire que je tire des données de JSON et que je crée une colonne virtuelle à partir de cela. La colonne virtuelle n'est pas stockée dans MySQL 5.7 et dans MySQL 8 - c'est juste la possibilité de créer une colonne séparée.
Vous demandez comment c'est, vous avez dit que ALTER TABLE est une opération si longue. Mais ici, ce n'est pas si mal.
La création d'une colonne virtuelle est rapide . Il y a là un problème, mais en fait dans MySQL il y a un verrou sur toutes les opérations DDL. ALTER TABLE est une opération assez rapide et ne reconstruit pas la table entière.
Nous avons créé une colonne virtuelle ici. J'ai dû convertir la date, car en JSON, elle est stockée au format iso, mais ici MySQL utilise un format complètement différent. Pour créer une colonne, je l'ai nommée, je lui ai donné un type et j'ai dit que j'y enregistrerais.
Pour optimiser la requête d'origine, vous devez extraire published_at et name. Published_at existe déjà, le nom est plus facile - créez simplement une colonne virtuelle.
mysql> ALTER TABLE cloud_data_json -> ADD data_name VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.name') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
Étape 2. Création d'un index
Dans le code ci-dessous, je crée un index sur published_at et exécute la requête:
mysql> alter table cloud_data_json add key (published_at); Query OK, 0 rows affected (0.31 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G table: cloud_data_json type: index possible_keys: NULL key: published_at key_len: 9 rows: 10 filtered: 100.00 Extra: Backward index scan
Vous pouvez voir que MySQL utilise réellement l'index. Il s'agit d'une optimisation par commande. Dans cet exemple, les données et le nom ne sont pas indexés. MySQL utilise l'ordre par données, et puisque nous avons un index sur published_at, il l'utilise.
De plus, je pourrais utiliser la même syntaxe sucre
STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ") au lieu de published_at dans l'ordre. MySQL comprendrait toujours qu'il y a un index sur cette colonne et commencerait à l'utiliser.
Il y a en fait un petit problème avec cela. Supposons que je veuille trier les données non seulement par published_at, mais aussi par nom.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc, data_name asc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 101589 filtered: 100.00 Extra: Using filesort
Si votre appareil traite des dizaines de milliers d'événements par seconde, published_at ne donnera pas un bon tri, car il y aura des doublons. Par conséquent, nous ajoutons un autre tri par nom_données. Il s'agit d'une requête typique non seulement pour l'Internet des objets: donnez-moi les 10 derniers événements, mais triez-les par date, puis, par exemple, par nom de famille de la personne dans l'ordre croissant. Pour cela, dans l'exemple ci-dessus, il y a deux champs et deux clés de tri sont spécifiées: décroissante et ascendante.
Tout d'abord, dans ce cas, MySQL n'utilisera pas d'index. Dans ce cas particulier, MySQL décide qu'une analyse complète de la table sera plus rentable que l'utilisation d'un index, et là encore, l'opération de tri de fichiers très lente est utilisée.
Nouveau dans MySQL 8.0
décroissant / croissant
Dans MySQL 5.7, une telle requête ne peut pas être optimisée, ne serait-ce qu'au détriment d'autres choses. Dans MySQL 8, il y avait une réelle opportunité de spécifier le tri pour chaque champ.
mysql> alter table cloud_data_json add key published_at_data_name (published_at desc, data_name asc); Query OK, 0 rows affected (0.44 sec) Records: 0 Duplicates: 0 Warnings: 0
La chose la plus intéressante est que la clé décroissante / ascendante après le nom de l'index a longtemps été en SQL. Même dans la toute première version de MySQL 3.23, vous pouviez spécifier published_at descending ou published_at ascending. MySQL a accepté cela,
mais n'a rien fait , c'est-à-dire qu'il a toujours trié dans une direction.
Dans MySQL 8, cela a été corrigé et maintenant il existe une telle fonctionnalité. Vous pouvez créer un champ par ordre décroissant et avec un tri par défaut.
Revenons en arrière une seconde et regardons à nouveau l'exemple de l'étape 2.
Pourquoi ça marche, sinon ça ne marche pas? Cela fonctionne car dans les index MySQL, il s'agit d'un arbre B, et les index B peuvent être lus à la fois depuis le début et la fin. Dans ce cas, MySQL lit l'index depuis la fin et tout va bien. Mais si nous descendons et montons, vous ne pouvez pas lire. Vous pouvez lire dans le même ordre, mais
vous ne pouvez pas combiner deux tris - vous devez trier à nouveau.
Puisque nous optimisons un cas très spécifique, nous pouvons créer un index pour lui et spécifier un tri spécifique: ici published_at est décroissant, data_name est croissant. MySQL utilise cet index, et tout ira bien et rapidement.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: index possible_keys: NULL key: published_at_data_name key_len: 267 ref: NULL rows: 10 filtered: 100.00 Extra: NULL
Il s'agit d'une fonctionnalité de MySQL 8, qui est maintenant, au moment de la publication, déjà disponible et prêt à être utilisé en production.
Résultats de sortie
Il y a deux autres choses intéressantes que je veux montrer:
1. Jolie impression, c'est-à-dire une belle sortie de données à l'écran. Avec SELECT normal, JSON ne sera pas formaté.
mysql> select json_pretty(data) from cloud_data_json where data->>'$.data' like '%beer%' limit 1\G … json_pretty(data): { "ttl": 60, "data": "FvGav,tagkey=beer-store spFridge=7.00,pvFridge=7.44", "name": "LOG_DATA_DEBUG", "coreid": "3600....", "published_at": "2017-09-28T18:21:16.517Z" }
2. Nous pouvons dire que MySQL affichera le résultat sous la forme d'un tableau JSON ou d'un objet JSON, spécifier les champs, puis la sortie sera formatée en JSON.
Recherche plein texte dans les documents JSON
Si nous utilisons un système de stockage flexible et ne savons pas ce qui se trouve à l'intérieur de notre JSON, il serait logique d'utiliser la recherche en texte intégral.
Malheureusement, la
recherche en texte intégral a ses limites . La première chose que j'ai essayée était juste de créer une clé de texte intégral. J'ai essayé de faire une chose pareille:
mysql> alter table cloud_data_json_indexes add fulltext key (data); ERROR 3152 (42000): JSON column 'data' supports indexing only via generated columns on a specified ISON path.
Malheureusement, cela ne fonctionne pas. Même dans MySQL 8, la création d'un index de texte intégral simplement par le champ JSON est malheureusement impossible. Bien sûr, je voudrais avoir une telle fonction - la possibilité de rechercher au moins par les clés JSON serait très utile.
Mais si ce n'est pas encore possible, créons une colonne virtuelle. Dans notre cas, il y a un champ de données, et il serait intéressant pour nous de voir ce qu'il y a à l'intérieur.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.data') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name, data_data); ERROR 3106 (HY000): 'Fulltext index on virtual generated column' is not supported for generated columns.
Malheureusement, cela ne fonctionne pas non plus -
vous ne pouvez pas créer un index de texte intégral sur une colonne virtuelle .
Si c'est le cas, créons une colonne stockée. MySQL 5.7 vous permet de déclarer une colonne en tant que champ stocké.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_name VARCHAR(255) CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS (data->>'$.name') STORED; Query OK, 123518 rows affected (1.75 sec) Records: 123518 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name); Query OK, 0 rows affected, 1 warning (3.78 sec) Records: 0 Duplicates: 0 Warnings: 1 mysql> show warnings; +
Dans les exemples précédents, nous avons créé des colonnes virtuelles qui ne sont pas stockées, mais des index sont créés et stockés. Dans ce cas, j'ai dû dire à MySQL qu'il s'agit d'une colonne STORED, c'est-à-dire qu'elle sera créée et que les données y seront copiées. Après cela, MySQL a créé un index de texte intégral, pour cela nous avons dû recréer la table. Mais cette limitation est en fait la recherche plein texte InnoDB et InnoDB: vous devez recréer le tableau pour ajouter un identifiant de recherche plein texte spécial.
Fait intéressant, dans MySQL 8, il y avait un
nouvel encodage UTF8 MB4 pour les émoticônes . Bien sûr, pas tout à fait pour eux, mais parce que dans UTF8MB3, il y a des problèmes avec le russe, le chinois, le japonais et d'autres langues.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data TEXT CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS ( CONVERT(data->>'$.data' USING UTF8MB4) ) STORED Query OK, 123518 rows affected (3.14 sec) Records: 123518 Duplicates: 0 Warnings: 0
En conséquence, MySQL 8 devrait stocker les données JSON dans UTF8MB4. Mais que ce soit en raison du fait que Node.js se connecte à Device Cloud, et que quelque chose y est mal écrit, ou qu'il s'agit d'un bogue de la version bêta, cela ne s'est pas produit. Par conséquent, j'ai dû convertir les données avant de les écrire dans une colonne stockée.
mysql> ALTER TABLE cloud_data_json_indexes DROP KEY ft_json, ADD FULLTEXT KEY ft_json(data_name, data_data); Query OK, 0 rows affected (1.85 sec) Records: 0 Duplicates: 0 Warnings: 0
Après cela, j'ai pu créer une recherche en texte intégral sur deux champs: sur le nom JSON et sur les données JSON.
Non seulement l'IoT
JSON n'est pas seulement l'Internet des objets. Il peut être utilisé pour d'autres choses intéressantes:
- Champs personnalisés (CMS);
- Structures complexes, etc.
Certaines choses peuvent être mises en œuvre de manière beaucoup plus pratique à l'aide d'un système de stockage de données flexible. Un excellent exemple a été fourni à Oracle OpenWorld: réservations de cinéma. Il est très difficile de l'implémenter dans le modèle relationnel - vous obtenez de nombreuses tables dépendantes, jointures, etc. D'autre part, nous pouvons stocker la salle entière sous forme de structure JSON, respectivement, l'écrire dans MySQL dans d'autres tables et l'utiliser de la manière habituelle: créer des index basés sur JSON, etc.
Les structures complexes sont facilement stockées au format JSON.
Il s'agit d'un arbre qui a été planté avec succès. Malheureusement, quelques années plus tard, les cerfs l'ont mangé, mais c'est une histoire complètement différente.
Ce rapport est un excellent exemple de la façon dont une section entière se développe à partir d'un sujet lors d'une grande conférence, puis d'un événement distinct. Dans le cas de l'Internet des objets, nous avons eu InoThings ++ - une conférence pour les professionnels du marché de l'Internet des objets, qui se tiendra pour la deuxième fois le 4 avril.
L'événement central de la conférence, semble-t-il, sera la table ronde «Avons-nous besoin de normes nationales sur l'Internet des objets?», Qui sera organiquement complétée par des rapports appliqués détaillés. Venez si vos systèmes fortement chargés se déplacent correctement vers IIoT.