
Au fil des années d'exploitation de Kubernetes en production, nous avons accumulé de nombreuses histoires intéressantes, car les bogues dans divers composants du système ont entraîné des conséquences désagréables et / ou incompréhensibles qui affectent le fonctionnement des conteneurs et des pods. Dans cet article, nous avons sélectionné quelques-unes des plus fréquentes ou intéressantes. Même si vous n'êtes jamais assez chanceux pour rencontrer de telles situations, lire à propos de ces brefs détectives - d'autant plus, de première main - est toujours amusant, n'est-ce pas?
Historique 1. Docker supercronique et glacial
Sur l'un des clusters, nous recevions périodiquement un Docker «gelé», qui interférait avec le fonctionnement normal du cluster. Dans le même temps, ce qui suit a été observé dans les journaux Docker
level=error msg="containerd: start init process" error="exit status 2: \"runtime/cgo: pthread_create failed: No space left on device SIGABRT: abort PC=0x7f31b811a428 m=0 goroutine 0 [idle]: goroutine 1 [running]: runtime.systemstack_switch() /usr/local/go/src/runtime/asm_amd64.s:252 fp=0xc420026768 sp=0xc420026760 runtime.main() /usr/local/go/src/runtime/proc.go:127 +0x6c fp=0xc4200267c0 sp=0xc420026768 runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 fp=0xc4200267c8 sp=0xc4200267c0 goroutine 17 [syscall, locked to thread]: runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 …
Dans cette erreur, le message nous intéresse le plus:
pthread_create failed: No space left on device . Une étude rapide de la
documentation a expliqué que Docker ne pouvait pas bifurquer le processus, ce qui provoquait un «gel» périodique.
Dans le suivi de ce qui se passe, l'image suivante correspond:

Une situation similaire est observée sur d'autres nœuds:


Sur les mêmes nœuds, nous voyons:
root@kube-node-1 ~
Il s'est avéré que ce comportement est une conséquence du travail du
pod avec
supercronic (l'utilitaire sur Go que nous utilisons pour exécuter des tâches cron dans les pods):
\_ docker-containerd-shim 833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 /var/run/docker/libcontainerd/833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 docker-runc | \_ /usr/local/bin/supercronic -json /crontabs/cron | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true | | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true -no-pidfile | \_ [newrelic-daemon] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> …
Le problème est le suivant: lorsqu'une tâche démarre en supercronic, le processus généré par elle
ne peut pas se terminer correctement , se transformant en
zombie .
Remarque : pour être plus précis, les processus sont générés par des tâches cron, cependant, le supercronic n'est pas un système init et ne peut pas «adopter» les processus que ses enfants ont engendrés. Lorsque des signaux SIGHUP ou SIGTERM se produisent, ils ne sont pas transmis aux processus générés, à la suite de quoi les processus enfants ne se terminent pas, restant dans le statut zombie. Vous pouvez en savoir plus sur tout cela, par exemple, dans un tel article .Il existe deux façons de résoudre les problèmes:
- Solution de contournement temporaire: augmentez le nombre de PID dans le système à un moment donné:
/proc/sys/kernel/pid_max (since Linux 2.5.34) This file specifies the value at which PIDs wrap around (ie, the value in this file is one greater than the maximum PID). PIDs greater than this value are not allo‐ cated; thus, the value in this file also acts as a system-wide limit on the total number of processes and threads. The default value for this file, 32768, results in the same range of PIDs as on earlier kernels
- Ou, faites le lancement de tâches en supercronic pas directement, mais avec l'aide du même tini , qui est capable de terminer correctement les processus et de ne pas générer de zombie.
Historique 2. "Zombies" lors de la suppression de cgroup
Kubelet a commencé à consommer beaucoup de CPU:
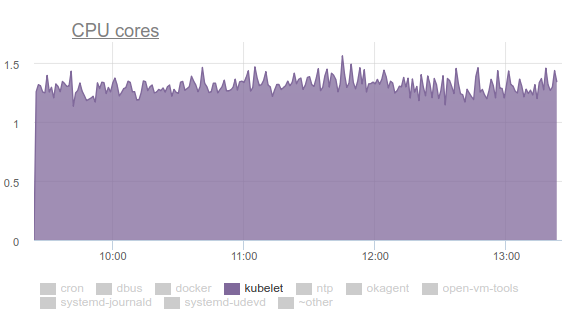
Personne n'aime cela, alors nous nous sommes armés de
perf et avons commencé à régler le problème. Les résultats de l'enquête sont les suivants:
- Kubelet passe plus d'un tiers du temps CPU à extraire les données de la mémoire de tous les groupes de contrôle:

- Dans la liste de diffusion des développeurs du noyau, vous pouvez trouver une discussion sur le problème . En bref, l'essentiel est que différents fichiers tmpfs et autres choses similaires ne sont pas complètement supprimés du système lorsque cgroup est supprimé - le soi-disant zombie memcg reste. Tôt ou tard, ils seront néanmoins supprimés du cache de pages, cependant, la mémoire sur le serveur est volumineuse et le noyau ne voit pas l'intérêt de perdre du temps à les supprimer. Par conséquent, ils continuent de s'accumuler. Pourquoi cela se produit-il même? Il s'agit d'un serveur avec des tâches cron qui crée constamment de nouvelles tâches et avec elles de nouveaux pods. Ainsi, de nouveaux groupes de contrôle sont créés pour les conteneurs qu'ils contiennent, qui seront bientôt supprimés.
- Pourquoi cAdvisor dans Kubelet passe autant de temps? Ceci est facilement visible par l'exécution la plus simple du
time cat /sys/fs/cgroup/memory/memory.stat . Si l'opération prend 0,01 seconde sur une machine saine, puis 1,2 seconde sur un cron02 problématique. Le fait est que cAdvisor, qui lit très lentement les données des sysfs, essaie également de prendre en compte la mémoire utilisée dans les groupes de zombies. - Pour supprimer de force les zombies, nous avons essayé de vider les caches, comme recommandé dans LKML:
sync; echo 3 > /proc/sys/vm/drop_caches sync; echo 3 > /proc/sys/vm/drop_caches , mais le noyau s'est avéré plus compliqué et a bloqué la machine.
Que faire? Le problème est résolu (
commit , et la description, voir
le message de sortie ) en mettant à jour le noyau Linux vers la version 4.16.
Historique 3. Systemd et sa monture
Encore une fois, kubelet consomme trop de ressources sur certains nœuds, mais cette fois, c'est déjà de la mémoire:

Il s'est avéré qu'il y avait un problème dans le systemd utilisé dans Ubuntu 16.04, et cela se produit lors du contrôle des montages qui sont créés pour connecter les sous-
subPath depuis ConfigMaps ou secrets. Une fois le pod terminé, le
service systemd et son montage de service restent sur le système. Au fil du temps, ils accumulent une énorme quantité. Il y a même des problèmes sur ce sujet:
- kops # 5916 ;
- kubernetes # 57345 .
... dans le dernier, se référer à PR dans systemd:
# 7811 (le problème dans systemd est
# 7798 ).
Le problème n'est plus dans Ubuntu 18.04, mais si vous souhaitez continuer à utiliser Ubuntu 16.04, notre solution de contournement sur ce sujet peut être utile.
Nous avons donc créé le DaemonSet suivant:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: labels: app: systemd-slices-cleaner name: systemd-slices-cleaner namespace: kube-system spec: updateStrategy: type: RollingUpdate selector: matchLabels: app: systemd-slices-cleaner template: metadata: labels: app: systemd-slices-cleaner spec: containers: - command: - /usr/local/bin/supercronic - -json - /app/crontab Image: private-registry.org/systemd-slices-cleaner/systemd-slices-cleaner:v0.1.0 imagePullPolicy: Always name: systemd-slices-cleaner resources: {} securityContext: privileged: true volumeMounts: - name: systemd mountPath: /run/systemd/private - name: docker mountPath: /run/docker.sock - name: systemd-etc mountPath: /etc/systemd - name: systemd-run mountPath: /run/systemd/system/ - name: lsb-release mountPath: /etc/lsb-release-host imagePullSecrets: - name: antiopa-registry priorityClassName: cluster-low tolerations: - operator: Exists volumes: - name: systemd hostPath: path: /run/systemd/private - name: docker hostPath: path: /run/docker.sock - name: systemd-etc hostPath: path: /etc/systemd - name: systemd-run hostPath: path: /run/systemd/system/ - name: lsb-release hostPath: path: /etc/lsb-release
... et il utilise le script suivant:
... et ça commence toutes les 5 minutes avec le supercronic déjà mentionné. Son Dockerfile ressemble à ceci:
FROM ubuntu:16.04 COPY rootfs / WORKDIR /app RUN apt-get update && \ apt-get upgrade -y && \ apt-get install -y gnupg curl apt-transport-https software-properties-common wget RUN add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable" && \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - && \ apt-get update && \ apt-get install -y docker-ce=17.03.0* RUN wget https://github.com/aptible/supercronic/releases/download/v0.1.6/supercronic-linux-amd64 -O \ /usr/local/bin/supercronic && chmod +x /usr/local/bin/supercronic ENTRYPOINT ["/bin/bash", "-c", "/usr/local/bin/supercronic -json /app/crontab"]
Historique 4. Compétition dans la planification des modules
Il a été noté que: si un pod est placé sur notre nœud et que son image est pompée pendant très longtemps, alors l'autre pod qui est "arrivé" au même nœud
ne commence tout simplement
pas à tirer l'image du nouveau pod . Au lieu de cela, il attend que l'image du pod précédent soit tirée. En conséquence, un pod qui a déjà été planifié et dont l'image pourrait être téléchargée en une minute se retrouvera longtemps dans l'état
containerCreating .
Dans les événements, il y aura quelque chose comme ça:
Normal Pulling 8m kubelet, ip-10-241-44-128.ap-northeast-1.compute.internal pulling image "registry.example.com/infra/openvpn/openvpn:master"
Il s'avère qu'une
seule image du registre lent peut bloquer le déploiement sur le nœud.
Malheureusement, il n'y a pas tant de façons de sortir de la situation:
- Essayez d'utiliser votre Docker Registry directement dans le cluster ou directement avec le cluster (par exemple, GitLab Registry, Nexus, etc.);
- Utilisez des utilitaires comme kraken .
Historique 5. Nœuds suspendus avec mémoire insuffisante
Pendant le fonctionnement de diverses applications, nous avons également reçu une situation où le nœud cesse complètement d'être accessible: SSH ne répond pas, tous les démons de surveillance tombent, puis rien (ou presque rien) n'est anormal dans les journaux.
Je vais vous dire dans les images sur l'exemple d'un nœud où MongoDB a fonctionné.
Voici à quoi ressemble au sommet
avant le crash:

Et donc -
après l' accident:

Dans la surveillance aussi, il y a un saut brusque dans lequel le nœud cesse d'être accessible:
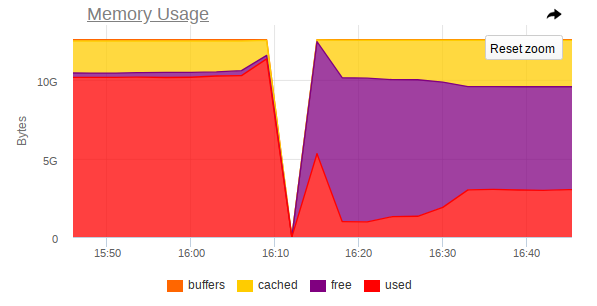
Ainsi, les captures d'écran montrent que:
- La RAM sur la machine est proche de la fin;
- On observe une forte augmentation de la consommation de RAM, après quoi l'accès à l'ensemble de la machine est fortement désactivé;
- Une grosse tâche arrive chez Mongo, qui oblige le processus SGBD à utiliser plus de mémoire et à lire activement à partir du disque.
Il s'avère que si Linux manque de mémoire libre (une pression de mémoire se produit) et qu'il n'y a pas d'échange, puis
avant que le tueur OOM n'arrive, un équilibre peut se produire entre le lancement de pages dans le cache de pages et leur réécriture sur le disque. Ceci est fait par kswapd, qui libère courageusement autant de pages de mémoire que possible pour une distribution ultérieure.
Malheureusement, avec une grande charge d'E / S, couplée à une petite quantité de mémoire libre,
kswapd devient le goulot d'étranglement de tout le système , car
tous les défauts de page des pages de mémoire du système lui sont liés. Cela peut durer très longtemps si les processus ne veulent plus utiliser de mémoire, mais sont fixés au bord même de l'abîme OOM-killer.
La question logique est: pourquoi le tueur OOM arrive si tard? Dans l'itération OOM actuelle, killer est extrêmement stupide: il ne tuera le processus que lorsque la tentative d'allocation d'une page mémoire échoue, c'est-à-dire si l'erreur de page échoue. Cela ne se produit pas pendant longtemps, car kswapd libère courageusement des pages de mémoire en vidant le cache de pages (toutes les E / S de disque du système, en fait) sur disque. Plus en détail, avec une description des étapes nécessaires pour éliminer de tels problèmes dans le noyau, vous pouvez lire
ici .
Ce comportement
devrait s'améliorer avec le noyau Linux 4.6+.
Histoire 6. Les pods sont en attente
Dans certains clusters, dans lesquels il y a vraiment beaucoup de pods, nous avons commencé à remarquer que la plupart d'entre eux étaient suspendus dans l'état
Pending depuis très longtemps, bien que les conteneurs Docker eux-mêmes soient déjà en cours d'exécution sur les nœuds et que vous puissiez travailler manuellement avec eux.
Il n'y a rien de mal à
describe :
Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 1m default-scheduler Successfully assigned sphinx-0 to ss-dev-kub07 Normal SuccessfulAttachVolume 1m attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "sphinx-config" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "default-token-fzcsf" Normal SuccessfulMountVolume 49s (x2 over 51s) kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx-exporter/sphinx-indexer:v1" already present on machine Normal Created 43s kubelet, ss-dev-kub07 Created container Normal Started 43s kubelet, ss-dev-kub07 Started container Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx/sphinx:v1" already present on machine Normal Created 42s kubelet, ss-dev-kub07 Created container Normal Started 42s kubelet, ss-dev-kub07 Started container
Après avoir fouillé, nous avons fait l'hypothèse que kubelet n'a tout simplement pas le temps d'envoyer au serveur API toutes les informations sur l'état des pods, les échantillons de vivacité / préparation.
Et après avoir étudié l'aide, nous avons trouvé les paramètres suivants:
--kube-api-qps - QPS to use while talking with kubernetes apiserver (default 5) --kube-api-burst - Burst to use while talking with kubernetes apiserver (default 10) --event-qps - If > 0, limit event creations per second to this value. If 0, unlimited. (default 5) --event-burst - Maximum size of a bursty event records, temporarily allows event records to burst to this number, while still not exceeding event-qps. Only used if --event-qps > 0 (default 10) --registry-qps - If > 0, limit registry pull QPS to this value. --registry-burst - Maximum size of bursty pulls, temporarily allows pulls to burst to this number, while still not exceeding registry-qps. Only used if --registry-qps > 0 (default 10)
Comme vous pouvez le voir, les
valeurs par défaut sont assez petites , et à 90% elles couvrent tous les besoins ... Cependant, dans notre cas ce n'était pas suffisant. Par conséquent, nous définissons ces valeurs:
--event-qps=30 --event-burst=40 --kube-api-burst=40 --kube-api-qps=30 --registry-qps=30 --registry-burst=40
... et redémarré les kubelets, après quoi ils ont vu l'image suivante sur les graphiques d'accès au serveur API:

... et oui, tout a commencé à voler!
PS
Pour l'aide à la collecte des bugs et à la préparation de l'article, j'exprime ma profonde gratitude aux nombreux ingénieurs de notre entreprise, et en particulier à Andrei Klimentyev (collègue de notre équipe R&D) (
zuzzas ).
PPS
Lisez aussi dans notre blog: