En réponse à l'augmentation du nombre d'applications en cours d'exécution et du nombre de périphériques réseau, la bande passante réseau augmente et les exigences de livraison de paquets sont resserrées. Sur une échelle de centres de données critiques pour le cloud essentiels pour les entreprises, l'approche traditionnelle de la maintenance des infrastructures ne permet plus de résoudre des tâches typiques. C'est ainsi que le concept d'AIOps (Algorithmic IT Operations) est né.
Selon Gartner, environ 50% des entreprises utiliseront les AIOps d'ici l'année prochaine. Nous pouvons parler de ce que des outils similaires peuvent faire aujourd'hui, en utilisant l'exemple de Huawei FabricInsight, un analyseur de réseau qui fait partie d'une solution complète pour les centres de données Huawei CloudFabric.
La transformation numérique des entreprises offre de nouvelles opportunités - l'introduction de l'analyse du Big Data, le développement d'algorithmes d'apprentissage automatique - n'est plus seulement une mode, mais un besoin conscient, dont la fermeture apporte un réel profit. Cependant, les nouvelles implémentations entraînent une augmentation multiple de la complexité de l'infrastructure, ce qui pose en même temps de nouveaux défis en termes de maintenance.
Le principal problème du maintien d'une grande infrastructure aujourd'hui est la quantité de données qui doivent être collectées et traitées pour obtenir des informations sur l'état du centre de données, ainsi que la vitesse avec laquelle il est nécessaire de donner une réponse pertinente aux causes des défaillances. D'une part, le nombre de paramètres surveillés est en constante augmentation, d'autre part, le temps joue contre les organisations, car l'objectif de toute entreprise est de rétablir la disponibilité de ses services le plus rapidement possible en cas de problème (compte tenu notamment des exigences strictes du SLA). La vitesse de la «montée» du service après l'effondrement est largement déterminée par la vitesse de l'enquête sur l'incident. Et cela, à son tour, dépend de l'exhaustivité des informations sur ce qui se passe. Mais si au moins 50 à 100 racks de serveurs sont installés dans le centre de données, les mécanismes de surveillance standard ne peuvent pas faire face aux exigences élevées de bande passante et de livraison rapide des paquets.
Pourquoi SNMP échoue?
Les mécanismes standard - SNMP et xFlow - collectent des données uniquement toutes les 5 à 15 minutes, en échantillonnant les informations. Ils ont été initialement développés en tenant compte des limites du post-traitement des données accumulées sans devoir identifier les problèmes en temps réel. Et même une telle collecte de données limitée affecte le fonctionnement des périphériques réseau.
Étant donné que le trafic problématique n'est que de 3,65%, l'approche traditionnelle, basée sur les résultats de l'analyse, ne révèle que 30% des problèmes de réseau, 70% ne sont pas visibles pour les systèmes de surveillance.
Des administrateurs expérimentés qui savent quoi et où chercher sont nécessaires pour identifier la racine du problème à partir des données collectées par SNMP et xFlow. Les problèmes doivent être identifiés en analysant d'énormes journaux et plusieurs messages d'erreur, puis en modifiant manuellement la configuration. Mais avec le développement de SDN, avec la virtualisation des ressources physiques, la configuration manuelle appartient au passé. Aujourd'hui, même toute une équipe d'administrateurs système ne peut plus garantir la conformité continue des paramètres d'infrastructure avec les exigences de l'entreprise.
FabricInsight fonctionne différemment
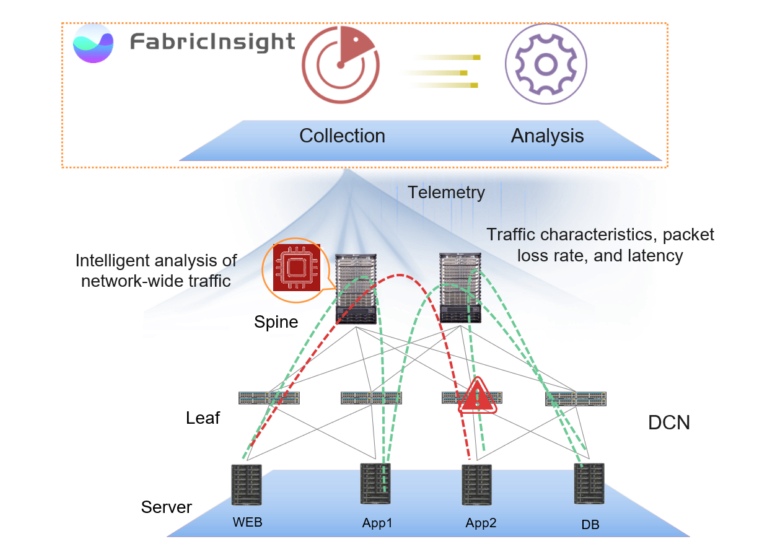
La plateforme d'analyse de réseau FabricInsight propose une approche différente, automatisant la maintenance du réseau et la détection des points de défaillance. FabricInsight analyse le comportement des applications, identifie les chemins d'accès réseau qu'elles utilisent et suit l'état des périphériques sur celles-ci.

Cette approche repose sur deux éléments clés: la collecte de toutes les données disponibles et leur analyse automatique. Complétée par une visualisation fonctionnelle et une politique d'ouverture des données, cette approche nous permet de résoudre de nombreux problèmes qui étaient auparavant des impasses.
Collectez toutes les données disponibles.
La clé d'une réponse rapide à la situation est une image complète de ce qui se passe à l'intérieur du centre de données au niveau du réseau. FabricInsight utilise un mécanisme d'abonnement par télémétrie push pour collecter toutes les données de service de deuxième niveau en temps opportun sans échantillonnage. Pour obtenir une image complète du réseau, des données sont collectées sur le fonctionnement des appareils, les applications et le passage du trafic réseau (paquets TCP SYN, FIN et RST) - ERSPAN est pris en charge pour la mise en miroir des paquets sans utiliser le processeur de l'appareil et le GRPC de Google pour rendre compte des performances des appareils eux-mêmes.
Les données collectées via FabricInsight LEAF sont transmises au FabricInsight Collector, qui surveille les paramètres temporels du paquet passant par le réseau. Collector fournit des données de trafic réseau avec des horodatages, encode et envoie via HTTP à FabricInsight Analyzer. Cette approche vous permet de collecter un maximum d'informations sur le réseau, capturant même des rafales de trafic à court terme qui ne peuvent pas être détectées par des solutions "classiques".
Dans le même temps, FabricInsight ne regarde pas à l'intérieur des paquets IP (il ne capture pas leur contenu), utilisant uniquement des en-têtes dans son travail. Ainsi, il peut être utilisé dans des domaines critiques pour les entreprises, par exemple, où il y a du travail avec des données personnelles.
Analyse en temps réel
Le deuxième élément intégral du système est l'analyseur FabricInsight. En recevant les données collectées, il identifie les trajets de trafic et exécute des algorithmes qui analysent la situation en temps quasi réel. En général, FabricInsight Analyzer corrèle le trafic réseau avec les applications, ce qui vous permet d'identifier et de résoudre rapidement les problèmes. Grâce à l'apprentissage automatique, les algorithmes sont «formés» pour identifier le comportement normal et anormal de l'infrastructure.
NetworkInsight reflète les résultats de l'analyse du réseau dans son interface sous la forme de cartes de l'état du réseau, des interactions entre les applications, des analyses pour les applications individuelles, etc., mises à jour en temps réel. L’interface est implémentée de manière à établir un lien visuel entre le niveau des applications et des dispositifs physiques spécifiques responsables de l’opérabilité du réseau, ce qui accélère le dépannage et les méthodes pour les résoudre.
Si des anomalies sont détectées en mode automatique, les informations initiales sont enregistrées, en fonction des problèmes identifiés (la durée de stockage est réglable), si nécessaire - FabricInsight avertit l'utilisateur. De plus, les procédures de correction de la situation «en un clic avec la souris» via l'interface graphique sont initialisées. Dans le même temps, divers modèles de correction d'erreurs sont analysés pour trouver l'approche la plus pertinente.
Étuis
Pour identifier les anomalies du centre de données, une analyse de corrélation du fonctionnement des applications, des appareils et des trajets de trafic est utilisée, ainsi divers types d'anomalies sont enregistrés - à la fois temporaires et à long terme.

Soit dit en passant, la plupart des anomalies temporaires mentionnées ci-dessus ne peuvent pas être corrigées en utilisant l'approche classique. Cela vaut également pour certaines anomalies à long terme. Un exemple assez courant est une mise à jour logicielle «tordue». Supposons qu'une certaine application fonctionnait dans le centre de données qui a généré un certain trafic. Après sa mise à jour, le volume de ce trafic a considérablement changé, par exemple, le débit des applications a diminué, les retards ont augmenté. Cette anomalie sera corrigée par FabricInsight.
Un autre exemple est la dégradation progressive du module de communication optique (perte de performances), précédant la panne. La dégradation détermine l'instabilité de la transmission qui, sur de longues périodes, peut indiquer la nécessité d'un remplacement précoce de l'équipement. Mais identifier cela avec une approche standard est extrêmement difficile.

En réponse à ce problème, l'interface FabricInsight affiche les statuts de tous les modules optiques du système ainsi qu'une estimation de la probabilité de leur défaillance.

Intégration
Bien que FabricInsight soit apparu sur le marché russe en janvier de cette année, il a déjà été déployé dans ICBC, China UnionPay, China Merchants Bank, PICC et d'autres grands centres de données basés sur l'infrastructure Huawei.
Jusqu'à présent, la solution ne prend en charge que nos commutateurs (sur les chipsets Broadcom), mais à l'avenir, il est prévu d'aller au-delà de l'écosystème d'un fabricant. De plus, lorsque nous travaillions sur FabricInsight, nous nous sommes initialement concentrés sur des normes ouvertes afin de pouvoir nous lier d'amitié avec des outils tiers normalement. Par exemple, Druid peut être utilisé pour exporter des données depuis FabricInsight, à travers lesquelles vous pouvez envoyer des informations à des visualiseurs tiers. FabricInsight est également déjà intégré à l'outil de rendu ouvert de Grafana.
En général, les outils AIOps comme notre FabricInsight sont un moyen logique de développer des outils de surveillance et de maintenance des infrastructures. Il nous semble que c'est le seul moyen de continuer à respecter le SLA pour les services.