Bonjour, Habr!
Je m'appelle Anton Markelov, je suis ingénieur ops chez United Traders. Nous sommes engagés dans des projets d'une manière ou d'une autre liés aux investissements, aux échanges et à d'autres questions financières. Nous ne sommes pas une très grande entreprise, une trentaine d'ingénieurs de développement, les balances sont appropriées - un peu moins d'une centaine de serveurs. Au cours de la croissance quantitative et qualitative de notre infrastructure, la solution classique «nous gardons à la fois l'application et sa base de données sur le même serveur» a cessé de nous convenir à la fois en termes de fiabilité et de rapidité. De la part des analystes, il était nécessaire de créer des requêtes inter-bases de données, le service des opérations en avait assez de déconner avec la sauvegarde et la surveillance d'un grand nombre de serveurs de bases de données. De plus, le stockage de l'état sur la même machine que l'application elle-même a considérablement réduit la flexibilité de la planification des ressources et la résilience de l'infrastructure.
Le processus de transition vers l'architecture actuelle était évolutif, diverses solutions ont été testées à la fois pour fournir une interface pratique pour les développeurs et les analystes, et pour augmenter la fiabilité et la gérabilité de l'ensemble de cette économie. Je veux parler des principales étapes de la modernisation de notre SGBD, du rake auquel nous sommes arrivés et des décisions que nous avons prises, en conséquence, un environnement indépendant tolérant aux pannes qui fournit des moyens d'interaction pratiques pour les ingénieurs d'exploitation, les développeurs et les analystes. J'espère que notre expérience sera utile aux ingénieurs des entreprises de notre envergure.
Cet article est un résumé de mon
rapport à la conférence UPTIMEDAY, peut-être que le format vidéo sera plus confortable pour quelqu'un, bien que l'écrivain soit un peu mieux avec mes mains qu'un haut-parleur.
Le «Snowflake Man» avec KDPV a été
emprunté sans vergogne à Maxim Dorofeev.
Maladies de croissance
Nous avons une architecture de microservices, les services sont écrits principalement en Java ou Kotlin en utilisant le framework Spring. À côté de chaque microservice se trouve une base PostgreSQL, tout est couvert par nginx en haut pour fournir un accès. Un microservice typique est une application sur Spring Boot qui écrit ses données dans PostgreSQL (une partie des applications en même temps et dans ClickHouse), communique avec les voisins via Kafka et possède des points de terminaison REST ou GraphQL pour la communication avec le monde extérieur.
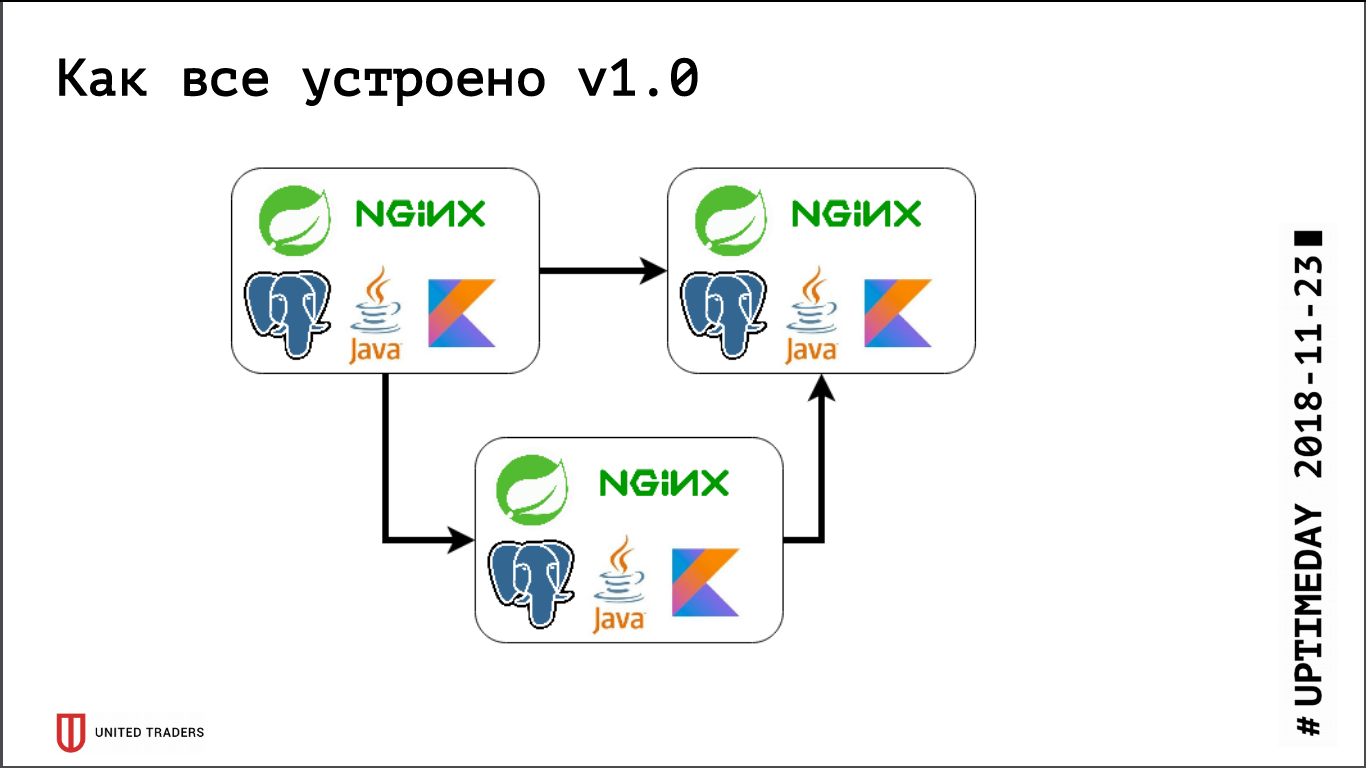
Auparavant, lorsque nous étions très petits, nous ne conservions que plusieurs serveurs dans DigitalOcean, Kafka n'était pas encore là, toutes les communications se faisaient via REST. Autrement dit, nous avons pris une droplet, y avons installé Java, PostgreSQL, nginx, y avons lancé Zabbix afin qu'il surveille les ressources du serveur et la disponibilité des points de terminaison de service. Ils ont tout déployé avec l'aide d'Ansible, nous avions des playbooks standardisés, quatre à cinq rôles ont déployé l'ensemble du service. Tant que nous avions, relativement parlant, 6 serveurs en production et 3 sur le test - vous pourriez en quelque sorte vivre avec.
Puis la phase de développement actif a commencé, le nombre d'applications a augmenté, dix microservices se sont transformés en quarante, leurs fonctionnalités ont commencé à changer, ainsi que l'intégration avec des systèmes externes tels que CRM, sites clients et similaires. Nous avons eu la première douleur. Certaines applications ont commencé à consommer plus de ressources, ont cessé de pénétrer dans les serveurs existants, nous avons reçu des gouttelettes, déplacé les applications d'avant en arrière, choisi beaucoup de mains. Ça faisait très mal - personne n'aime les travaux mécaniques stupides, - je voulais décider rapidement. Nous sommes donc allés de l'avant - nous avons juste pris 3 grands serveurs dédiés au lieu de 10 gouttelettes de cloud. Cela a fermé le problème pendant un certain temps, mais il est devenu évident qu'il était temps de trouver des options pour une sorte d'orchestration et de rééquilibrage des serveurs. Nous avons commencé à examiner de près des solutions comme DC / OS et Kubernetes, et à augmenter progressivement notre expertise dans ce domaine.
À peu près à la même époque, nous avions un département analytique, qui devait régulièrement faire des demandes difficiles, préparer des rapports, avoir de beaux tableaux de bord, ce qui nous a apporté une seconde douleur. Premièrement, les analystes ont lourdement chargé la base, et deuxièmement, ils avaient besoin de requêtes inter-bases de données, car chaque microservice conservait une tranche de données assez étroite. Nous avons testé plusieurs systèmes, au début, nous avons essayé de tout résoudre grâce à la réplication au niveau de la table (elle était de retour dans le neuvième PostgreSQL, il n'y avait pas de réplication logique prête à l'emploi), mais les métiers résultants basés sur pglogical, Presto, Slony-I et Bucardo n'ont pas du tout arrangé. Par exemple, pglogical n'a pas pris en charge la migration - une nouvelle version du microservice a été déployée, la structure de la base de données a changé, Java lui-même a changé la structure à l'aide de Flyway, et sur les répliques en pglogical, tout doit être modifié manuellement. Sinon, soit il manquait quelque chose, soit c'était trop difficile.
Super esclave
À la suite de la recherche, une solution simple et brutale est née appelée Superslave: nous avons pris un serveur distinct, configuré sur lui un esclave pour chaque serveur de production sur différents ports, et créé une base de données virtuelle qui combine les bases de données des esclaves via postgres_fdw (wrapper de données étranger). Autrement dit, tout cela a été mis en œuvre au moyen de postgres standard sans introduire d'entités supplémentaires, de manière simple et fiable: avec une seule demande, il a été possible d'obtenir des données à partir de plusieurs bases de données. Nous avons donné cette base virtuelle aux analystes. Un avantage supplémentaire est que la réplique en lecture seule, même avec une erreur de droits d'accès, ne pouvait rien y écrire.
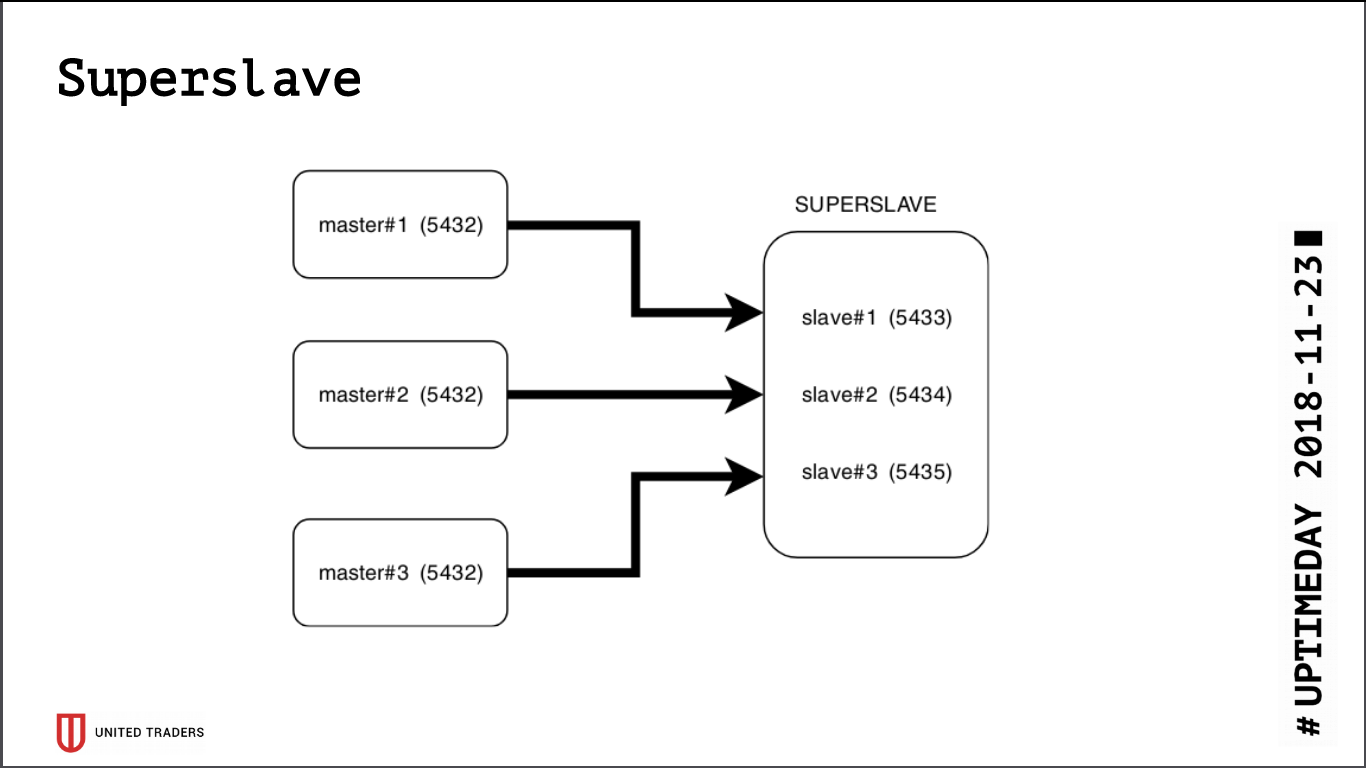
Nous avons pris
Redash pour la visualisation, il sait dessiner des graphiques, exécuter des requêtes selon un calendrier, par exemple, une fois par jour, et dispose d'un système de droits lourd, nous avons donc laissé les analystes et les développeurs y aller.

Parallèlement, la croissance s'est poursuivie, Kafka est apparu dans l'infrastructure comme un bus et ClickHouse pour le stockage des analyses. Ils sont facilement regroupés hors de la boîte, notre super esclave sur leur arrière-plan ressemblait à un fossile maladroit. De plus, PostgreSQL, en fait, est resté le seul état qui devait être glissé après l'application (s'il devait encore être transféré vers un autre serveur), et nous voulions vraiment obtenir une application sans état afin de nous engager étroitement dans des expériences avec Kubernetes et lui plates-formes similaires.
Nous avons commencé à chercher une solution répondant aux exigences suivantes:
- tolérance aux pannes: lorsque N serveurs tombent, le cluster continue de fonctionner;
- pour les applications, tout doit rester comme avant, aucun changement dans le code;
- facilité de déploiement et de gestion;
- moins de couches d'abstraction sur PostgreSQL standard;
- idéalement, l'équilibrage de charge afin que toutes les demandes ne soient pas envoyées à un seul serveur;
- Idéalement, il est écrit dans une langue familière.
Il n'y avait pas beaucoup de candidats:
- réplication de streaming standard (repmgr, Patroni, Stolon);
- réplication basée sur les déclencheurs (Londiste, Slony);
- réplication de requête de couche intermédiaire (pgpool-II);
- réplication synchrone avec plusieurs serveurs principaux (Bucardo).
Avec une grande partie, nous avons déjà eu de mauvaises expériences lors de la construction de la base transversale, donc Patroni et Stolon sont restés. Patroni est écrit en Python, Stolon in Go, nous avons suffisamment d'expertise dans les deux langues. De plus, ils ont une architecture et des fonctionnalités similaires, donc le choix a été fait pour des raisons subjectives: Patroni a été développé par Zalando, et nous avons essayé une fois de travailler avec leur projet Nakadi (API REST pour Kafka), où nous avons rencontré un grave manque de documentation.
Stolon
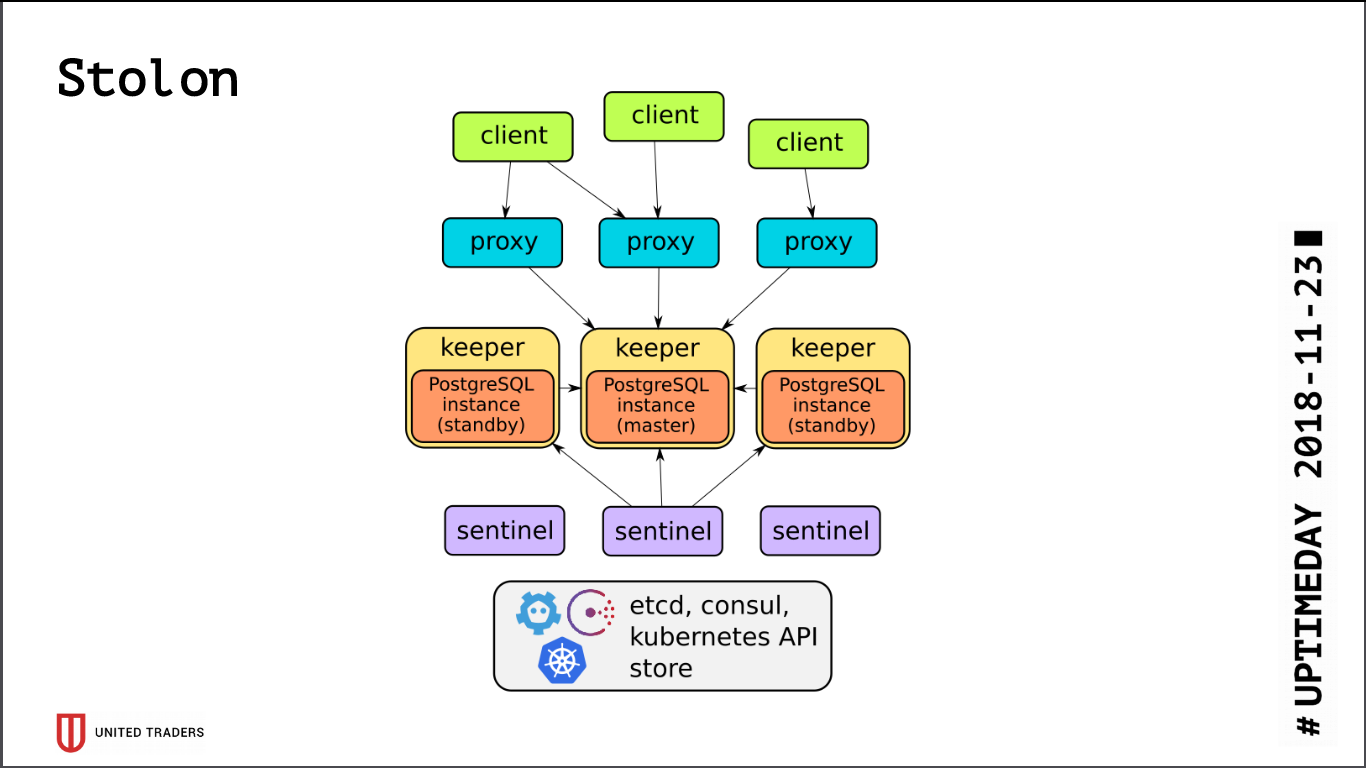
L'architecture de
Stolon est assez simple: il y a N serveurs, avec l'aide de etcd / consul un leader est sélectionné, PostgreSQL y est lancé en mode assistant et est répliqué sur d'autres serveurs. Ensuite, les proxys stolon vont à ce maître PostgreSQL, se faisant passer pour des applications avec des postgres ordinaires, et les clients vont à ces proxys. En cas de disparition d’un maître, des réélections ont lieu, quelqu’un devient maître, les autres se mettent en attente. Il y a peu de couches d'abstraction, PostgreSQL est installé comme d'habitude, la seule mise en garde est que la configuration PostgreSQL est stockée dans etcd, et elle est configurée quelque peu différemment.
Lors du test du cluster, nous avons détecté plusieurs problèmes:
- Stolon ne sait pas comment travailler sur ZooKeeper, seulement consul ou etcd;
- etcd est très sensible aux E / S. Si vous gardez PostgreSQL et etcd sur le même serveur, vous avez certainement besoin de SSD rapides;
- même sur SSD, il est nécessaire de configurer les délais d'attente etcd, sinon tout se brisera sous charge - le cluster pensera que le maître est tombé et rompra constamment les connexions;
- Par défaut, max_connections sur PostgreSQL est petit (200), vous devez l'augmenter selon vos besoins;
- un cluster de trois etcd survivra à la mort d'un seul serveur, idéalement vous devez avoir une configuration, par exemple 5 etcd + 3 Stolon;
- hors de la boîte, toutes les connexions vont au maître, les esclaves ne sont pas accessibles à la connexion.
Étant donné que toutes les connexions à PostgreSQL vont à l'assistant, nous rencontrons à nouveau un problème avec de lourdes demandes d'analyse. etcd réagissait parfois douloureusement à la charge élevée du maître et le commutait. Et changer d'assistant est toujours de rompre les connexions. La demande a été redémarrée, tout a recommencé. Pour une solution de contournement,
un script Python a été écrit qui a demandé des adresses stolonctl d'esclaves vivants et a généré une configuration pour HAProxy, redirigeant les demandes vers eux.
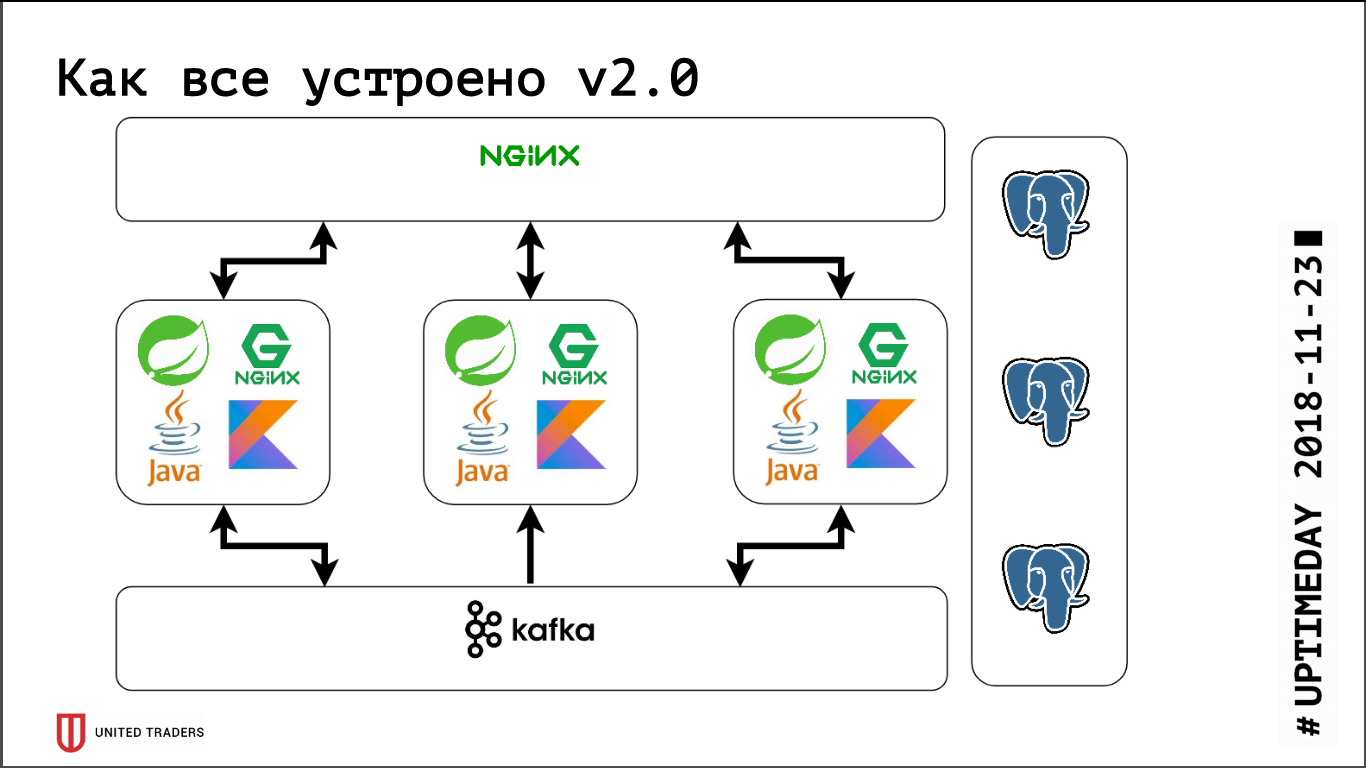
L'image suivante s'est avérée: les demandes des applications vont au port stolon-proxy, qui les redirige vers le maître, et les demandes des analystes (elles sont toujours en lecture seule) vont au port HAProxy, qui les envoie à un esclave.
Aussi, littéralement aujourd'hui, un PR a été adopté chez Stolon, ce qui a permis d'envoyer des informations sur les instances de Stolon à une découverte de service tiers.
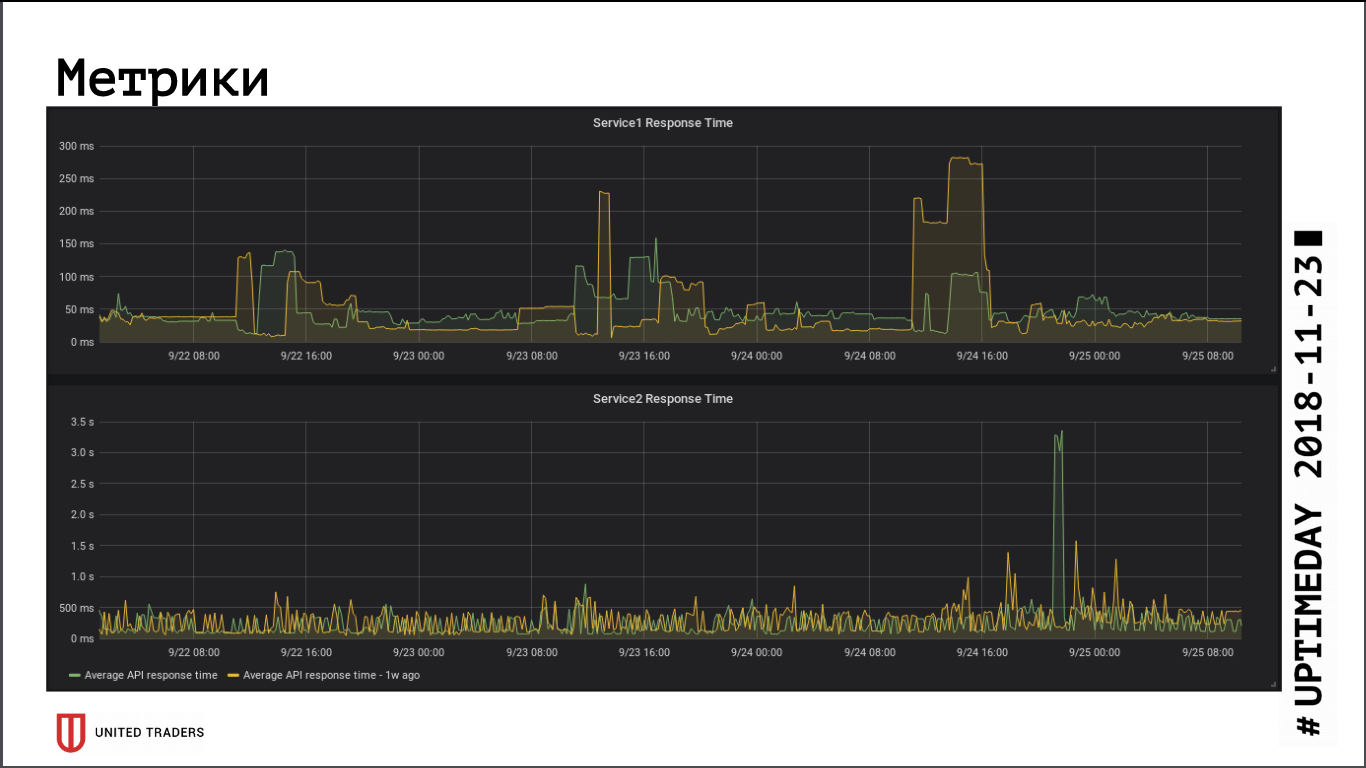
En ce qui concerne les mesures de vitesse de réponse de l'application, la transition vers un cluster distant n'a pas eu d'impact significatif sur les performances, le temps de réponse moyen n'a pas changé. La latence du réseau qui en résulte, apparemment, a été compensée par le fait que la base de données est maintenant sur un serveur dédié.
Stolon sans problèmes survit à un plantage de l'assistant (perte de serveur, perte de réseau, perte de disque), lorsque le serveur prend vie - il réinitialise automatiquement la réplique. Le point le plus faible de Stolon est etcd, ses échecs mettent le cluster. Nous avons eu un accident typique: un cluster de trois nœuds etcd, deux ont été coupés. Tout, le quorum a été brisé, etcd est entré dans un état malsain, le cluster Stolon n'accepte aucune connexion, y compris les demandes de stolonctl. Schéma de récupération: transformez etcd sur le serveur survivant en un cluster à nœud unique, puis ajoutez à nouveau les membres. Conclusion: pour survivre à la mort de deux serveurs, vous devez avoir au moins 5 instances etcd.
Surveillance et détection des erreurs
Avec la croissance de l'infrastructure et la complexité des microservices, j'ai voulu collecter plus d'informations sur ce qui se passe à l'intérieur de l'application et de la machine Java. Nous n'avons pas pu adapter Zabbix au nouvel environnement: il est très gênant dans les conditions d'une infrastructure en mutation. J'ai dû soit moudre des béquilles via son API, soit grimper à l'intérieur avec mes mains, ce qui est encore pire. Sa base de données est mal adaptée aux charges lourdes, et en général il est très gênant de mettre tout cela dans une base de données relationnelle.
En conséquence, nous avons choisi Prometheus pour la surveillance. Il a un actionneur prêt à l'emploi pour les applications Spring pour fournir des mesures, pour Kafka, ils ont vissé JMX Exporter, qui fournit également des mesures d'une manière confortable. Ces exportateurs qui n'étaient pas trouvés «dans la boîte», nous écrivions-nous en Python, il y en a une dizaine. Nous visualisons Grafana, collectons les journaux avec Graylog (puisqu'il prend désormais en charge Beats).
Nous utilisons
Sentry pour collecter les erreurs. Il écrit tout sous une forme structurée, dessine des graphiques, montre ce qui s'est passé plus souvent, moins souvent. Habituellement, les développeurs se rendent immédiatement sur Sentry immédiatement après le déploiement, voient s'il y a un pic ou doivent être annulés de toute urgence. Il s'avère qu'il détecte rapidement les erreurs sans chercher dans les journaux.
C'est tout pour le moment, si le format des articles convient aux lecteurs, nous continuerons à parler de notre infrastructure, il y a encore beaucoup de plaisir: Kafka et des solutions analytiques pour les événements qui le traversent, canal CI / CD pour les applications Windows et les aventures avec Openshift.