Les algorithmes pour les recommandations, les prévisions d'événements ou les évaluations des risques sont une décision tendance dans les banques, les compagnies d'assurance et de nombreux autres secteurs d'activité. Par exemple, ces programmes aident, sur la base d'une analyse des données, à suggérer quand un client remboursera un prêt bancaire, quelle sera la demande dans le commerce de détail, quelle est la probabilité d'un événement assuré ou d'une sortie de clients dans les télécommunications, etc. Pour une entreprise, c'est une opportunité précieuse pour optimiser ses dépenses, augmenter la vitesse de travail et généralement améliorer le service.
Cependant, les approches traditionnelles telles que la classification et la régression ne conviennent pas à l'élaboration de tels programmes. Considérez ce problème comme un exemple de cas de prévision d'épisodes médicaux: nous analysons les nuances dans la nature des données et les approches possibles de modélisation, construisons un modèle et analysons sa qualité.
Le défi de prédire les épisodes médicaux
La prédiction des épisodes est basée sur une analyse des données historiques. Dans ce cas, l'ensemble de données se compose de deux parties. Le premier concerne les données sur les services précédemment fournis au patient. Cette partie de l'ensemble de données comprend des données sociodémographiques sur le patient, telles que l'âge et le sexe, ainsi que des diagnostics qui lui ont été faits à différents moments dans le codage ICD10-CM [1] et les procédures HCPCS effectuées [2]. Ces données forment des séquences dans le temps qui vous permettent d'avoir une idée de l'état du patient à un moment particulier. Pour les modèles de formation, ainsi que pour travailler en production, des données personnalisées suffisent.
La deuxième partie de l'ensemble de données est une liste d'épisodes qui se produisent pour le patient. Pour chaque épisode, nous indiquons son type et sa date d'occurrence, ainsi que la période de temps, les services inclus et d'autres informations. À partir de ces données, des variables cibles pour la prédiction sont générées.
L'aspect du temps est important dans la résolution du problème: nous ne nous intéressons qu'aux épisodes qui peuvent survenir dans un futur proche. D'autre part, l'ensemble de données à notre disposition a été collecté pendant une période de temps limitée, au-delà de laquelle il n'y a pas de données. Ainsi, nous ne pouvons pas dire si les épisodes se produisent en dehors de la période d'observation, quels sont-ils, à quel moment précis ils surviennent. Cette situation est appelée censure à droite.
De même, la censure gauche se produit: pour certains patients, un épisode peut commencer à se développer plus tôt que ce que nous pouvons observer. Pour nous, cela ressemblera à un épisode survenu sans arrière-plan.
Il existe un autre type de censure des données - l'interruption de l'observation (si la période d'observation n'est pas terminée et que l'événement ne s'est pas produit). Par exemple, en raison du déplacement d'un patient, d'une défaillance du système de collecte de données, etc.
Dans la fig. 1 montre schématiquement différents types de censure des données. Tous faussent les statistiques et rendent difficile la construction d'un modèle.
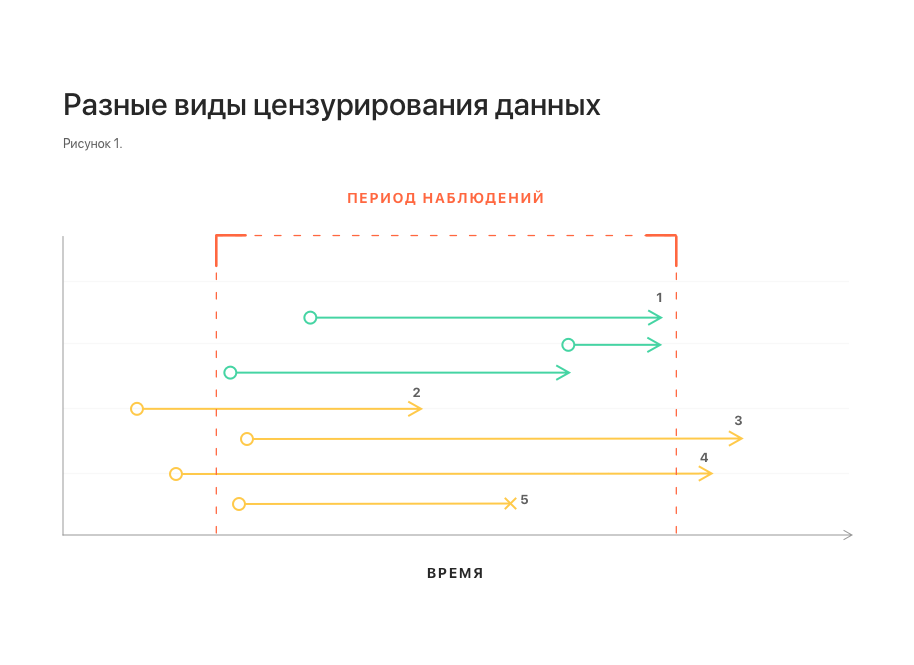 Notes: 1 - observations non censurées; 2, 3 - censure gauche et droite, respectivement; 4 - censure gauche et droite en même temps;
Notes: 1 - observations non censurées; 2, 3 - censure gauche et droite, respectivement; 4 - censure gauche et droite en même temps;
5 - interruption de l'observation.Une autre caractéristique importante de l'ensemble de données est liée à la nature du flux de données dans la vie réelle. Certaines données peuvent arriver en retard, auquel cas elles ne sont pas disponibles au moment de la prédiction. Pour prendre en compte cette fonctionnalité, il est nécessaire de compléter l'ensemble de données en lançant plusieurs éléments depuis la queue de chaque séquence.
Classification et régression
Naturellement, la première pensée sera de réduire le problème à la classification et à la régression bien connues. Cependant, ces approches rencontrent de sérieuses difficultés.
Pourquoi la régression ne nous convient pas, cela ressort clairement des phénomènes considérés de censure droite et gauche: la distribution du moment d'apparition d'un épisode dans l'ensemble de données peut être décalée. De plus, l'ampleur et le fait de la présence de ce biais ne peuvent pas être déterminés à l'aide de l'ensemble de données lui-même. Le modèle construit peut montrer des résultats arbitrairement bons avec n'importe quelle approche de validation, mais cela, très probablement, n'aura rien à voir avec sa pertinence pour la prévision sur les données de production.
Plus prometteur, à première vue, est une tentative de réduire le problème à la classification: pour fixer une certaine période de temps et déterminer l'épisode qui se produira dans cette période. La principale difficulté ici est la liaison de l'intervalle de temps qui nous intéresse. Il ne peut être lié de manière fiable qu’au moment de la dernière mise à jour de l’historique du patient. En même temps, la demande de prédiction de l'épisode n'est pas du tout liée au temps et peut arriver à tout moment, à la fois à l'intérieur de cette période (et ensuite la période d'intérêt effective est raccourcie), et complètement au-delà - et alors la prédiction perd généralement son sens (voir Fig. 2). Cela induit naturellement une augmentation de la période d'intérêt, ce qui réduit finalement la valeur de la prédiction de toute façon.
 Remarques: 1 - met à jour l'historique du patient; 2 - la dernière mise à jour et la durée qui lui est associée; 3, 4 - demandes de prédiction d'épisode reçues pendant cette période. On voit que l'intervalle de prédiction effectif pour eux est moindre; 5 - demande reçue en dehors de l'intervalle. Pour lui, la prédiction est impossible.
Remarques: 1 - met à jour l'historique du patient; 2 - la dernière mise à jour et la durée qui lui est associée; 3, 4 - demandes de prédiction d'épisode reçues pendant cette période. On voit que l'intervalle de prédiction effectif pour eux est moindre; 5 - demande reçue en dehors de l'intervalle. Pour lui, la prédiction est impossible.Analyse de survie
Comme alternative, nous pouvons considérer l'approche, dans la littérature russe, appelée analyse de survie (analyse de survie, ou analyse du temps sur événement) [3]. Il s'agit d'une famille de modèles spécialement conçus pour travailler avec des données censurées. Elle est basée sur l'approximation de la fonction de risque (fonction de danger, intensité de survenance des événements), qui estime la distribution de probabilité de la survenue d'un événement dans le temps. Cette approche vous permet de prendre correctement en compte la présence de différents types de censure.
Pour le problème résolu, cette approche permet en outre de combiner les deux aspects du problème dans un modèle: déterminer le type d'épisode et prédire le moment de son apparition. Pour ce faire, il suffit de construire un modèle distinct pour chaque type d'épisode, similaire à l'approche one-vs-all dans la classification. L'occurrence d'un épisode non cible peut alors être interprétée comme l'exclusion d'un objet de l'échantillon observé sans l'occurrence d'un événement, qui est un autre type de censure des données et également correctement pris en compte par le modèle. Cette interprétation est également correcte du point de vue de la logique commerciale: si un patient subit une chirurgie de la cataracte, cela n'exclut pas la survenue d'autres épisodes pour lui à l'avenir.
Parmi la famille des modèles d'analyse de survie, on distingue deux variétés: analytique et régressive. Les modèles analytiques sont purement descriptifs, ils sont construits pour l'ensemble de la population, ne prennent pas en compte les caractéristiques de ses membres individuels et ne peuvent donc prédire la survenance d'un événement que pour un membre typique de la population. Contrairement aux modèles analytiques, les modèles de régression sont construits en tenant compte des caractéristiques des membres individuels de la population et permettent de faire des prévisions également pour les membres individuels en tenant compte de leurs caractéristiques. dans ce problème, c'est cette variation qui a été utilisée, ou plutôt, le modèle de risque proportionnel de Cox (ci-après - CoxPH).
Régression de survie et chirurgie de la cataracte
L'approche la plus simple sera similaire à la régression conventionnelle: prendre comme résultat la prévision mathématique du moment du début de l'événement. Étant donné que CoxPH reçoit les données sous forme de vecteur numérique à l'entrée et que notre ensemble de données est en fait une séquence de codes et de procédures de diagnostic (données catégorielles), une transformation préliminaire des données est requise:
- Traduction de codes en une représentation intégrée à l'aide du modèle GloVe préalablement formé [4];
- Agrégation de tous les codes disponibles dans la dernière période de l'histoire du patient en un seul vecteur;
- Codage instantané du sexe du patient et de l'échelle de l'âge.
Nous utilisons les vecteurs de caractéristiques obtenus pour l'apprentissage du modèle et sa validation. Le modèle résultant montre les valeurs suivantes de l'indice de concordance (indice c ou statistique c) [5]:
- 0,71 pour une validation en 5 volets;
- 0,69 sur l'échantillon en attente.
Ceci est comparable au niveau de 0,6–0,7 habituel pour de tels modèles [6].
Cependant, si vous regardez l'erreur absolue moyenne entre le moment prévu de survenue de l'épisode et le moment réel, il s'avère que l'erreur est de 5 jours. La raison d'une telle grosse erreur est que l'optimisation pour c-index ne garantit que l'ordre correct des valeurs: si un événement doit se produire plus tôt qu'un autre, alors les valeurs prévues du temps prévu pour les événements seront respectivement de moins l'une de l'autre. De plus, aucune déclaration n'est faite concernant les valeurs prédites elles-mêmes.
Une autre variante possible de la valeur de sortie du modèle est un tableau de valeurs de la fonction de risque à différents moments. Cette option a une structure plus complexe, elle est plus difficile à interpréter que la précédente, mais en même temps elle fournit plus d'informations.
La modification du format de sortie nécessite une manière différente d'évaluer la qualité du modèle: nous devons nous assurer que pour les exemples positifs (lorsqu'un épisode se produit), le niveau de risque est plus élevé que pour les exemples négatifs (lorsqu'un épisode ne se produit pas). Pour ce faire, pour chaque distribution prédite de la fonction de risque dans l'échantillon retardé, nous passerons du tableau de valeurs à une valeur - le maximum. Après avoir compté les valeurs médianes pour les exemples positifs et négatifs, nous verrons qu'elles diffèrent de manière fiable: 0,13 contre 0,04, respectivement.
Ensuite, nous utilisons ces valeurs pour construire la courbe ROC et calculer la zone en dessous - ROC AUC, qui est de 0,92, ce qui est acceptable pour le problème résolu.
Conclusion
Ainsi, nous avons vu que l'analyse de survie est la meilleure approche pour résoudre le problème de la prévision des épisodes médicaux, en tenant compte de toutes les nuances du problème et des données disponibles. Cependant, son application implique un format différent de la sortie du modèle et une approche différente pour évaluer sa qualité.
L'application du modèle CoxPH à la prévision des épisodes de chirurgie de la cataracte nous a permis d'atteindre des indicateurs de qualité du modèle acceptables. Une approche similaire peut être appliquée à d'autres types d'épisodes, mais les indicateurs de qualité spécifiques des modèles ne peuvent être évalués directement que dans le processus de modélisation.
Littérature
[1] Modification clinique de la CIM-10
en.wikipedia.org/wiki/ICD-10_Clinical_Modification[2] Système de codage des procédures communes de soins de santé
en.wikipedia.org/wiki/Healthcare_Common_Procedure_Coding_System[3] Analyse de survie
en.wikipedia.org/wiki/Survival_analysis[4] GloVe: vecteurs mondiaux pour la représentation des mots
nlp.stanford.edu/projects/glove[5] Statistique C: définition, exemples, pondération et signification
www.statisticshowto.datasciencecentral.com/c-statistic[6] VC Raykar et al. On Ranking in Survival Analysis: Bounds on the Concordance Index
papers.nips.cc/paper/3375-on-ranking-in-survival-analysis-bounds-on-the-concordance-index.pdf