Pendant des décennies, la réutilisation de logiciels a été discutée plus souvent qu'elle ne l'était réellement. Aujourd'hui, la situation est inverse: les développeurs réutilisent quotidiennement les programmes des autres sous la forme de dépendances logicielles, et le problème lui-même reste presque inexploré.
Ma propre expérience comprend une décennie de travail avec
le référentiel interne de Google , où les dépendances sont définies comme un concept prioritaire, ainsi que le développement d'
un système de dépendance pour le langage de programmation Go .
Les dépendances comportent des risques graves qui sont trop souvent négligés. La transition vers la simple réutilisation des plus petits logiciels s'est faite si rapidement que nous n'avons pas encore développé de meilleures pratiques pour la sélection et l'utilisation efficaces des dépendances. Même pour prendre des décisions quand elles sont appropriées et quand elles ne le sont pas. Le but de cet article est d'évaluer les risques et de stimuler la recherche de solutions dans ce domaine.
Qu'est-ce que la dépendance?
Dans le développement moderne, la
dépendance est un code supplémentaire appelé à partir d'un programme. L'ajout d'une dépendance évite la répétition du travail déjà effectué: conception, écriture, test, débogage et prise en charge d'une unité de code spécifique. Nous appelons cette unité de code un
package , bien que sur certains systèmes, d'autres termes, comme une bibliothèque ou un module, soient utilisés à la place d'un package.
Accepter les dépendances externes est une vieille pratique: la plupart des programmeurs ont téléchargé et installé la bibliothèque nécessaire, que ce soit PCRE ou zlib depuis C, Boost ou Qt depuis C ++, JodaTime ou Junit depuis Java. Ces packages ont du code débogué de haute qualité qui nécessite une expérience considérable pour créer. Si un programme a besoin des fonctionnalités d'un tel package, il est beaucoup plus facile de télécharger, d'installer et de mettre à jour manuellement le package que de développer cette fonctionnalité à partir de zéro. Mais les coûts initiaux élevés signifient que la réutilisation manuelle est coûteuse: les petits paquets sont plus faciles à écrire vous-même.
Un gestionnaire de dépendances (parfois appelé gestionnaire de packages) automatise le téléchargement et l'installation des packages de dépendances. Les gestionnaires de dépendances facilitant le téléchargement et l'installation de packages individuels, la réduction des coûts fixes rend les petits packages économiques à publier et à réutiliser.
Par exemple, un gestionnaire de dépendances Node.js appelé NPM donne accès à plus de 750 000 packages. L'un d'eux,
escape-string-regexp , contient une seule fonction qui échappe aux opérateurs d'expression régulière des données d'entrée. Toute mise en œuvre:
var matchOperatorsRe = /[|\\{}()[\]^$+*?.]/g; module.exports = function (str) { if (typeof str !== 'string') { throw new TypeError('Expected a string'); } return str.replace(matchOperatorsRe, '\\$&'); };
Avant l'apparition des gestionnaires de dépendances, il était impossible d'imaginer la publication d'une bibliothèque à huit lignes: trop de frais généraux et trop peu d'avantages. Mais NPM a réduit les frais généraux à presque zéro, ce qui a permis de regrouper et de réutiliser des fonctionnalités presque triviales. Fin janvier 2019, la dépendance
escape-string-regexp été intégrée à près de mille autres packages NPM, sans parler de tous les packages que les développeurs écrivent pour leur propre usage et ne publient pas dans le domaine public.
Maintenant, les gestionnaires de dépendances sont apparus pour presque tous les langages de programmation. Maven Central (Java), Nuget (.NET), Packagist (PHP), PyPI (Python) et RubyGems (Ruby) - chacun d'eux a plus de 100 000 packages. L'avènement d'une telle réutilisation généralisée de petits packages est l'un des plus grands changements dans le développement de logiciels au cours des deux dernières décennies. Et si nous ne faisons pas plus attention, cela entraînera de graves problèmes.
Qu'est-ce qui pourrait mal tourner?
Dans le cadre de cette discussion, un package est un code téléchargé depuis Internet. L'ajout d'une dépendance confie le travail de développement de ce code - conception, écriture, test, débogage et support - à quelqu'un d'autre sur Internet que vous ne connaissez généralement pas. En utilisant ce code, vous exposez votre propre programme aux effets de tous les plantages et défauts de la dépendance. L'exécution de votre logiciel
dépend désormais littéralement du code d'un inconnu sur Internet. Pour le dire ainsi, tout semble très précaire. Pourquoi quelqu'un serait-il même d'accord avec cela?
Nous sommes d'accord, parce que c'est facile, parce que tout semble fonctionner, parce que tout le monde le fait aussi, et surtout, parce que cela semble être la continuation naturelle d'une pratique établie depuis des siècles. Mais il y a une différence importante que nous ignorons.
Il y a des décennies, la plupart des développeurs ont également fait confiance à d'autres pour écrire des programmes dont ils dépendaient, tels que des systèmes d'exploitation et des compilateurs. Ce logiciel a été acheté auprès de sources bien connues, souvent avec une sorte d'accord de support. Il y a encore de la place pour les
erreurs ou les naufrages . Mais nous savions au moins à qui nous avions affaire et, en règle générale, nous pouvions utiliser des mesures d'influence commerciales ou légales.
Le phénomène des logiciels libres, distribués gratuitement sur Internet, a largement supplanté l'ancienne pratique d'achat de logiciels. Lorsque la réutilisation était encore difficile, peu de projets introduisaient de telles dépendances. Bien que leurs licences aient généralement renoncé à toute «garantie de valeur commerciale et d'adéquation à un usage particulier», les projets ont acquis une bonne réputation. Les utilisateurs ont largement pris en compte cette réputation dans leurs décisions. Au lieu d'interventions commerciales et juridiques, un soutien de réputation est venu. De nombreux packages courants de cette époque jouissent encore d'une bonne réputation: par exemple, BLAS (publié en 1979), Netlib (1987), libjpeg (1991), LAPACK (1992), HP STL (1994) et zlib (1995).
Les gestionnaires de lots ont réduit le modèle de réutilisation du code à une extrême simplicité: les développeurs peuvent désormais partager le code avec précision pour des fonctions individuelles sur des dizaines de lignes. C'est une grande réussite technique. Il existe d'innombrables packages disponibles, et un projet peut en inclure un grand nombre, mais les mécanismes de confiance de code commercial, juridique ou de réputation appartiennent au passé. Nous faisons plus confiance au code, bien qu'il y ait moins de raisons de faire confiance.
Le coût d'une mauvaise dépendance peut être considéré comme la somme de tous les mauvais résultats possibles dans une série du prix de chaque mauvais résultat multiplié par sa probabilité (risque).
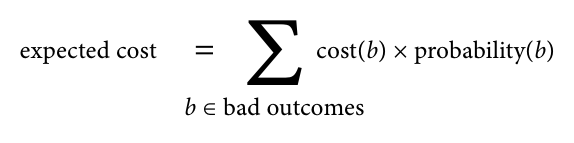
Le prix d'un mauvais résultat dépend du contexte dans lequel la dépendance est utilisée. À une extrémité du spectre se trouve un projet de passe-temps personnel où le prix de la plupart des mauvais résultats est proche de zéro: vous vous amusez simplement, les erreurs n'ont aucun impact réel, sauf pour un peu plus de temps passé, et les déboguer peut même être amusant. Ainsi, la probabilité de risque est presque hors de propos: elle est multipliée par zéro. À l'autre extrémité du spectre se trouve le logiciel de production, qui doit être pris en charge pendant des années. Ici, le coût de la dépendance peut être très élevé: les serveurs peuvent tomber, les données confidentielles peuvent être divulguées, les clients peuvent en souffrir, les entreprises peuvent même faire faillite. En production, il est beaucoup plus important d'évaluer et de minimiser le risque de défaillance grave.
Quel que soit le prix attendu, il existe certaines approches pour évaluer et réduire les risques d'ajout de dépendances. Il est probable que les gestionnaires de packages devraient être optimisés pour réduire ces risques, alors qu'ils se sont jusqu'à présent concentrés sur la réduction des coûts de téléchargement et d'installation.
Contrôle de dépendance
Vous n'embaucheriez pas un développeur dont vous n'avez jamais entendu parler et dont vous ne savez rien. Tout d'abord, vous apprendrez quelque chose sur lui: vérifiez les liens, menez une interview, etc. Avant de dépendre du package que vous avez trouvé sur Internet, il est également sage d'en apprendre un peu plus sur ce package.
Une vérification de base peut donner une idée de la probabilité de problèmes lors de l'utilisation de ce code. Si des problèmes mineurs sont détectés lors de l'inspection, vous pouvez prendre des mesures pour les éliminer. Si le contrôle révèle de graves problèmes, il peut être préférable de ne pas utiliser le package: vous pouvez en trouver un plus adapté, ou peut-être devrez-vous le développer vous-même. N'oubliez pas que les packages open source sont publiés par les auteurs dans l'espoir qu'ils seront utiles, mais sans garantir la convivialité ou le support. En cas d'échec de production, c'est à vous de le déboguer. Comme l'a averti la première
licence publique générale GNU , «tous les risques associés à la qualité et aux performances du programme vous incombent. Si le programme s'avère défectueux, vous assumez les frais de tous les entretiens, réparations ou corrections nécessaires. »
Ensuite, nous décrivons quelques considérations pour vérifier le package et décider s'il doit en dépendre.
La conception
La documentation du package est-elle claire? L'API a-t-elle une conception claire? Si les auteurs peuvent bien expliquer l'API et la conception à une personne, cela augmente la probabilité qu'ils expliquent également bien la mise en œuvre de l'ordinateur dans le code source. L'écriture de code pour une API claire et bien conçue est plus simple, plus rapide et probablement moins sujette aux erreurs. Les auteurs ont-ils documenté ce qu'ils attendent du code client pour être compatible avec les futures mises à jour? (Les exemples incluent les documents de compatibilité
C ++ et
Go ).
Qualité du code
Le code est-il bien écrit? Lisez quelques extraits. Les auteurs semblent-ils prudents, consciencieux et cohérents? Cela ressemble-t-il au code que vous souhaitez déboguer? Vous devrez peut-être le faire.
Développez vos propres moyens systématiques pour vérifier la qualité du code. Quelque chose de simple, comme la compilation en C ou C ++ avec des avertissements importants du compilateur activés (par exemple,
-Wall ), peut donner une idée du sérieux avec lequel les développeurs ont travaillé pour éviter divers comportements non définis. Les langages récents, tels que Go, Rust et Swift, utilisent le mot clé
unsafe pour désigner le code qui viole le système de type; regardez combien il y a de code dangereux. Des outils sémantiques plus avancés tels que
Infer ou
SpotBugs sont également utiles. Les linters sont moins utiles: vous devez ignorer les conseils standard sur des sujets tels que le style des parenthèses et vous concentrer sur les problèmes sémantiques.
N'oubliez pas les méthodes de développement que vous ne connaissez peut-être pas. Par exemple, la bibliothèque SQLite se présente sous la forme d'un fichier unique avec 200 000 codes et un en-tête de 11 000 lignes, suite à la fusion de plusieurs fichiers. La taille même de ces fichiers soulève immédiatement un drapeau rouge, mais une enquête plus approfondie conduira au code source réel du développement: une arborescence de fichiers traditionnelle avec plus d'une centaine de fichiers C source, des tests et des scripts de support. Il s'avère que la distribution à fichier unique est construite automatiquement à partir des sources d'origine: c'est plus facile pour les utilisateurs finaux, en particulier ceux qui n'ont pas de gestionnaires de dépendances. (Le code compilé fonctionne également plus rapidement car le compilateur voit plus d'options d'optimisation).
Test
Y a-t-il des tests dans le code? Pouvez-vous les contrôler? Passent-ils? Les tests établissent que la fonctionnalité principale du code est correcte et signalent que le développeur essaie sérieusement de la conserver. Par exemple, l'arborescence de développement SQLite contient une suite de tests incroyablement détaillée avec plus de 30 000 cas de test individuels. Il existe une
documentation pour les développeurs expliquant la stratégie de test. En revanche, s'il y a peu ou pas de tests du tout, ou si les tests échouent, c'est un grave drapeau rouge: les changements futurs dans le package sont susceptibles de conduire à des régressions qui pourraient être facilement détectées. Si vous insistez sur des tests dans votre code (non?), Vous devez fournir des tests pour le code que vous transmettez à d'autres.
En supposant que les tests existent, s'exécutent et réussissent, vous pouvez collecter des informations supplémentaires en exécutant des outils pour analyser la couverture du code,
détecter les conditions de concurrence, vérifier l'allocation de mémoire et détecter les fuites de mémoire.
Débogage
Trouvez le traqueur de bogues pour ce paquet. Y a-t-il de nombreux messages d'erreur ouverts? Depuis combien de temps sont-ils ouverts? Combien de bugs sont corrigés? Y a-t-il des bogues corrigés récemment? S'il y a beaucoup de questions ouvertes sur les vrais bugs, surtout pas fermés depuis longtemps, c'est un mauvais signe. En revanche, si les erreurs sont rares et rapidement corrigées, c'est super.
Le soutien
Regardez l'histoire des commits. Depuis combien de temps le code est-il activement maintenu? Est-il activement soutenu maintenant? Les packages qui ont été activement pris en charge pendant une longue période sont susceptibles de continuer à être pris en charge. Combien de personnes travaillent sur le package? De nombreux packages sont des projets personnels que les développeurs créent pour le divertissement pendant leur temps libre. D'autres sont le résultat de milliers d'heures de travail pour un groupe de développeurs rémunérés. En général, les packages du deuxième type corrigent généralement les erreurs plus rapidement, introduisent régulièrement de nouvelles fonctions et, en général, ils sont mieux pris en charge.
D'un autre côté, certains codes sont vraiment «parfaits». Par exemple, il ne sera peut-être plus nécessaire de modifier à nouveau la
escape-string-regexp de NPM.
Utiliser
Combien de packages dépendent de ce code? Les gestionnaires de packages fournissent souvent de telles statistiques, ou vous pouvez voir sur Internet à quelle fréquence d'autres développeurs mentionnent ce package. Un plus grand nombre d'utilisateurs signifie au moins le fait que pour beaucoup, le code fonctionne assez bien et que les erreurs le seront plus rapidement. Une utilisation généralisée est également une garantie partielle de service continu: si un package largement utilisé perd son mainteneur, il est très probable qu'un utilisateur intéressé assume son rôle.
Par exemple, des bibliothèques comme PCRE, Boost ou JUnit sont incroyablement largement utilisées. Cela rend plus probable - bien que cela ne garantisse certainement pas - que les erreurs que vous avez pu rencontrer soient déjà corrigées parce que d'autres les ont rencontrées avant vous.
La sécurité
Ce package fonctionnera-t-il avec une entrée non sécurisée? Si oui, dans quelle mesure est-il résistant aux données malveillantes? At-il des bogues qui sont mentionnés dans la
base de données nationale de vulnérabilité (NVD) ?
Par exemple, quand en 2006 Jeff Dean et moi avons commencé à travailler sur
Google Code Search (
grep pour les bases de code publiques), la bibliothèque d'expression régulière populaire PCRE semblait être le choix évident. Cependant, lors d'une conversation avec l'équipe de sécurité de Google, nous avons appris que PCRE a une longue histoire de problèmes, tels que des dépassements de tampon, en particulier dans l'analyseur. Nous en avons été nous-mêmes convaincus en recherchant PCRE dans NVD. Cette découverte ne nous a pas immédiatement conduit à abandonner PCRE, mais nous a fait réfléchir plus attentivement sur les tests et l'isolement.
Licence
Le code est-il correctement autorisé? At-il même une licence? La licence est-elle acceptable pour votre projet ou entreprise? Une partie étonnante des projets GitHub n'a pas de licence claire. Votre projet ou votre entreprise peut imposer des restrictions supplémentaires sur les licences de dépendance. Par exemple, Google
interdit l' utilisation de code sous des licences telles que AGPL (trop stricte) et type WTFPL (trop vague).
Dépendances
Ce package a-t-il ses propres dépendances? Les carences des dépendances indirectes sont tout aussi néfastes que les inconvénients des dépendances directes. Les gestionnaires de packages peuvent répertorier toutes les dépendances transitives d'un package donné, et chacune d'elles devrait idéalement être vérifiée comme décrit dans cette section. Un package avec de nombreuses dépendances nécessitera beaucoup de travail.
De nombreux développeurs n'ont jamais regardé la liste complète des dépendances transitives de leur code et ne savent pas de quoi ils dépendent. Par exemple, en mars 2016, la communauté des utilisateurs de NPM a constaté que de nombreux projets populaires - y compris Babel, Ember et React - dépendent indirectement d'un petit paquet appelé le
left-pad d'une fonction à 8 lignes. Ils l'ont découvert lorsque l'auteur de
left-pad supprimé le package de NPM,
brisant par inadvertance la plupart des assemblages d'utilisateurs de Node.js. Et le
left-pad guère exceptionnel à cet égard. Par exemple, 30% des 750 000 paquets dans NPM dépendent - au moins indirectement - de
escape-string-regexp . En adaptant l'observation de Leslie Lamport des systèmes distribués, le gestionnaire de paquets crée facilement une situation où une défaillance de paquet, dont vous ne saviez même pas l'existence, pourrait rendre votre propre code inutilisable.
Test de toxicomanie
Le processus de vérification doit inclure l'exécution de vos propres tests de package. Si le package a réussi le test et que vous décidez de faire dépendre votre projet de celui-ci, l'étape suivante devrait être d'écrire de nouveaux tests axés spécifiquement sur la fonctionnalité de votre application. Ces tests commencent souvent comme de courts programmes autonomes pour vous assurer que vous pouvez comprendre l'API du package et qu'il fait ce que vous pensez (si vous ne pouvez pas comprendre ou s'il ne fait pas ce dont vous avez besoin, arrêtez immédiatement!). Ensuite, cela vaut la peine de transformer ces programmes en tests automatisés qui s'exécuteront avec les nouvelles versions du package. Si vous trouvez une erreur et que vous avez un correctif potentiel, vous pouvez facilement redémarrer ces tests pour un projet spécifique et vous assurer que le correctif n'a rien cassé d'autre.
Une attention particulière devrait être accordée aux zones problématiques identifiées lors de l'examen de la situation de référence. Pour la recherche de code, par expérience, nous savions que PCRE prend parfois beaucoup de temps pour exécuter certaines expressions régulières. Notre plan initial était de créer des pools de threads séparés pour les expressions régulières «simples» et «complexes». L'un des premiers tests a été une référence qui a comparé
pcregrep à plusieurs autres implémentations
grep . Lorsque nous avons constaté que
pcregrep était 70 fois plus lent que le
grep le plus rapide pour un cas de test de base, nous avons commencé à repenser notre plan d'utilisation de PCRE. Malgré le fait que nous ayons finalement complètement abandonné PCRE, ce test reste dans notre base de code aujourd'hui.
Abstraction des dépendances
La dépendance de package est une solution que vous pouvez désactiver à l'avenir. Peut-être que les mises à jour mèneront le paquet dans une nouvelle direction. De graves problèmes de sécurité peuvent être trouvés. Peut-être que la meilleure option apparaîtra. Pour toutes ces raisons, cela vaut la peine de simplifier la migration du projet vers une nouvelle dépendance.
Si un package est appelé à partir de plusieurs emplacements dans le code source du projet, vous devrez apporter des modifications à tous ces emplacements différents pour basculer vers une nouvelle dépendance. Pire encore, si le package est présenté dans l'API de votre propre projet, la migration vers une nouvelle dépendance nécessitera d'apporter des modifications à tout le code qui appelle votre API, et cela peut déjà être hors de votre contrôle. Pour éviter de tels coûts, il est logique de définir votre propre interface avec un wrapper mince qui implémente cette interface à l'aide d'une dépendance. Veuillez noter que l'encapsuleur ne doit inclure que ce dont le projet a besoin de la dépendance, et non tout ce que la dépendance offre. Idéalement, cela vous permet de remplacer ultérieurement une autre dépendance, également appropriée, en changeant uniquement le wrapper.La migration des tests de chaque projet pour utiliser la nouvelle interface vérifie l'implémentation de l'interface et des wrappers, et simplifie également les tests de tout remplacement potentiel pour la dépendance.Pour Code Search, nous avons développé une classe abstraite Regexpqui définit l'interface de recherche de code nécessaire à partir de n'importe quel moteur d'expression régulière. Ensuite, ils ont écrit un wrapper mince autour de PCRE qui implémente cette interface. Cette méthode a facilité le test de bibliothèques alternatives et a empêché l'introduction accidentelle de la connaissance des composants PCRE internes dans le reste de l'arborescence source. Ceci, à son tour, garantit que si nécessaire, il sera facile de basculer vers une autre dépendance.Isolement des dépendances
Il peut également être approprié d'isoler la dépendance au moment de l'exécution afin de limiter les dommages possibles causés par des erreurs. Par exemple, Google Chrome permet aux utilisateurs d'ajouter des dépendances au navigateur - code d'extension. Lorsque Chrome a été lancé pour la première fois en 2008, il a introduit une fonction critique (désormais standard sur tous les navigateurs) pour isoler chaque extension dans un bac à sable fonctionnant dans un processus distinct du système d'exploitation. Un exploit potentiel dans une extension mal écrite n'avait pas d'accès automatique à toute la mémoire du navigateur lui-mêmeet n'a pas pu effectuer d'appels système inappropriés. Pour la recherche de code, jusqu'à ce que nous supprimions complètement le PCRE, le plan était au moins d'isoler l'analyseur PCRE dans un bac à sable similaire. Aujourd'hui, une autre option serait un bac à sable léger basé sur un hyperviseur, tel que gVisor . L'isolement des dépendances réduit les risques associés à l'exécution de ce code.Même avec ces exemples et d'autres options prêtes à l'emploi, l'isolement de code suspect au moment de l'exécution est encore trop compliqué et rarement effectué. La véritable isolation nécessitera un langage entièrement sécurisé en mémoire, sans s'écraser sur du code non typé. Celles-ci sont complexes non seulement dans les langages totalement dangereux, tels que C et C ++, mais également dans les langages qui fournissent des opérations non sécurisées restreintes, comme Java lorsque JNI est activé, ou comme Go, Rust et Swift lorsque vous activez vos fonctions dangereuses. Même dans un langage à mémoire sûre comme JavaScript, le code a souvent accès à bien plus que ce dont il a besoin. En novembre 2018, il s'est avéré que la dernière version du package npm event-stream(une API de streaming fonctionnelle pour les événements JavaScript) contient un code malveillant déroutantajouté il y a deux mois et demi. Le code a collecté des portefeuilles bitcoin auprès des utilisateurs de l'application mobile Copay, a accédé à des ressources système sans aucun rapport avec le traitement des flux d'événements. L'un des nombreux moyens possibles de se protéger contre ce type de problèmes serait une meilleure isolation des dépendances.Abandon de la dépendance
Si la dépendance semble trop risquée et que vous ne pouvez pas l'isoler, la meilleure option peut être de l'abandonner complètement, ou du moins d'exclure les parties les plus problématiques.Par exemple, lorsque nous avons mieux compris les risques de PCRE, notre plan pour Google Code Search est passé de «utiliser la bibliothèque PCRE directement» à «utiliser PCRE, mais mettre l'analyseur dans le bac à sable», puis «écrire un nouvel analyseur d'expressions régulières, mais enregistrer le moteur PCRE», puis dans «écrire un nouvel analyseur et le connecter à un autre moteur open source plus efficace». Plus tard, Jeff Dean et moi avons également réécrit le moteur, donc il n'y avait plus de dépendances, et nous avons découvert le résultat: RE2 .Si vous n'avez besoin que d'une petite partie de la dépendance, le moyen le plus simple est de faire une copie de ce dont vous avez besoin (bien sûr, en conservant les droits d'auteur et autres mentions légales). Vous assumez la responsabilité de la correction des erreurs, de la maintenance, etc., mais vous êtes également complètement isolé des risques plus importants. Il y a un dicton dans la communauté des développeurs Go : "Un peu de copie vaut mieux qu'un peu de dépendance."Mise à jour des dépendances
Pendant longtemps, la sagesse généralement acceptée dans le logiciel était: "Si cela fonctionne, ne touchez à rien." La mise à jour comporte le risque d'introduire de nouvelles erreurs; sans récompense - si vous n'avez pas besoin d'une nouvelle fonctionnalité, pourquoi prendre le risque? Cette approche ignore deux aspects. Tout d'abord, le coût d'une mise à niveau progressive. Dans le logiciel, la complexité d'apporter des modifications au code n'est pas mise à l'échelle linéairement: dix petits changements sont moins de travail et plus faciles qu'un gros changement correspondant. Deuxièmement, la difficulté de détecter les erreurs déjà corrigées. Surtout dans le contexte de la sécurité, où les erreurs connues sont activement exploitées, chaque jour sans la mettre à jour augmente les risques que les attaquants puissent profiter des bugs de l'ancien code.Par exemple, considérons l'histoire d'Equifax en 2017, que les dirigeants ont racontée en détail dans des témoignages devant le Congrès. Le 7 mars, une nouvelle vulnérabilité a été découverte dans Apache Struts et une version corrigée a été publiée. Le 8 mars, Equifax a reçu la notification US-CERT de la nécessité de mettre à jour toute utilisation d'Apache Struts. Equifax a lancé une analyse du code source et du réseau les 9 et 15 mars, respectivement; pas une seule analyse n'a trouvé de serveurs Web vulnérables ouverts sur Internet. Le 13 mai, les attaquants ont trouvé de tels serveurs que les experts d'Equifax n'ont pas trouvés. Ils ont utilisé la vulnérabilité Apache Struts pour pirater le réseau Equifax et ont volé des informations personnelles et financières détaillées sur 148 millions de personnes au cours des deux prochains mois. Enfin, le 29 juillet, Equifax a remarqué un piratage et l'a annoncé publiquement le 4 septembre. Fin septembre, le PDG d'Equifax, ainsi que CIO et CSO, avaient démissionné et une enquête avait commencé au Congrès.L'expérience d'Equifax conduit au fait que, bien que les gestionnaires de packages connaissent les versions qu'ils utilisent lors de la génération, vous avez besoin d'autres mécanismes pour suivre ces informations lors du déploiement en production. Pour la langue Go, nous expérimentons avec l'inclusion automatique du manifeste dans chaque fichier binaire afin que les processus de déploiement puissent analyser les binaires pour les dépendances qui nécessitent une mise à jour. Go rend également ces informations disponibles au moment de l'exécution, afin que les serveurs puissent accéder aux bases de données des erreurs connues et signaler de manière indépendante au système de surveillance lorsqu'elles doivent être mises à jour.Une mise à jour rapide est importante, mais la mise à jour signifie l'ajout de nouveau code au projet, ce qui devrait signifier la mise à jour de l'évaluation des risques de l'utilisation des dépendances en fonction de la nouvelle version. Au minimum, vous souhaitez voir les différences indiquant les modifications apportées de la version actuelle aux versions mises à jour, ou au moins lire les notes de publication pour identifier les zones de problème les plus probables dans le code mis à jour. Si de nombreux codes changent et que les différences sont difficiles à comprendre, il s'agit également d'informations que vous pouvez inclure dans la mise à jour de votre évaluation des risques.En outre, vous devez réexécuter des tests écrits spécifiquement pour le projet afin de vous assurer que le package mis à jour est au moins aussi adapté au projet que la version précédente. Il est également judicieux de réexécuter vos propres tests de package. Si le package a ses propres dépendances, il est possible que la configuration du projet utilise d'autres versions de ces dépendances (plus anciennes ou plus récentes) que celles utilisées par les auteurs du package. L'exécution de vos propres tests de package vous permet d'identifier rapidement les problèmes spécifiques à la configuration.Encore une fois, les mises à jour ne doivent pas être entièrement automatiques. Avant de déployer des versions mises à jour , assurez-vous qu'elles conviennent à votre environnement .Si le processus de mise à jour implique de réexécuter les tests d'intégration et de qualification déjà écrits, le retard dans la mise à jour est dans la plupart des cas plus risqué qu'une mise à jour rapide.La fenêtre des mises à jour de sécurité critiques est particulièrement petite. Après le piratage d'Equifax, les équipes de sécurité judiciaire ont trouvé des preuves que des attaquants (peut-être différents) ont réussi à exploiter la vulnérabilité Apache Struts sur les serveurs affectés le 10 mars, trois jours seulement après sa divulgation publique. Mais ils n'y ont lancé qu'une seule équipe whoami.Surveillez vos dépendances
Même après tout cela, le travail n'est pas terminé. Il est important de continuer à surveiller les dépendances et, dans certains cas, même à les abandonner.Tout d'abord, assurez-vous de continuer à utiliser des versions spécifiques de packages. La plupart des gestionnaires de packages vous permettent désormais d'enregistrer facilement ou même automatiquement le hachage cryptographique du code source attendu pour une version donnée du package, puis de vérifier ce hachage lorsque vous téléchargez à nouveau le package sur un autre ordinateur ou dans un environnement de test. Cela garantit que la génération utilisera le même code source de dépendance que vous avez testé et testé. Ces contrôles ont empêché l'attaquantevent-stream, injecte automatiquement du code malveillant dans la version 3.3.5 déjà publiée. Au lieu de cela, l'attaquant a dû créer une nouvelle version 3.3.6 et attendre que les gens mettent à jour (sans regarder attentivement les modifications).Il est également important de surveiller l'émergence de nouvelles dépendances indirectes: les mises à jour peuvent facilement introduire de nouveaux packages, dont dépend désormais la réussite de votre projet. Ils méritent également votre attention. Dans le cas, le event-streamcode malveillant était caché dans un autre package flatMap-stream, qui a event-streamété ajouté en tant que nouvelle dépendance dans la nouvelle version .Les dépendances rampantes peuvent également affecter la taille du projet. Pendant le développement de Google Sawzall- Langage de traitement des journaux JIT - à différents moments, les auteurs ont constaté que le binaire principal de l'interpréteur contient non seulement JIT Sawzall, mais aussi des interprètes PostScript, Python et JavaScript (inutilisés). À chaque fois, le coupable s'est avéré être des dépendances inutilisées déclarées par une bibliothèque Sawzall, combinées avec le fait que le système de génération de Google a utilisé entièrement automatiquement la nouvelle dépendance. C'est pourquoi le compilateur Go génère une erreur lors de l'importation d'un package inutilisé.La mise à jour est le moment naturel pour réviser votre décision d'utiliser une dépendance changeante. Il est également important de revoir périodiquement toute dépendance qui neest en train de changer. Semble-t-il plausible qu'il n'y ait aucun problème de sécurité ou autre erreur à corriger? Le projet est-il abandonné? Il est peut-être temps de planifier un remplacement pour cette dépendance.Il est également important de revérifier le journal de sécurité de chaque dépendance. Par exemple, Apache Struts a révélé de graves vulnérabilités dans l'exécution de code à distance en 2016, 2017 et 2018. Même si vous avez de nombreux serveurs qui le démarrent et le mettent à jour rapidement, un tel historique suggère s'il vaut la peine de l'utiliser.Conclusion
L'ère de la réutilisation des logiciels est enfin arrivée, et je ne veux pas minimiser les avantages: cela a apporté une transformation extrêmement positive aux développeurs. Cependant, nous avons adopté cette transformation sans tenir pleinement compte des conséquences potentielles. Les anciennes raisons de faire confiance aux dépendances perdent de leur pertinence en même temps que nous avons plus de dépendances que jamais.L'analyse critique des dépendances spécifiques que j'ai décrite dans cet article représente une quantité importante de travail et reste l'exception plutôt que la règle. Mais je doute qu'il y ait des développeurs qui travaillent vraiment dur pour le faire pour chaque nouvelle dépendance possible. Je n'ai fait qu'une partie de ce travail pour certaines de mes propres dépendances. Fondamentalement, toute la solution se résume à ce qui suit: "Voyons ce qui se passe." Trop souvent, quelque chose de plus semble trop d'effort.Mais les attaques de Copay et d'Equifax sont des avertissements clairs de problèmes réels dans la façon dont nous utilisons les dépendances logicielles aujourd'hui. Nous ne devons pas ignorer les avertissements. J'offre trois recommandations générales.- . , , , . , .
- . , , . , , . , , , .
- . . . , . , , . , , API. .
Il y a beaucoup de bons logiciels. Travaillons ensemble et découvrons comment l'utiliser en toute sécurité.