
Partie 1/3 ici .
Partie 2/3 ici .
Bonjour à tous! Et voici la troisième partie du guide Kubernetes on bare metal! Je ferai attention à la surveillance du cluster et à la collecte des journaux, nous lancerons également une application de test pour utiliser les composants du cluster préconfigurés. Ensuite, nous effectuerons plusieurs tests de résistance et vérifierons la stabilité de ce schéma de cluster.
L'outil le plus populaire que la communauté Kubernetes propose pour fournir une interface Web et obtenir des statistiques de cluster est le tableau de bord Kubernetes . En fait, il est toujours en cours de développement, mais même maintenant, il peut fournir des données supplémentaires pour résoudre les problèmes d'application et gérer les ressources du cluster.
Le sujet est en partie controversé. Est-il vrai que vous avez besoin d'une sorte d'interface Web pour gérer le cluster, ou est-ce suffisant pour utiliser l'outil de console kubectl ? Eh bien, parfois ces options se complètent.
Développons notre tableau de bord Kubernetes et voyons. Avec un déploiement standard, ce tableau de bord ne démarre qu'à l'adresse de l'hôte local. Ainsi, vous devez utiliser la commande proxy kubectl pour l' expansion , mais elle n'est toujours disponible que sur votre périphérique de contrôle kubectl local. Pas mal du point de vue de la sécurité, mais je veux avoir accès dans le navigateur, en dehors du cluster, et je suis prêt à prendre des risques (après tout, ssl avec un token efficace est utilisé).
Pour appliquer ma méthode, vous devez légèrement modifier le fichier de déploiement standard dans la section service. Pour ouvrir ce tableau de bord sur une adresse ouverte, nous utilisons notre équilibreur de charge.
Nous entrons dans le système de la machine avec l'utilitaire kubectl configuré et créons:
control# vi kube-dashboard.yaml # Copyright 2017 The Kubernetes Authors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ------------------- Dashboard Secret ------------------- # apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-certs namespace: kube-system type: Opaque --- # ------------------- Dashboard Service Account ------------------- # apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Role & Role Binding ------------------- # kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kubernetes-dashboard-minimal namespace: kube-system rules: # Allow Dashboard to create 'kubernetes-dashboard-key-holder' secret. - apiGroups: [""] resources: ["secrets"] verbs: ["create"] # Allow Dashboard to create 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] verbs: ["create"] # Allow Dashboard to get, update and delete Dashboard exclusive secrets. - apiGroups: [""] resources: ["secrets"] resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"] verbs: ["get", "update", "delete"] # Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] resourceNames: ["kubernetes-dashboard-settings"] verbs: ["get", "update"] # Allow Dashboard to get metrics from heapster. - apiGroups: [""] resources: ["services"] resourceNames: ["heapster"] verbs: ["proxy"] - apiGroups: [""] resources: ["services/proxy"] resourceNames: ["heapster", "http:heapster:", "https:heapster:"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubernetes-dashboard-minimal namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubernetes-dashboard-minimal subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Deployment ------------------- # kind: Deployment apiVersion: apps/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard spec: containers: - name: kubernetes-dashboard image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1 ports: - containerPort: 8443 protocol: TCP args: - --auto-generate-certificates # Uncomment the following line to manually specify Kubernetes API server Host # If not specified, Dashboard will attempt to auto discover the API server and connect # to it. Uncomment only if the default does not work. # - --apiserver-host=http://my-address:port volumeMounts: - name: kubernetes-dashboard-certs mountPath: /certs # Create on-disk volume to store exec logs - mountPath: /tmp name: tmp-volume livenessProbe: httpGet: scheme: HTTPS path: / port: 8443 initialDelaySeconds: 30 timeoutSeconds: 30 volumes: - name: kubernetes-dashboard-certs secret: secretName: kubernetes-dashboard-certs - name: tmp-volume emptyDir: {} serviceAccountName: kubernetes-dashboard # Comment the following tolerations if Dashboard must not be deployed on master tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule --- # ------------------- Dashboard Service ------------------- # kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: type: LoadBalancer ports: - port: 443 targetPort: 8443 selector: k8s-app: kubernetes-dashboard
Exécutez ensuite:
control# kubectl create -f kube-dashboard.yaml control# kubectl get svc --namespace=kube-system kubernetes-dashboard LoadBalancer 10.96.164.141 192.168.0.240 443:31262/TCP 8h
Eh bien, comme vous pouvez le voir, notre BN a ajouté l'IP 192.168.0.240 pour ce service. Essayez maintenant d'ouvrir https://192.168.0.240 pour afficher le tableau de bord Kubernetes.
Il y a 2 façons d'accéder: utilisez le fichier admin.conf de notre nœud maître, que nous avons utilisé précédemment lors de la configuration de kubectl, ou créez un compte de service spécial avec un jeton de sécurité.
Créons un utilisateur administrateur:
control# vi kube-dashboard-admin.yaml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system control# kubectl create -f kube-dashboard-admin.yaml serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created
Vous avez maintenant besoin d'un jeton pour entrer dans le système:
control# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}') Name: admin-user-token-vfh66 Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name: admin-user kubernetes.io/service-account.uid: 3775471a-3620-11e9-9800-763fc8adcb06 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1025 bytes namespace: 11 bytes token: erJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwna3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJr dWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VmLXRva2VuLXZmaDY2Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZ XJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIzNzc1NDcxYS0zNjIwLTExZTktOTgwMC03Nj NmYzhhZGNiMDYiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.JICASwxAJHFX8mLoSikJU1tbij4Kq2pneqAt6QCcGUizFLeSqr2R5x339ZR8W4 9cIsbZ7hbhFXCATQcVuWnWXe2dgXP5KE8ZdW9uvq96rm_JvsZz0RZO03UFRf8Exsss6GLeRJ5uNJNCAr8No5pmRMJo-_4BKW4OFDFxvSDSS_ZJaLMqJ0LNpwH1Z09SfD8TNW7VZqax4zuTSMX_yVS ts40nzh4-_IxDZ1i7imnNSYPQa_Oq9ieJ56Q-xuOiGu9C3Hs3NmhwV8MNAcniVEzoDyFmx4z9YYcFPCDIoerPfSJIMFIWXcNlUTPSMRA-KfjSb_KYAErVfNctwOVglgCISA
Copiez le jeton et collez-le dans le champ du jeton sur l'écran de connexion.
Après être entré dans le système, vous pouvez étudier le cluster un peu plus en profondeur - j'aime cet outil.
La prochaine étape vers l'approfondissement du système de surveillance de notre cluster est d'installer le tas .
Heapster vous permet de surveiller le cluster de conteneurs et d'analyser les performances de Kubernetes (version v1.0.6 et supérieure). Il propose des plateformes appropriées.
Cet outil offre des statistiques sur l'utilisation du cluster via la console et ajoute également plus d'informations sur les ressources de nœuds et de foyer au tableau de bord Kubernetes.
Il n'y a pas de difficulté à l'installer sur du métal nu, et j'avais besoin de mener une enquête: pourquoi l'outil ne fonctionne pas dans la version d'origine, mais j'ai trouvé une solution.
Continuons donc et approuvons ce module complémentaire:
control# vi heapster.yaml apiVersion: v1 kind: ServiceAccount metadata: name: heapster namespace: kube-system --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: heapster namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: heapster spec: serviceAccountName: heapster containers: - name: heapster image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: Heapster name: heapster namespace: kube-system spec: ports: - port: 80 targetPort: 8082 selector: k8s-app: heapster --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: heapster roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:heapster subjects: - kind: ServiceAccount name: heapster namespace: kube-system
Il s'agit du fichier de déploiement standard le plus courant de la communauté Heapster, avec seulement une légère différence: pour le faire fonctionner sur notre cluster, la ligne " source = " dans le déploiement heapster est modifiée comme suit:
--source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true
Dans cette description, vous trouverez toutes ces options. J'ai changé le port kubelet en 10250 et désactivé la vérification du certificat SSL (il y avait un petit problème avec ça).
Nous devons également ajouter des autorisations pour obtenir des statistiques sur les nœuds dans le rôle RBAC Heapster; ajoutez ces quelques lignes à la fin du rôle:
control# kubectl edit clusterrole system:heapster ...... ... - apiGroups: - "" resources: - nodes/stats verbs: - get
En résumé, votre rôle RBAC devrait ressembler à ceci:
# Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" creationTimestamp: "2019-02-22T18:58:32Z" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:heapster resourceVersion: "6799431" selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/system%3Aheapster uid: d99065b5-36d3-11e9-a7e6-763fc8adcb06 rules: - apiGroups: - "" resources: - events - namespaces - nodes - pods verbs: - get - list - watch - apiGroups: - extensions resources: - deployments verbs: - get - list - watch - apiGroups: - "" resources: - nodes/stats verbs: - get
Ok, exécutons maintenant la commande pour nous assurer que le déploiement du tas est correctement lancé.
control# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% kube-master1 183m 9% 1161Mi 60% kube-master2 235m 11% 1130Mi 59% kube-worker1 189m 4% 1216Mi 41% kube-worker2 218m 5% 1290Mi 44% kube-worker3 181m 4% 1305Mi 44%
Eh bien, si vous avez reçu des données sur la sortie, tout se fait correctement. Revenons à notre page de tableau de bord et jetons un œil aux nouveaux graphiques qui sont désormais disponibles.

Désormais, nous pouvons également suivre l'utilisation réelle des ressources pour les nœuds de cluster, les foyers, etc.
Si cela ne suffit pas, vous pouvez encore améliorer les statistiques en ajoutant InfluxDB + Grafana. Cela ajoutera la possibilité de dessiner vos propres panneaux Grafana.
Nous utiliserons cette version de l' installation InfluxDB + Grafana à partir de la page Heapster Git, mais, comme d'habitude, nous apporterons des corrections. Comme nous avions déjà configuré le déploiement de tas, nous avons seulement besoin d'ajouter Grafana et InfluxDB, puis de modifier le déploiement de tas existant afin qu'il place également des mesures dans Influx.
Ok, créons les déploiements InfluxDB et Grafana:
control# vi influxdb.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-influxdb namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: influxdb spec: containers: - name: influxdb image: k8s.gcr.io/heapster-influxdb-amd64:v1.5.2 volumeMounts: - mountPath: /data name: influxdb-storage volumes: - name: influxdb-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-influxdb name: monitoring-influxdb namespace: kube-system spec: ports: - port: 8086 targetPort: 8086 selector: k8s-app: influxdb
Ensuite, Grafana, et n'oubliez pas de modifier les paramètres du service pour activer l'équilibreur de charge MetaLB et obtenir l'adresse IP externe pour le service Grafana.
control# vi grafana.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-grafana namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: grafana spec: containers: - name: grafana image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4 ports: - containerPort: 3000 protocol: TCP volumeMounts: - mountPath: /etc/ssl/certs name: ca-certificates readOnly: true - mountPath: /var name: grafana-storage env: - name: INFLUXDB_HOST value: monitoring-influxdb - name: GF_SERVER_HTTP_PORT value: "3000" # The following env variables are required to make Grafana accessible via # the kubernetes api-server proxy. On production clusters, we recommend # removing these env variables, setup auth for grafana, and expose the grafana # service using a LoadBalancer or a public IP. - name: GF_AUTH_BASIC_ENABLED value: "false" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin - name: GF_SERVER_ROOT_URL # If you're only using the API Server proxy, set this value instead: # value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy value: / volumes: - name: ca-certificates hostPath: path: /etc/ssl/certs - name: grafana-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-grafana name: monitoring-grafana namespace: kube-system spec: # In a production setup, we recommend accessing Grafana through an external Loadbalancer # or through a public IP. # type: LoadBalancer # You could also use NodePort to expose the service at a randomly-generated port # type: NodePort type: LoadBalancer ports: - port: 80 targetPort: 3000 selector: k8s-app: grafana
Et créez-les:
control# kubectl create -f influxdb.yaml deployment.extensions/monitoring-influxdb created service/monitoring-influxdb created control# kubectl create -f grafana.yaml deployment.extensions/monitoring-grafana created service/monitoring-grafana created
Il est temps de changer le déploiement du tas et d'y ajouter la connexion InfluxDB; vous devez ajouter une seule ligne:
- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
Modifiez le déploiement du tas:
control# kubectl get deployments --namespace=kube-system NAME READY UP-TO-DATE AVAILABLE AGE coredns 2/2 2 2 49d heapster 1/1 1 1 2d12h kubernetes-dashboard 1/1 1 1 3d21h monitoring-grafana 1/1 1 1 115s monitoring-influxdb 1/1 1 1 2m18s control# kubectl edit deployment heapster --namespace=kube-system ... beginning bla bla bla spec: containers: - command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true - --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086 image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent .... end
Trouvez maintenant l'adresse IP externe du service Grafana et connectez-vous au système à l'intérieur:
control# kubectl get svc --namespace=kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ..... some other services here monitoring-grafana LoadBalancer 10.98.111.200 192.168.0.241 80:32148/TCP 18m
Ouvrez http://192.168.0.241 dans un navigateur, pour la première fois utilisez les informations d'identification admin / admin:

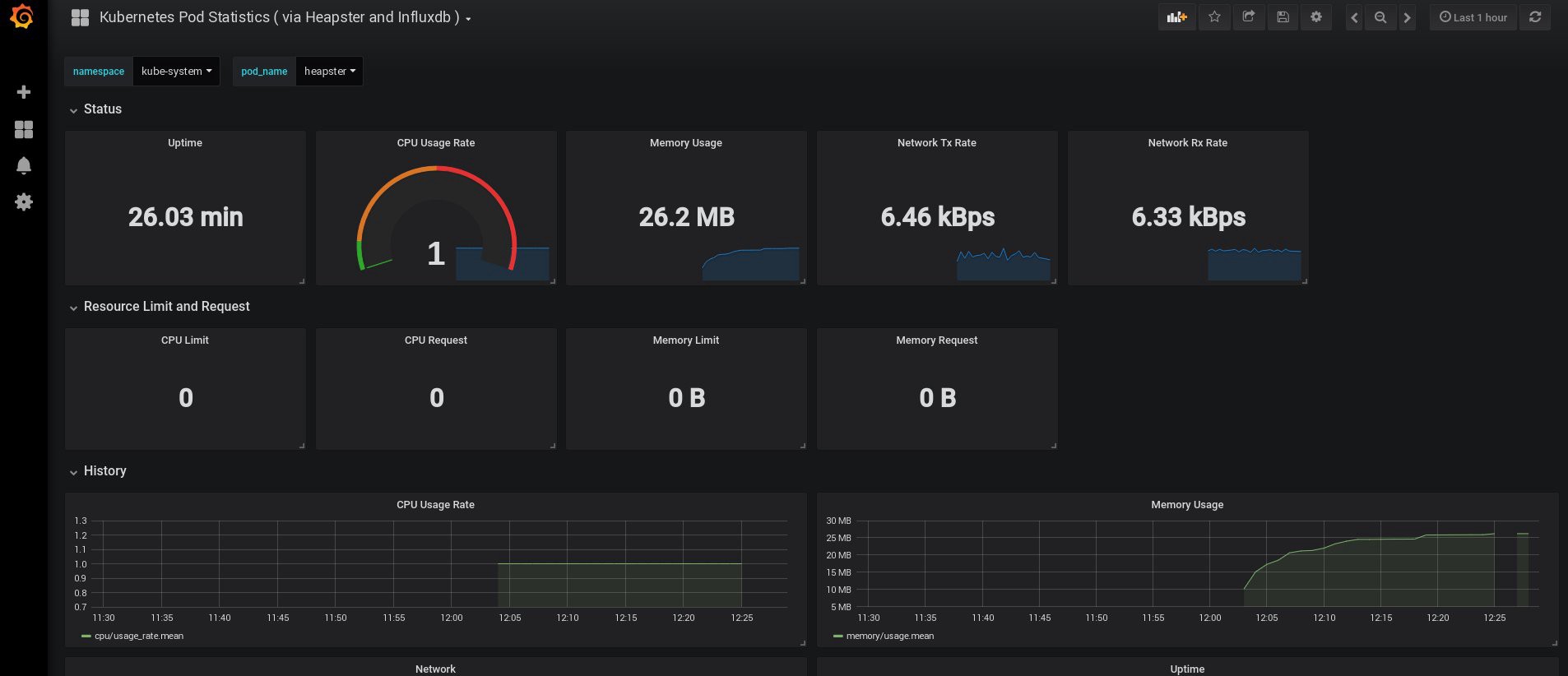
Lorsque je me suis connecté, mon Grafana était vide, mais, heureusement, nous pouvons obtenir tous les tableaux de bord nécessaires sur grafana.com . Vous devez importer les panneaux n ° 3649 et 3646. Lors de l'importation, sélectionnez la source de données appropriée.
Après cela, surveillez l'utilisation des ressources des nœuds et des foyers et, bien sûr, créez vos propres tableaux de bord uniques.
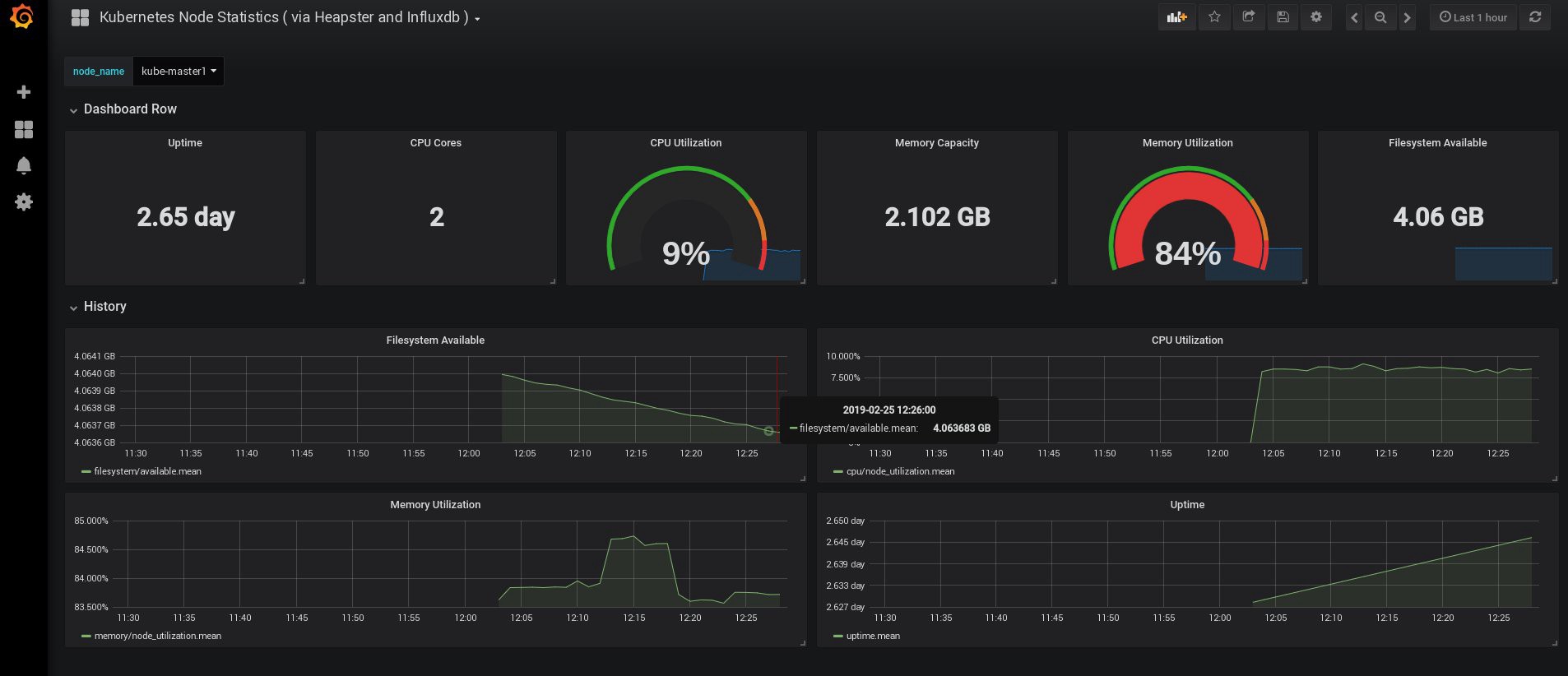
Eh bien, pour l'instant, terminons avec la surveillance; Les éléments suivants dont nous pourrions avoir besoin sont les journaux pour stocker nos applications et le cluster. Il existe plusieurs façons de l'implémenter, et elles sont toutes décrites dans la documentation de Kubernetes. Sur la base de ma propre expérience, je préfère utiliser des installations externes des services Elasticsearch et Kibana, ainsi que des agents d'enregistrement qui s'exécutent sur chaque nœud de travail Kubernetes. Cela protégera le cluster des surcharges associées à un grand nombre de journaux et autres problèmes, et permettra de recevoir des journaux, même si le cluster devient complètement complètement non fonctionnel.
La pile de collecte de journaux la plus populaire pour les fans de Kubernetes est Elasticsearch, Fluentd et Kibana (pile EFK). Dans cet exemple, nous exécuterons Elasticsearch et Kibana sur un nœud externe (vous pouvez utiliser la pile ELK existante), ainsi que Fluentd à l'intérieur de notre cluster en tant que jeu de démons pour chaque nœud en tant qu'agent de collecte de journaux.
Je vais sauter la partie sur la création d'une machine virtuelle avec des installations Elasticsearch et Kibana; C'est un sujet assez populaire, vous pouvez donc trouver beaucoup de matériel sur la meilleure façon de le faire. Par exemple, dans mon article . Supprimez simplement le fragment de configuration logstash du fichier docker-compose.yml et supprimez également 127.0.0.1 de la section des ports elasticsearch.
Après cela, vous devriez avoir un elasticsearch fonctionnel connecté au port VM-IP: 9200. Pour plus de sécurité, configurez login: pass ou clés de sécurité entre fluentd et elasticsearch. Cependant, je les protège souvent simplement avec des règles iptables.
Il ne reste plus qu'à créer un daemonset fluentd dans Kubernetes et à spécifier l'adresse externe du noeud elasticsearch : port dans la configuration.
Nous utilisons l'add-on Kubernetes officiel avec la configuration yaml d'ici , avec des modifications mineures:
control# vi fluentd-es-ds.yaml apiVersion: v1 kind: ServiceAccount metadata: name: fluentd-es namespace: kube-system labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "namespaces" - "pods" verbs: - "get" - "watch" - "list" --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: fluentd-es namespace: kube-system apiGroup: "" roleRef: kind: ClusterRole name: fluentd-es apiGroup: "" --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-es-v2.4.0 namespace: kube-system labels: k8s-app: fluentd-es version: v2.4.0 kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: selector: matchLabels: k8s-app: fluentd-es version: v2.4.0 template: metadata: labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" version: v2.4.0 # This annotation ensures that fluentd does not get evicted if the node # supports critical pod annotation based priority scheme. # Note that this does not guarantee admission on the nodes (#40573). annotations: scheduler.alpha.kubernetes.io/critical-pod: '' seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: priorityClassName: system-node-critical serviceAccountName: fluentd-es containers: - name: fluentd-es image: k8s.gcr.io/fluentd-elasticsearch:v2.4.0 env: - name: FLUENTD_ARGS value: --no-supervisor -q resources: limits: memory: 500Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: config-volume mountPath: /etc/fluent/config.d terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: config-volume configMap: name: fluentd-es-config-v0.2.0
Ensuite, nous allons faire une configuration spécifique de fluentd:
control# vi fluentd-es-configmap.yaml kind: ConfigMap apiVersion: v1 metadata: name: fluentd-es-config-v0.2.0 namespace: kube-system labels: addonmanager.kubernetes.io/mode: Reconcile data: system.conf: |- <system> root_dir /tmp/fluentd-buffers/ </system> containers.input.conf: |-
@id fluentd-containers.log @type tail path /var/log/containers/*.log pos_file /var/log/es-containers.log.pos tag raw.kubernetes.* read_from_head true <parse> @type multi_format <pattern> format json time_key time time_format %Y-%m-%dT%H:%M:%S.%NZ </pattern> <pattern> format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ time_format %Y-%m-%dT%H:%M:%S.%N%:z </pattern> </parse>
# Detect exceptions in the log output and forward them as one log entry. <match raw.kubernetes.**> @id raw.kubernetes @type detect_exceptions remove_tag_prefix raw message log stream stream multiline_flush_interval 5 max_bytes 500000 max_lines 1000 </match> # Concatenate multi-line logs <filter **> @id filter_concat @type concat key message multiline_end_regexp /\n$/ separator "" </filter> # Enriches records with Kubernetes metadata <filter kubernetes.**> @id filter_kubernetes_metadata @type kubernetes_metadata </filter> # Fixes json fields in Elasticsearch <filter kubernetes.**> @id filter_parser @type parser key_name log reserve_data true remove_key_name_field true <parse> @type multi_format <pattern> format json </pattern> <pattern> format none </pattern> </parse> </filter> output.conf: |- <match **> @id elasticsearch @type elasticsearch @log_level info type_name _doc include_tag_key true host 192.168.1.253 port 9200 logstash_format true <buffer> @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size 2M queue_limit_length 8 overflow_action block </buffer> </match>
La configuration est élémentaire, mais elle suffit amplement pour un démarrage rapide; il collectera les journaux du système et des applications. Si vous avez besoin de quelque chose de plus compliqué, vous pouvez consulter la documentation officielle sur les plugins fluentd et les configurations Kubernetes.
Créons maintenant un daemonset fluentd dans notre cluster:
control# kubectl create -f fluentd-es-ds.yaml serviceaccount/fluentd-es created clusterrole.rbac.authorization.k8s.io/fluentd-es created clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created daemonset.apps/fluentd-es-v2.4.0 created control# kubectl create -f fluentd-es-configmap.yaml configmap/fluentd-es-config-v0.2.0 created
Assurez-vous que tous les pods fluentd et autres ressources fonctionnent correctement, puis ouvrez Kibana. Dans Kibana, recherchez et ajoutez un nouvel index de fluentd. Si vous trouvez quelque chose, alors tout est fait correctement, sinon, vérifiez les étapes précédentes et recréez le daemonset ou éditez le configmap:

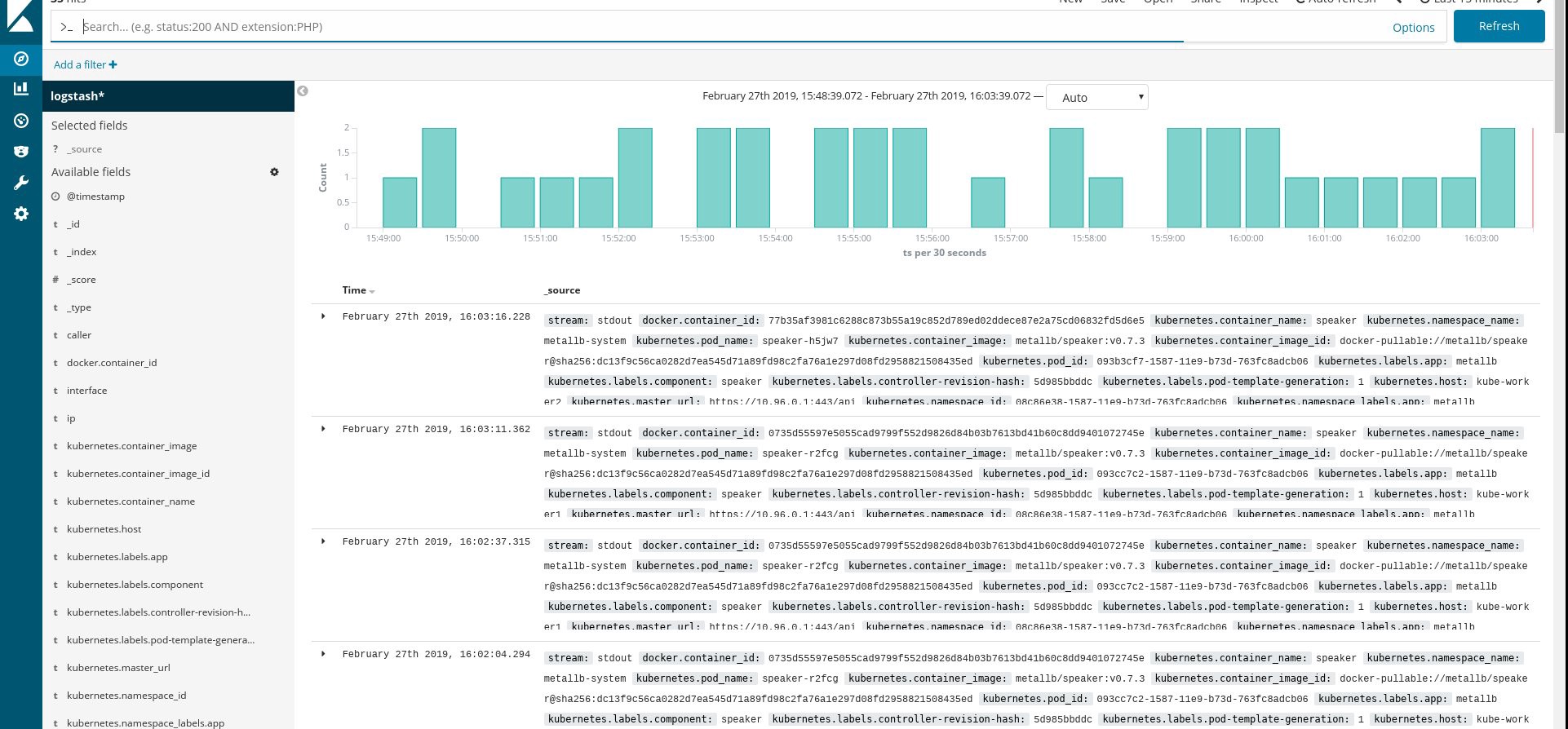
Eh bien, maintenant que nous obtenons les journaux du cluster, vous pouvez créer des tableaux de bord. Bien sûr, la configuration est la plus simple, vous devez donc probablement la modifier par vous-même. L'objectif principal était de montrer comment cela se fait.
Après avoir terminé toutes les étapes précédentes, nous avons obtenu un très bon cluster Kubernetes prêt à l'emploi. Il est temps d'intégrer une application de test et de voir ce qui se passe.
Pour cet exemple, prenez ma petite application Python / Flask Kubyk, qui possède déjà un conteneur Docker, alors prenez-la dans le registre ouvert Docker. Nous allons maintenant ajouter un fichier de base de données externe à cette application - pour cela, nous utiliserons le stockage GlusterFS configuré.
Tout d'abord, nous créons un nouveau volume pvc pour cette application (demande de volume permanent), où nous allons stocker la base de données SQLite avec les informations d'identification de l'utilisateur. Vous pouvez utiliser la classe de mémoire pré-créée de la partie 2 de ce guide.
control# mkdir kubyk && cd kubyk control# vi kubyk-pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: kubyk annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi control# kubectl create -f kubyk-pvc.yaml
Ayant créé un nouveau PVC pour l'application, nous sommes prêts pour le déploiement.
control# vi kubyk-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: kubyk-deployment spec: selector: matchLabels: app: kubyk replicas: 1 template: metadata: labels: app: kubyk spec: containers: - name: kubyk image: ratibor78/kubyk ports: - containerPort: 80 volumeMounts: - name: kubyk-db mountPath: /kubyk/sqlite volumes: - name: kubyk-db persistentVolumeClaim: claimName: kubyk control# vi kubyk-service.yaml apiVersion: v1 kind: Service metadata: name: kubyk spec: type: LoadBalancer selector: app: kubyk ports: - port: 80 name: http
Créons maintenant un déploiement et un service:
control# kubectl create -f kubyk-deploy.yaml deployment.apps/kubyk-deployment created control# kubectl create -f kubyk-service.yaml service/kubyk created
Vérifiez la nouvelle adresse IP attribuée au service, ainsi que le statut du sous:
control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d1h glusterfs-5dtdj 1/1 Running 1 41d glusterfs-zqxwt 1/1 Running 0 2d1h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 11s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ... some text.. kubyk LoadBalancer 10.109.105.224 192.168.0.242 80:32384/TCP 10s
Il semble donc que nous ayons lancé avec succès une nouvelle application; si nous ouvrons l'adresse IP http://192.168.0.242 dans le navigateur, nous devrions voir la page de connexion de cette application. Vous pouvez utiliser les informations d'identification admin / admin pour vous connecter, mais si nous essayons de nous connecter à ce stade, nous obtiendrons une erreur car aucune base de données n'est encore disponible.
Voici un exemple de message d'erreur de journal du foyer dans le tableau de bord Kubernetes:
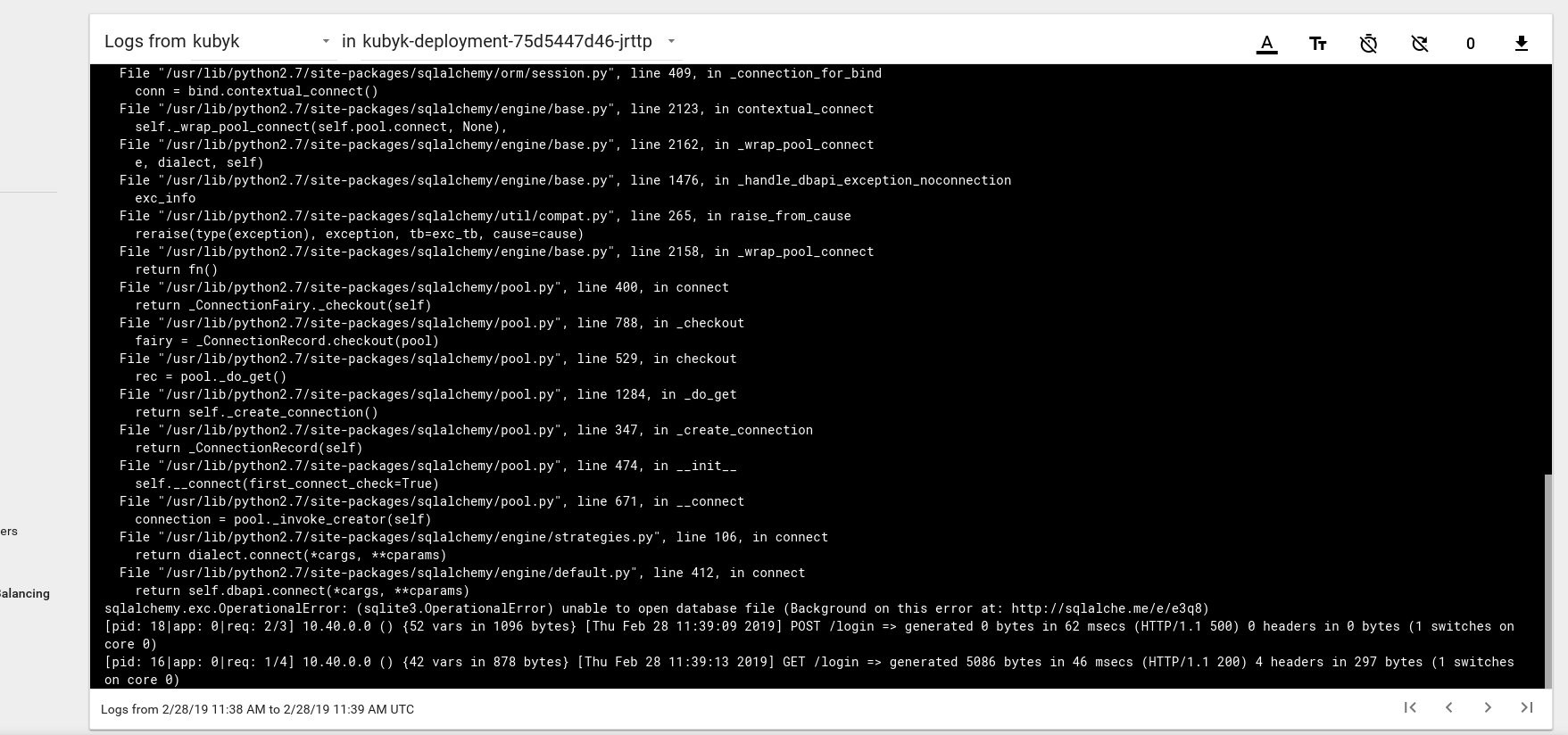
Pour résoudre ce problème, vous devez copier le fichier DB SQlite de mon référentiel git vers le volume pvc précédemment créé. L'application commencera à utiliser cette base de données.
control# git pull https://github.com/ratibor78/kubyk.git control# kubectl cp ./kubyk/sqlite/database.db kubyk-deployment-75d5447d46-jrttp:/kubyk/sqlite
Nous utilisons le sous de l'application et la commande kubectl cp pour copier ce fichier sur le volume.
Vous devez également donner à l'utilisateur nginx un accès en écriture à ce répertoire; mon application est lancée via l'utilisateur nginx à l'aide de supervisord .
control# kubectl exec -ti kubyk-deployment-75d5447d46-jrttp -- chown -R nginx:nginx /kubyk/sqlite/
Essayons de nous reconnecter:
Très bien, maintenant notre application fonctionne correctement, et nous pouvons faire évoluer le déploiement de kubyk sur 3 répliques, par exemple, pour placer une copie de l'application dans un nœud de travail. Puisque nous avons précédemment créé le volume pvc, tous nos pods avec des répliques d'applications utiliseront la même base de données, et le service répartira ainsi le trafic entre les répliques de manière circulaire.
control# kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE heketi 1/1 1 1 39d kubyk-deployment 1/1 1 1 4h5m control# kubectl scale deployments kubyk-deployment --replicas=3 deployment.extensions/kubyk-deployment scaled control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d5h glusterfs-5dtdj 1/1 Running 21 41d glusterfs-zqxwt 1/1 Running 0 2d5h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-bdnqx 1/1 Running 0 26s kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 4h7m kubyk-deployment-75d5447d46-wz9xz 1/1 Running 0 26s
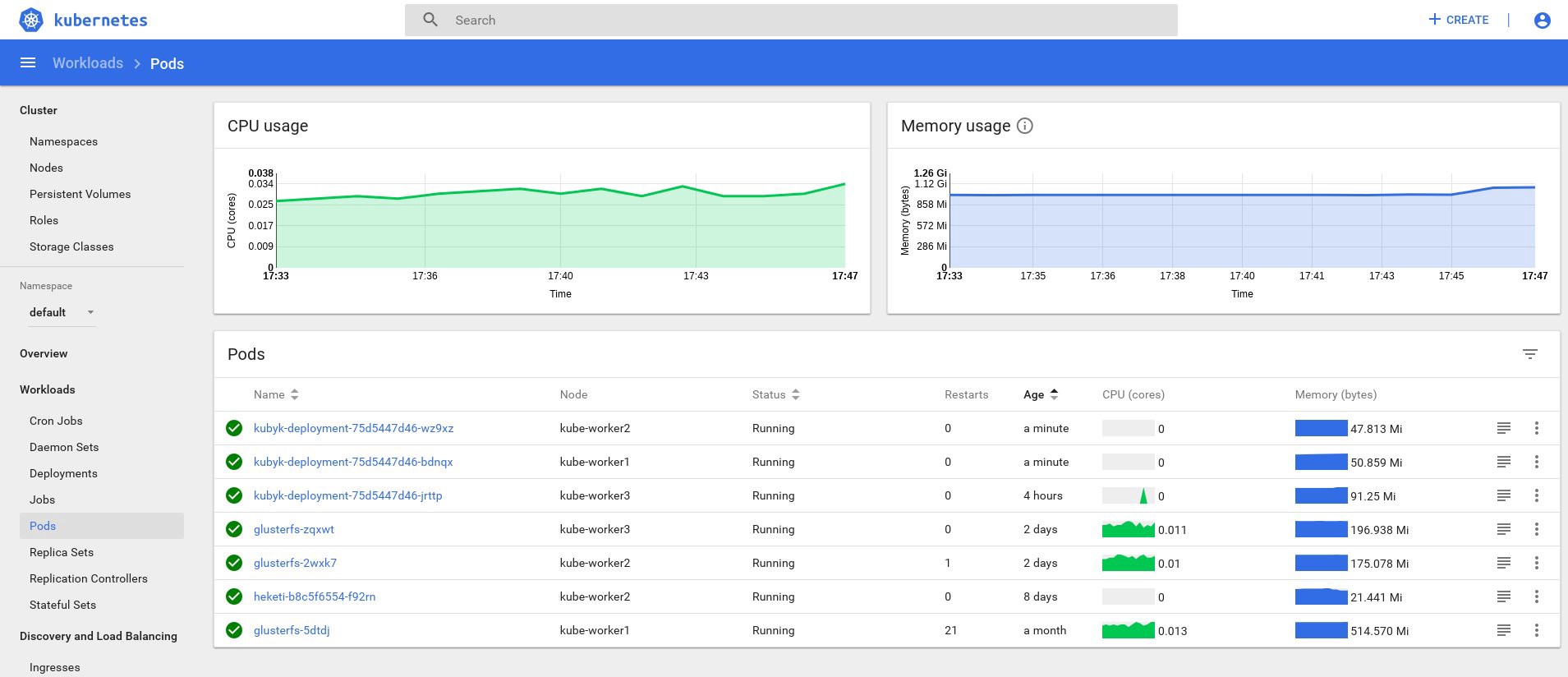
Nous avons maintenant des répliques d'application pour chaque nœud actif, de sorte que l'application ne cessera pas de fonctionner si elle perd des nœuds. De plus, nous obtenons un moyen simple d'équilibrer la charge, comme je l'ai dit plus tôt. Pas un mauvais endroit pour commencer.
Créons un nouvel utilisateur dans notre application:
Toutes les nouvelles demandes seront traitées par le prochain foyer de la liste. Cela peut être vérifié par les journaux des foyers. Par exemple, un nouvel utilisateur est créé par l'application dans un sous, puis le sous suivant répond à la requête suivante, et ainsi de suite. Étant donné que cette application utilise un seul volume persistant pour stocker la base de données, toutes les données seront en sécurité même si toutes les réplicas sont perdues.
Dans les applications volumineuses et complexes, vous aurez besoin non seulement d'un volume désigné pour la base de données, mais de divers volumes pour accueillir les informations persistantes et de nombreux autres éléments.
Eh bien, nous avons presque fini. Vous pouvez ajouter beaucoup plus d'aspects, car Kubernetes est un sujet volumineux et dynamique, mais nous nous arrêterons là. L'objectif principal de cette série d'articles était de montrer comment créer votre propre cluster Kubernetes, et j'espère que ces informations vous ont été utiles.
PS
Des tests de stabilité et des tests de résistance, bien sûr.
Le diagramme de cluster de notre exemple fonctionne sans 2 nœuds de travail, 1 nœuds maîtres et 1 nœuds etcd. Si vous le souhaitez, désactivez-les et vérifiez si l'application de test fonctionnera.
En compilant ces guides, j'ai préparé un cluster de production pour un schéma presque similaire. Une fois, après avoir créé un cluster et y avoir déployé une application, j'ai rencontré une panne de courant majeure; absolument tous les serveurs du cluster ont été coupés - un cauchemar animé de l'administrateur système. Certains serveurs se sont arrêtés pendant longtemps, puis des erreurs de système de fichiers se sont produites sur eux. Mais la relance m'a beaucoup surpris: le cluster Kubernetes s'est complètement rétabli. Tous les volumes et déploiements de GlusterFS ont été lancés. Pour moi, c'est une démonstration du grand potentiel de cette technologie.
Bien à vous et, j'espère, à bientôt!