
Le code est utilisé pour créer des interfaces. Mais le code lui-même est une interface.
Malgré le fait que la lisibilité du code est très importante, ce concept est mal défini - et souvent sous la forme d'un ensemble de règles: utilisez des noms de variables significatifs, divisez les grandes fonctions en plus petites et utilisez des modèles de conception standard.
Dans le même temps, bien sûr, tout le monde a dû faire face à un code conforme à ces règles, mais pour une raison quelconque, c'est une sorte de gâchis.
Vous pouvez essayer de résoudre ce problème en ajoutant de nouvelles règles: si les noms de variables deviennent très longs, vous devez refactoriser la logique principale; si de nombreuses méthodes auxiliaires se sont accumulées dans une seule classe, elle devrait peut-être être divisée en deux; Les modèles de conception ne peuvent pas être appliqués dans le mauvais contexte.
De telles instructions se transforment en un labyrinthe de décisions subjectives, et pour y naviguer, vous aurez besoin d'un développeur qui peut faire le bon choix - c'est-à-dire qu'il doit déjà être capable d'écrire du code lisible.
Ainsi, un ensemble d'instructions n'est pas une option. Par conséquent, nous devrons formuler une image plus large de la lisibilité du code.
Pourquoi la lisibilité est nécessaire
En pratique, une bonne lisibilité signifie généralement que le code est agréable à lire. Cependant, on ne peut pas aller loin sur une telle définition: premièrement, elle est subjective, et deuxièmement, elle nous oblige à lire un texte ordinaire.
Un code illisible est perçu comme un roman qui prétend être un code: beaucoup de commentaires révélant l'essence de ce qui se passe, des feuilles de texte à lire séquentiellement, des formulations intelligentes dont le seul sens est d'être «intelligent», la peur de réutiliser des mots. Le développeur essaie de rendre le code lisible, mais cible le mauvais type de lecteurs.
La lisibilité du texte et la lisibilité du code ne sont pas la même chose.
Traduit en AlconostLe code est utilisé pour créer des interfaces. Mais le code lui-même est une interface.
Si le code est beau, cela signifie-t-il qu'il est lisible? L'esthétique est un effet secondaire agréable de lisibilité, mais en tant que critère n'est pas très utile. Peut-être que dans des cas extrêmes, l'esthétique du code dans le projet aidera à retenir les employés - mais avec le même succès, vous pouvez offrir un bon package social. De plus, chacun a sa propre idée de ce que signifie «beau code». Et au fil du temps, cette définition de la lisibilité se transforme en un tourbillon de différends concernant la tabulation, les espaces, les crochets, la «notation de chameau», etc.
Si le code produit moins d'erreurs, peut-il être considéré comme plus lisible? Moins il y a d'erreurs, mieux c'est, mais quel mécanisme existe-t-il? Comment attribuer les vagues sensations agréables que vous ressentez lorsque vous lisez le code? De plus, peu importe à quel point les sourcils froncent les sourcils en lisant le code, cela n'ajoutera pas d'erreurs.
Si le code est facile à modifier, est-il lisible? Mais c'est peut-être la bonne direction de la pensée. Les exigences changent, des fonctions sont ajoutées, des erreurs surviennent - et à un moment donné, quelqu'un doit modifier votre code. Et pour ne pas causer de nouveaux problèmes, le développeur doit comprendre exactement ce qu'il modifie et comment les modifications vont changer le comportement du code. Nous avons donc trouvé une nouvelle règle heuristique: le code lisible devrait être facile à modifier.
Quel code est plus facile à modifier?
Je veux immédiatement brouiller: «Le code est plus facile à modifier lorsque les noms des variables sont donnés de manière significative», mais nous renommons simplement «lisibilité» en «facilité d'édition». Nous avons besoin d'une compréhension plus approfondie, et non du même ensemble de règles sous une forme différente.
Commençons par oublier un instant que nous parlons de code. La programmation, vieille de plusieurs décennies, n'est qu'un point à l'échelle de l'histoire humaine. En nous limitant à ce «point», nous ne pouvons pas creuser profondément.
Par conséquent, regardons la lisibilité à travers le prisme de la conception d'interfaces que nous rencontrons à presque toutes les étapes - et pas seulement avec les interfaces numériques. Le jouet a des fonctionnalités qui le font rouler ou grincer. La porte a une interface qui vous permet de l'ouvrir, la fermer et la verrouiller. Les données du livre sont collectées dans des pages, ce qui permet un accès aléatoire plus rapide que le défilement. En étudiant la conception, vous pouvez en apprendre beaucoup plus sur ces interfaces - demandez à l'équipe de conception si vous le pouvez. Dans le cas général, nous préférons tous de bonnes interfaces, même si nous ne savons pas toujours ce qui les rend bonnes.
Le code est utilisé pour créer des interfaces. Mais le code lui-même, combiné avec l'IDE, est une interface. Une interface conçue pour un très petit groupe d'utilisateurs - nos collègues. De plus, nous les appellerons «utilisateurs» - afin de rester dans l'espace de conception de l'interface utilisateur.
Dans cet esprit, considérez ces exemples de chemins utilisateur:
- L'utilisateur souhaite ajouter une nouvelle fonction. Cela nécessite de trouver le bon endroit et d'ajouter une fonction sans générer de nouvelles erreurs.
- L'utilisateur souhaite corriger l'erreur. Il devra trouver la source du problème et modifier le code afin que l'erreur disparaisse et que de nouvelles erreurs n'apparaissent pas.
- L'utilisateur veut s'assurer que dans les cas limites, le code se comporte d'une certaine manière. Il devra trouver un morceau de code spécifique, puis retracer la logique et simuler ce qui se passe.
Et ainsi de suite: la plupart des chemins suivent un schéma similaire. Afin de ne pas compliquer les choses, considérez des exemples spécifiques - mais n'oubliez pas qu'il s'agit d'une recherche de principes généraux, pas d'une liste de règles.
Nous pouvons supposer en toute confiance que l'utilisateur ne sera pas en mesure d'ouvrir immédiatement la section de code souhaitée. Cela s'applique également à vos propres projets de loisirs: même si la fonction est écrite par vous, il est très facile d'oublier où elle se trouve. Par conséquent, le code doit être tel qu'il soit facile de trouver celui qui convient.
Pour mettre en œuvre une recherche pratique, vous aurez besoin d'une optimisation des moteurs de recherche - ici, c'est à nous que les noms de variables significatifs viennent à la rescousse. Si l'utilisateur ne trouve pas la fonction, se déplaçant le long de la pile d'appels à partir d'un point connu, il peut lancer une recherche par mots clés. Cependant, vous ne pouvez pas inclure trop de mots clés dans les noms. Lors de la recherche par code, le seul point d'entrée est recherché, d'où vous pouvez continuer à travailler davantage. Par conséquent, l'utilisateur doit aider à se rendre à un endroit spécifique, et si vous en faites trop avec des mots clés, il y aura trop de résultats de recherche inutiles.
Si l'utilisateur est en mesure de vérifier immédiatement que tout est correct à un niveau de logique particulier, il peut oublier les couches d'abstraction précédentes et libérer son esprit pour la suivante.
Vous pouvez également effectuer une recherche à l'aide de la saisie semi-automatique: si vous avez une idée générale de la fonction que vous souhaitez appeler ou de l'énumération à utiliser, vous pouvez commencer à taper le nom voulu, puis sélectionner l'option appropriée dans la liste de saisie semi-automatique. Si la fonction est destinée uniquement à certains cas ou si vous devez lire attentivement son implémentation en raison des caractéristiques de son utilisation, vous pouvez l'indiquer en lui donnant un nom plus authentique: en faisant défiler la liste de saisie semi-automatique, l'utilisateur évitera plutôt ce qui semble compliqué - à moins, bien sûr, qu'il soit sûr qu'est-ce que.
Par conséquent, les noms réguliers courts sont plus susceptibles d'être perçus comme des options par défaut, adaptées aux utilisateurs "occasionnels". Il ne devrait pas y avoir de surprise dans les fonctions avec de tels noms: vous ne pouvez pas insérer de setters dans des fonctions qui ressemblent à de simples getters, pour la même raison que le bouton Afficher dans l'interface ne devrait pas changer les données utilisateur.

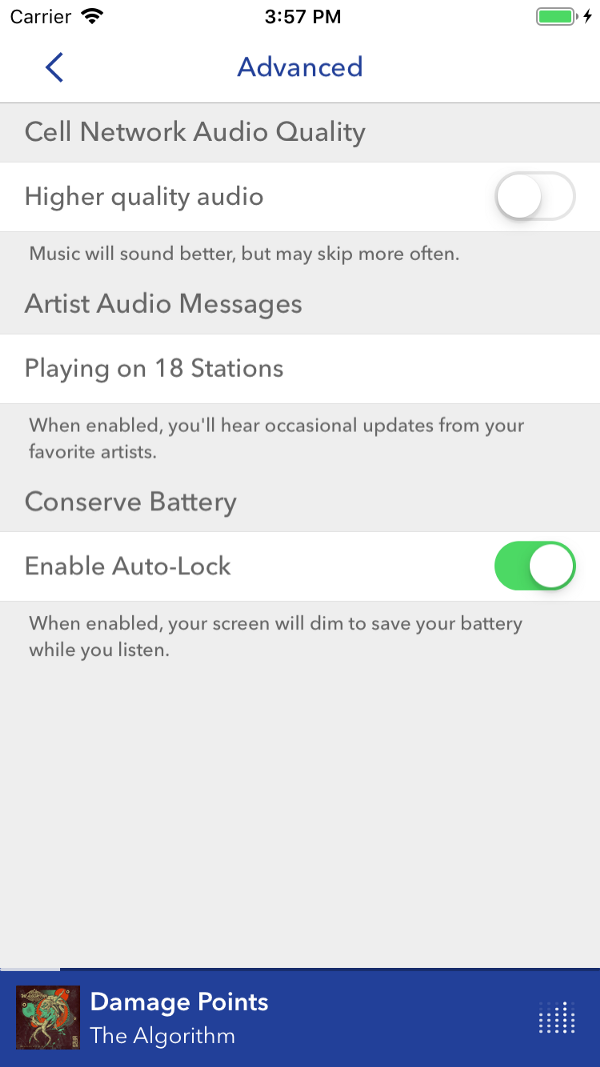 Dans l'interface orientée client, les fonctions familières, telles qu'une pause, se passent presque sans texte. À mesure que la fonctionnalité devient plus complexe, les noms s'allongent, ce qui fait ralentir et réfléchir les utilisateurs. Capture d'écran - Pandora
Dans l'interface orientée client, les fonctions familières, telles qu'une pause, se passent presque sans texte. À mesure que la fonctionnalité devient plus complexe, les noms s'allongent, ce qui fait ralentir et réfléchir les utilisateurs. Capture d'écran - PandoraLes utilisateurs veulent trouver rapidement les bonnes informations. Dans la plupart des cas, la compilation prend beaucoup de temps et, dans une application en cours d'exécution, vous devrez vérifier manuellement de nombreux cas de bordure différents. Si possible, nos utilisateurs préfèrent lire le code et comprendre comment il se comporte, plutôt que de définir des points d'arrêt et d'exécuter le code.
Pour ne pas exécuter le code, deux conditions doivent être remplies:
- L'utilisateur comprend ce que le code essaie de faire.
- L'utilisateur est sûr que le code fait ce qu'il prétend.
Les abstractions aident à satisfaire la première condition: les utilisateurs doivent pouvoir plonger dans des couches d'abstraction au niveau de détail souhaité. Imaginez une interface utilisateur hiérarchique: aux premiers niveaux, la navigation s'effectue sur des sections étendues, puis de plus en plus concrétisées - au niveau de la logique qui doit être étudiée plus en détail.
La lecture séquentielle d'un fichier ou d'une méthode s'effectue en temps linéaire. Mais si l'utilisateur peut monter et descendre les piles d'appels - c'est une recherche dans l'arborescence, et si la hiérarchie est bien équilibrée, cette action est effectuée dans un temps logarithmique. Il y a certainement de la place pour les listes dans les interfaces, mais vous devez soigneusement examiner s'il doit y avoir plus de deux ou trois appels de méthode dans un certain contexte.
 Dans les menus courts, la navigation hiérarchique est beaucoup plus rapide. Dans le menu "long" à droite - seulement 11 lignes. À quelle fréquence correspondons-nous à ce nombre dans le code de la méthode? Capture d'écran - Pandora
Dans les menus courts, la navigation hiérarchique est beaucoup plus rapide. Dans le menu "long" à droite - seulement 11 lignes. À quelle fréquence correspondons-nous à ce nombre dans le code de la méthode? Capture d'écran - PandoraDifférents utilisateurs ont des stratégies différentes pour la deuxième condition. Dans les situations à faible risque, les commentaires ou les noms de méthode sont des preuves suffisantes. Dans des domaines plus risqués et complexes, ainsi que lorsque le code est surchargé de commentaires non pertinents, ces derniers sont susceptibles d'être ignorés. Parfois, même les noms des méthodes et des variables seront mis en doute. Dans de tels cas, l'utilisateur doit lire beaucoup plus de code et garder à l'esprit un modèle logique plus large. Limiter le contexte à de petites zones faciles à conserver aidera également ici. Si l'utilisateur est en mesure de vérifier immédiatement que tout est correct à un niveau de logique particulier, il peut oublier les couches d'abstraction précédentes et libérer son esprit pour la suivante.
Dans ce mode de fonctionnement, les jetons individuels commencent à avoir une plus grande importance. Par exemple, un drapeau booléen
element.visible = true/false
il est facile à comprendre indépendamment du reste du code, mais cela nécessite de combiner deux jetons différents dans l'esprit. Si utiliser
element.visibility = .visible/.hidden
alors la valeur de l'indicateur peut être comprise tout de suite: dans ce cas, vous n'avez pas besoin de lire le nom de la variable pour découvrir qu'il est lié à la visibilité. ¹ Nous avons vu des approches similaires dans la conception d'interfaces orientées client. Au cours des dernières décennies, les boutons OK et Annuler se sont transformés en éléments d'interface plus descriptifs: enregistrer et annuler, envoyer et continuer la modification, etc., pour comprendre ce qui sera fait, il suffit que l'utilisateur regarde les options proposées sans lire tout le contexte.
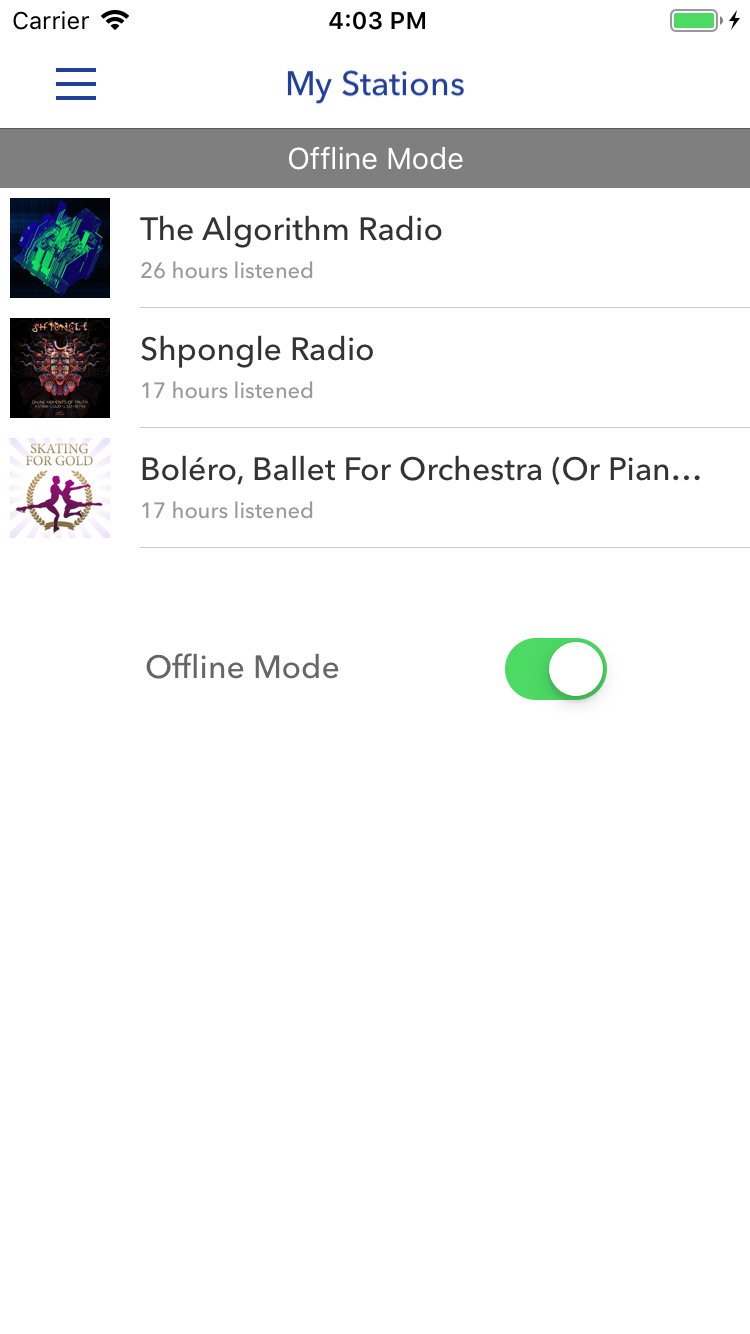 La ligne «Mode hors ligne» dans l'exemple ci-dessus indique que l'application est hors ligne. Le commutateur dans l'exemple ci-dessous a la même signification, mais pour le comprendre, vous devez regarder le contexte. Capture d'écran - Pandora
La ligne «Mode hors ligne» dans l'exemple ci-dessus indique que l'application est hors ligne. Le commutateur dans l'exemple ci-dessous a la même signification, mais pour le comprendre, vous devez regarder le contexte. Capture d'écran - PandoraLes tests unitaires aident également à confirmer le comportement attendu du code: ils agissent comme des commentaires - qui, cependant, peuvent être plus fiables, car ils sont plus pertinents. Certes, ils doivent également terminer l'assemblage. Mais dans le cas d'un pipeline CI bien établi, les tests sont exécutés régulièrement, vous pouvez donc ignorer cette étape lorsque vous apportez des modifications au code existant.
En théorie, la sécurité découle d'une compréhension suffisante: dès que notre utilisateur comprend le comportement du code, il pourra apporter des modifications en toute sécurité. Dans la pratique, vous devez considérer que les développeurs sont des gens ordinaires: notre cerveau utilise les mêmes astuces et est également paresseux. Par conséquent, moins vous aurez besoin d'efforts pour comprendre le code, plus nos actions seront sûres.
Le code lisible doit passer la plupart des vérifications d'erreurs à l'ordinateur. L'une des façons de procéder consiste à utiliser les vérifications de débogage "assert", mais elles nécessitent également l'assemblage et le démarrage. Pire encore, si l'utilisateur a oublié les cas limites, assert n'aidera pas. Les tests unitaires pour vérifier les cas de frontière souvent oubliés peuvent faire mieux, mais une fois que l'utilisateur a apporté des modifications, vous devrez attendre que les tests s'exécutent.
En résumé: le code lisible doit être facile à utiliser. Et - comme effet secondaire - il peut être magnifique.
Pour accélérer le cycle de développement, nous utilisons la fonction de vérification des erreurs intégrée au compilateur. Habituellement, dans de tels cas, un assemblage complet n'est pas requis et les erreurs sont affichées en temps réel. Comment profiter de cette opportunité? De manière générale, vous devez trouver des situations où les vérifications du compilateur deviennent très strictes. Par exemple, la plupart des compilateurs ne regardent pas à quel point l'instruction "if" est décrite, mais vérifient soigneusement le "commutateur" pour les conditions manquantes. Si un utilisateur essaie d'ajouter ou de modifier une condition, il sera plus sûr que tous les opérateurs similaires précédents soient complets. Et lorsque la condition «case» change, le compilateur marque toutes les autres conditions qui doivent être vérifiées.
Un autre problème de lisibilité courant est l'utilisation de primitives dans les expressions conditionnelles. Ce problème est particulièrement aigu lorsque l'application analyse JSON, car vous souhaitez simplement ajouter des instructions «if» autour de l'égalité de chaîne ou d'entier. Cela augmente non seulement la probabilité de fautes de frappe, mais complique également la tâche des utilisateurs de déterminer les valeurs possibles. Lors de la vérification des cas limites, il y a une grande différence entre quand une ligne est possible et quand - seulement deux ou trois options distinctes. Même si les primitives sont fixées dans des constantes, vous devez vous dépêcher une fois, en essayant de terminer le projet à temps, et une valeur arbitraire apparaîtra. Mais si vous utilisez des objets ou des énumérations spécialement créés, le compilateur bloque les arguments non valides et donne une liste spécifique d'arguments valides.
De même, si certaines combinaisons d'indicateurs booléens ne sont pas autorisées, remplacez-les par une seule énumération. Prenons, par exemple, une composition qui peut être dans les états suivants: elle est mise en mémoire tampon, entièrement chargée et jouée. Si vous imaginez les états de chargement et de lecture comme deux drapeaux booléens
(loaded, playing)
le compilateur permettra l'entrée de valeurs invalides
(loaded: false, playing: true)
Et si vous utilisez l'énumération
(.buffering/.loaded/.playing)
il sera alors impossible d'indiquer un état invalide. Dans l'interface orientée client, la valeur par défaut doit être d'interdire les combinaisons de paramètres non valides. Mais lorsque nous écrivons du code à l'intérieur de l'application, nous oublions souvent de nous offrir la même protection.
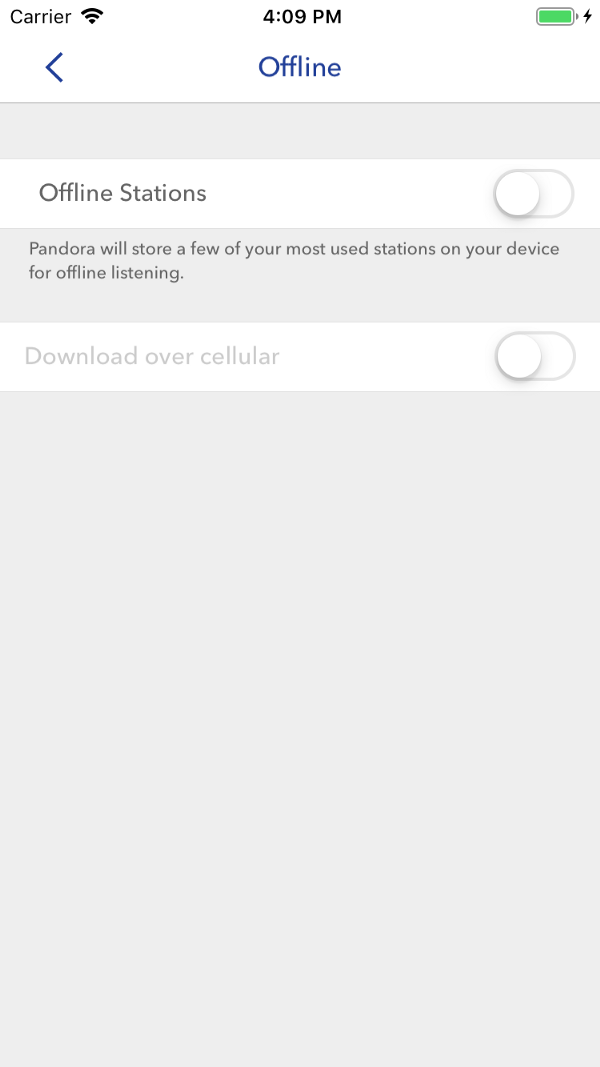
 Les combinaisons non valides sont désactivées à l'avance; les utilisateurs n'ont pas besoin de penser aux configurations incompatibles. Capture d'écran - Apple
Les combinaisons non valides sont désactivées à l'avance; les utilisateurs n'ont pas besoin de penser aux configurations incompatibles. Capture d'écran - AppleEn suivant les chemins utilisateur considérés, nous sommes arrivés aux mêmes règles qu'au début. Mais maintenant, nous avons un principe selon lequel ils peuvent être formulés indépendamment et modifiés en fonction de la situation. Pour ce faire, nous nous demandons:
- Sera-t-il facile pour l'utilisateur de rechercher le morceau de code souhaité? Les résultats de la recherche seront-ils encombrés de fonctions non liées à la requête?
- Un utilisateur, ayant trouvé le code nécessaire, peut-il rapidement vérifier l'exactitude de son comportement?
- L'environnement de développement permet-il une édition sécurisée et une réutilisation du code?
En résumé: le code lisible doit être facile à utiliser. Et - comme effet secondaire - il peut être magnifique.
Remarque
- Il peut sembler que les variables booléennes sont plus pratiques à réutiliser, mais cette option de réutilisation implique l'interchangeabilité. Prenons, par exemple, les indicateurs captables et mis en cache , qui représentent des concepts situés sur des plans complètement différents: la possibilité de cliquer sur un élément et l'état de mise en cache. Mais si les deux indicateurs sont booléens, vous pouvez les échanger accidentellement, obtenant une expression non triviale dans une ligne de code, ce qui signifie que la mise en cache est associée à la possibilité de cliquer sur un élément. Lors de l'utilisation d'énumérations, afin de former de telles relations, nous serons obligés de créer une logique explicite et vérifiable pour la conversion des «unités de mesure» que nous utilisons.
À propos du traducteurL'article a été traduit par Alconost.
Alconost
localise des jeux , des
applications et des sites dans 70 langues. Traducteurs en langue maternelle, tests linguistiques, plateforme cloud avec API, localisation continue, chefs de projet 24/7, tout format de ressources de chaîne.
Nous réalisons également
des vidéos de publicité et de formation - pour les sites qui vendent, présentent des images, de la publicité, des formations, des teasers, des explicateurs, des bandes-annonces pour Google Play et l'App Store.
→
En savoir plus