Les réseaux de neurones convolutifs font un excellent travail de classification des images déformées, contrairement aux humains.

Dans cet article, je montrerai pourquoi les réseaux de neurones profonds avancés peuvent parfaitement reconnaître les images déformées et comment cela aide à révéler la stratégie étonnamment simple utilisée par les réseaux de neurones pour classer les photographies naturelles. Ces découvertes,
publiées dans ICLR 2019, ont de nombreuses conséquences: premièrement, elles démontrent qu'il est beaucoup plus facile de trouver une solution «
ImageNet » qu'on ne le pensait. Deuxièmement, ils nous aident à créer des systèmes de classification d'images plus interprétables et compréhensibles. Troisièmement, ils expliquent plusieurs phénomènes observés dans les réseaux neuronaux convolutionnels modernes (SNS), par exemple, leur tendance à rechercher des textures (voir nos autres
travaux dans ICLR 2019 et l'
entrée de blog correspondante), et ignorant la disposition spatiale de parties de l'objet.
Bons vieux modèles "sac de mots"
Au bon vieux temps, avant l'avènement de l'apprentissage en profondeur, la reconnaissance des images naturelles était assez simple: nous définissons un ensemble de caractéristiques visuelles clés («mots»), déterminons la fréquence à laquelle chaque caractéristique visuelle se produit dans une image («sac») et classifions l'image en fonction de celles-ci. chiffres. Par conséquent, de tels modèles en vision par ordinateur sont appelés le "sac de mots" (sac de mots ou BoW). Par exemple, supposons que nous ayons deux caractéristiques visuelles, l'œil humain et le stylo, et que nous voulons classer les images en deux classes, «personnes» et «oiseaux». Le modèle BoW le plus simple serait le suivant: pour chaque œil trouvé dans l'image, nous augmentons le témoignage en faveur de la «personne» de 1. Et vice versa, pour chaque plume nous augmentons le témoignage en faveur de «l'oiseau» de 1. Quelle classe gagne plus de preuves, ce sera elle.
Une caractéristique pratique d'un modèle BoW aussi simple est l'interprétabilité et la clarté du processus décisionnel: nous pouvons vérifier précisément quelles caractéristiques particulières de l'image parlent en faveur d'une classe particulière, l'intégration spatiale des caractéristiques est très simple (par rapport à l'intégration non linéaire des caractéristiques dans les réseaux de neurones profonds), donc il suffit de comprendre comment le modèle prend ses décisions.
Les modèles BoW traditionnels étaient extrêmement populaires et fonctionnaient très bien avant l'invasion de l'apprentissage en profondeur, mais sont rapidement passés de mode en raison de l'efficacité relativement faible. Mais sommes-nous sûrs que les réseaux de neurones utilisent une stratégie de décision fondamentalement différente de BoW?
Réseau interprété en profondeur avec fonctionnalités Bag (BagNet)
Pour tester cette hypothèse, nous combinons l'interprétabilité et la clarté des modèles BoW avec l'efficacité des réseaux de neurones. La stratégie ressemble à ceci:
- Divisez l'image en petits morceaux qx q.
- Nous passons les morceaux à travers le réseau neuronal pour obtenir des preuves d'appartenance à la classe (logits) pour chaque morceau.
- Résumez les preuves dans toutes les pièces pour obtenir une solution au niveau de l'image entière.
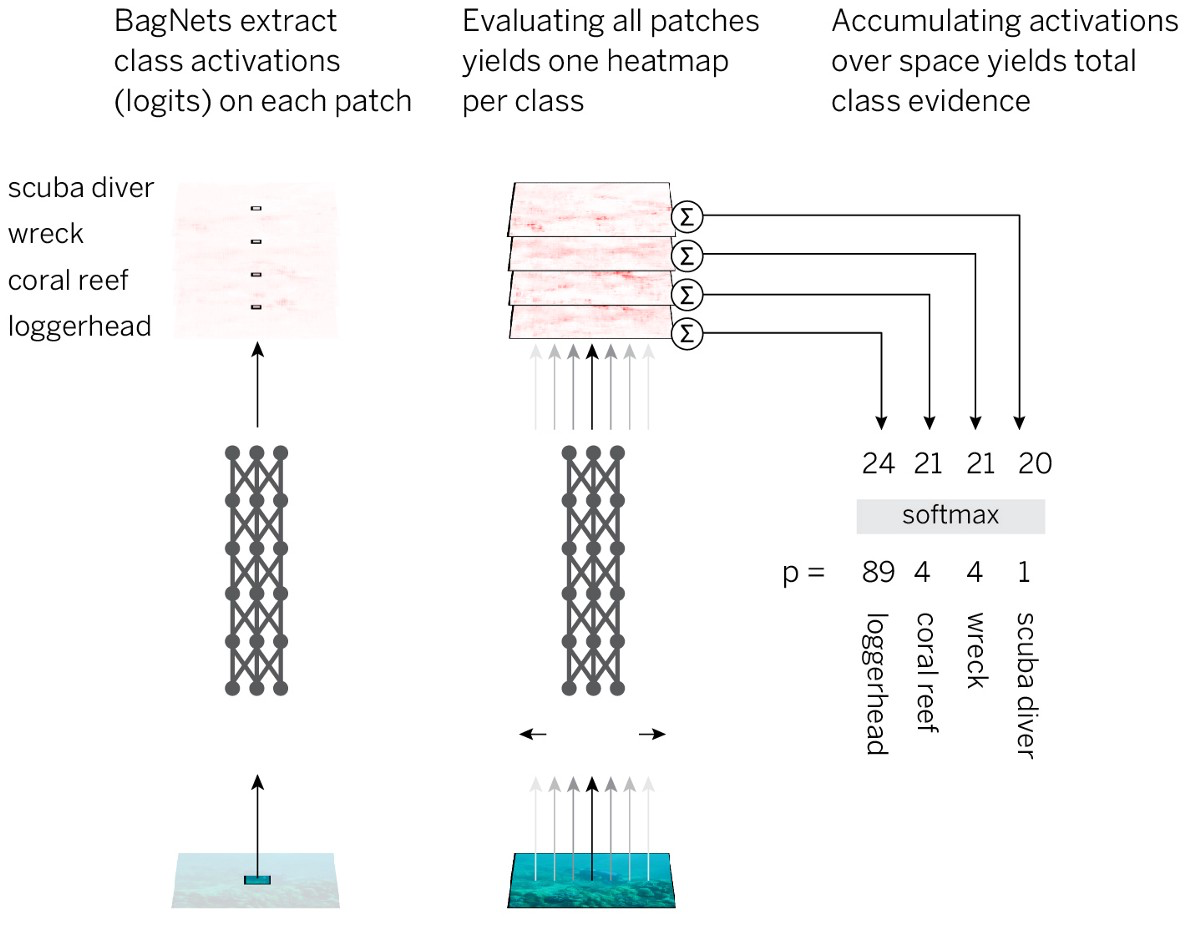
Pour implémenter cette stratégie, de la manière la plus simple, nous prenons l'architecture ResNet-50 standard et remplaçons presque toutes les convolutions 3x3 par des convolutions 1x1. Par conséquent, chaque élément caché dans la dernière couche convolutionnelle «ne voit» qu'une petite partie de l'image (c'est-à-dire que son champ de perception est beaucoup plus petit que la taille de l'image). On évite ainsi le balisage imposé de l'image et au plus près du SNA standard, tout en appliquant une stratégie pré-planifiée. Nous appelons l'architecture résultante BagNet-q, où q désigne la taille du champ de perception de la couche très supérieure (nous avons testé le modèle avec q = 9, 17 et 33). BagNet-q fonctionne environ 2,5 fois plus longtemps que ResNet-50.
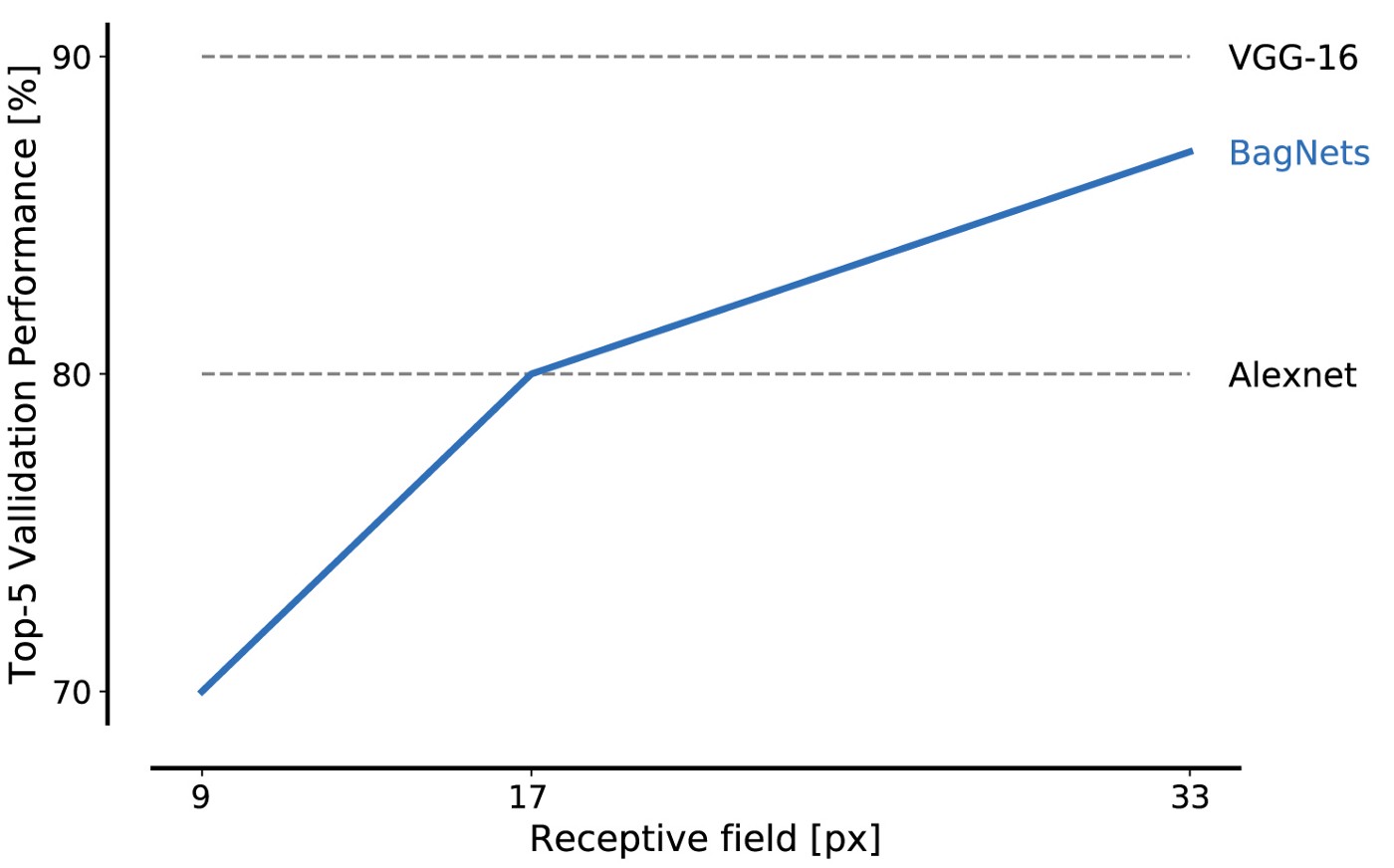
Les performances de BagNet sur les données de la base de données ImageNet sont impressionnantes même lors de l'utilisation de petits morceaux: des fragments de 17x17 pixels suffisent pour atteindre l'efficacité du niveau AlexNet, et des fragments de 33x33 pixels suffisent pour atteindre une précision de 87%, entrant dans le top 5. Vous pouvez augmenter l'efficacité en plaçant les paquets 3x3 plus soigneusement et en ajustant les hyperparamètres.
Ceci est notre premier résultat majeur: ImageNet peut être résolu en utilisant uniquement un ensemble de petites fonctionnalités d'image. Les relations spatiales éloignées des parties de la composition, telles que la forme des objets ou l'interaction entre les parties de l'objet, peuvent être complètement ignorées; ils ne sont absolument pas nécessaires pour résoudre le problème.
Une caractéristique remarquable de BagNet'ov est la transparence de leur système de prise de décision. Par exemple, vous pouvez découvrir quelles caractéristiques des images seront les plus caractéristiques pour une classe donnée. Par exemple, la tanche, un gros poisson, est généralement reconnue par l'image des doigts sur un fond vert. Pourquoi? Parce que sur la plupart des photos de cette catégorie, il y a un pêcheur tenant une tanche comme trophée. Et lorsque BagNet reconnaît incorrectement l'image comme une ligne, cela se produit généralement car quelque part sur la photo, il y a des doigts sur un fond vert.
 Les parties les plus caractéristiques des images. La rangée du haut dans chaque cellule correspond à la reconnaissance correcte, et celle du bas aux fragments distrayants qui ont conduit à une reconnaissance incorrecte
Les parties les plus caractéristiques des images. La rangée du haut dans chaque cellule correspond à la reconnaissance correcte, et celle du bas aux fragments distrayants qui ont conduit à une reconnaissance incorrecteNous obtenons également la «carte thermique» exacte, qui montre quelles parties de l'image ont contribué à la décision.
 Les cartes thermiques ne sont pas une approximation; elles montrent avec précision la contribution de chaque partie de l'image.
Les cartes thermiques ne sont pas une approximation; elles montrent avec précision la contribution de chaque partie de l'image.BagNet démontre que vous ne pouvez obtenir une grande précision avec ImageNet que sur la base de faibles corrélations statistiques entre les caractéristiques locales des images et la catégorie des objets. Si cela suffit, alors pourquoi les réseaux de neurones ResNet-50 standard apprendraient-ils quelque chose de fondamentalement différent? Pourquoi ResNet-50 devrait-il étudier des relations complexes à grande échelle telles que la forme d'un objet, si l'abondance des caractéristiques locales de l'image est suffisante pour résoudre le problème?
Pour tester l'hypothèse selon laquelle les SNA modernes adhèrent à une stratégie similaire au fonctionnement des réseaux BoW les plus simples, nous avons testé différents réseaux - ResNet, DenseNet et VGG sur les «signes» suivants de BagNet:
- Les solutions sont indépendantes du brassage spatial des caractéristiques de l'image (cela ne peut être vérifié que sur les modèles VGG).
- Les modifications de différentes parties de l'image ne doivent pas dépendre les unes des autres (dans le sens de leur influence sur l'appartenance à la classe).
- Les erreurs commises par le SNA standard et BagNet'ami devraient être similaires.
- SNS standard et BagNet doivent être sensibles aux fonctionnalités similaires.
Dans les quatre expériences, nous avons trouvé des comportements étonnamment similaires du SNS et de BagNet. Par exemple, dans la dernière expérience, nous montrons que BagNet est le plus sensible (si, par exemple, ils se chevauchent) aux mêmes endroits dans les images que le SNA. En fait, les cartes thermiques BagNet (cartes de sensibilité spatiale) prédisent mieux la sensibilité de DenseNet-169 que les cartes thermiques obtenues par des méthodes d'attribution telles que DeepLift (calculant directement les cartes thermiques pour DenseNet-169). Bien sûr, le SNA ne répète pas exactement le comportement de BagNet, mais certaines déviations le démontrent. En particulier, plus les réseaux deviennent profonds, plus les tailles des fonctionnalités sont grandes et plus les dépendances s'étendent. Par conséquent, les réseaux de neurones profonds sont en effet une amélioration par rapport aux modèles BagNet, mais je ne pense pas que la base de leur classification soit en quelque sorte en train de changer.
Aller au-delà de la classification BoW
L'observation de la prise de décision du SCN dans le style des stratégies de BoW peut expliquer certaines des caractéristiques étranges du SCN. Tout d'abord, cela explique pourquoi le SCN est si
lié aux textures . Deuxièmement, pourquoi le SNA n'est pas sensible au
mélange de parties de l'image. Cela peut même expliquer l'existence d'autocollants contradictoires et de perturbations contradictoires: des signaux déroutants peuvent être placés n'importe où dans l'image, et le SNS captera sûrement ce signal, qu'il corresponde au reste de l'image.
En fait, notre travail montre que le SCN, lors de la reconnaissance d'images, utilise beaucoup de lois statistiques faibles et ne procède pas à l'intégration de parties de l'image au niveau des objets, comme le font les gens. Il en va probablement de même pour d'autres tâches et modalités sensorielles.
Nous devons planifier soigneusement nos architectures, nos tâches et nos méthodes de formation pour surmonter la tendance à utiliser de faibles corrélations statistiques. Une approche consiste à traduire la distorsion de la formation SNA de petites fonctionnalités locales à des fonctionnalités plus globales. Une autre consiste à supprimer ou à remplacer les fonctionnalités sur lesquelles le réseau de neurones ne devrait pas s'appuyer, comme nous l'avons fait dans une autre
publication pour l'ICLR 2019, en utilisant le prétraitement par transfert de style pour éliminer la texture d'un objet naturel.
Un des plus gros problèmes reste cependant la classification des images: si les caractéristiques locales sont suffisantes, il n'y a aucune incitation à étudier la véritable "physique" du monde naturel. Nous devons restructurer la tâche de manière à déplacer des modèles pour étudier la nature physique des objets. Pour ce faire, vous devrez probablement aller au-delà de l'enseignement purement observationnel jusqu'aux corrélations des données d'entrée et de sortie afin que les modèles puissent extraire les relations causales.
Ensemble, nos résultats suggèrent que le SCN peut suivre une stratégie de classification extrêmement simple. Le fait qu'une telle découverte puisse être faite en 2019 souligne combien nous comprenons encore peu les caractéristiques internes du travail des réseaux de neurones profonds. Le manque de compréhension ne nous permet pas de développer des modèles et des architectures fondamentalement améliorés qui comblent le fossé entre la perception de l'homme et de la machine. Approfondir notre compréhension nous permettra de découvrir des moyens de réduire cet écart. Cela peut être extrêmement utile: en essayant de déplacer le SNA vers les propriétés physiques des objets, nous avons soudainement atteint une
résistance au bruit au niveau humain. J'attends l'apparition d'un grand nombre d'autres résultats intéressants sur notre chemin vers le développement du SCN, qui comprend vraiment la nature physique et causale de notre monde.