 Publié par Denis Tsyplakov , architecte de solutions, DataArt
Publié par Denis Tsyplakov , architecte de solutions, DataArtAu fil des ans, j'ai constaté que les programmeurs répétaient de temps en temps les mêmes erreurs. Malheureusement, les livres sur les aspects théoriques du développement ne permettent pas de les éviter: les livres n'ont généralement pas de conseils concrets et pratiques. Et je devine même pourquoi ...
La première recommandation qui vient à l'esprit lorsqu'il s'agit, par exemple, de
journalisation ou de conception de classe est très simple: "Ne faites pas de conneries." Mais l'expérience montre que ce n'est certainement pas suffisant. La conception des classes dans ce cas est un bon exemple - un mal de tête éternel qui découle du fait que chacun regarde cette question à sa manière. Par conséquent, j'ai décidé de rassembler des conseils de base dans un article, après quoi vous éviterez un certain nombre de problèmes typiques et, surtout, en sauverez vos collègues. Si certains principes vous semblent banaux (parce qu'ils sont vraiment banaux!) - eh bien, alors ils se sont déjà installés dans votre sous-cortex, et votre équipe peut être félicitée.
Je ferai une réservation, en fait, nous nous concentrerons sur les cours uniquement pour des raisons de simplicité. On peut dire presque la même chose des fonctions ou de tout autre élément constitutif de l'application.
Si l'application fonctionne et exécute la tâche, sa conception est bonne. Ou pas? Dépend de la fonction objective de l'application; ce qui est tout à fait adapté à une application mobile qui doit être présentée une fois sur le salon peut ne pas convenir à la plateforme de trading qu'une banque développe depuis des années. Dans une certaine mesure, le principe
SOLID peut être appelé la réponse à cette question, mais il est trop général - je voudrais des instructions plus spécifiques qui peuvent être mentionnées dans une conversation avec des collègues.
Application cible
Puisqu'il ne peut y avoir de réponse universelle, je propose de restreindre la portée. Supposons que nous écrivons une application métier standard qui accepte les demandes via HTTP ou une autre interface, implémente une logique au-dessus d'eux, puis fait une demande au service suivant de la chaîne ou stocke les données reçues quelque part. Pour simplifier, supposons que nous utilisons le framework Spring IoC, car il est assez courant maintenant et les autres frameworks sont assez similaires. Que dire d'une telle application?
- Le temps que le processeur passe à traiter une demande est important, mais pas critique - une augmentation de 0,1% du temps ne le sera pas.
- Il n'y a pas de téraoctets de mémoire à notre disposition, mais si l'application prend 50 à 100 Ko supplémentaires, ce ne sera pas un désastre.
- Bien sûr, plus l'heure de début est courte, mieux c'est. Mais il n'y a pas de différence fondamentale entre 6 sec et 5,9 sec.
Critères d'optimisation
Qu'est-ce qui est important pour nous dans ce cas?
Le code du projet est susceptible d'être utilisé par l'entreprise pendant plusieurs, voire plus de dix ans.
Le code à différents moments sera modifié par plusieurs développeurs qui ne se connaissent pas.
Il est possible que dans quelques années, les développeurs souhaitent utiliser la nouvelle bibliothèque LibXYZ ou le framework FrABC.
À un moment donné, une partie du code ou le projet entier peut être fusionné avec la base de code d'un autre projet.
Au milieu des gestionnaires, il est généralement admis que ces problèmes sont résolus à l'aide de la documentation. La documentation, bien sûr, est bonne et utile, car elle est tellement géniale lorsque vous commencez à travailler sur un projet que vous avez cinq tickets ouverts accrochés à vous, le chef de projet vous demande comment vous avez progressé, et vous devez lire (et vous rappeler) quelque 150 pages de texte écrites de loin par de brillants écrivains. Bien sûr, vous aviez quelques jours, voire quelques semaines, à consacrer au projet, mais, si vous utilisez une arithmétique simple, d'une part 5 000 000 d'octets de code, d'autre part, disons 50 heures de travail. Il s'avère qu'il fallait en moyenne injecter 100 Ko de code par heure. Et ici, tout dépend beaucoup de la qualité du code. S'il est propre: facile à assembler, bien structuré et prévisible, le versement dans un projet semble être un processus nettement moins douloureux. Ce n'est pas le dernier rôle qui est joué par la conception des classes. Pas le dernier.
Ce que nous voulons de la conception des cours
De tout ce qui précède, de nombreuses conclusions intéressantes peuvent être tirées sur l'architecture générale, la pile technologique, le processus de développement, etc. Mais dès le début, nous avons décidé de parler de la conception des classes, voyons quelles choses utiles nous pouvons apprendre de ce qui a été dit plus tôt à ce sujet.
- J'aimerais qu'un développeur qui ne connaît pas bien le code de l'application puisse comprendre ce que fait cette classe en regardant une classe. Et vice versa - en regardant une exigence fonctionnelle ou non fonctionnelle, je pourrais rapidement deviner où se trouve l'application dans les classes qui en sont responsables. Eh bien, il est souhaitable que la mise en œuvre des exigences ne soit pas «répartie» dans toute l'application, mais concentrée dans une classe ou un groupe compact de classes. Permettez-moi d'expliquer avec un exemple le type d'anti-motif que je veux dire. Supposons que nous devons vérifier que 10 demandes d'un certain type ne peuvent être exécutées que par des utilisateurs qui ont plus de 20 points dans leur compte (peu importe ce que cela signifie). Une mauvaise façon de mettre en œuvre une telle exigence consiste à insérer un chèque au début de chaque demande. Ensuite, la logique sera répartie sur 10 méthodes, dans différents contrôleurs. Un bon moyen est de créer un filtre ou WebRequestInterceptor et de tout vérifier au même endroit.
- Je veux que les changements dans une classe n'affectant pas le contrat de classe n'affectent pas, eh bien, ou (soyons réalistes!) Au moins n'affectent pas beaucoup les autres classes. En d'autres termes, je veux résumer la mise en œuvre d'un contrat de classe.
- J'aimerais qu'il soit possible, en modifiant le contrat de classe, en parcourant la chaîne d'appels et en faisant des usages de recherche, de trouver les classes que ce changement affecte. Autrement dit, je veux que les classes n'aient pas de dépendances indirectes.
- Si possible, j'aimerais que les processus de traitement des demandes consistant en plusieurs étapes à un seul niveau ne soient pas étalés par le code de plusieurs classes, mais soient décrits au même niveau. C'est très bien si le code décrivant un tel processus de traitement tient sur un écran à l'intérieur d'une méthode avec un nom clair. Par exemple, nous devons rechercher tous les mots sur une ligne, appeler un service tiers pour chaque mot, obtenir une description du mot, appliquer un formatage à la description et enregistrer les résultats dans la base de données. Il s'agit d'une séquence d'actions en 4 étapes. Il est très pratique de comprendre le code et de changer sa logique lorsqu'il existe une méthode où ces étapes se succèdent.
- Je veux vraiment que les mêmes choses dans le code soient implémentées de la même manière. Par exemple, si nous accédons à la base de données immédiatement à partir du contrôleur, il est préférable de le faire partout (même si je n'appellerais pas une telle bonne pratique de conception). Et si nous avons déjà entré les niveaux de services et de référentiels, il est préférable de ne pas contacter la base de données directement depuis le contrôleur.
- J'aimerais que le nombre de classes / interfaces non directement responsables des exigences fonctionnelles et non fonctionnelles ne soit pas très important. Travailler avec un projet dans lequel il y a deux interfaces pour chaque classe avec logique, une hiérarchie complexe d'héritage de cinq classes, une fabrique de classe et une fabrique de classe abstraite, est assez difficile.
Recommandations pratiques
Après avoir formulé des souhaits, nous pouvons définir des étapes spécifiques qui nous permettront d'atteindre nos objectifs.
Méthodes statiques
En guise d'échauffement, je vais commencer par une règle relativement simple. Vous ne devez pas créer de méthodes statiques à moins qu'elles ne soient nécessaires au fonctionnement de l'une des bibliothèques utilisées (par exemple, vous devez créer un sérialiseur pour un type de données).
En principe, il n'y a rien de mal à utiliser des méthodes statiques. Si le comportement d'une méthode dépend entièrement de ses paramètres, pourquoi ne pas vraiment la rendre statique. Mais vous devez prendre en compte le fait que nous utilisons Spring IoC, qui sert à lier les composants de notre application. Spring IoC traite des concepts des haricots et de leur portée. Cette approche peut être mélangée avec des méthodes statiques regroupées en classes, mais la compréhension d'une telle application et même la modification de quelque chose (si, par exemple, vous devez passer un paramètre global à une méthode ou une classe) peut être très difficile.
Dans le même temps, les méthodes statiques par rapport aux bacs IoC donnent un avantage très insignifiant dans la vitesse d'invocation des méthodes. Et sur cela, peut-être, les avantages s'arrêtent.
Si vous ne créez pas une fonction métier qui nécessite un grand nombre d'appels ultrarapides entre différentes classes, il est préférable de ne pas utiliser de méthodes statiques.
Ici, le lecteur peut demander: "Mais qu'en est-il des classes StringUtils et IOUtils?" En effet, une tradition s'est développée dans le monde Java - pour mettre des fonctions auxiliaires pour travailler avec des chaînes et des flux d'entrée-sortie dans des méthodes statiques et les collecter sous l'égide des classes SomethingUtils. Mais cette tradition me semble plutôt moussue. Si vous le suivez, bien sûr, on ne s'attend pas à de grands dommages - tous les programmeurs Java y sont habitués. Mais cela n'a aucun sens dans une telle action rituelle. D'une part, pourquoi ne pas rendre le bean StringUtils, d'autre part, si vous ne rendez pas le bean et toutes les méthodes auxiliaires statiques, rendons déjà les classes parapluie statiques StockTradingUtils et BlockChainUtils. Commencer à mettre de la logique dans des méthodes statiques, dessiner une frontière et s'arrêter est difficile. Je vous conseille de ne pas commencer.
Enfin, n'oubliez pas que, grâce à Java 11, bon nombre des méthodes d'assistance qui parcouraient les développeurs de projet en projet depuis des décennies, faisaient soit partie de la bibliothèque standard, soit étaient fusionnées dans des bibliothèques, par exemple, dans Google Guava.
Contrat de classe atomique et compact
Il existe une règle simple qui s'applique au développement de tout système logiciel. En regardant n'importe quelle classe, vous devriez pouvoir expliquer rapidement et de manière compacte, sans recourir à de longues fouilles, ce que fait cette classe. S'il est impossible d'adapter l'explication dans un paragraphe (ce n'est pas nécessaire, cependant, exprimé dans une phrase), il pourrait être utile de réfléchir à cette classe et de la diviser en plusieurs classes atomiques. Par exemple, la classe "Recherche des fichiers texte sur un disque et compte le nombre de lettres Z dans chacun d'eux" - un bon candidat pour la décomposition "recherche sur un disque" + "compte le nombre de lettres".
En revanche, ne faites pas de classes trop petites, chacune étant conçue pour une action. Mais quelle taille devrait alors avoir la classe? Les règles de base sont les suivantes:
- Idéalement, lorsque le contrat de classe correspond à la description de la fonction commerciale (ou de la sous-fonction, selon la façon dont les exigences sont organisées). Ce n'est pas toujours possible: si une tentative de se conformer à cette règle conduit à la création d'un code encombrant et non évident, il est préférable de diviser la classe en parties plus petites.
- Une bonne métrique pour évaluer la qualité d'un contrat de classe est le rapport de sa complexité intrinsèque à la complexité du contrat. Par exemple, un très bon (bien que fantastique) contrat de classe peut ressembler à ceci: "La classe a une méthode qui reçoit une ligne avec une description du sujet en russe à l'entrée et compose une histoire de qualité ou même une histoire sur un sujet donné en conséquence." Ici, le contrat est simple et généralement compris. Son implémentation est extrêmement complexe, mais la complexité est cachée à l'intérieur de la classe.
Pourquoi cette règle est-elle importante?
- Premièrement, la capacité de s’expliquer clairement ce que fait chacune des classes est toujours utile. Malheureusement, loin de tous les développeurs de projets peuvent le faire. Vous pouvez souvent entendre quelque chose comme: «Eh bien, c'est un tel wrapper sur la classe Path, que nous avons en quelque sorte créé et parfois utilisé à la place de Path. Elle a également une méthode qui peut doubler tous les chemins d'accès File.separator - nous avons besoin de cette méthode lors de l'enregistrement des rapports dans le cloud, et pour une raison quelconque, elle s'est retrouvée dans la classe Path. "
- Le cerveau humain est capable de fonctionner simultanément avec pas plus de cinq à dix objets. La plupart des gens n'en ont pas plus de sept. En conséquence, si un développeur doit fonctionner avec plus de sept objets pour résoudre un problème, il manquera quelque chose ou sera obligé de regrouper plusieurs objets sous un "parapluie" logique. Et si vous devez encore l'emballer, pourquoi ne pas le faire tout de suite, consciemment, et donner à ce parapluie un nom significatif et un contrat clair.
Comment vérifier que tout est suffisamment granuleux? Demandez à un collègue de vous accorder 5 (cinq) minutes. Prenez la partie de l'application que vous travaillez actuellement à créer. Pour chaque classe, expliquez à un collègue ce que fait exactement cette classe. Si vous ne rentrez pas dans 5 minutes, ou si un collègue ne comprend pas pourquoi tel ou tel cours est nécessaire, vous devriez peut-être changer quelque chose. Eh bien, ou ne pas changer et refaire l'expérience, avec un autre collègue.
Dépendances de classe
Supposons que nous devons sélectionner des sections de texte liées de plus de 100 octets pour un fichier PDF compressé dans une archive ZIP et les enregistrer dans la base de données. Un antipattern populaire dans de tels cas ressemble à ceci:
- Il existe une classe qui ouvre une archive ZIP, recherche un fichier PDF et le renvoie en tant que InputStream.
- Cette classe a un lien vers une classe qui recherche dans les paragraphes PDF de texte.
- La classe qui fonctionne avec PDF, à son tour, a un lien vers la classe qui stocke les données dans la base de données.
D'une part, tout semble logique: les données reçues, appelées directement la classe suivante de la chaîne. Mais en même temps, les contrats de la classe au sommet de la chaîne se mélangent dans les contrats et les dépendances de toutes les classes qui entrent dans la chaîne derrière elle. Il est beaucoup plus correct de rendre ces classes atomiques et indépendantes les unes des autres, et de créer une autre classe qui implémente réellement la logique de traitement en connectant ces trois classes entre elles.
Comment ne pas le faire: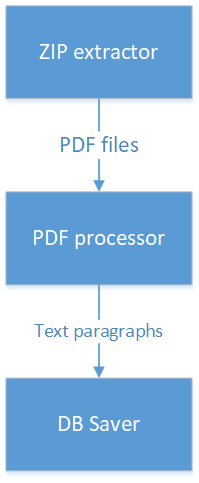
Qu'est-ce qui ne va pas ici? La classe qui fonctionne avec les fichiers ZIP transmet les données à la classe qui traite le PDF et qui, à son tour, transmet les données à la classe qui fonctionne avec la base de données. Cela signifie que la classe qui fonctionne avec ZIP, par conséquent, pour une raison quelconque, dépend des classes qui fonctionnent avec la base de données. De plus, la logique de traitement est répartie sur trois classes, et pour la comprendre, il faut parcourir les trois classes. Que se passe-t-il si vous avez besoin de paragraphes de texte obtenus à partir de PDF pour passer à un service tiers via un appel REST? Vous devrez changer la classe qui fonctionne avec PDF, et dessiner dedans aussi travailler avec REST.
Comment faire: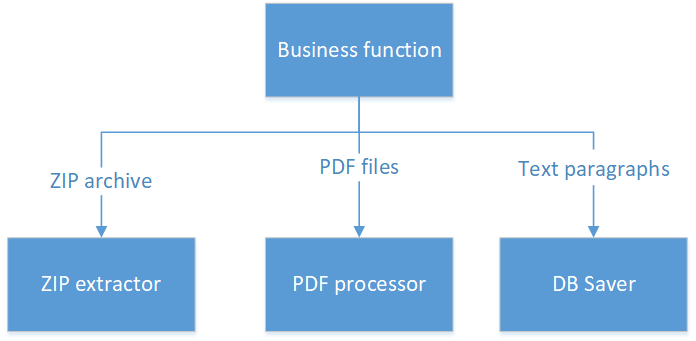
Ici, nous avons quatre classes:
- Une classe qui ne fonctionne qu'avec une archive ZIP et renvoie une liste de fichiers PDF (on peut dire - le retour de fichiers est mauvais - ils sont gros et vont casser l'application. Mais dans ce cas, lisons le mot «renvoie» au sens large. Par exemple, il renvoie Stream de InputStream )
- La deuxième classe est chargée de travailler avec PDF.
- La troisième classe ne sait rien et ne peut rien faire sauf enregistrer des paragraphes dans la base de données.
- Et la quatrième classe, qui se compose littéralement de plusieurs lignes de code, contient toute la logique métier qui tient sur un seul écran.
Je souligne encore une fois qu'en 2019 à Java il y a au moins deux bons (et un peu moins
bonnes) façons de ne pas transférer de fichiers et une liste complète de tous les paragraphes en tant qu'objets en mémoire. C’est:
- API Java Stream
- Rappels Autrement dit, une classe avec une fonction métier ne transmet pas de données directement, mais dit ZIP Extractor: voici un rappel pour vous, recherchez les fichiers PDF dans un fichier ZIP, créez un InputStream pour chaque fichier et appelez le rappel transféré avec lui.
Comportement implicite
Lorsque nous n'essayons pas de résoudre un problème complètement nouveau qui n'a été résolu par personne auparavant, mais que nous faisons plutôt quelque chose que d'autres développeurs ont déjà fait plusieurs centaines (ou centaines de milliers) fois auparavant, tous les membres de l'équipe ont des attentes concernant la complexité cyclomatique et l'intensité des ressources de la solution. . Par exemple, si nous devons trouver dans un fichier tous les mots commençant par la lettre z, il s'agit d'une lecture séquentielle et unique du fichier en blocs à partir du disque. Autrement dit, si vous vous concentrez sur
https://gist.github.com/jboner/2841832 - une telle opération prendra plusieurs microsecondes par 1 Mo, eh bien, peut-être, selon l'environnement de programmation et la charge du système, plusieurs dizaines, voire une centaine de microsecondes, mais pas une seconde du tout. Cela prendra plusieurs dizaines de kilo-octets de mémoire (nous laissons de côté la question de ce que nous faisons avec les résultats, c'est le souci d'une autre classe), et le code occupera très probablement environ un écran. Dans le même temps, nous nous attendons à ce qu'aucune autre ressource système ne soit utilisée. Autrement dit, le code ne crée pas de threads, n'écrit pas de données sur le disque, n'envoie pas de paquets sur le réseau et n'enregistre pas les données dans la base de données.
C'est l'attente habituelle d'un appel de méthode:
zWordFinder.findZWords(inputStream). ...
Si le code de votre classe ne satisfait pas à ces exigences pour une raison raisonnable, par exemple, pour classer un mot en z et non z, vous devez appeler la méthode REST à chaque fois (je ne sais pas pourquoi cela pourrait être nécessaire, mais imaginons cela) il est nécessaire d'écrire très attentivement dans le contrat de classe, et c'est très bien si le nom de la méthode indique que la méthode est en cours d'exécution quelque part à consulter.
Si vous n'avez aucune raison raisonnable de comportement implicite, réécrivez la classe.
Comment comprendre les attentes de la complexité et de l'intensité des ressources de la méthode? Vous devez recourir à l'une de ces méthodes simples:
- Avec l'expérience, acquérez des horizons assez larges.
- Demandez à un collègue - cela peut toujours être fait.
- Avant de commencer le développement, discutez avec les membres de l'équipe du plan de mise en œuvre.
- Pour vous poser la question: "Mais je n'utilise pas trop de ressources redondantes dans cette méthode?" C'est généralement suffisant.
Vous n'avez pas non plus besoin de vous impliquer dans l'optimisation - économiser 100 octets lorsqu'il est utilisé par la classe 100 000 n'a pas beaucoup de sens pour la plupart des applications.
Cette règle ouvre une fenêtre sur le monde riche de la suringénierie, masquant des réponses à des questions telles que «pourquoi ne pas dépenser un mois pour économiser 10 octets de mémoire dans une application qui a besoin de 10 Go pour fonctionner». Mais je ne développerai pas ce sujet ici. Elle mérite un article séparé.
Noms de méthode implicites
En programmation Java, il existe actuellement plusieurs conventions implicites concernant les noms de classe et leur comportement. Il n'y en a pas beaucoup, mais il vaut mieux ne pas les casser. J'essaierai d'énumérer ceux qui me viennent à l'esprit:
- Constructeur - crée une instance de la classe, peut créer des structures de données assez ramifiées, mais cela ne fonctionne pas avec la base de données, n'écrit pas sur le disque, n'envoie pas de données sur le réseau (je dirai que l'enregistreur intégré peut faire tout cela, mais c'est une autre histoire dans dans tous les cas, cela repose sur la conscience du configurateur de journalisation).
- Getter - getSomething () - renvoie une sorte de structure mémoire des profondeurs de l'objet. Encore une fois, il n'écrit pas sur le disque, n'effectue pas de calculs complexes, n'envoie pas de données sur le réseau, ne fonctionne pas avec la base de données (sauf lorsqu'il s'agit d'un champ ORM paresseux, et ce n'est qu'une des raisons pour lesquelles les champs paresseux doivent être utilisés avec le plus grand soin) .
- Setter - setSomething (Quelque chose quelque chose) - définit la valeur de la structure de données, ne fait pas de calculs complexes, n'envoie pas de données sur le réseau, ne fonctionne pas avec la base de données. En règle générale, le setter ne devrait pas impliquer de comportement ni de consommation implicites de ressources informatiques importantes.
- equals () et hashcode () - rien n'est attendu du tout, sauf pour des calculs et des comparaisons simples en quantité linéairement dépendante de la taille de la structure de données. Autrement dit, si nous appelons hashcode pour un objet de trois champs primitifs, il est prévu que N * 3 instructions de calcul simples soient exécutées.
- toSomething () - il est également prévu que cette méthode convertisse un type de données en un autre, et pour la conversion, elle n'a besoin que d'une quantité de mémoire comparable à la taille des structures et du temps du processeur, qui dépend linéairement de la taille des structures. Ici, il convient de noter que la conversion de type ne peut pas toujours être effectuée de manière linéaire, par exemple, la conversion d'une image pixel au format SVG peut être une action très simple, mais dans ce cas, il est préférable de nommer la méthode différemment. Par exemple, le nom computeAndConvertToSVG () semble quelque peu gênant, mais il suggère immédiatement que des calculs importants ont lieu à l'intérieur.
Je vais vous donner un exemple. J'ai récemment fait un audit d'application. Par la logique du travail, je sais que l'application quelque part dans le code s'abonne à la file d'attente RabbitMQ. Je marche dans le code - je ne trouve pas cet endroit. Je cherche directement un attrait pour le lapin, je commence à grimper, je vais à la place dans le flux d'affaires où l'abonnement a réellement lieu - je commence à jurer. A quoi cela ressemble dans le code:
- La méthode service.getQueueListener (tickerName) est appelée - le résultat renvoyé est ignoré. Cela peut alerter, mais un tel morceau de code où les résultats de la méthode sont ignorés n'est pas le seul dans l'application.
- A l'intérieur, tickerName est vérifié pour null et une autre méthode getQueueListenerByName (tickerName) est appelée.
- À l'intérieur, une instance de la classe QueueListener est tirée du hachage par le nom du ticker (si ce n'est pas le cas, elle est créée) et la méthode getSubscription () est appelée dessus.
- Et maintenant, à l'intérieur de la méthode getSubscription (), l'abonnement a réellement lieu. Et cela arrive quelque part au milieu d'une méthode de la taille de trois écrans.
Je vais vous dire franchement - sans parcourir toute la chaîne et sans lire une douzaine d'écrans de code attentifs, il était irréaliste de deviner où est l'abonnement. Si la méthode s'appelait subscribeToQueueByTicker (tickerName), cela me ferait gagner beaucoup de temps.
Classes utilitaires
Il existe un merveilleux livre Design Patterns: Elements of Reusable Object-Oriented Software (1994), il est souvent appelé GOF (Gang of Four, selon le nombre d'auteurs). L'avantage de ce livre est principalement qu'il a donné aux développeurs de différents pays une langue unique pour décrire les modèles de conception de classe. Maintenant, au lieu de «la classe est garantie d'exister dans une seule instance et d'avoir un point d'accès statique», nous pouvons dire «singleton». Le même livre a causé des dommages visibles aux esprits fragiles. Ce mal est bien décrit par une citation de l'un des forums "Chers collègues, j'ai besoin de créer une boutique en ligne, dites-moi avec quels modèles je dois commencer." En d'autres termes, certains programmeurs ont tendance à abuser des modèles de conception, et partout où vous pouvez gérer avec une classe, ils en créent parfois cinq ou six à la fois - juste au cas où, «pour plus de flexibilité».
Comment décider si vous avez besoin d'une fabrique de classe abstraite (ou d'un autre modèle plus compliqué qu'une interface) ou non? Il y a quelques considérations simples:
- Si vous rédigez une demande au printemps, 99% du temps n'est pas nécessaire. Spring vous propose des blocs de construction de niveau supérieur, utilisez-les. Le maximum que vous pouvez trouver utile est une classe abstraite.
- Si le point 1 ne vous donne toujours pas de réponse claire - n'oubliez pas que chaque modèle représente +1000 points pour la complexité de l'application. Analysez soigneusement si les avantages de l'utilisation du modèle l'emportent sur les inconvénients. Passant à une métaphore, rappelez-vous que chaque médicament guérit non seulement, mais nuit aussi légèrement. Ne buvez pas toutes les pilules en même temps.
Un bon exemple de la façon dont vous n'en avez pas besoin, vous pouvez le voir
ici .
Conclusion
Pour résumer, je tiens à noter que j'ai énuméré les recommandations les plus élémentaires. Je ne les distinguerais même pas sous la forme d'un article - ils sont si évidents. Mais au cours de la dernière année, j'ai rencontré trop souvent des demandes dans lesquelles bon nombre de ces recommandations ont été violées. Écrivons un code simple, facile à lire et à entretenir.