
Bonjour à tous!
Je suis développeur backend dans l'équipe du serveur Badoo. Lors de la conférence HighLoad de l’année dernière, j’ai
fait une présentation , dont je veux partager avec vous une version texte. Ce message sera très utile à ceux qui écrivent des tests pour le backend eux-mêmes et rencontrent des problèmes avec les tests de code hérité, ainsi qu'à ceux qui veulent tester une logique métier complexe.
De quoi parlerons-nous? Tout d'abord, je parlerai brièvement de notre processus de développement et de la façon dont il affecte notre besoin de tests et le désir d'écrire ces tests. Ensuite, nous allons monter et descendre la pyramide de l'automatisation des tests, discuter des types de tests que nous utilisons, parler des outils à l'intérieur de chacun d'eux et des problèmes que nous résolvons avec leur aide. En fin de compte, réfléchissez à la façon de gérer et d'exécuter tout cela.
Notre processus de développement
Nous avons illustré notre processus de développement:
Un golfeur est un développeur backend. À un moment donné, une tâche de développement lui arrive, généralement sous la forme de deux documents: les exigences du côté commercial et un document technique qui décrit les changements dans notre protocole d'interaction entre le backend et les clients (applications mobiles et site).
Le développeur écrit le code et le met en service, et plus tôt que toutes les applications clientes. Toutes les fonctionnalités sont protégées par des indicateurs de fonctionnalité ou des tests A / B, cela est prescrit dans un document technique. Après cela, conformément aux priorités actuelles et à la feuille de route du produit, les applications client sont publiées. Pour nous, développeurs backend, il est totalement imprévisible lorsqu'une fonctionnalité particulière sera implémentée sur les clients. Le cycle de publication des applications client est un peu plus compliqué et plus long que le nôtre, donc nos chefs de produit jonglent littéralement avec les priorités.
La culture de développement adoptée par l'entreprise est d'une grande importance: le développeur backend est responsable de la fonctionnalité depuis le moment de sa mise en œuvre sur le backend jusqu'à la dernière intégration sur la dernière plateforme sur laquelle il était initialement prévu de mettre en œuvre cette fonctionnalité.
Cette situation est tout à fait possible: il y a six mois, vous avez déployé une fonctionnalité, les équipes clientes ne l'ont pas mise en œuvre depuis longtemps, car les priorités de l'entreprise ont changé, vous êtes déjà occupé à travailler sur d'autres tâches, vous avez de nouveaux délais, priorités - et ici, vos collègues se mettent en marche et ils disent: «Vous souvenez-vous de cette chose que vous avez lavée il y a six mois? Elle ne travaille pas. " Et au lieu de vous engager dans de nouvelles tâches, vous éteignez les incendies.

Par conséquent, nos développeurs ont une motivation inhabituelle pour les programmeurs PHP - s'assurer qu'il y a le moins de problèmes possible pendant la phase d'intégration.
Que voulez-vous faire en premier pour vous assurer que la fonctionnalité fonctionne?
Bien sûr, la première chose qui me vient à l'esprit est de procéder à des tests manuels. Vous récupérez l'application, mais elle ne sait pas comment - parce que la fonctionnalité est nouvelle, les clients s'en occuperont dans six mois. Eh bien, les tests manuels ne donnent aucune garantie que pendant le temps qui s'écoule entre la sortie du backend et le début de l'intégration, personne ne cassera quoi que ce soit sur les clients.
Et ici, les tests automatisés viennent à notre aide.
Tests unitaires
Les tests les plus simples que nous écrivons sont des tests unitaires. Nous utilisons PHP comme langage principal pour le backend, et PHPUnit comme framework pour les tests unitaires. Pour l'avenir, je dirai que tous nos tests backend sont écrits sur la base de ce cadre.
Les tests unitaires couvrent le plus souvent de petits morceaux de code isolés, vérifient les performances des méthodes ou des fonctions, c'est-à-dire qu'il s'agit de minuscules unités de logique métier. Nos tests unitaires ne doivent pas interagir avec quoi que ce soit, accéder à des bases de données ou à des services.
Softmocks
La principale difficulté rencontrée par les développeurs lors de l'écriture de tests unitaires est le code non testable, et il s'agit généralement du code hérité.
Un exemple simple. Badoo a 12 ans, autrefois une très petite startup, qui a été développée par plusieurs personnes. Le démarrage a réussi avec succès sans aucun test. Ensuite, nous sommes devenus assez grands et nous avons réalisé que vous ne pouvez pas vivre sans tests. Mais à cette époque, beaucoup de code avait été écrit qui fonctionnait. Ne le réécrivez pas juste pour le plaisir de tester! Ce ne serait pas très raisonnable d'un point de vue commercial.
Par conséquent, nous avons développé une petite
bibliothèque open source SoftMocks , ce qui rend notre processus d'écriture de tests moins cher et plus rapide. Il intercepte tous les fichiers PHP inclus / requis et remplace à la volée le fichier source par du contenu modifié, c'est-à-dire du code réécrit. Cela nous permet de créer des talons pour n'importe quel code.
Il détaille le fonctionnement de la bibliothèque.
Voici à quoi cela ressemble pour un développeur:
Avec l'aide de ces constructions simples, nous pouvons redéfinir globalement tout ce que nous voulons. En particulier, ils nous permettent de contourner les limitations du créateur PHPUnit standard. Autrement dit, nous pouvons nous moquer des méthodes statiques et privées, redéfinir les constantes et faire bien plus, ce qui est impossible dans PHPUnit ordinaire.
Cependant, nous avons rencontré un problème: il semble aux développeurs que s'il y a des SoftMocks, il n'est pas nécessaire d'écrire le code testé - vous pouvez toujours "peigner" le code avec nos mocks globaux, et tout fonctionnera bien. Mais cette approche conduit à un code plus complexe et à l'accumulation de "béquilles". Par conséquent, nous avons adopté plusieurs règles qui nous permettent de garder la situation sous contrôle:
- Tout nouveau code devrait être facilement testé avec des simulations PHPUnit standard. Si cette condition est remplie, le code peut être testé et vous pouvez facilement sélectionner un petit morceau et le tester uniquement.
- SoftMocks peut être utilisé avec un ancien code écrit d'une manière qui ne convient pas aux tests unitaires, ainsi que dans les cas où il est trop cher / long / difficile à faire autrement (mettez l'accent sur ce qui est nécessaire).
Le respect de ces règles est soigneusement contrôlé au stade de la révision du code.
Test de mutation
Séparément, je veux parler de la qualité des tests unitaires. Je pense que beaucoup d'entre vous utilisent des mesures comme la couverture du code. Mais elle, malheureusement, ne répond pas à une question: "Ai-je passé un bon test unitaire?" Il est possible que vous ayez écrit un tel test, qui en fait ne vérifie rien, ne contient pas une seule assertion, mais il génère une excellente couverture de code. Bien sûr, l'exemple est exagéré, mais la situation n'est pas si éloignée de la réalité.
Récemment, nous avons commencé à introduire le test mutationnel. Il s'agit d'un concept assez ancien, mais peu connu. L'algorithme pour de tels tests est assez simple:
- prendre le code et la couverture du code;
- analyser et commencer à changer le code: vrai à faux,> à> =, + à - (en général, nuire à tous les niveaux);
- pour chaque changement de mutation, exécutez des suites de tests qui couvrent la chaîne modifiée;
- si les tests échouent, alors ils sont bons et ne nous permettent vraiment pas de casser le code;
- si les tests ont réussi, très probablement, ils ne sont pas assez efficaces, malgré la couverture, et il peut être utile de les examiner de plus près, pour donner une certaine affirmation (ou il existe un domaine non couvert par le test).
Il existe plusieurs frameworks prêts à l'emploi pour PHP, tels que Humbug et Infection. Malheureusement, ils ne nous convenaient pas, car ils sont incompatibles avec SoftMocks. Par conséquent, nous avons écrit notre propre petit utilitaire de console, qui fait de même, mais utilise notre format de couverture de code interne et est ami avec SoftMocks. Maintenant, le développeur le démarre manuellement et analyse les tests écrits par lui, mais nous travaillons à l'introduction de l'outil dans notre processus de développement.
Test d'intégration
A l'aide de tests d'intégration, nous vérifions l'interaction avec différents services et bases de données.
Pour mieux comprendre l'histoire, développons une promo fictive et couvrons-la avec des tests. Imaginez que nos chefs de produits aient décidé de distribuer des billets de conférence à nos utilisateurs les plus dévoués:
La promotion doit être affichée si:
- l'utilisateur dans le champ "Travail" indique "programmeur",
- l'utilisateur participe au test A / B HL18_promo,
- L'utilisateur est inscrit depuis plus de deux ans.
En cliquant sur le bouton «Obtenir un ticket», nous devons enregistrer les données de cet utilisateur dans une liste afin de les transférer à nos responsables qui distribuent les tickets.
Même dans cet exemple assez simple, il y a une chose qui ne peut pas être vérifiée à l'aide de tests unitaires - l'interaction avec la base de données. Pour ce faire, nous devons utiliser des tests d'intégration.
Considérez la manière standard de tester l'interaction avec la base de données proposée par PHPUnit:
- Augmentez la base de données de test.
- Nous préparons les DataTables et DataSets.
- Exécutez le test.
- Nous effaçons la base de données de test.
Quelles difficultés attendent une telle approche?
- Vous devez prendre en charge les structures de DataTables et DataSets. Si nous avons changé la disposition du tableau, il est nécessaire de refléter ces changements dans le test, ce qui n'est pas toujours pratique et nécessite du temps supplémentaire.
- Il faut du temps pour préparer la base de données. Chaque fois lors de la configuration du test, nous devons y télécharger quelque chose, créer des tableaux, ce qui est long et gênant s'il y a beaucoup de tests.
- Et l'inconvénient le plus important: l'exécution de ces tests en parallèle les rend instables. Nous avons commencé le test A, il a commencé à écrire sur la table de test, qu'il a créée. Dans le même temps, nous avons lancé le test B, qui souhaite fonctionner avec la même table de test. En conséquence, des blocages mutuels et d'autres situations imprévues surviennent.
Pour éviter ces problèmes, nous avons développé notre propre petite bibliothèque DBMocks.
DBMocks
Le principe de fonctionnement est le suivant:
- Avec l'aide de SoftMocks, nous interceptons tous les wrappers à travers lesquels nous travaillons avec des bases de données.
- Quand
la requête passe par une simulation, analyse la requête SQL et en extrait DB + TableName, et obtient l'hôte de la connexion.
- Sur le même hôte dans tmpfs, nous créons une table temporaire avec la même structure que celle d'origine (nous copions la structure en utilisant SHOW CREATE TABLE).
- Après cela, nous redirigerons toutes les demandes qui proviendront de la simulation vers cette table vers une demande temporaire fraîchement créée.
Qu'est-ce que cela nous donne:
- pas besoin de s'occuper constamment des structures;
- les tests ne peuvent plus corrompre les données des tables source, car nous les redirigeons vers des tables temporaires à la volée;
- nous testons toujours la compatibilité avec la version de MySQL avec laquelle nous travaillons, et si la demande cesse soudainement d'être compatible avec la nouvelle version, alors notre test la verra et la plantera.
- et surtout, les tests sont maintenant isolés, et même si vous les exécutez en parallèle, les threads se disperseront dans différentes tables temporaires, car nous ajoutons une clé unique à chaque test dans les noms des tables de test.
Test d'API
La différence entre les tests unitaires et API est bien illustrée par ce GIF:
 La serrure fonctionne bien, mais elle est attachée à la mauvaise porte.
La serrure fonctionne bien, mais elle est attachée à la mauvaise porte.Nos tests simulent une session client, sont capables d'envoyer des requêtes au backend, en suivant notre protocole, et le backend y répond comme un vrai client.
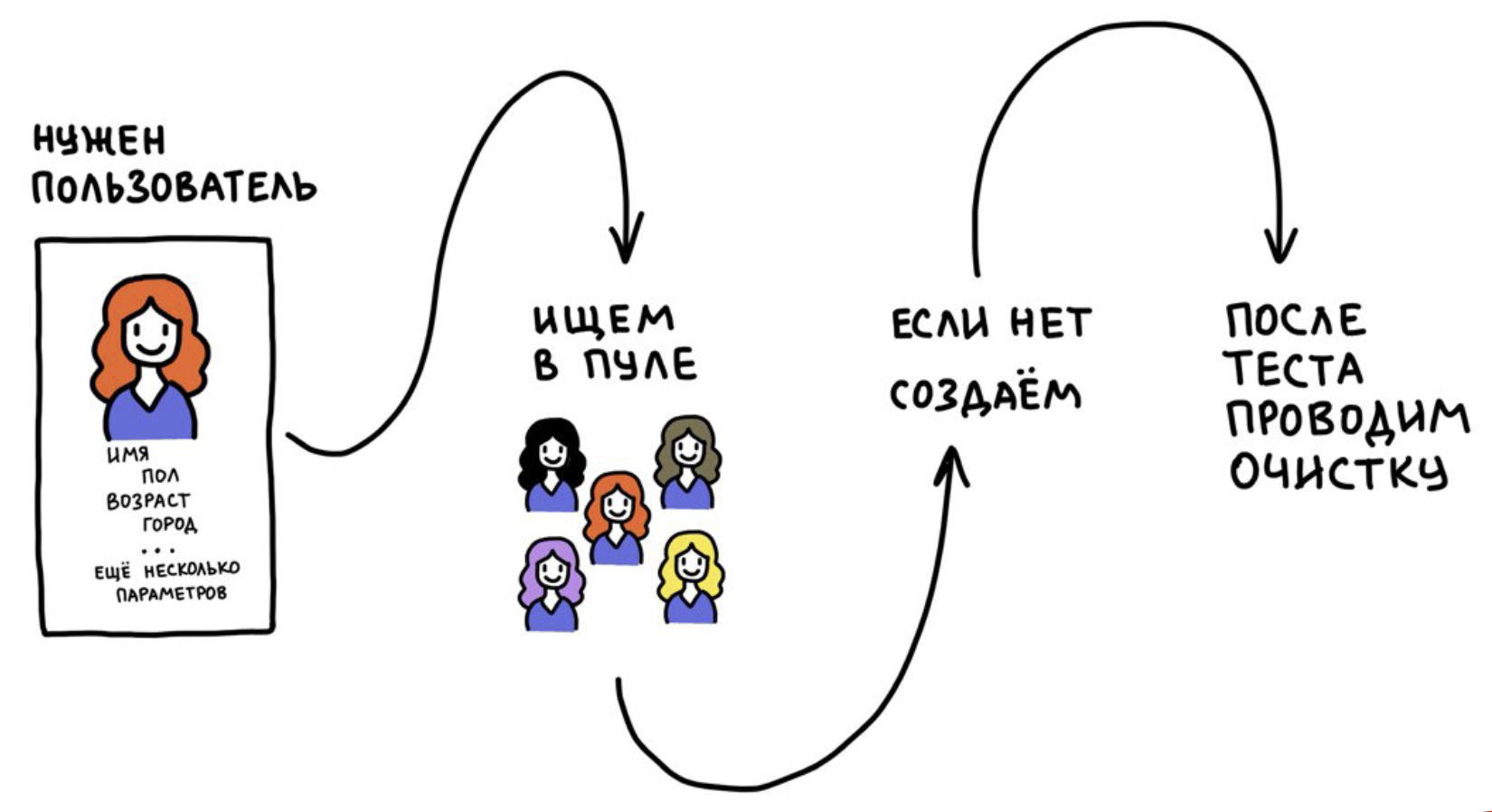
Pool d'utilisateurs de test
De quoi avons-nous besoin pour réussir ces tests? Revenons aux conditions du salon de notre promo:
- l'utilisateur dans le champ "Travail" indique "programmeur",
- l'utilisateur participe au test A / B HL18_promo,
- L'utilisateur est inscrit depuis plus de deux ans.
Apparemment, ici, tout est sur l'utilisateur. Et en réalité, 99% des tests API nécessitent un utilisateur enregistré autorisé, présent dans tous les services et bases de données.
Où l'obtenir? Vous pouvez essayer de l'enregistrer au moment du test, mais:
- elle est longue et consommatrice de ressources;
- après avoir terminé le test, cet utilisateur doit être supprimé d'une manière ou d'une autre, ce qui est une tâche plutôt banale si nous parlons de grands projets;
- enfin, comme dans de nombreux autres projets très chargés, nous effectuons de nombreuses opérations en arrière-plan (ajout d'un utilisateur à divers services, réplication vers d'autres centres de données, etc.); les tests ne savent rien de ces processus, mais s'ils s'appuient implicitement sur les résultats de leur exécution, il y a un risque d'instabilité.
Nous avons développé un outil appelé Pool d'utilisateurs de test. Il repose sur deux idées:
- Nous n'enregistrons pas les utilisateurs à chaque fois, mais nous les utilisons plusieurs fois.
- Après le test, nous réinitialisons les données utilisateur à leur état d'origine (au moment de l'inscription). Si cela n'est pas fait, les tests deviendront instables au fil du temps, car les utilisateurs seront «pollués» avec des informations provenant d'autres tests.
Cela fonctionne comme ceci:
À un moment donné, nous voulions exécuter nos tests d'API dans un environnement de production. Pourquoi voulons-nous même cela? Parce que l'infrastructure de développement n'est pas la même que la production.
Bien que nous essayions de répéter constamment l'infrastructure de production à une taille réduite, devel n'en sera jamais une copie complète. Pour être absolument sûr que la nouvelle version répond aux attentes et qu'il n'y a aucun problème, nous téléchargeons le nouveau code dans le cluster de préproduction, qui fonctionne avec les données et services de production, et y exécutons nos tests d'API.
Dans ce cas, il est très important de réfléchir à la façon d'isoler les utilisateurs de test des vrais.
Que se passera-t-il si les utilisateurs de test commencent à apparaître réels dans notre application. Comment isoler? Chacun de nos utilisateurs a un drapeau
is_test_user . Au stade de l'inscription, cela devient
yes ou
no et ne change plus. Par ce drapeau, nous isolons les utilisateurs dans tous les services. Il est également important d'exclure les utilisateurs de test des analyses commerciales et des résultats des tests A / B afin de ne pas fausser les statistiques.
Vous pouvez y aller de manière plus simple: nous avons commencé avec le fait que tous les utilisateurs de test ont été «relocalisés» en Antarctique. Si vous avez un géoservice, c'est une façon complètement fonctionnelle.
API QA
Nous n'avons pas seulement besoin d'un utilisateur - nous en avons besoin avec certains paramètres: travailler en tant que programmeur, participer à un certain test A / B et a été enregistré il y a plus de deux ans. Pour les utilisateurs de tests, nous pouvons facilement attribuer une profession à l'aide de notre API backend, mais entrer dans les tests A / B est probabiliste. Et la condition d'inscription il y a plus de deux ans est généralement difficile à remplir, car on ne sait pas quand l'utilisateur est apparu dans le pool.
Pour résoudre ces problèmes, nous avons une API QA. Il s'agit en fait d'une porte dérobée pour les tests, qui est une méthode API bien documentée qui vous permet de gérer rapidement et facilement les données des utilisateurs et de changer leur état en contournant le protocole principal de notre communication avec les clients. Les méthodes sont écrites par des développeurs backend pour les ingénieurs QA et pour une utilisation dans les tests d'interface utilisateur et d'API.
L'API QA ne peut être appliquée que dans le cas d'utilisateurs de test: s'il n'y a pas d'indicateur correspondant, le test tombera immédiatement. Voici l'une de nos méthodes d'API QA qui vous permet de changer la date d'enregistrement de l'utilisateur en une date arbitraire:
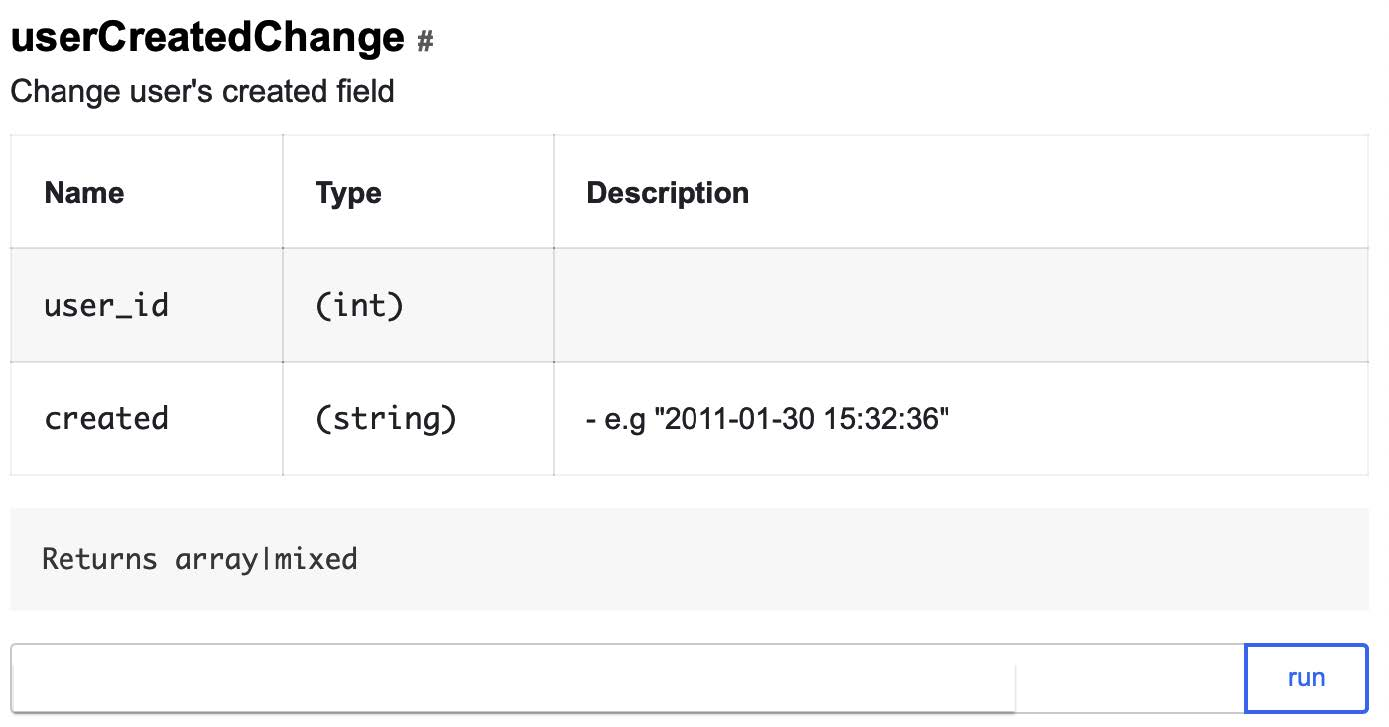
Et cela ressemblera donc à trois appels qui vous permettront de modifier rapidement les données de l'utilisateur de test afin qu'il satisfasse aux conditions d'affichage de la promo:
- Dans le champ "Travail" le "programmeur" est indiqué:
addUserWorkEducation?user_id=ID&works[]=Badoo,
- L'utilisateur participe au test A / B HL18_promo:
forceSplitTest?user_id=ID&test=HL18_promo
- Enregistré il y a plus de deux ans:
userCreatedChange?user_id=ID&created=2016-09-01
Puisqu'il s'agit d'une porte dérobée, il est impératif de penser à la sécurité. Nous avons protégé notre service de plusieurs manières:
- isolé au niveau du réseau: les services ne sont accessibles que depuis le réseau du bureau;
- à chaque demande, nous transmettons un secret, sans lequel il est impossible d'accéder à l'API QA même à partir du réseau du bureau;
- les méthodes ne fonctionnent qu'avec les utilisateurs de test.
Remotemocks
Pour travailler avec le backend distant des tests API, nous pouvons avoir besoin de simulations. Pour quoi? Par exemple, si le test d'API dans l'environnement de production commence à accéder à la base de données, nous devons nous assurer que les données qu'il contient sont effacées des données de test. De plus, les simulations contribuent à rendre la réponse au test plus adaptée aux tests.
Nous avons trois textes:
Badoo est une application multilingue, nous avons un composant de localisation complexe qui vous permet de traduire et de recevoir rapidement des traductions pour l'emplacement actuel de l'utilisateur. Nos localisateurs travaillent constamment pour améliorer les traductions, effectuer des tests A / B avec des jetons et rechercher des formulations plus efficaces. Et, pendant le test, nous ne pouvons pas savoir quel texte sera retourné par le serveur - il peut changer à tout moment. Mais nous pouvons utiliser RemoteMocks pour vérifier si le composant de localisation est correctement accédé.
Comment fonctionnent RemoteMocks? Le test demande au backend de les initialiser pour sa session et, à réception de toutes les demandes suivantes, le backend vérifie les faux pour la session en cours. S'ils le sont, il les initialise simplement à l'aide de SoftMocks.
Si nous voulons créer une maquette distante, nous indiquons quelle classe ou méthode doit être remplacée et avec quoi. Toutes les demandes backend ultérieures seront exécutées en tenant compte de cette simulation:
$this->remoteInterceptMethod( \Promo\HighLoadConference::class, 'saveUserEmailToDb', true );
Eh bien, maintenant, collectons notre test d'API:
D'une manière si simple, nous pouvons tester toute fonctionnalité qui vient au développement dans le backend et nécessite des modifications dans le protocole mobile.
Règles d'utilisation des tests d'API
Tout semble aller bien, mais nous avons de nouveau rencontré un problème: les tests d'API se sont avérés trop pratiques pour le développement et il y avait une tentation de les utiliser partout. En conséquence, une fois que nous avons réalisé que nous commencions à résoudre des problèmes à l'aide de tests API auxquels ils n'étaient pas destinés.
Pourquoi est-ce mauvais? Parce que les tests API sont très lents. Ils vont sur le réseau, se tournent vers le backend, qui récupère la session, va à la base de données et à un tas de services. Par conséquent, nous avons développé un ensemble de règles d'utilisation des tests API:
- Les tests API ont pour but de vérifier le protocole d'interaction entre le client et le serveur, ainsi que l'intégration correcte du nouveau code;
- il est permis de couvrir des processus complexes avec eux, par exemple, des chaînes d'actions;
- ils ne peuvent pas être utilisés pour tester la petite variabilité de la réponse du serveur - c'est la tâche des tests unitaires;
- lors de la révision du code, nous vérifions notamment les tests.
Tests d'interface utilisateur
Puisque nous envisageons une pyramide d'automatisation, je vais vous parler un peu des tests d'interface utilisateur.
Les développeurs backend de Badoo n'écrivent pas de tests d'interface utilisateur - pour cela, nous avons une équipe dédiée dans le département QA. Nous couvrons la fonctionnalité avec des tests d'interface utilisateur lorsqu'elle est déjà évoquée et stabilisée, car nous pensons qu'il est déraisonnable de dépenser des ressources pour une automatisation assez coûteuse de la fonctionnalité, qui, peut-être, n'ira pas au-delà du test A / B.
Nous utilisons Calabash pour les tests automatiques mobiles et Selenium pour le Web.
Il parle de notre plate-forme d'automatisation et de test.
Essai de fonctionnement
Nous avons maintenant 100 000 tests unitaires, 6 000 tests d'intégration et 14 000 tests API. Si vous essayez de les exécuter dans un seul thread, alors même sur notre machine la plus puissante, une exécution complète de tous prendra: modulaire - 40 minutes, intégration - 90 minutes, tests API - dix heures. C'est trop long.
Parallélisation
Nous avons parlé de notre expérience de parallélisation des tests unitaires dans cet article .La première solution, qui semble évidente, consiste à exécuter des tests dans plusieurs threads. Mais nous sommes allés plus loin et avons fait un cloud pour un lancement parallèle afin de pouvoir faire évoluer les ressources matérielles. Simplifié, son travail ressemble à ceci:
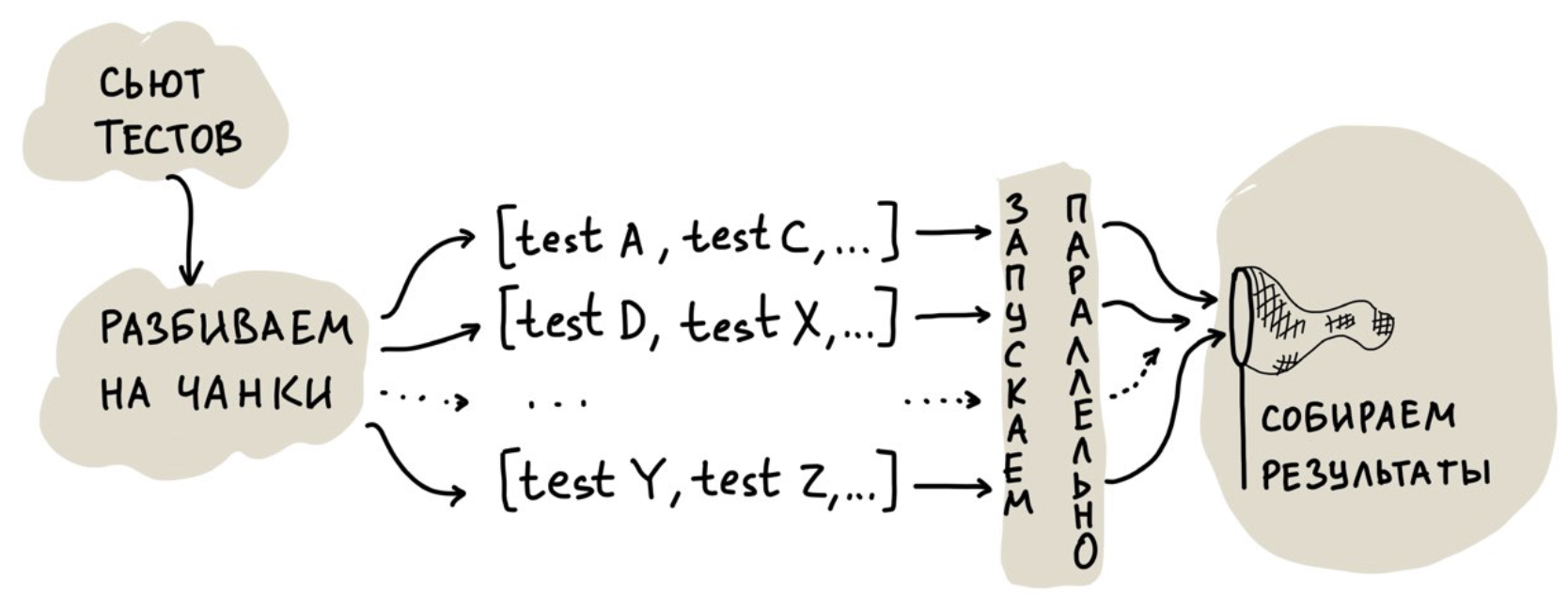
La tâche la plus intéressante ici est la répartition des tests entre les threads, c'est-à-dire leur répartition en morceaux.
Vous pouvez les diviser également, mais tous les tests sont différents, il peut donc y avoir un fort biais dans le temps d'exécution d'un thread: tous les threads ont déjà atteint et l'un se bloque pendant une demi-heure, car il était «chanceux» avec des tests très lents.
Vous pouvez démarrer plusieurs threads et les alimenter en testant un à la fois. Dans ce cas, l'inconvénient est moins évident: il y a des frais généraux d'initialisation de l'environnement qui, avec un grand nombre de tests et cette approche, commencent à jouer un rôle important.
Qu'avons-nous fait? Nous avons commencé à collecter des statistiques sur le temps nécessaire pour exécuter chaque test, puis à commencer à composer des morceaux de telle manière que, selon les statistiques, un thread ne fonctionnerait pas pendant plus de 30 secondes. Dans le même temps, nous emballons les tests assez étroitement en morceaux pour les rendre plus petits.
Cependant, notre approche présente également un inconvénient. Il est associé aux tests API: ils sont très lents et consomment beaucoup de ressources, empêchant l'exécution de tests rapides.
Par conséquent, nous avons divisé le cloud en deux parties: dans la première, seuls les tests rapides sont lancés, et dans la seconde, à la fois rapide et lent peuvent être lancés. Avec cette approche, nous avons toujours un morceau du cloud qui peut gérer des tests rapides.
En conséquence, les tests unitaires ont commencé à s'exécuter en une minute, les tests d'intégration en cinq minutes et les tests API en 15 minutes. Autrement dit, une course complète au lieu de 12 heures ne prend pas plus de 22 minutes.
Test de couverture de code exécuté
Nous avons un grand monolithe complexe et, dans le bon sens, nous devons constamment effectuer tous les tests, car un changement à un endroit peut casser quelque chose à un autre. C'est l'un des principaux inconvénients de l'architecture monolithique.
À un moment donné, nous sommes arrivés à la conclusion que vous n'avez pas besoin d'exécuter tous les tests à chaque fois - vous pouvez effectuer des analyses en fonction de la couverture du code:
- Prenez notre branche diff.
- Nous créons une liste de fichiers modifiés.
- Pour chaque fichier, nous obtenons une liste de tests,
qui le couvrent.
- À partir de ces tests, nous créons un ensemble et l'exécutons dans un nuage de test.
Où obtenir une couverture? Nous collectons des données une fois par jour lorsque l'infrastructure de l'environnement de développement est inactive. Le nombre de tests effectués a considérablement diminué, la vitesse de réception des commentaires de leur part, au contraire, a considérablement augmenté. Profit!
Un bonus supplémentaire était la possibilité d'exécuter des tests pour les correctifs. Malgré le fait que Badoo n'a pas été une startup depuis longtemps, nous pouvons toujours mettre en œuvre rapidement des changements dans la production, verser rapidement des correctifs, déployer des fonctionnalités et changer la configuration. En règle générale, la vitesse de déploiement des correctifs est très importante pour nous. , .
. , , , . . , code coverage . , , — , - , . .
API-, code coverage. , , . - , API- .
Conclusion
- , . - , , - .
- ≠ . code review , .
- , , . .
- . .
- , ! , .
, Badoo PHP Meetup 16 . PHP-. , . ! 12:00, — YouTube- .