Voici une traduction un peu rafraîchie de mon blog de 2015 . La publication montre comment organiser gratuitement une bibliothèque universitaire personnelle de taille illimitée. Il s'agit d'un cas amusant d'un manuel auto-écrit auquel je suis retourné plusieurs fois moi-même et beaucoup d'autres fois j'ai référé mes amis, même des non-russophones qui ont dû utiliser Google Translator et déduire le reste des captures d'écran. Enfin, j'ai décidé de le traduire en ajoutant quelques informations de base sur la façon d'utiliser Zotero avec rmarkdown.

Une brève (et, espérons-le, inutile pour vous) introduction des gestionnaires bibliographiques
Le gestionnaire bibliographique est un épargnant de vie dans la vie académique quotidienne. Je souffre presque de douleurs physiques en pensant à des collègues qui, pour une raison quelconque, n'ont jamais commencé à en utiliser un - toutes ces feuilles de calcul Excel avec des citations préférées, des dossiers en désordre avec des PDF, des heures constantes perdues pour la tâche meurtrière du formatage manuel de la liste de référence. Une fois que vous commencez à utiliser un gestionnaire de référence, tout devient un cauchemar heureusement oublié.
J'ai tendance à penser aux métadonnées bibliographiques comme LEGO.

Pour chaque article (chapitre de livre / pré-impression / package R), nous avons un certain nombre de pièces de métadonnées - titre, auteurs, date de publication, etc. Ce sont les blocs LEGO. Pour différents styles bibliographiques, nous avons juste besoin de réorganiser ces blocs en insérant diverses virgules, points-virgules et guillemets.
Le gestionnaire bibliographique garde une trace de tous les blocs LEGO et sait (apprend facilement) comment en composer des styles de citation appropriés. Tout ce dont nous avons besoin est de télécharger le style de citation d'un journal spécifique . Il y a plus de six mille styles bibliographiques! [Ceci est mon argument n ° 1 contre les idées de complot d'un pouvoir centralisé qui gouverne notre monde.)]
Pourquoi Zotero?
Il existe des dizaines de gestionnaires bibliographiques ( voir un tableau comparatif ). Certains d'entre eux sont gratuits, les autres nécessitent des abonnements payants. Probablement, les deux plus populaires sont Zotero et Mendeley . Les deux sont gratuits à utiliser et font de l'argent en offrant un stockage cloud pour synchroniser les PDF des documents. Pourtant, les deux offrent un stockage limité et gratuit - Zotero donne 300 Mo et Mendeley donne 2 Go.
Pourquoi puis-je choisir et recommander Zotero? Parce qu'il est assez facile de configurer Zotero afin que les 300 Mo gratuits ne soient utilisés que pour synchroniser les métadonnées (ce qui signifie en pratique un stockage presque infini), et les PDF sont synchronisés séparément en utilisant une solution cloud de votre choix (j'utilise Google Drive). C'est le principal hack de configuration que je montre dans ce blog . Il n'y a pas de hack similaire pour Mendeley, et avec eux, à un moment donné, on est obligé de payer pour un stockage supplémentaire.
Une autre considération en faveur de Zotero est qu'il s'agit d'un programme open source avec une forte communauté et un engagement franc de rester libre pour toujours, tandis que Mendeley est un produit à but lucratif Elsevier. La communauté universitaire connaît bien Elsevier en particulier et les produits à but lucratif en général. Ici, l'histoire d'Academia.edu est très indicative. Jetez un œil à cette pièce de Forbes . En tant que décision tout au long de ma carrière, je suis confiant dans le choix de Zotero. Et le projet continue de se développer correctement - il suffit de regarder les récentes entrées du blog Zotero sur les nouvelles fonctionnalités telles que l' intégration de Google Docs, l'intégration de Unpaywall et un nouveau service Web pour des citations rapides .
Enfin, un exemple de la force de la communauté Zotero. Une fois que j'ai compris que le référentiel de styles n'a pas de style pour la recherche démographique, l'une des meilleures revues de démographie. J'ai ouvert une demande sur le forum Zotero et en deux jours le style a été créé.
Prérequis
- [Téléchargez et installez Zotero] [vers le bas]. Il est multiplateforme et fonctionne sans problème avec divers systèmes, même lorsque la même base de données est installée en parallèle sur des machines avec différents systèmes d'exploitation. J'ai utilisé win + linux et win + mac - aucun problème de synchronisation jamais.
- À partir de la même [page de téléchargement] [vers le bas], installez Zotero Connector, une extension de navigateur qui permet de récupérer des métadonnées bibliographiques.
- Créez un [compte sur le site Web de Zotero] [reg]. Il sera utilisé ultérieurement pour synchroniser la base de données des métadonnées bibliographiques.
- Téléchargez et installez les deux plugins dont nous aurons besoin - [ZotFile] [zot] (organise la base de données des PDF) et [Better BibTeX] [bbt] (exporte la bibliothèque vers .bib, nous l'utiliserons plus tard avec rmarkdown). Les plugins pour Zotero sont des archives .xpi. Pour installer les plugins, ouvrez Zotero et cliquez sur
Tools --> Add-ons . Une fenêtre distincte pour le Add-ons manager apparaîtra.

Là, nous devons cliquer sur le bouton d'engrenage d'options et sélectionner l'option Install Add-on From File . Enfin, accédez au fichier .xpi et installez. Zotero vous demandera de redémarrer, veuillez le faire.
Nous sommes prêts à passer par la configuration étape par étape.
Préférences Zotero
Commençons par parcourir les préférences de Zotero. Pour les modifier, cliquez sur Edit --> Preferences . Une fenêtre avec plusieurs onglets apparaît.
Général Je décoche seulement l'option de créer des instantanés de pages Web automatiques que je ne trouve pas si utiles par rapport à tous les effets d'encombrement de tous ces multiples petits fichiers nécessaires pour répliquer une page html localement.

Sync . Ici, nous devons spécifier les détails du compte pour synchroniser notre base de données. Il est important de décocher l'option de synchronisation en texte intégral, sinon le stockage de 300 Mo sera rapidement rempli. Nous aurons la solution pour le texte intégral un peu plus tard.

Cherchez . Définit la base de données du moteur de recherche interne. Les valeurs par défaut sont raisonnables.
Exporter . Choisissez le style d'exportation rapide à l'aide du Shift+Ctrl+C
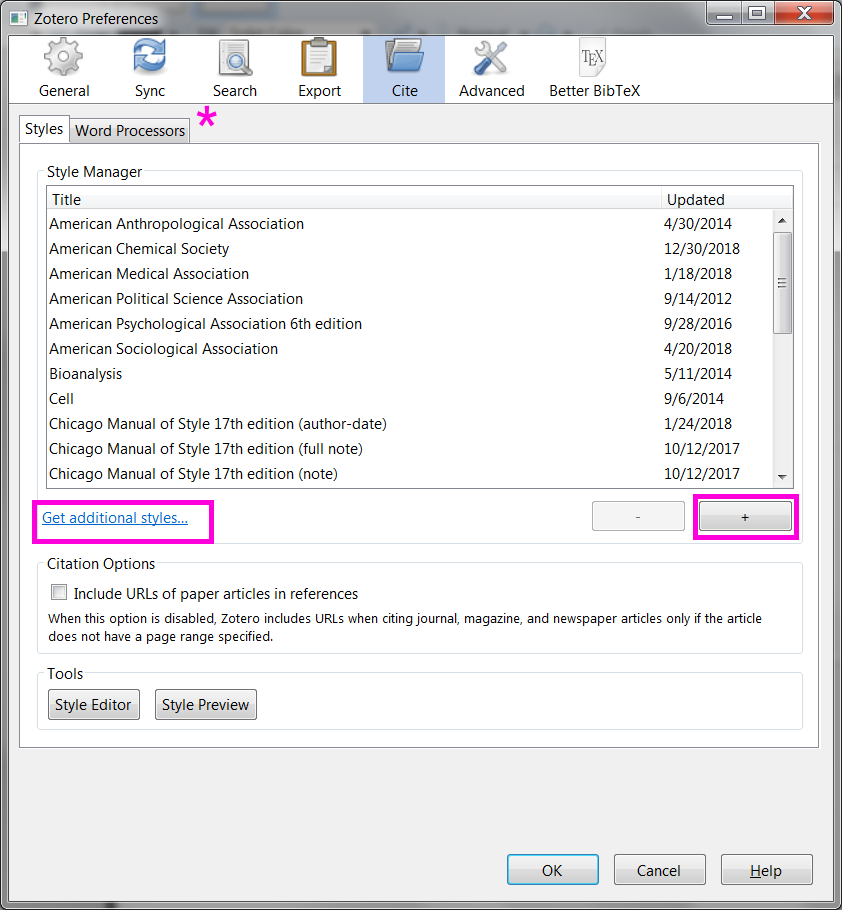
Cite . Styles de citation stockés localement. Une fonctionnalité intéressante ici est le lien Get additional styles qui apporte une sélection intégrée de l'ensemble de la base de données des styles Zotero . Les styles peuvent également être installés à partir de fichiers locaux .csl, pour cela, appuyez sur le bouton + . Ne manquez pas le sous-onglet Word Processors . Là, nous pouvons obtenir les plugins qui intègrent Zotero à Microsoft Word et Libre Office.
Avancé Ici, nous sommes plus intéressés par le sous-onglet Files and Folders . Il s'agit de l'étape la plus importante pour séparer le stockage des métadonnées et des fichiers.

Le premier chemin devrait conduire à un répertoire qui stocke les PDF en texte intégral, je l'appelle zotero-library . Ce répertoire doit se trouver quelque part dans la partie du système de fichiers local qui est synchronisée. Dans mon cas, c'est le répertoire nommé ikashnitsky , que je synchronise avec Google Drive. Le deuxième chemin mène aux fichiers système de Zotero, je l'appelle zotero-system . Ce répertoire doit être placé quelque part dans la partie non synchronisée du système de fichiers local. Il sera mis à jour par la synchronisation native de Zotero, et il vaut mieux que ces fichiers système ne soient pas remplacés par un logiciel de synchronisation externe.
Meilleur BibTeX . Cet onglet apparaît après l'installation de l'extension Better BibTeX. L'extension est nécessaire pour exporter la bibliothèque bibliographique entière (ou certaines de ses parties) sous forme de fichier texte .bib. Cette étape est nécessaire pour utiliser Zotero dans RStudio lors de la rédaction d'articles académiques avec rmarkdown .

L'option la plus importante ici est de définir les règles de création des clés de citation. Il existe un nombre presque infini de façons de définir ces clés ( consultez le manuel ). Mon choix personnel est [auth:lower][year][journal:lower:abbr] , ce qui signifie qu'une clé se compose du nom du premier auteur, de l'année de publication et de l'abréviation des premières lettres du titre du journal, tout en minuscules. Ainsi, la clé de mon dernier article publié dans Tijdschrift voor economische en sociale geografie est kashnitsky2019tveesg .
Préférences ZotFile
Ensuite, nous devons configurer ZotFile. Cette extension permet de renommer les PDF selon des règles prédéfinies et de les stocker dans une base de données hiérarchique avec des noms significatifs des sous-répertoires. Pour ouvrir la fenêtre de configuration, cliquez sur Tools --> ZotFile Preferences . Encore une fois, la fenêtre comporte plusieurs onglets.
Général Nous définissons ici deux chemins. Le premier est l'emplacement par défaut des fichiers téléchargés par votre navigateur. Cette option indique à ZotFile où chercher les fichiers PDF à traiter lorsque vous importez un document à partir du site Web de l'éditeur (rappelez-vous que nous avons précédemment installé Zotero Connector). Le deuxième chemin mène au répertoire local créé pour les fichiers PDF en texte intégral, celui que j'ai nommé zotero-library et qui est synchronisé avec une solution cloud externe de notre choix.

Pour naviguer plus facilement dans cette base de données PDF, cochez l'option Use subfolder defined by . Ici encore, nous avons un large choix de façons de définir les règles pour nommer les sous-répertoires. Cliquez sur l'icône d'informations pour découvrir les options. Je choisis simplement d'avoir un dossier séparé pour chaque premier auteur.
Paramètres de la tablette . Apparemment, ce menu permet de configurer un échange de PDF avec une tablette. Je ne l'ai jamais utilisé, donc omis.
Renommer les règles . Ici, il est important de s'assurer que ZotFile est responsable du changement de nom. Ensuite, nous définissons comment renommer les PDF en fonction des métadonnées bibliographiques disponibles. Encore une fois, nous avons ici de nombreuses options. Mon choix est {%a_}{%y_}{%t} qui donne des noms de fichiers comme kashnitsky_2018_russian_periphery_is_dying_in_movement.pdf (encore un exemple pour mon récent article dans GeoJournal ).

Paramètres avancés . J'ai seulement vérifié l'option de remplacer tous les symboles non standard par de l'ASCII ordinaire.
Une note très importante sur ZotFile! .
Si vous analysez les métadonnées manuellement à partir d'un PDF, assurez-vous de renommer le fichier à l'aide de ZotFile. Pour cela, cliquez avec le bouton droit sur l'enregistrement de métadonnées Manage Attachments --> Rename Attachments . Cette action indique explicitement d'utiliser ZotFile pour renommer et déplace le PDF renommé vers un sous-répertoire approprié. La pièce jointe dans Zotero ne doit pas ressembler à un fichier PDF ...

... mais devrait plutôt être un lien vers le fichier renommé.

Dans ces captures d'écran, je montre également l'emplacement des fichiers PDF réels dans les deux cas (cliquez avec le bouton droit sur l'enregistrement de métadonnées Show File ). Comme vous pouvez le voir, dans le premier cas, le PDF se trouve dans un dossier dénué de sens quelque part dans le zotero-system . En revanche, le PDF renommé par ZotFile est situé dans un sous-répertoire correctement nommé dans zotero-library . Ainsi, dans ce dernier cas, le PDF est synchronisé avec mon Google Drive et est accessible de n'importe où.

Plus important encore, lorsque j'ai besoin de restaurer toute ma base de données d'articles académiques sur une autre machine, il me suffit de suivre ces étapes. Tant que la base de données de métadonnées du système est synchronisée par Zotero et que je fournis à Zotero le lien vers un stockage PDF, il reconnaîtra tous les chemins relatifs vers les fichiers et la bibliothèque entière est restaurée. Cette configuration permet également d'avoir la même bibliothèque synchronisée en continu sur plusieurs machines. Le hack est dans ZotFile qui ajoute une ligne de chemin de file aux métadonnées des articles.

Tant que je garde les paramètres inchangés, tout sera bien synchronisé sur plusieurs appareils. Au final, j'apprécie le stockage illimité de mes PDF avec la synchronisation native très agréable et fiable des métadonnées de Zotero.
Dernière remarque sur Zotero . N'hésitez pas à nettoyer de temps en temps tout l'encombrement du zotero-system/storage .
Utiliser la bibliothèque Zotero dans RStudio avec rmarkdown
Zotero a une très belle intégration intégrée avec Microsoft Word et Libre Office. Un peu de magie est nécessaire si l'on veut l'utiliser avec LaTeX ou (comme moi) avec rmarkdown . La partie magique est le plugin Better BibTeX, que nous avons installé et configuré plus tôt.
Better BibTeX offre un moyen facile d'exporter des notices bibliographiques de Zotero en texte brut .bib et de maintenir le fichier à jour une fois les notices modifiées. Faites un clic droit sur la collection dans Zotero et choisissez Export Collection .

Ensuite, dans la fenêtre suivante, choisissez d'exporter en tant que Better BibTeX et cochez l'option Se tenir à Keep updated .

Le fichier de sortie .bib doit être placé dans le répertoire à partir duquel nous allons tricoter le fichier .rmd. Le nom du .bib est spécifié dans l'en-tête YAML du .rmd. Voici un exemple de mon projet en cours d'exécution avec \ @jm_aburto .

Notez que les fonctions YAML exactes peuvent varier en fonction du rmarkdown modèle rmarkdown . Dans ce cas, j'utilise bookdown , qui permet également de spécifier le style bibliographique souhaité, le fichier .csl doit également être copié dans le répertoire tricot.
Ensuite, tout est prêt à utiliser les clés de citation pour générer des citations dans tout le texte. Pour plus de détails sur la syntaxe de citation de rmarkdown , il est préférable de se référer au manuel de RStudio ou au chapitre correspondant du livre de bookdown sur bookdown .
Le dernier conseil ici est d'utiliser le package citr , qui apporte un moyen simple et interactif de sélectionner des citations dans le fichier .bib. Une fois le package installé, une Insert citation complément RStudio apparaît qui exécute la commande citr:::insert_citation() (vous pouvez attribuer une touche de raccourci au complément). Cette fonction apporte une application brillante pour sélectionner une citation de manière interactive. Plus de détails dans le repo github .
Bonne écriture papier avec Zotero et RStudio!