Je suis un grand fan de tout ce que fait
Fabien Sanglard , j'aime son blog, et j'ai lu ses
deux livres de bout en bout (décrit dans un
podcast récent des
Hansleminutes ).
Fabien a récemment écrit un excellent article où il a
décrypté un minuscule ray tracer, désobfusquant le code et expliquant les mathématiques de manière fantastique. Je recommande vraiment de prendre le temps de lire ceci!
Mais cela m'a fait me demander
s'il était possible de porter ce code C ++ en C # ? Comme j'ai dû écrire beaucoup de C ++ récemment dans mon
travail principal , j'ai pensé que je pouvais l'essayer.
Mais plus important encore, je voulais avoir une meilleure idée de
savoir si C # est un langage de bas niveau ?
Une question légèrement différente, mais connexe: dans quelle mesure C # convient-il à la "programmation système"? À ce sujet, je recommande vraiment
l'excellent post de Joe Duffy de 2013 .
Port de ligne
J'ai commencé par porter simplement le
code C ++ désobfusculé ligne par ligne en C #. C'était assez simple: il semble que la vérité est toujours en train de dire que C # est C ++++ !!!
L'exemple montre la structure de données principale - 'vecteur', voici une comparaison, C ++ à gauche, C # à droite:

Il existe donc quelques différences syntaxiques, mais comme .NET vous permet de définir
vos propres types de valeur , j'ai pu obtenir les mêmes fonctionnalités. Ceci est important car le traitement du «vecteur» comme une structure signifie que nous pouvons obtenir une meilleure «localité de données» et nous n'avons pas besoin d'impliquer le garbage collector .NET, car les données seront poussées sur la pile (oui, je sais que c'est un détail d'implémentation).
Pour plus d'informations sur les
structs ou les «types de valeur» dans .NET, voir ici:
En particulier, dans le dernier article d'Eric Lippert, nous trouvons une citation si utile qui montre clairement ce que sont réellement les «types de valeur»:
Bien sûr, le fait le plus important sur les types de valeurs n'est pas les détails de mise en œuvre, la façon dont ils sont distingués , mais plutôt la signification sémantique originale du «type de valeur», à savoir qu'il est toujours copié «par valeur» . Si les informations d'allocation étaient importantes, nous les appellerions «types de tas» et «types de pile». Mais dans la plupart des cas, cela n'a pas d'importance. La plupart du temps, la sémantique de la copie et de l'identification est pertinente.
Voyons maintenant à quoi ressemblent certaines autres méthodes (encore C ++ à gauche, C # à droite), d'abord
RayTracing(..) :
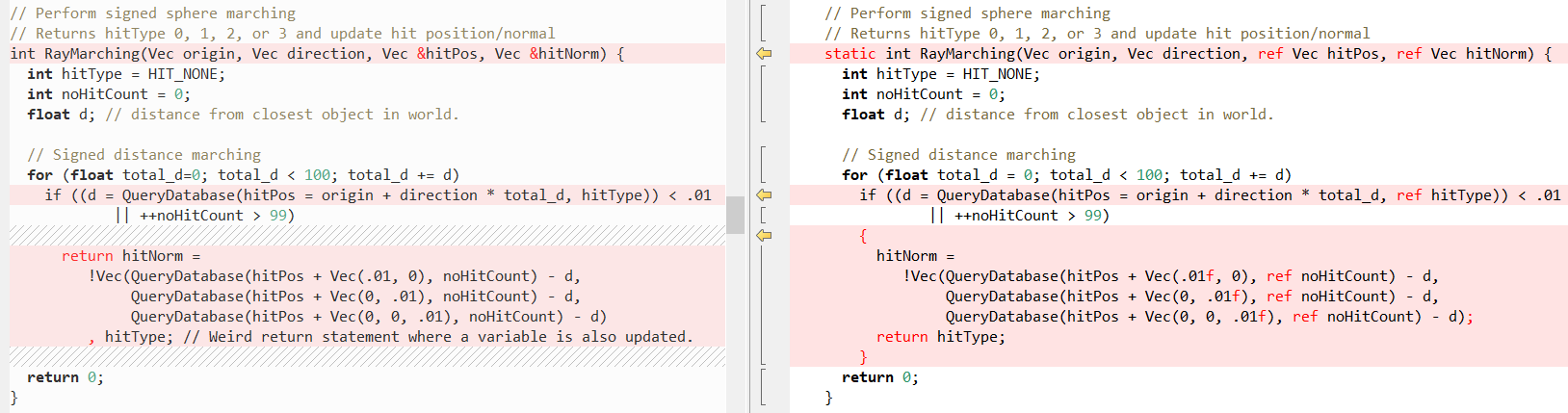
Ensuite,
QueryDatabase (..) :
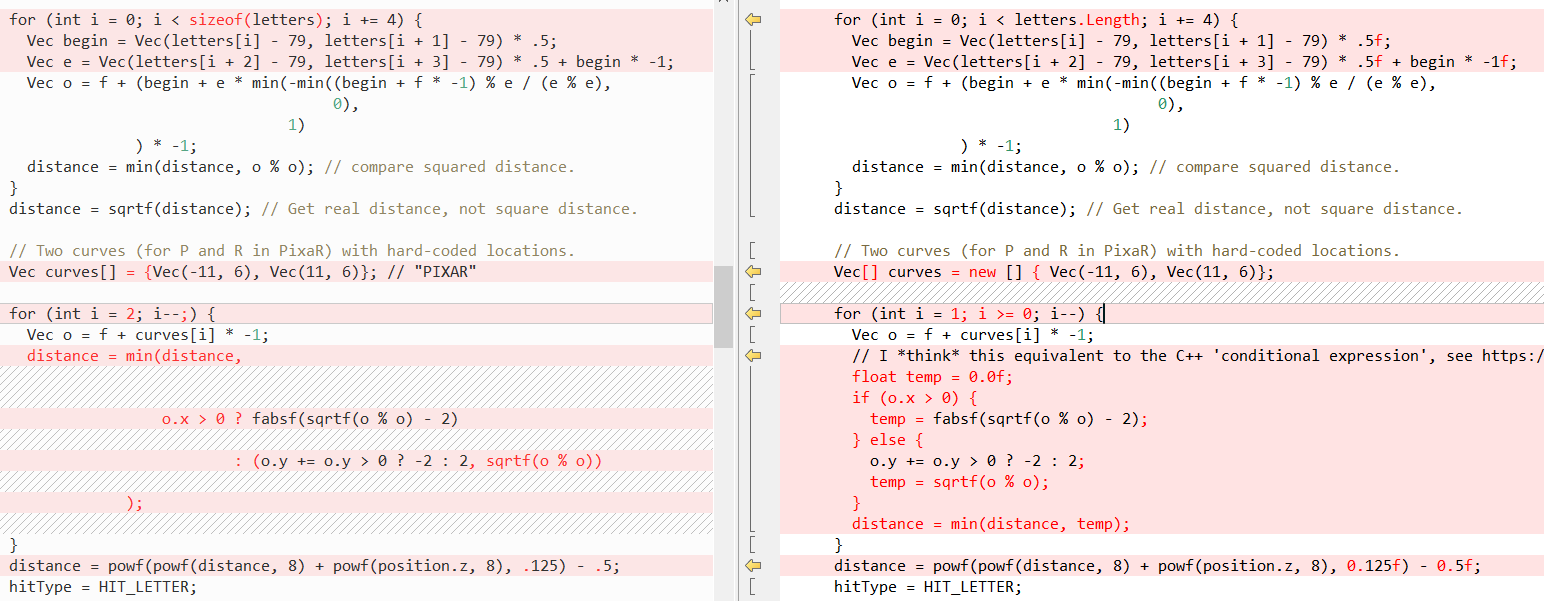
(voir l'article de
Fabian pour une explication de ce que font ces deux fonctions)
Mais encore une fois, le fait est que C # facilite l'écriture de code C ++! Dans ce cas, le mot-clé
ref nous aide le plus, ce qui nous permet de passer une
valeur par référence . Nous utilisons
ref dans les appels de méthode depuis un certain temps, mais récemment, des efforts ont été faits pour résoudre
ref ailleurs:
Parfois, l' utilisation de
ref améliore les performances, car la structure n'a alors pas besoin d'être copiée, voir les benchmarks dans le
post d'Adam Stinix et
«Performance traps ref locals and ref Returns in C #» pour plus d'informations.
Mais la chose la plus importante est qu'un tel script fournit à notre port C # le même comportement que le code source C ++. Bien que je tiens à noter que les soi-disant «liens gérés» ne sont pas tout à fait les mêmes que les «pointeurs», en particulier, vous ne pourrez pas effectuer d'arithmétique sur eux, voir plus à ce sujet ici:
Performances
Ainsi, le code était bien porté, mais les performances sont également importantes. Surtout dans le traceur de rayons, qui peut calculer la trame pendant plusieurs minutes. Le code C ++ contient la variable
sampleCount , qui contrôle la qualité d'image finale, avec
sampleCount = 2 comme suit:

Evidemment pas très réaliste!
Mais lorsque vous arrivez à
sampleCount = 2048 , tout semble
beaucoup mieux:

Mais commencer avec
sampleCount = 2048 prend
beaucoup de temps, donc toutes les autres exécutions sont effectuées avec une valeur de
2 afin de respecter au moins une minute. La modification de
sampleCount n'affecte que le nombre d'itérations de la boucle de code la plus externe, voir
cet élément essentiel pour une explication.
Résultats après un port de ligne «naïf»
Afin de comparer substantiellement C ++ et C #, j'ai utilisé l'outil de
fenêtres temporelles , c'est le port de la commande
time unix. Les premiers résultats ressemblaient à ceci:
| C ++ (VS 2017) | .NET Framework (4.7.2) | .NET Core (2.2) |
|---|
| Temps (sec) | 47,40 | 80.14 | 78.02 |
| Au cœur (sec) | 0,14 (0,3%) | 0,72 (0,9%) | 0,63 (0,8%) |
| Dans l'espace utilisateur (sec) | 43,86 (92,5%) | 73,06 (91,2%) | 70,66 (90,6%) |
| Nombre d'erreurs de défaut de page | 1143 | 4818 | 5945 |
| Ensemble de travail (Ko) | 4232 | 13 624 | 17 052 |
| Mémoire extrudée (Ko) | 95 | 172 | 154 |
| Mémoire non préemptive | 7 | 14 | 16 |
| Fichier d'échange (Ko) | 1460 | 10 936 | 11 024 |
Initialement, nous voyons que le code C # est légèrement plus lent que la version C ++, mais il s'améliore (voir ci-dessous).
Mais voyons d'abord ce que le JIT .NET nous fait même avec ce port ligne par ligne «naïf». Tout d'abord, il fait un bon travail d'intégration de méthodes d'assistance plus petites. Cela peut être vu dans la sortie de l'excellent outil
Inlining Analyzer (vert = intégré):
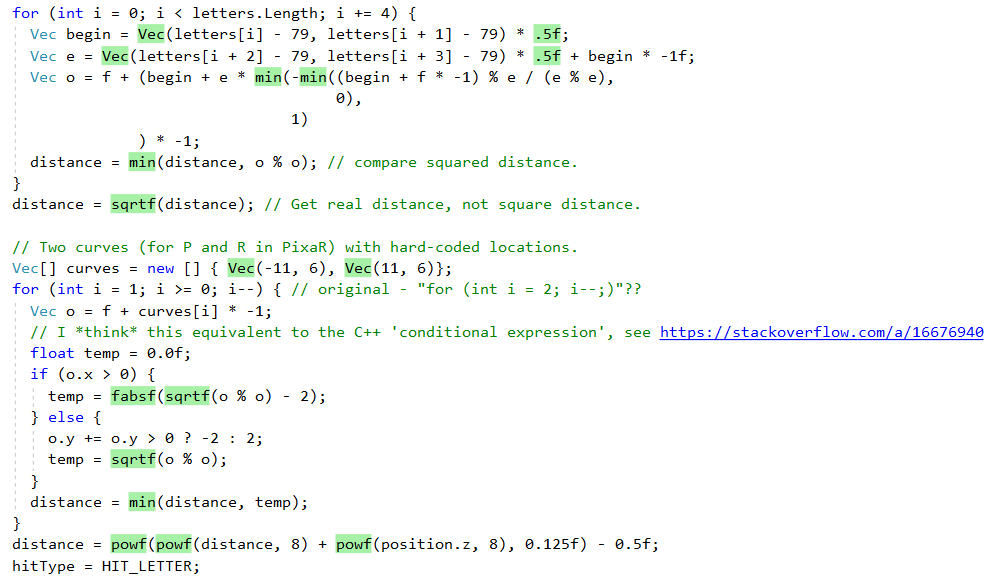
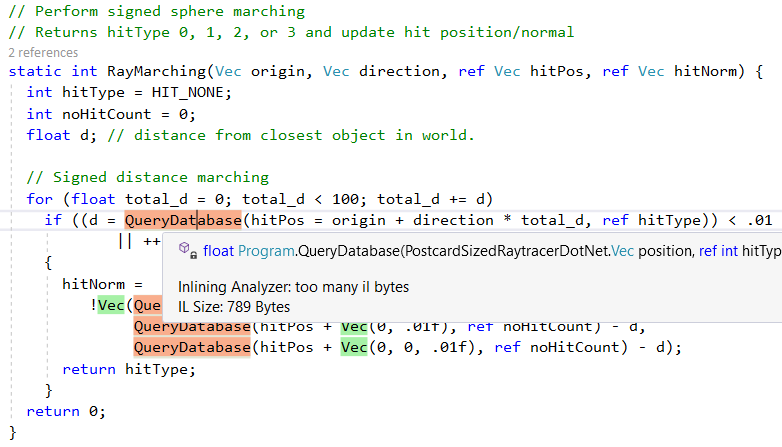
Cependant, il
QueryDatabase(..) pas toutes les méthodes, par exemple, en raison de la complexité,
QueryDatabase(..) ignoré:
Une autre fonctionnalité du compilateur .NET Just-In-Time (JIT) est la conversion d'appels de méthode spécifiques en instructions CPU correspondantes. Nous pouvons le voir en action avec la fonction shell
sqrt , voici le code source C # (notez l'appel à
Math.Sqrt ):
Et voici le code assembleur que le JIT .NET génère: il n'y a pas d'appel à
Math.Sqrt et l'instruction processeur
vsqrtsd est utilisée :
; Assembly listing for method Program:sqrtf(float):float ; Emitting BLENDED_CODE for X64 CPU with AVX - Windows ; Tier-1 compilation ; optimized code ; rsp based frame ; partially interruptible ; Final local variable assignments ; ; V00 arg0 [V00,T00] ( 3, 3 ) float -> mm0 ;# V01 OutArgs [V01 ] ( 1, 1 ) lclBlk ( 0) [rsp+0x00] "OutgoingArgSpace" ; ; Lcl frame size = 0 G_M8216_IG01: vzeroupper G_M8216_IG02: vcvtss2sd xmm0, xmm0 vsqrtsd xmm0, xmm0 vcvtsd2ss xmm0, xmm0 G_M8216_IG03: ret ; Total bytes of code 16, prolog size 3 for method Program:sqrtf(float):float ; ============================================================
(pour obtenir ce problème, suivez
ces instructions , utilisez le
module complémentaire "Disasmo" VS2019 ou consultez
SharpLab.io )
Ces remplacements sont également appelés
intrinsèques , et dans le code ci-dessous, nous pouvons voir comment le JIT les génère. Cet extrait montre le mappage pour
AMD64 uniquement, mais le JIT cible également
X86 ,
ARM et
ARM64 , la méthode complète
ici .
bool Compiler::IsTargetIntrinsic(CorInfoIntrinsics intrinsicId) { #if defined(_TARGET_AMD64_) || (defined(_TARGET_X86_) && !defined(LEGACY_BACKEND)) switch (intrinsicId) {
Comme vous pouvez le voir, certaines méthodes sont implémentées telles que
Sqrt et
Abs , tandis que d'autres utilisent des fonctions d'exécution C ++, par exemple,
powf .
L'ensemble de ce processus est très bien expliqué dans l'article
«Comment Math.Pow () est-il implémenté dans le .NET Framework?» , il peut également être vu dans la source CoreCLR:
Résultats après de simples améliorations de performances
Je me demande si vous pouvez immédiatement améliorer le port ligne par port naïf. Après quelques profils, j'ai fait deux changements majeurs:
- Suppression de l'initialisation de la matrice en ligne
- Remplacement des fonctions de
Math.XXX(..) par des analogues de MathF.()
Ces changements sont expliqués plus en détail ci-dessous.
Suppression de l'initialisation de la matrice en ligne
Pour plus d'informations sur la raison pour laquelle cela est nécessaire, consultez
cette excellente réponse Stack Overflow d'
Andrei Akinshin , ainsi que les
tests de performances et le code assembleur. Il arrive à la conclusion suivante:
Conclusion
- Est-ce que .NET met en cache les tableaux locaux codés en dur? Comme ceux qui mettent le compilateur Roslyn dans les métadonnées.
- Dans ce cas, il y aura des frais généraux? Malheureusement, oui: pour chaque appel, JIT copiera le contenu du tableau à partir des métadonnées, ce qui prend plus de temps par rapport à un tableau statique. Le runtime sélectionne également des objets et crée du trafic en mémoire.
- Y a-t-il lieu de s'inquiéter à ce sujet? C'est possible. S'il s'agit d'une méthode chaude et que vous souhaitez atteindre un bon niveau de performances, vous devez utiliser un tableau statique. S'il s'agit d'une méthode froide qui n'affecte pas les performances de l'application, vous devrez probablement écrire un «bon» code source et placer le tableau dans la zone de méthode.
Vous pouvez voir les modifications apportées dans
ce diff .
Utilisation des fonctions MathF au lieu des mathématiques
Deuxièmement, et surtout, j'ai considérablement amélioré les performances en apportant les modifications suivantes:
#if NETSTANDARD2_1 || NETCOREAPP2_0 || NETCOREAPP2_1 || NETCOREAPP2_2 || NETCOREAPP3_0
À partir de .NET Standard 2.1, des implémentations concrètes de fonctions mathématiques communes
float existent. Ils se trouvent dans la classe
System.MathF . Pour en savoir plus sur cette API et sa mise en œuvre, voir ici:
Après ces modifications, la différence dans les performances du code C # et C ++ a été réduite à environ 10%:
| C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON |
|---|
| Temps (sec) | 41,38 | 58,89 | 46.04 | 44,33 |
| Au cœur (sec) | 0,05 (0,1%) | 0,06 (0,1%) | 0,14 (0,3%) | 0,13 (0,3%) |
| Dans l'espace utilisateur (sec) | 41,19 (99,5%) | 58,34 (99,1%) | 44,72 (97,1%) | 44,03 (99,3%) |
| Nombre d'erreurs de défaut de page | 1119 | 4749 | 5776 | 5661 |
| Ensemble de travail (Ko) | 4136 | 13 440 | 16 788 | 16 652 |
| Mémoire extrudée (Ko) | 89 | 172 | 150 | 150 |
| Mémoire non préemptive | 7 | 13 | 16 | 16 |
| Fichier d'échange (Ko) | 1428 | 10 904 | 10 960 | 11 044 |
TC - compilation à plusieurs niveaux, compilation à plusieurs
niveaux (
je suppose qu'elle sera activée par défaut dans .NET Core 3.0)
Pour être complet, voici les résultats de plusieurs analyses:
| Exécuter | C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON |
|---|
| TestRun-01 | 41,38 | 58,89 | 46.04 | 44,33 |
| TestRun-02 | 41.19 | 57,65 | 46,23 | 45,96 |
| TestRun-03 | 42.17 | 62,64 | 46,22 | 48,73 |
Remarque : la différence entre le .NET Core et le .NET Framework est due à l'absence de l'API MathF dans le .NET Framework 4.7.2, pour plus d'informations, consultez
le ticket de support .Net Framework (4.8?) Pour netstandard 2.1 .
Augmentez encore la productivité
Je suis sûr que le code peut encore être amélioré!
Si vous souhaitez résoudre la différence de performances,
voici le code C # . À titre de comparaison, vous pouvez regarder le code assembleur C ++ de l'excellent service
Explorateur du compilateur .
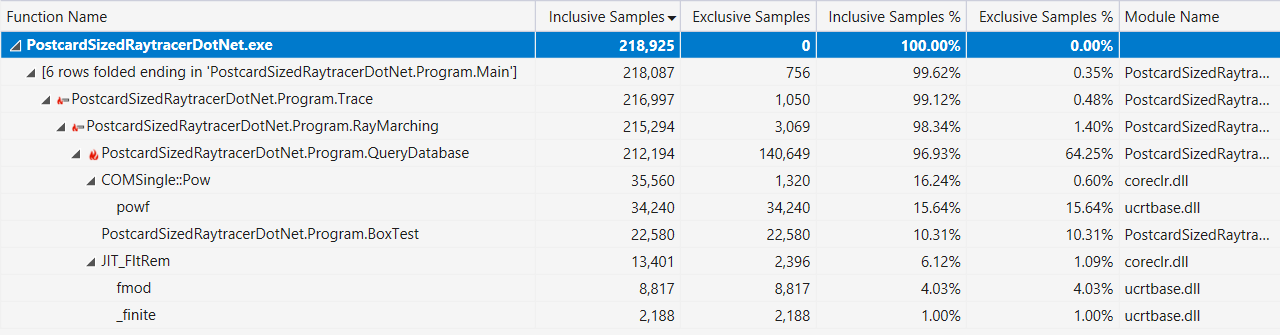
Enfin, si cela vous aide, voici la sortie du profileur Visual Studio avec un affichage «hot path» (après les améliorations de performances décrites ci-dessus):
C # est-il un langage de bas niveau?
Ou plus précisément:
Quelles fonctionnalités linguistiques de la fonctionnalité C # / F # / VB.NET ou BCL / Runtime signifient une programmation "de bas niveau" *?
* Oui, je comprends que «bas niveau» est un terme subjectif.
Remarque: chaque développeur C # a sa propre idée de ce qu'est le «bas niveau», ces fonctions seront prises pour acquises par les programmeurs C ++ ou Rust.
Voici la liste que j'ai faite:
- ref ref et locaux ref
- «Passer et retourner par référence pour éviter de copier de grandes structures. Les types et la mémoire sûrs peuvent être encore plus rapides que dangereux! »
- Code non sécurisé dans .NET
- «Le langage C # de base, tel que défini dans les chapitres précédents, est très différent de C et C ++ en ce qu'il manque de pointeurs comme type de données. Au lieu de cela, C # fournit des liens et la possibilité de créer des objets régis par le garbage collector. Cette conception, combinée à d'autres fonctionnalités, fait de C # un langage beaucoup plus sûr que C ou C ++. »
- Pointeurs gérés dans .NET
- «Il existe un autre type de pointeur dans le CLR - un pointeur géré. Il peut être défini comme un type de lien plus général qui peut pointer vers d'autres emplacements, et pas seulement vers le début de l'objet. »
- C # 7 Series, Part 10: Span <T> et Universal Memory Management
- «System.Span <T> est juste un type de pile (
ref struct ) qui enveloppe tous les modèles d'accès à la mémoire, c'est un type d'accès universel à la mémoire continue. Nous pouvons imaginer une implémentation Span avec une référence factice et une longueur qui accepte les trois types d'accès à la mémoire. "
- Compatibilité («Guide de programmation C #»)
- «Le .NET Framework fournit l'interopérabilité avec du code non managé via les services d'appel de plate-forme, l'
System.Runtime.InteropServices , la compatibilité C ++ et la compatibilité COM (interopérabilité COM).»
J'ai également lancé un cri sur Twitter et j'ai obtenu beaucoup plus d'options à inclure dans la liste:
- Ben Adams : «Outils intégrés pour les plates-formes (instructions CPU)»
- Mark Gravell : «SIMD via Vector (qui va bien avec Span) est * assez * bas; .NET Core devrait (bientôt?) Offrir des outils directement intégrés au CPU pour une utilisation plus explicite des instructions spécifiques du CPU »
- Mark Gravell : «JIT puissant: des choses comme l'élision de plage sur les tableaux / intervalles, ainsi que l'utilisation de règles per-struct-T pour supprimer les gros morceaux de code que JIT sait avec certitude qu'ils ne sont pas disponibles pour ce T ou sur votre spécifique CPU (BitConverter.IsLittleEndian, Vector.IsHardwareAccelerated, etc.) "
- Kevin Jones : «Je mentionnerais en particulier les classes
MemoryMarshal et Unsafe , et peut-être quelques autres choses dans les System.Runtime.CompilerServices »
- Theodoros Chatsigiannakis : «Vous pouvez également inclure
__makeref et le reste»
- damageboy : "La capacité de générer dynamiquement du code qui correspond exactement à l'entrée attendue, étant donné que cette dernière ne sera connue qu'au moment de l'exécution et pourra changer périodiquement?"
- Robert Hacken : "Emission dynamique d'IL"
- Victor Baybekov : «Stackalloc n'a pas été mentionné. Il est également possible d'écrire IL pur (non dynamique, donc il est enregistré sur un appel de fonction), par exemple, utilisez
ldftn mis en cache et appelez-les via calli . Il existe un modèle de projet dans VS2017 qui rend cela trivial en réécrivant les méthodes extern + MethodImplOptions.ForwardRef + ilasm.ex »
- Victor Baybekov : "MethodImplOptions.AggressiveInlining" active également la programmation de bas niveau "dans le sens où il vous permet d'écrire du code de haut niveau avec de nombreuses petites méthodes tout en contrôlant le comportement de JIT pour obtenir un résultat optimisé. Sinon, copiez-collez des centaines de méthodes LOC ... "
- Ben Adams : "En utilisant les mêmes conventions d'appel (ABI) que dans la plate-forme de base, et p / invoque pour l'interaction?"
- Victor Baibekov : «De plus, puisque vous avez mentionné #fsharp - il a un
inline - inline qui fonctionne au niveau IL jusqu'à JIT, donc il était considéré comme important au niveau de la langue. C # cela ne suffit pas (jusqu'à présent) pour les lambdas, qui sont toujours des appels virtuels, et les solutions de contournement sont souvent étranges (génériques limités) "
- Alexandre Mutel : «Nouveau SIMD embarqué, post-traitement de classe / IL d'Usafe Unsafe (par exemple, custom, Fody, etc.). Pour C # 8.0, les prochains pointeurs de fonction ... "
- Alexandre Mutel : «Concernant IL, F # supporte directement IL dans une langue par exemple»
- OmariO : « BinaryPrimitives . Niveau bas, mais sûr "
- Koji Matsui : «Et votre propre assembleur intégré? C'est difficile à la fois pour la boîte à outils et le runtime, mais il peut remplacer la solution p / invoke actuelle et implémenter le code intégré, le cas échéant "
- Frank A. Kruger : «Ldobj, stobj, initobj, initblk, cpyblk»
- Conrad Coconut : «Peut-être diffuser du stockage local? Tampons de taille fixe? Vous devriez probablement mentionner les contraintes non gérées et les types blittables :) »
- Sebastiano Mandala : «Juste un petit ajout à tout ce qui a été dit: que diriez-vous de quelque chose de simple, comme l'organisation des structures et comment le remplissage et l'alignement de la mémoire et de l'ordre des champs peuvent affecter les performances du cache? C'est quelque chose que je dois moi-même explorer. »
- Nino Floris : "Les constantes intégrées via readonlyspan, stackalloc, finaliseurs, WeakReference, délégués ouverts, MethodImplOptions, MemoryBarriers, TypedReference, varargs, SIMD, Unsafe.AsRef, peuvent définir les types de structures en conformité exacte avec la disposition (utilisée pour TaskAwaiter et sa version)".
Donc, à la fin, je dirais que C # vous permet certainement d'écrire du code qui ressemble à C ++, et en combinaison avec les bibliothèques d'exécution et de classe de base fournit beaucoup de fonctions de bas niveau.Lectures complémentaires
Compilateur Unity Burst: