Préface
Il y a un utilitaire tellement simple et très utile dans le monde -
BDelta , et il s'est avéré qu'il a pris racine dans notre processus de production pendant longtemps (bien que sa version ne puisse pas être installée, mais ce n'était certainement pas la dernière disponible). Nous l'utilisons pour sa destination - la construction de correctifs binaires. Si vous regardez ce qui se trouve dans le référentiel, cela devient un peu triste: en fait, il a été abandonné il y a longtemps et beaucoup y était très dépassé (une fois que mon ancien collègue y a fait plusieurs corrections, mais c'était il y a longtemps). En général, j'ai décidé de ressusciter cette entreprise: j'ai bifurqué, jeté ce que je n'avais pas l'intention d'utiliser, dépassé le projet sur
cmake , intégré les microfonctions «chaudes», retiré les grands tableaux de la pile (et les tableaux de longueur variable, dont j'ai «bombardé» franchement) , a une fois de plus conduit le profileur - et a découvert qu'environ 40% du temps est consacré à l'
écriture ...
Alors quoi de neuf avec fwrite?
Dans ce code, fwrite (dans mon cas de test particulier: création d'un patch entre des fichiers de 300 Mo proches, les données d'entrée sont complètement en mémoire) est appelé des millions de fois avec un petit tampon. De toute évidence, cette chose va ralentir, et donc je voudrais en quelque sorte influencer cette honte. Il n'y a aucune envie d'implémenter tout type de sources de données, entrée-sortie asynchrone, je voulais trouver une solution plus simple. La première chose qui m'est venue à l'esprit était d'augmenter la taille du tampon
setvbuf(file, nullptr, _IOFBF, 64* 1024)
mais je n'ai pas obtenu une amélioration significative du résultat (maintenant l'écriture représente environ 37% du temps) - cela signifie que le problème n'est toujours pas dans l'enregistrement fréquent des données sur le disque. En regardant fwrite «sous le capot», vous pouvez voir que la structure de verrouillage / déverrouillage du fichier se produit à l'intérieur comme ceci (pseudo-code, toute l'analyse a été effectuée sous Visual Studio 2017):
size_t fwrite (const void *buffer, size_t size, size_t count, FILE *stream) { size_t retval = 0; _lock_str(stream); __try { retval = _fwrite_nolock(buffer, size, count, stream); } __finally { _unlock_str(stream); } return retval; }
Selon le profileur, _fwrite_nolock ne représente que 6% du temps, le reste est en surcharge. Dans mon cas particulier, la sécurité des threads est un excès évident, je vais la sacrifier en remplaçant l'appel
fwrite par
_fwrite_nolock - même avec des arguments que je n'ai pas besoin d'être
intelligent . Total: cette simple manipulation a parfois réduit le coût d'enregistrement du résultat, qui dans la version originale représentait presque la moitié du temps. Soit dit en passant, dans le monde POSIX, il existe une fonction similaire -
fwrite_unlocked . D'une manière générale, il en va de même pour l'effroi. Ainsi, avec l'aide de la paire #define, vous pouvez vous procurer une solution multiplateforme sans verrous inutiles s'ils ne sont pas nécessaires (et cela se produit assez souvent).
fwrite, _fwrite_nolock, setvbuf
Abandonnons le projet d'origine et commençons à tester un cas spécifique: l'enregistrement d'un gros fichier (512 Mo) en portions extrêmement petites - 1 octet. Système de test: AMD Ryzen 7 1700, 16 Go de RAM, disque dur 3,5 "7200 tr / min 64 Mo de cache, Windows 10 1809, le binaire a été construit en 32 bits, des optimisations sont incluses, la bibliothèque est liée statiquement.
Échantillon pour l'expérience:
#include <chrono> #include <cstdio> #include <inttypes.h> #include <memory> #ifdef _MSC_VER #define fwrite_unlocked _fwrite_nolock #endif using namespace std::chrono; int main() { std::unique_ptr<FILE, int(*)(FILE*)> file(fopen("test.bin", "wb"), fclose); if (!file) return 1; constexpr size_t TEST_BUFFER_SIZE = 256 * 1024; if (setvbuf(file.get(), nullptr, _IOFBF, TEST_BUFFER_SIZE) != 0) return 2; auto start = steady_clock::now(); const uint8_t b = 77; constexpr size_t TEST_FILE_SIZE = 512 * 1024 * 1024; for (size_t i = 0; i < TEST_FILE_SIZE; ++i) fwrite_unlocked(&b, sizeof(b), 1, file.get()); auto end = steady_clock::now(); auto interval = duration_cast<microseconds>(end - start); printf("Time: %lld\n", interval.count()); return 0; }
Les variables seront TEST_BUFFER_SIZE, et pour quelques cas, nous remplacerons fwrite_unlocked par fwrite. Commençons par le cas de fwrite sans définir explicitement la taille du buffer (commentez setvbuf et le code associé): temps 27048906 μs, vitesse d'écriture - 18,93 Mb / s. Réglez maintenant la taille de la mémoire tampon à 64 Ko: temps - 25037111 μs, vitesse - 20,44 Mo / s. Maintenant nous testons le fonctionnement de _fwrite_nolock sans appeler setvbuf: 7262221 ms, la vitesse est de 70,5 Mb / s!
Ensuite, testez la taille du tampon (setvbuf):
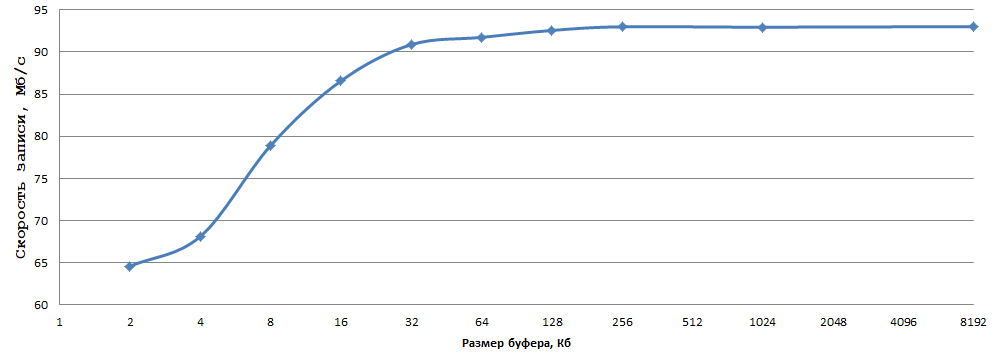
Les données ont été obtenues en moyenne 5 expériences, j'étais trop paresseux pour considérer les erreurs. Quant à moi, 93 Mo / s lors de l'écriture d'un octet sur un disque dur normal est un très bon résultat, il suffit de sélectionner la taille de tampon optimale (dans mon cas 256 Ko - juste à droite) et de remplacer fwrite par _fwrite_nolock / fwrite_unlocked (dans si la sécurité du fil n'est pas nécessaire, bien sûr).
De même avec effroi dans des conditions similaires. Voyons maintenant comment ça se passe sous Linux, la configuration de test est la suivante: AMD Ryzen 7 1700X, 16 Go de RAM, HDD 3,5 "7200 tr / min 64 Mo de cache, OpenSUSE 15 OS, GCC 8.3.1, nous allons tester x86-64 binar, système de fichiers sur section de test ext4 Le résultat de fwrite sans définir explicitement la taille de la mémoire tampon dans ce test est de 67,6 Mb / s, lors de la définition de la mémoire tampon à 256 Ko, la vitesse a augmenté à 69,7 Mb / s. Nous allons maintenant effectuer des mesures similaires pour fwrite_unlocked - les résultats sont respectivement de 93,5 et 94,6 Mb / s. Faire varier la taille du tampon de 1 Ko à 8 Mo m'a conduit aux conclusions suivantes: l'augmentation du tampon augmente la vitesse d'écriture, mais la différence dans mon cas n'était que de 3 Mb / s, je n'ai pas du tout remarqué de différence de vitesse entre la mémoire tampon de 64 Ko et 8 Mo. A partir des données reçues sur cette machine Linux, nous pouvons tirer les conclusions suivantes:
- fwrite_unlocked est plus rapide que fwrite, mais la différence de vitesse d'écriture n'est pas aussi grande que sur Windows
- La taille de la mémoire tampon sous Linux n'a pas d'effet aussi significatif sur la vitesse d'écriture via fwrite / fwrite_unlocked que sous Windows
Au total, la méthode proposée est efficace à la fois sur Windows, mais aussi sur Linux (quoique dans une bien moindre mesure).
Postface
Le but de cet article était de décrire une technique simple et efficace dans de nombreux cas (je n'ai pas rencontré les fonctions _fwrite_nolock / fwrite_unlocked plus tôt, elles ne sont pas très populaires - mais en vain). Je ne prétends pas être nouveau dans le matériel, mais j'espère que l'article sera utile à la communauté.