La chose la plus importante pour le service Yandex.Zen est de développer et de maintenir une plate-forme qui relie le public aux auteurs. Pour être une plate-forme attrayante pour les bons auteurs, Zen doit être en mesure de trouver un public pertinent pour les chaînes écrivant sur n'importe quel sujet, y compris le plus étroit. Le chef du groupe de bonheur des auteurs Boris Sharchilev a parlé du classement autocentrique, qui sélectionne les utilisateurs les plus pertinents pour les auteurs. À partir du rapport, vous pouvez découvrir en quoi cette approche diffère de la sélection des éléments pertinents - plus populaire dans les systèmes de recommandation.
En équilibrant le classement centré sur l'utilisateur et le centrage automatique, nous pouvons atteindre le bon équilibre entre le bonheur des utilisateurs et le bonheur des auteurs.
- Chers collègues, bonjour à tous. Je m'appelle Borya. Je m'occupe de la qualité du classement en Zen. Je suis sûr que c'est l'un des services Yandex les plus intéressants, nous avons un apprentissage machine très cool, et dans les 17 prochaines minutes, je vais essayer de vous en convaincre.
Qu'est-ce que le Zen? S'il est assez simple, Zen est un service de recommandation personnalisé. Nous essayons de recommander aux utilisateurs un contenu pertinent en fonction de ce que nous savons des intérêts de ces utilisateurs. Notre objectif de haut niveau est que les utilisateurs passent du temps dans le Zen. Et ce qui est très important, c'est qu'ils ne regrettent pas cette fois.
Notre forme de base de consommation de contenu ressemble à ceci. Il s'agit d'un flux infini de recommandations. Et ici, il est clair que nous, en principe, essayons de recommander des documents très sur des sujets très différents. Il y a différents sujets: quelque chose sur les affaires, quelque chose sur l'humour, même quelque chose sur la fantaisie. Autrement dit, dans la bande, vous pouvez trouver des articles éducatifs et éducatifs, ainsi que des articles plus divertissants. Et, bien sûr, la personnalisation. Le flux Zen pour tout le monde est différent - selon ce qui intéresse l'utilisateur. De plus, bien sûr, un peu de publicité.

Un point très important. Au tout début, lorsque nous sommes apparus pour la première fois, nous étions en fait un agrégateur de contenu sur Internet. Autrement dit, nous avons fait le tour des sites existants, leur avons pris du contenu et l'avons montré à l'utilisateur en fonction de ses intérêts. Maintenant, la situation est différente. Maintenant, Zen est une plate-forme de blogs sur laquelle tout le monde peut créer sa propre chaîne, que ce soit un blogueur célèbre ou un auteur novice qui a quelque chose à dire. Les nouveaux auteurs voient un écran de bienvenue si agréable dans lequel nous parlons du service - que Zen lui-même sélectionnera un public, et il n'a qu'à écrire de bons documents.
Désormais, la plateforme représente plus de la moitié du trafic total dans Zen. Et ce chiffre ne fera que croître. Nous comprenons que tout le monde peut classer le contenu existant. Bien sûr, nous le ferons mieux que tout. Mais tout le monde n'a pas un contenu unique, et nous pensons que ce sera notre avantage concurrentiel.

Il est important de comprendre que le Zen est déjà très grand. Selon Yandex.Radar, à la fin de l'année dernière, nous avions environ 10-12 millions de lecteurs quotidiens par jour, environ 35 millions de lecteurs quotidiens, et même selon certaines données de Yandex.Radar, nous avons l'année dernière Pour la première fois, ils ont fait le tour du public de Yandex.News. Cela signifie que nous faisons Internet avec sérieux, nous avons des tâches très sérieuses, il y en a beaucoup et nous attendons avec impatience votre aide.
Parlons des détails de son fonctionnement et discutons de ce que nous pouvons faire avec un stagiaire, de la façon dont nous pouvons aider notre service.
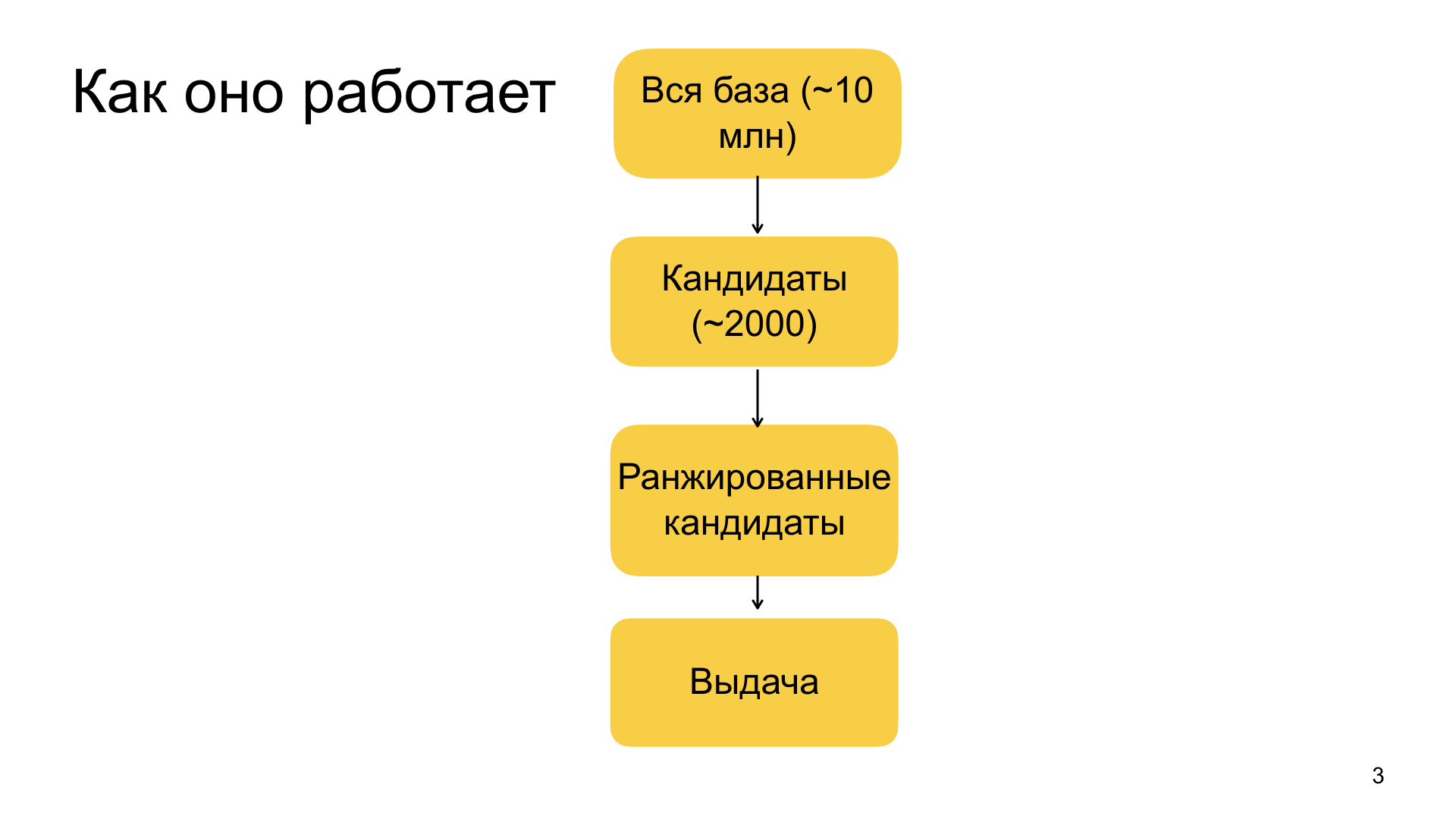
L'aperçu général des recommandations que nous avons est organisé comme suit. Tout commence par notre grande base de données de documents à partir de laquelle nous sélectionnons des matériaux pour des recommandations. Il se compose de dizaines de millions de documents. De plus, cette base de données est constamment renouvelée - environ un million de nouveaux documents y arrivent quotidiennement. Idéalement, nous aimerions appliquer l'intégralité de notre machine d'apprentissage automatique à toutes ces dizaines de millions de documents personnellement pour chaque utilisateur, et choisir le plus pertinent pour lui. Mais, malheureusement, cela ne fonctionne pas dans la pratique, car le Zen est un service qui fonctionne en temps réel. Nous avons des garanties très strictes sur la rapidité avec laquelle nous sommes prêts à répondre.Par conséquent, pour des raisons pratiques, nous sommes obligés de réduire la base de dizaines de millions de documents à des milliers de recommandations potentielles au premier stade, que nous pouvons déjà classer complètement avec notre modèle et choisir les plus pertinentes. Cette étape de réduction de la base de dizaines de millions à environ des milliers est appelée sélection des candidats ou classement facile.
Lorsque nous avons ce kit, nous lui appliquons notre grand modèle d'apprentissage automatique complexe, qui au niveau supérieur est le renforcement du gradient. Tout cela est sans surprise, mais nous avons des facteurs très divers - de simples qui caractérisent, par exemple, la pertinence du domaine pour l'utilisateur, la source, la fréquence à laquelle il visite, clique, laisse des commentaires, aime et n'aime pas. Il en va de même des facteurs plus complexes qui sont basés, par exemple, sur les caractéristiques du réseau neuronal. Nous traitons le texte de l'article, nous traitons des images, d'autres sources de données et nous utilisons également de telles fonctionnalités composites. Tout ce schéma est assez compliqué, je n'aurai pas le temps de vous le dire en détail.
Après avoir classé nos 2 000 candidats, nous sélectionnons le top parmi eux. La taille du haut dépend de combien nous avons besoin de recommander des matériaux. Il est toujours défini différemment. Et c'est ainsi que nous formons le dernier numéro.
Voilà à quoi ressemble le circuit à un niveau élevé. Parlons maintenant des composants de l'ensemble du processus que nous souhaitons améliorer.

Il s'avère que nous voulons faire à peu près tout. Il y a beaucoup de tâches. Nous voulons augmenter la vitesse de livraison des données pour le classement: plus nous avons de données récentes, plus nous formulons de recommandations pertinentes. Je veux accélérer le service: plus nous travaillons vite, meilleure est l'expérience utilisateur. Nous voulons augmenter la fiabilité du service.
Il est important pour nous d'améliorer le classement. Autrement dit, nous devons appliquer de nouveaux modèles d'apprentissage automatique et améliorer nos modèles actuels dans d'autres pays. Nous sommes recommandés non seulement en Russie, mais aussi dans de nombreux autres pays du monde.
Nous voulons également prendre en compte la régionalité et recommander aux gens le contenu qui se rapporte à leur région.
Et c'est très important - nous devons développer notre plateforme de création. C'est notre avenir, nous devons y investir. Il y a aussi beaucoup de tâches. En particulier, nous devons être capables de trouver et de lancer un contenu de qualité. Il est important pour nous de montrer de bons matériaux, pas des déchets. Nous devons être en mesure de classer les nouveaux formats de contenu. Nous avons non seulement des articles, mais aussi de courtes vidéos et des publications que les utilisateurs regardent directement dans le flux. Tous ces formats doivent pouvoir être classés.
Et un point très important, dont je veux parler un peu plus en détail dans des détails plus techniques - il est important pour nous de pouvoir pour chaque auteur trouver un public qui lui soit pertinent, même s'il s'agit d'auteurs et de sujets de niche. Voyons plus en détail quel est le problème ici et comment nous le résolvons.
Regardons un exemple.
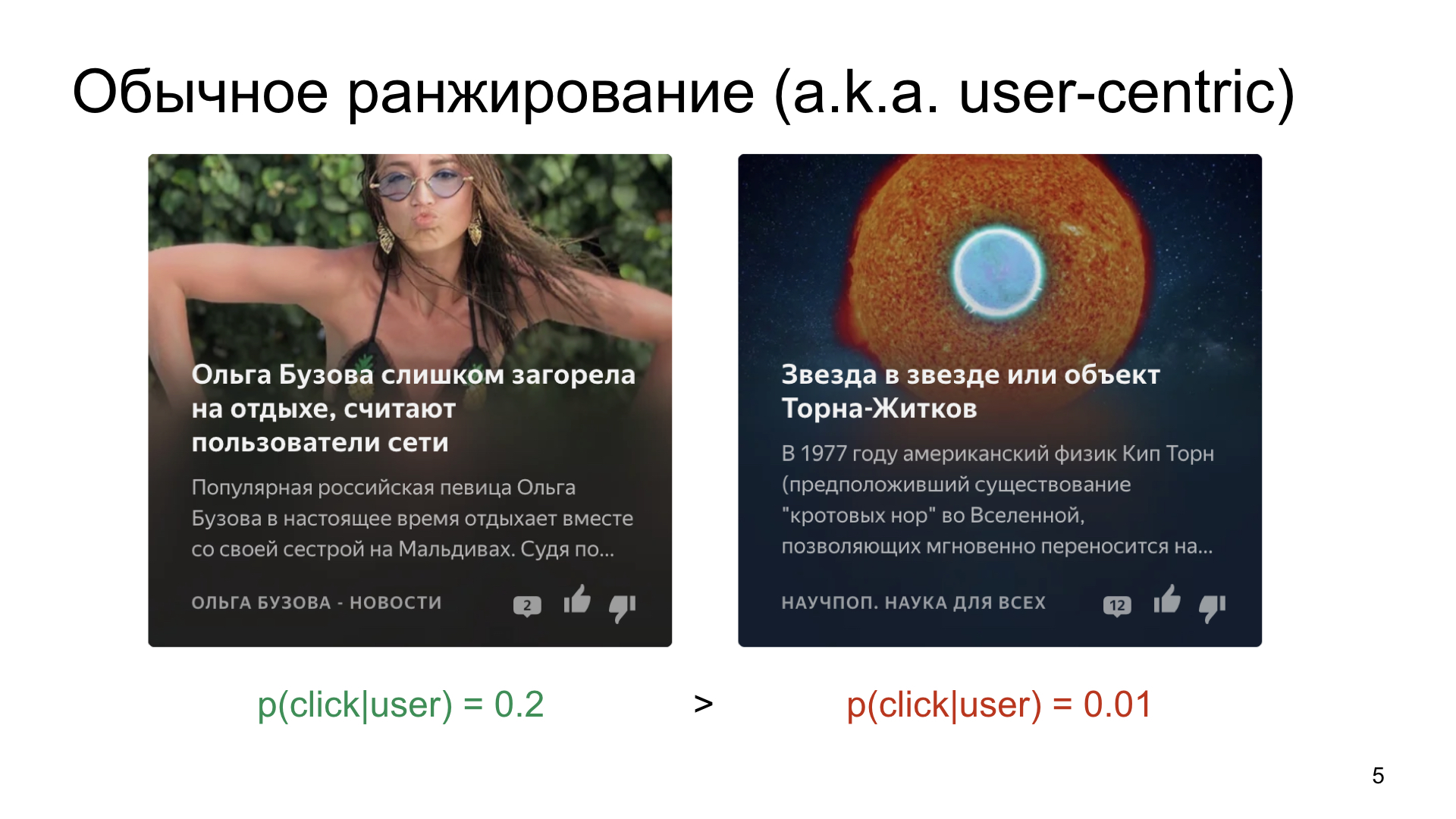
Nous sélectionnons, supposons, parmi deux cartes que nous voulons montrer à l'utilisateur.
C'est ainsi que le monde fonctionne et la façon dont les gens travaillent, qu'il y a quelque chose de plus moyen, où la probabilité d'un clic est en moyenne de 20%, et il y a quelque chose de plus de niche, par exemple, des articles sur la science ou sur l'espace.
Si nous classons simplement les cartes en fonction de la probabilité d'un clic, alors, bien sûr, un contenu plus cliquable et plus simple collectera un très grand nombre d'impressions, et même un très bon article sur la science ne le fera pas. Bien sûr, nous n'en voulons pas. Nous voulons trouver des publics intéressés, même pour des chaînes de niche.

Pourquoi voulez-vous faire ça? En fait, il y a deux raisons. Le premier est l'épicerie. Autrement dit, nous voulons que le Zen soit une sorte de coupure d'Internet. Pour que tout ce que l'utilisateur peut trouver et ce qui l'intéresse sur le grand Internet soit présenté en Zen. Et pour qu'il reçoive ce qui l'intéresse.
Les chaînes scientifiques ont leur propre public. Mais il y a une telle nuance. Si les amateurs de science affichent un contenu scientifique et populaire, ils sont plus susceptibles de cliquer dessus que sur la science. Mais si vous ne leur montrez que de la science, ils cliqueront également sur la science, et ils ne le regretteront même pas. La question est de savoir comment trouver de telles personnes et comment afficher du contenu, en se concentrant non pas sur l'utilisateur, mais sur l'auteur.

Comment faire La formule de classement habituelle, qui prédit la probabilité de clics, ne nous aidera pas ici, car en moyenne, plus d'articles de niche perdront. Mais vous pouvez aller dans l'autre sens - allouer un certain quota, et en cela donner plus ou moins uniformément des impressions aux auteurs, leur donner une sorte de garantie minimale. Cela peut être fait, et cela rendra les auteurs un peu plus heureux, mais, malheureusement, cela rendra nos utilisateurs moins heureux. Les utilisateurs cliqueront moins, seront plus contrariés et partiront. Bien sûr, nous ne voulons pas cela.
Comment être ici?
Nous avons longuement réfléchi et avons trouvé un nouveau concept. Nous l'avons appelé classements ou impressions autocentriques pour l'auteur.
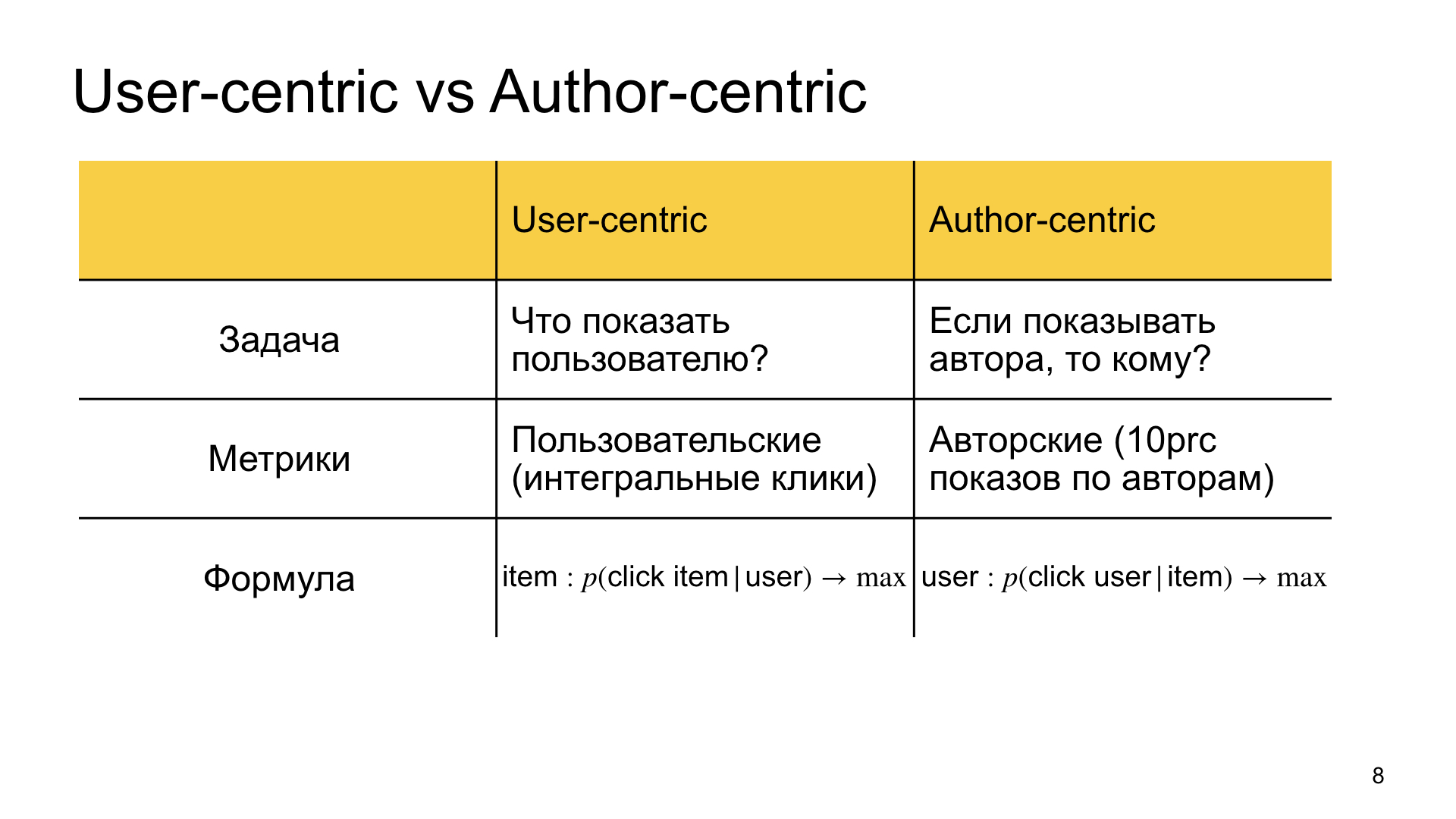
Quel est notre objectif dans le classement régulier, que nous appelons uscentrique? Trouvez le matériel le plus pertinent pour l'utilisateur. Nous répondons à la question de ce qu'il faut montrer à l'utilisateur.
Dans le classement autocentrique, nous renversons en quelque sorte l'énoncé du problème et disons que nous voulons montrer à cet auteur, et la question est de savoir à qui le montrer, à qui il est le plus pertinent. D'où la différence de métrique. Dans le premier cas, nous nous intéressons davantage aux mesures personnalisées, c'est-à-dire aux clics intégraux, au temps intégral dans Zen, etc. Dans le second cas, nous nous intéressons aux métriques dites d'auteur. Par exemple, nous mesurons dans quelle mesure le Zen vit, par exemple, les 10% des derniers auteurs. S'ils vivent assez bien, alors tout le monde est content aussi.

Comment fait-on cela? Supposons que nous ayons la formule de classement habituelle. Pour simplifier, supposons qu'il prédit la probabilité qu'un utilisateur clique sur un élément donné, sur une carte donnée. Que ferons-nous? Corrigeons-le maintenant pour chaque article et appliquons notre modèle pour cet article, idéalement - à tous les utilisateurs, en pratique - à une sorte d'échantillon d'utilisateur. Et nous allons construire une distribution de nos scores, c'est-à-dire des estimations de la probabilité de cliquer sur un article, pour chaque article par les utilisateurs. Maintenant, pour chaque article, nous avons une telle distribution que sur le graphique (diapositive ci-dessus - environ Ed.). Après cela, nous classerons les articles pour l'utilisateur et sélectionnerons le sommet non seulement par la probabilité d'un clic, mais par le centile dans lequel cet utilisateur tombe pour cet article. Autrement dit, nous estimons la probabilité d'un clic, voyons où l'utilisateur se situe dans cette distribution et organisons en fonction de cette valeur.

Ici, nous avons les mêmes deux cartes, l'une d'elles est plus cliquable, 20%, l'autre - moins de 1%. Maintenant, si vous prenez un utilisateur spécifique, une telle situation est possible qu'il a une chance de cliquer sur une carte plus populaire que sur une carte moins populaire, disons 10% contre 3%. Mais comme la probabilité moyenne d'un clic sur une carte populaire est de 20% et que l'utilisateur en a 10%, il est en moyenne moins pertinent pour cette publication que l'utilisateur zen moyen. Et dans une autre situation, l'inverse: il a 3% de chances de cliquer, mais l'article moyen a 1%. Par conséquent, il s'agit d'un public moyen plus pertinent pour l'article que les autres utilisateurs Zen. Par conséquent, l'idée clé ici est que même si la probabilité d'un clic sur un article est moindre, avec l'aide d'un tel cadre, nous avons la possibilité d'afficher un article moins populaire si l'utilisateur est dans le noyau le plus fiable pour cette publication.

Si les utilisateurs viennent à nous plus ou moins uniformément, alors le score donné par lequel nous nous classons, c'est-à-dire le centile dans lequel chaque utilisateur atterrit, sera distribué également entre les utilisateurs. Cela signifie que si tous les articles sont classés de cette manière, ils collecteront tous plus ou moins le même nombre d'impressions. Il n'y aura pas d'émissions de dizaines de millions d'impressions par rapport à 10 impressions de certaines cartes moins pertinentes. Ainsi, en équilibrant le classement centré sur l'utilisateur et le centrage automatique, nous pouvons atteindre le rapport entre le bonheur des utilisateurs et le bonheur des auteurs que nous considérons comme correct.
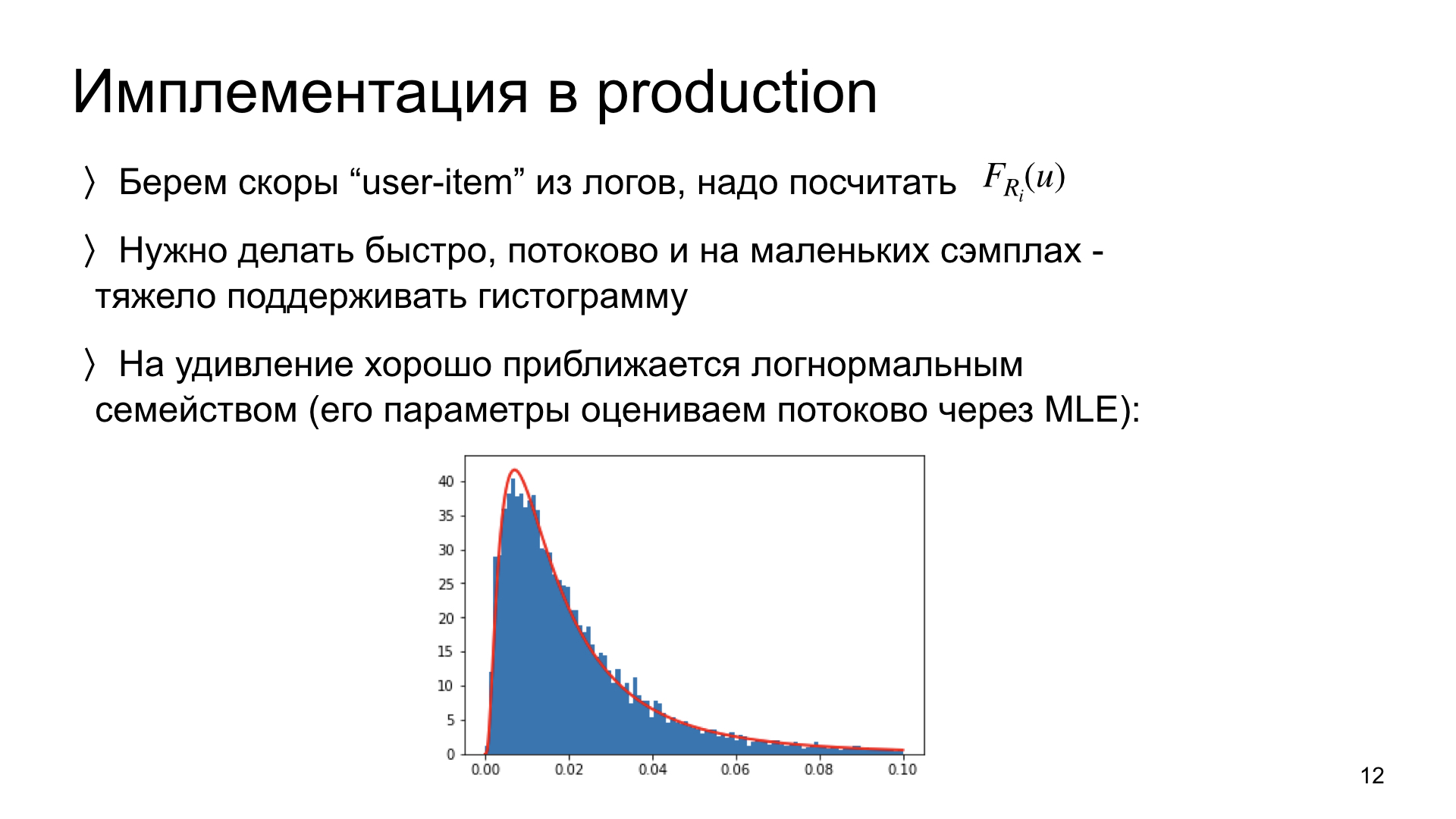
Quelques mots sur la façon dont nous implémentons cela en production. Nous devons consulter nos journaux et calculer la distribution de chaque article à partir d'eux. Une limitation importante: nous devons pouvoir le faire, d'une part, rapidement et d'autre part, en mode streaming. C'est-à-dire, idéalement, afin de mettre à jour l'estimation de distribution pour les nouvelles données, nous devons avoir en mémoire non pas toutes les données précédentes, mais seulement l'estimation actuelle. Un tel système est évolutif, un tel schéma fonctionne. Idéalement, nous devons pouvoir le faire sur de petites données. Si un article ne contient que 300 impressions, nous devons être en mesure d'estimer correctement la distribution d'un tel nombre d'observations.
Nous avons mené des expériences et constaté que ces distributions de scores sont étonnamment proches des distributions log-normales. Autrement dit, il s'agit d'une observation empirique. Et si c'est le cas, alors au lieu d'estimer l'histogramme entier de la distribution de manière non paramétrique, nous ne pouvons évaluer que deux paramètres de cette distribution. Et nous pouvons le faire dans le flux, en utilisant uniquement l'estimation des paramètres actuels et de nouvelles observations. Un tel schéma est très rapide et fonctionne très bien. Maintenant, elle est en production avec nous.
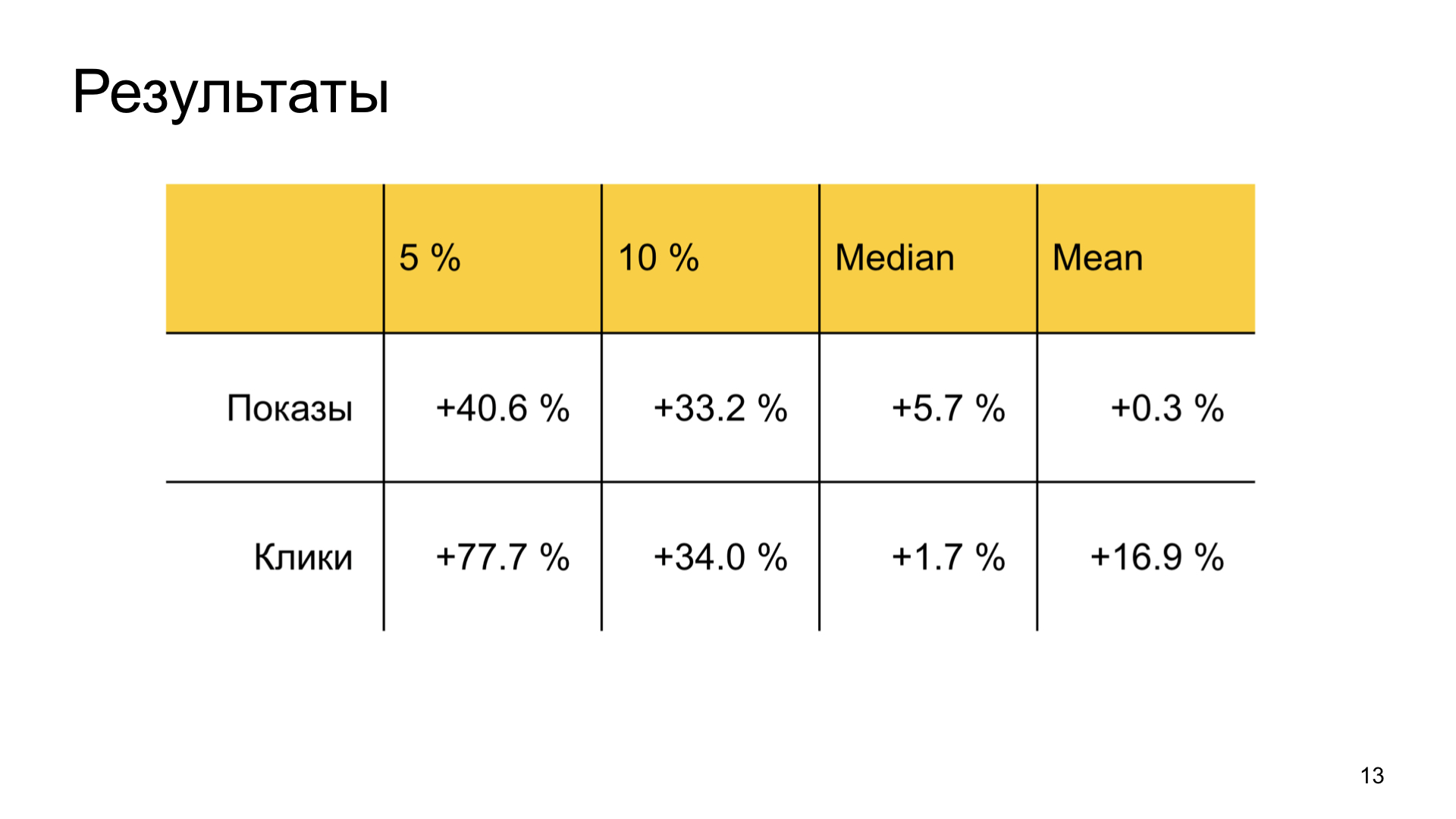
Les résultats sont également bons. Nous augmentons considérablement le bonheur des bons auteurs négligés dans Zen et ne gaspillons pas les métriques utilisateur courantes. Autrement dit, la tâche commerciale est entièrement accomplie.
J'ai maintenant montré l'un des exemples de tâches que nous pouvons traiter. Bien sûr, il y a beaucoup de ces tâches, et pour chacune d'elles, nous avons besoin de votre aide. Nous espérons vraiment que vous voudrez
travailler avec nous . Au final, je dirai quelques mots sur ce que nous attendons des stagiaires et ce que nous n’attendons pas d’eux. Du stagiaire, nous attendons la chose la plus importante - la capacité d'écrire du code. Nous n'avons pas de purs scientifiques au service. Nous sommes tous des ingénieurs ML, ils doivent être capables de faire le cycle complet des tâches. Ils doivent pouvoir et implémenter leur solution en production, et appliquer le ML. Autrement dit, nous nous attendons à ce que vous puissiez écrire du code à un niveau de base, comprendre les approches, connaître les algorithmes, les structures de données, les bases de l'apprentissage automatique.
Qu'attendons-nous des stagiaires? Tout d'abord, nous ne nous attendons pas à une connaissance approfondie des langages ou des frameworks. Autrement dit, si vous ne savez pas comment fonctionnent les coroutines en Python - ça va, nous vous apprendrons tout. Et nous n'attendons pas beaucoup d'expérience de votre part. Nous attendons de vous des connaissances, une envie de travailler. S'il n'y a pas d'expérience, ça va. Nous enseignerons tout et tout ira bien. Je vous remercie!