Pour ceux qui sont trop paresseux pour tout lire: une réfutation de sept mythes populaires est suggérée, ce qui dans le domaine de la recherche en machine learning est souvent considéré comme vrai, à partir de février 2019. Cet article est disponible sur
le site ArXiv au format pdf [en anglais].
Mythe 1: TensorFlow est une bibliothèque de tenseurs.
Mythe 2: Les bases de données d'images reflètent de vraies photos trouvées dans la nature.
Mythe 3: Les chercheurs en MO n'utilisent pas de kits de test pour les tests.
Mythe 4: la formation au réseau neuronal utilise toutes les données d'entrée.
Mythe 5: La normalisation des lots est nécessaire pour entraîner des réseaux résiduels très profonds.
Mythe 6: Les réseaux avec attention valent mieux que la convolution.
Mythe 7: Les cartes de signification sont un moyen fiable d'interpréter les réseaux de neurones.
Et maintenant pour les détails.
Mythe 1: TensorFlow est une bibliothèque de tenseurs
En fait, c'est une bibliothèque pour travailler avec des matrices, et cette différence est très importante.
Dans le
calcul de dérivés d'ordre supérieur d'expressions matricielles et tensorielles. Laue et al. Les auteurs de
NeurIPS 2018 démontrent que leur bibliothèque de différenciation automatique, basée sur un calcul tensoriel réel, a des arbres d'expression beaucoup plus compacts. Le fait est que le calcul tensoriel utilise la notation d'index, ce qui vous permet de travailler également avec les modes direct et inverse.
La numérotation matricielle masque les indices pour faciliter la notation, c'est pourquoi les arbres d'expression de différenciation automatique deviennent souvent trop complexes.
Considérons la multiplication matricielle C = AB. Nous avons
pour le mode direct et
pour le contraire. Pour effectuer correctement la multiplication, vous devez respecter strictement l'ordre et l'utilisation de la césure. Du point de vue de l'enregistrement, cela semble déroutant pour une personne impliquée dans MO, mais du point de vue des calculs, c'est une charge supplémentaire pour le programme.
Un autre exemple, moins trivial: c = det (A). Nous avons
pour le mode direct et
pour le contraire. Dans ce cas, il est évidemment impossible d'utiliser l'arbre d'expression pour les deux modes, étant donné qu'ils sont constitués d'opérateurs différents.
En général, la façon dont TensorFlow et d'autres bibliothèques (par exemple, Mathematica, Maple, Sage, SimPy, ADOL-C, TAPENADE, TensorFlow, Theano, PyTorch, HIPS autograd) ont implémenté la différenciation automatique, ce qui conduit au fait que pour le direct et le reverse Des arborescences d'expression différentes et inefficaces sont construites dans le mode. La numérotation des tenseurs contourne ces problèmes en raison de la commutativité de la multiplication due à la notation d'index. Pour plus de détails sur la façon dont cela fonctionne, voir l'article scientifique.
Les auteurs ont testé leur méthode en effectuant une différenciation automatique du régime inverse, également connu sous le nom de rétropropagation, dans trois tâches différentes, et ont mesuré le temps nécessaire pour calculer les Hessians.

Dans le premier problème, la fonction quadratique x
T Ax a été optimisée. Dans la seconde, la régression logistique a été calculée, dans la troisième - factorisation matricielle.
Sur le CPU, leur méthode s'est avérée être deux ordres de grandeur plus rapide que des bibliothèques populaires telles que TensorFlow, Theano, PyTorch et HIPS autograd.
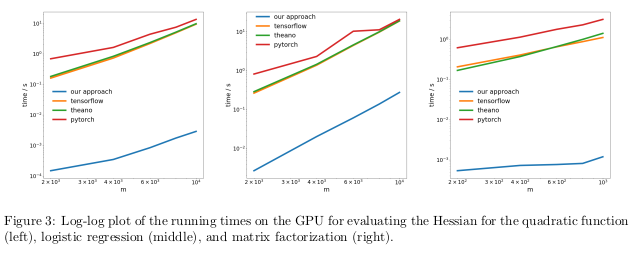
Sur le GPU, ils ont observé une accélération encore plus grande, jusqu'à trois ordres de grandeur.
Les conséquences:Calculer des dérivées pour des fonctions du second ordre ou plus à l'aide des bibliothèques d'apprentissage en profondeur actuelles est trop cher d'un point de vue informatique. Cela inclut le calcul des tenseurs généraux du quatrième ordre tels que les Hessians (par exemple, dans MAML et l'optimisation du second ordre de Newton). Heureusement, les formules quadratiques sont rares en apprentissage profond. Cependant, ils se trouvent souvent dans l'apprentissage automatique «classique» -
SVM , méthode des moindres carrés, LASSO, processus gaussiens, etc.
Mythe 2: les bases de données d'images reflètent des photos du monde réel
Beaucoup de gens aiment penser que les réseaux de neurones ont appris à mieux reconnaître les objets que les gens. Ce n'est pas le cas. Ils peuvent être en avance sur les personnes sur la base d'images sélectionnées, par exemple ImageNet, mais dans le cas de la reconnaissance d'objets à partir de vraies photos de la vie ordinaire, ils ne pourront certainement pas dépasser un adulte ordinaire. En effet, la sélection d'images dans les ensembles de données actuels ne coïncide pas avec la sélection de toutes les images possibles rencontrées naturellement dans la réalité.
Dans un travail assez ancien,
Unbias Look at Dataset Bias. Torralba et Efros. CVPR 2011. , Les auteurs ont proposé d'étudier les distorsions associées à un ensemble d'images dans douze bases de données populaires, afin de déterminer s'il est possible de former le classificateur pour déterminer l'ensemble de données à partir duquel cette image a été prise.

Les chances de deviner accidentellement l'ensemble de données correctes sont de 1/12 à 8%, tandis que les scientifiques eux-mêmes ont fait face à la tâche avec un taux de réussite> 75%.
Ils ont formé SVM sur un
histogramme de gradient directionnel (HOG) et ont constaté que le classificateur a terminé la tâche dans 39% des cas, ce qui dépasse considérablement les résultats aléatoires. Si nous répétions cette expérience aujourd'hui, avec les réseaux de neurones les plus avancés, nous verrions sûrement une augmentation de la précision du classificateur.
Si les bases de données d'images affichaient correctement les vraies images du monde réel, nous n'aurions pas à être en mesure de déterminer de quel ensemble de données provient une image particulière.

Cependant, il y a des traits dans les données qui rendent chaque ensemble d'images différent des autres. ImageNet possède de nombreuses voitures de course qui sont peu susceptibles de décrire la voiture moyenne «théorique» dans son ensemble.

Les auteurs ont également déterminé la valeur de chaque ensemble de données en mesurant dans quelle mesure un classificateur formé sur un ensemble fonctionne avec des images d'autres ensembles. Selon cette métrique, les bases de données LabelMe et ImageNet se sont avérées être les moins biaisées, ayant reçu une note de 0,58 en utilisant la méthode du «panier de devises». Toutes les valeurs se sont avérées être inférieures à l'unité, ce qui signifie que la formation sur un ensemble de données différent entraîne toujours de mauvaises performances. Dans un monde idéal sans ensembles biaisés, certains chiffres auraient dû dépasser un.
Les auteurs ont conclu avec pessimisme:
Quelle est donc la valeur des ensembles de données existants pour les algorithmes de formation conçus pour le monde réel? La réponse qui en résulte peut être décrite comme «meilleure que rien mais pas beaucoup».
Mythe 3: les chercheurs de MO n'utilisent pas de kits de test pour les tests
Dans le manuel sur l'apprentissage automatique, nous apprenons à diviser l'ensemble de données en formation, évaluation et vérification. L'efficacité du modèle, formé sur l'ensemble de formation et évalué sur l'évaluation aide la personne impliquée dans l'OM à affiner le modèle pour maximiser l'efficacité dans son utilisation réelle. L'ensemble de test n'a pas besoin d'être touché jusqu'à ce que la personne ait fini de s'ajuster pour fournir une évaluation impartiale de l'efficacité réelle du modèle dans le monde réel. Si une personne triche à l'aide d'un ensemble de tests aux stades de la formation ou de l'évaluation, le modèle risque de devenir trop adapté à un ensemble de données particulier.
Dans le monde hyper-compétitif de la recherche en MO, les nouveaux algorithmes et modèles sont souvent jugés par l'efficacité de leur travail avec les données de vérification. Par conséquent, cela n'a aucun sens pour les chercheurs d'écrire ou de publier des articles décrivant des méthodes qui fonctionnent mal avec des ensembles de données de test. Et cela signifie, en substance, que la communauté de la région de Moscou dans son ensemble utilise un ensemble de tests pour l'évaluation.
Quelles sont les conséquences de cette arnaque?

Les auteurs des
classificateurs CIFAR-10 se généralisent-ils en CIFAR-10? Recht et al. ArXiv 2018 a étudié ce problème en créant une nouvelle suite de tests pour CIFAR-10. Pour ce faire, ils ont fait une sélection d'images à partir de Tiny Images.
Ils ont choisi CIFAR-10 car il s'agit de l'un des ensembles de données les plus couramment utilisés dans le MO, le deuxième ensemble le plus populaire de NeurIPS 2017 (après le MNIST). Le processus de création d'un ensemble de données pour CIFAR-10 est également bien décrit et transparent, dans la grande base de données Tiny Images, il y a beaucoup d'étiquettes détaillées, de sorte que vous pouvez reproduire un nouvel ensemble de test, minimisant le décalage de distribution.

Ils ont constaté qu'un grand nombre de modèles différents de réseaux de neurones sur le nouvel ensemble de tests ont montré une baisse significative de la précision (4% - 15%). Cependant, le classement relatif des performances de chaque modèle est resté relativement stable.
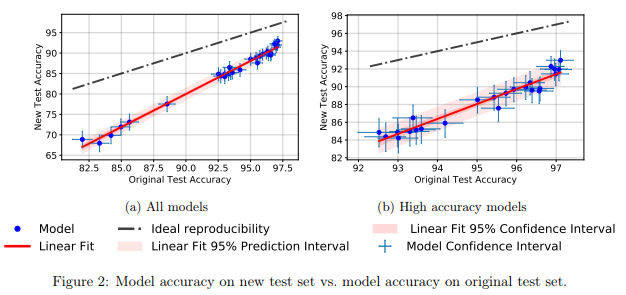
En général, les modèles les plus performants ont montré une baisse de précision plus faible que les modèles les moins performants. C'est bien car il s'ensuit que la perte de généralisation du modèle due à la triche, au moins dans le cas de CIFAR-10, diminue à mesure que la communauté invente des méthodes et des modèles améliorés de MO.
Mythe 4: la formation au réseau neuronal utilise toutes les entrées
Il est généralement admis que les
données sont une nouvelle huile , et que plus nous avons de données, mieux nous pouvons former des modèles d'apprentissage en profondeur qui sont maintenant inefficaces sur l'échantillon et sur-paramétrisés.
Dans
une étude empirique d'exemples d'oubli pendant l'apprentissage d'un réseau neuronal profond. Toneva et al. Les auteurs de l'
ICLR 2019 démontrent une redondance significative dans plusieurs ensembles courants de petites images. Étonnamment, 30% des données de CIFAR-10 peuvent simplement être supprimées sans modifier considérablement l'exactitude du contrôle.
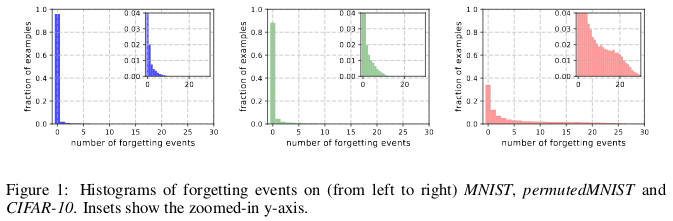 Histoires d'oubli de (gauche à droite) MNIST, permutedMNIST et CIFAR-10.
Histoires d'oubli de (gauche à droite) MNIST, permutedMNIST et CIFAR-10.L'oubli se produit lorsqu'un réseau de neurones classe incorrectement une image au temps t + 1, alors qu'au temps t il a pu classer correctement une image. Le flux de temps est mesuré par les mises à jour SGD. Pour suivre l'oubli, les auteurs ont lancé leur réseau neuronal sur un petit ensemble de données après chaque mise à jour SGD, et non sur tous les exemples disponibles dans la base de données. Les exemples qui ne doivent pas être oubliés sont appelés exemples inoubliables.
Ils ont constaté que 91,7% MNIST, 75,3% permutéMNIST, 31,3% CIFAR-10 et 7,62% CIFAR-100 sont des exemples inoubliables. Ceci est intuitivement compréhensible, car l'augmentation de la diversité et de la complexité de l'ensemble de données devrait faire oublier au réseau neuronal plus d'exemples.

Les exemples oubliables semblent présenter des caractéristiques plus rares et étranges par rapport à celles inoubliables. Les auteurs les comparent aux vecteurs de support dans SVM, car ils semblent dessiner les contours des limites de décision.
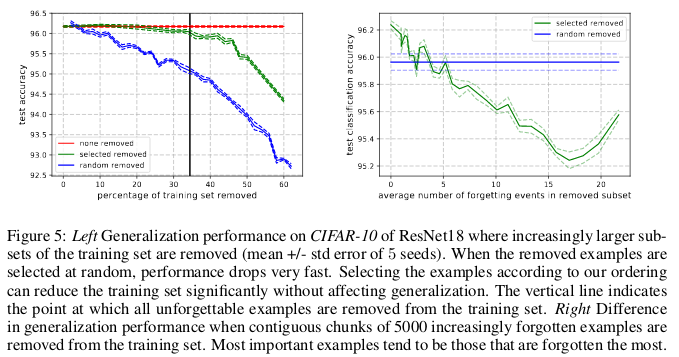
Des exemples inoubliables, à leur tour, codent pour la plupart des informations redondantes. Si nous trions les exemples selon le degré d'inoubliable, nous pouvons compresser l'ensemble de données en supprimant les plus inoubliables.
30% des données CIFAR-10 peuvent être supprimées sans affecter l'exactitude des contrôles, et la suppression de 35% des données entraîne une légère baisse de l'exactitude des contrôles de 0,2%. Si vous sélectionnez au hasard 30% des données, leur suppression entraînera une perte significative de la précision de la vérification de 1%.
De même, 8% des données peuvent être supprimées du CIFAR-100 sans perte de précision de validation.
Ces résultats montrent qu'il existe une redondance significative dans les données pour la formation des réseaux de neurones, similaire à la formation SVM, où les vecteurs non-support peuvent être supprimés sans affecter la décision du modèle.
Les conséquences:Si nous pouvons déterminer lesquelles des données sont inoubliables avant de commencer la formation, nous pouvons économiser de l'espace en les supprimant et en les temps sans les utiliser lors de la formation d'un réseau de neurones.
Mythe 5: La normalisation des lots est nécessaire pour entraîner des réseaux résiduels très profonds.
Pendant longtemps, on a cru que «la formation d'un réseau neuronal profond pour une optimisation directe uniquement dans un but contrôlé (par exemple, la probabilité logarithmique d'une classification correcte) en utilisant la descente de gradient, en commençant par des paramètres aléatoires, ne fonctionne pas bien».
Le tas de méthodes ingénieuses d'initialisation aléatoire, de fonctions d'activation, de techniques d'optimisation et d'autres innovations, telles que les connexions résiduelles, qui est apparu depuis lors a facilité la formation de réseaux de neurones profonds en utilisant la méthode de descente en gradient.
Mais une véritable percée s'est produite après l'introduction de la normalisation par lots (et d'autres techniques de normalisation séquentielle), limitant la taille des activations pour chaque couche du réseau afin d'éliminer le problème de la disparition et des gradients explosifs.
Dans un ouvrage récent,
Fixup Initialization: Residual Learning Without Normalization. Zhang et al. L'ICLR 2019 a montré qu'il est possible de former un réseau à 10000 couches en utilisant du SGD pur sans appliquer de normalisation.

Les auteurs ont comparé la formation de réseaux neuronaux résiduels pour différentes profondeurs sur CIFAR-10 et ont constaté que même si les méthodes d'initialisation standard ne fonctionnaient pas pour 100 couches, les méthodes de normalisation Fixup et batch ont réussi avec 10 000 couches.

Ils ont effectué une analyse théorique et ont montré que «la normalisation du gradient de certaines couches est limitée par le nombre croissant à l'infini d'un réseau profond», ce qui est un problème de gradients explosifs. Pour éviter cela, Foxup est utilisé, dont l'idée clé est de mettre à l'échelle les poids en m couches pour chacune des branches résiduelles L par le nombre de fois en fonction de m et L.

Fixup a aidé à former un réseau résiduel profond avec 110 couches sur le CIFAR-10 avec une vitesse d'apprentissage élevée comparable au comportement d'un réseau d'architecture similaire formé à la normalisation par lots.
Les auteurs ont en outre montré des résultats de test similaires en utilisant Fixup sur le réseau sans aucune normalisation, en travaillant avec la base de données ImageNet et avec des traductions de l'anglais vers l'allemand.
Mythe 6: Les réseaux avec attention sont meilleurs que les réseaux convolutifs.
L'idée que les mécanismes de «l'attention» sont supérieurs aux réseaux de neurones convolutifs gagne en popularité dans la communauté des chercheurs de MO. Dans le travail de
Vaswani et ses collègues , il a été noté que "le coût de calcul des convolutions détachables est égal à la combinaison d'une couche d'auto-attention et d'une couche de rétroaction ponctuelle".
Même les réseaux avancés compétitifs génératifs montrent l'avantage de l'attention personnelle sur la convolution standard lors de la modélisation des dépendances à longue portée.
Les contributeurs
accordent moins d'attention aux convolutions légères et dynamiques. Wu et al. L'ICLR 2019 jette un doute sur l'efficacité paramétrique et l'efficacité de l'auto-attention lors de la modélisation des dépendances à long terme, et offre de nouvelles options de convolution, partiellement inspirées par l'auto-attention, plus efficaces en termes de paramètres.
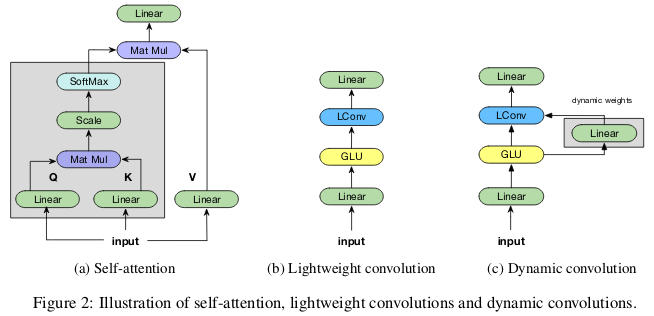
Les convolutions «légères» sont séparables en profondeur, softmax normalisées en dimension temporelle, séparées en poids en dimension canal, et réutilisent les mêmes poids à chaque pas de temps (en tant que réseaux neuronaux récurrents). Les convolutions dynamiques sont des convolutions légères qui utilisent des poids différents à chaque pas de temps.
De telles astuces rendent les convolutions légères et dynamiques de plusieurs ordres de grandeur plus efficaces que les convolutions indivisibles standard.

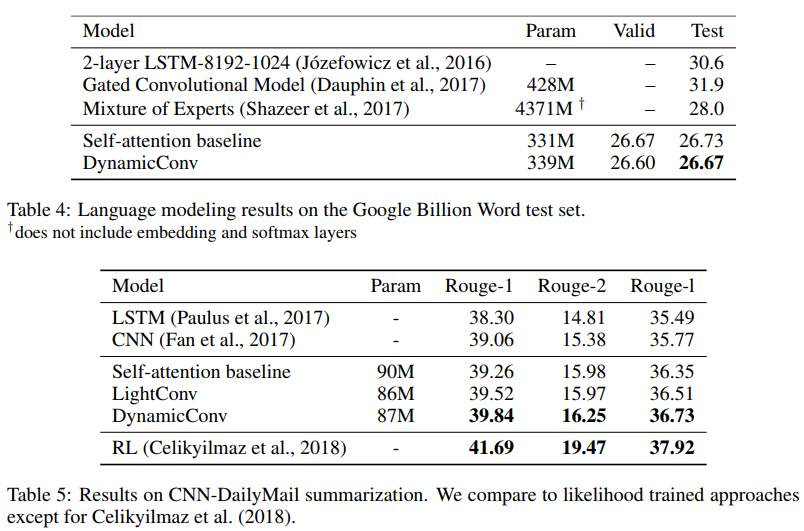
Les auteurs montrent que ces nouvelles circonvolutions correspondent ou dépassent les réseaux auto-absorbants en traduction automatique, modélisation de langage, problèmes de sommation abstraite, utilisant des paramètres identiques ou inférieurs.
Mythe 7: Cartes de signification - un moyen fiable d'interpréter les réseaux de neurones
Bien qu'il existe une opinion selon laquelle les réseaux de neurones sont des boîtes noires, il y a eu de nombreuses tentatives pour les interpréter. Les plus populaires d'entre elles sont les cartes de signification ou d'autres méthodes similaires qui attribuent des évaluations d'importance à des fonctionnalités ou à des exemples de formation.
Il est tentant de pouvoir conclure qu'une image donnée a été classée d'une certaine manière en raison de certaines parties de l'image qui sont importantes pour le réseau neuronal. Pour calculer les cartes de signification, il existe plusieurs méthodes qui utilisent souvent l'activation des réseaux de neurones dans une image donnée et les gradients passant par le réseau.
Dans l'
interprétation des réseaux de neurones est fragile. Ghorbani et al. Les auteurs de l'
AAAI 2019 montrent qu'ils peuvent introduire un changement insaisissable dans l'image, qui, cependant, faussera sa carte de signification.

Le réseau neuronal détermine le papillon monarque non pas par le motif sur ses ailes, mais en raison de la présence de feuilles vertes sans importance sur le fond de la photo.

Les images multidimensionnelles sont souvent plus proches des limites de décision prises par les réseaux de neurones profonds, d'où leur sensibilité aux attaques adversaires. Et si les attaques concurrentielles déplacent les images au-delà des limites de la solution, les attaques interprétatives compétitives les déplacent le long des limites de la solution sans quitter le territoire de la même solution.
La méthode de base développée par les auteurs est une modification de la méthode Goodfello de marquage à gradient rapide, qui fut l'une des premières méthodes réussies d'attaques compétitives. On peut supposer que d'autres attaques plus récentes et plus complexes peuvent également être utilisées pour des attaques sur l'interprétation des réseaux de neurones.
Les conséquences:En raison de la propagation croissante de l'apprentissage en profondeur dans des domaines d'application critiques tels que l'imagerie médicale, il est important d'approcher attentivement l'interprétation des décisions prises par les réseaux de neurones. Par exemple, même s'il serait formidable que le réseau de neurones convolutifs puisse reconnaître la tache sur l'image IRM comme une tumeur maligne, ces résultats ne devraient pas être fiables s'ils sont basés sur des méthodes d'interprétation peu fiables.