ASN.1 est une norme (ISO, UIT-T, GOST) d'un langage décrivant des informations structurées, ainsi que des règles de codage pour ces informations. Pour moi en tant que programmeur, ce n'est qu'un autre format de sérialisation et de présentation des données, avec JSON, XML, XDR et autres. Il est extrêmement courant dans notre vie ordinaire, et de nombreuses personnes le rencontrent: dans les communications cellulaires, téléphoniques, VoIP (UMTS, LTE, WiMAX, SS7, H.323), dans les protocoles réseau (LDAP, SNMP, Kerberos), dans tout Concernant la cryptographie (normes X.509, CMS, PKCS), dans les cartes bancaires et les passeports biométriques, et bien plus encore.
Cet article présente
PyDERASN : bibliothèque Python ASN.1 activement utilisée dans les projets liés à la cryptographie dans
Atlas .
En fait, cela ne vaut pas la peine de recommander ASN.1 pour les tâches cryptographiques: ASN.1 et ses codecs sont complexes. Cela signifie que le code ne sera pas simple, mais c'est toujours un vecteur d'attaque supplémentaire. Regardez simplement
la liste des vulnérabilités dans les bibliothèques ASN.1. Bruce Schneier, dans son
ingénierie de cryptographie, ne recommande pas non plus d'utiliser cette norme en raison de sa complexité: «Le codage TLV le plus connu est ASN.1, mais il est incroyablement complexe et nous nous en éloignons.» Mais, malheureusement, nous avons aujourd'hui
des infrastructures à clé publique qui utilisent activement les
certificats X.509 ,
les messages CRL, OCSP, TSP, CMP,
CMC ,
CMS et une tonne de normes
PKCS . Par conséquent, vous devez être en mesure de travailler avec ASN.1 si vous faites quelque chose lié à la cryptographie.
ASN.1 peut être codé de différentes manières / codecs:
- BER (règles d'encodage de base)
- CER (Canonical Encoding Rules)
- DER (Distinguished Encoding Rules)
- GSER (Generic String Encoding Rules)
- JER (règles d'encodage JSON)
- LWER (règles de codage léger)
- OER (Octet Encoding Rules)
- PER (Packed Encoding Rules)
- SER (règles de codage spécifiques à la signalisation)
- XER (règles d'encodage XML)
et plusieurs autres. Mais dans les tâches cryptographiques en pratique, deux sont utilisées: BER et DER. Même dans les documents XML signés (
XMLDSig ,
XAdES ), il y aura toujours des objets DER ASN.1 encodés en Base64, ainsi que dans le protocole
ACME basé sur JSON de Let's Encrypt. Vous pouvez mieux comprendre tous ces codecs et principes de codage BER / CER / DER dans des articles et des livres:
ASN.1 en termes simples ,
ASN.1 - Communication entre systèmes hétérogènes par Olivier Dubuisson ,
ASN.1 Complete par le professeur John Larmouth .
Le BER est un format TLV orienté octet binaire (par exemple, PER, populaire dans les communications mobiles - orienté bit). Chaque élément est encodé sous la forme: d'une balise (
T ag) identifiant le type d'élément encodé (entier, chaîne, date, etc.), la longueur (
L ength) du contenu et le contenu lui-même (
V alue). BER vous permet éventuellement de ne pas spécifier de valeur de longueur en définissant une valeur de longueur indéfinie spéciale et en terminant par un message de fin d'octets. En plus du codage de longueur, le BER présente une grande variabilité dans la méthode de codage des types de données, tels que
- INTEGER, OBJECT IDENTIFIER, BIT STRING et la longueur de l'élément peuvent ne pas être normalisés (non codés sous une forme minimale);
- BOOLEAN est vrai pour tout contenu différent de zéro;
- BIT STRING peut contenir des bits zéro "supplémentaires";
- BIT STRING, OCTET STRING et tous leurs types de chaînes dérivés, y compris la date / heure, peuvent être divisés en morceaux (morceaux) de longueur variable, dont la durée pendant le (dé) codage n'est pas connue à l'avance;
- UTCTime / GeneralizedTime peut avoir différentes méthodes pour définir le décalage de fuseau horaire et des fractions de zéro «extra» de secondes;
- Les valeurs de SEQUENCE PAR DEFAUT peuvent être codées ou non;
- Les valeurs nommées des derniers bits de BIT STRING peuvent être éventuellement codées;
- SEQUENCE (OF) / SET (OF) peut avoir un ordre arbitraire d'éléments.
Pour tout ce qui précède, il n'est pas toujours possible de coder les données de sorte qu'elles soient identiques au formulaire d'origine. Par conséquent, un sous-ensemble des règles a été inventé: DER est une réglementation stricte d'une seule méthode de codage valide, ce qui est essentiel pour les tâches cryptographiques, où, par exemple, la modification d'un bit invalidera la signature ou la somme de contrôle. Le DER présente un inconvénient important: les longueurs de tous les éléments doivent être connues à l'avance lors du codage, ce qui ne permet pas la sérialisation en flux des données. Le codec CER est exempt de cet inconvénient, garantissant de même une présentation sans ambiguïté des données. Malheureusement (ou heureusement, nous n'avons pas de décodeurs encore plus complexes?), Il n'est pas devenu populaire. Par conséquent, dans la pratique, nous rencontrons une utilisation «mixte» des données codées BER et DER. Étant donné que CER et DER sont tous deux un sous-ensemble de BER, tout décodeur BER est capable de les traiter.
Problèmes avec pyasn1
Au travail, nous écrivons de nombreux programmes Python liés à la cryptographie. Et il y a quelques années, il n'y avait pratiquement pas de choix de bibliothèques gratuites: ce sont des bibliothèques de très bas niveau qui vous permettent de simplement encoder / décoder, par exemple, un entier et un en-tête de structure, ou c'est la bibliothèque
pyasn1 . Nous avons vécu dessus pendant plusieurs années et au début, nous étions très satisfaits, car il vous permet de travailler avec des structures ASN.1 en tant qu'objets de haut niveau: par exemple, un objet certificat X.509 décodé vous permet d'accéder à ses champs via l'interface du dictionnaire: cert ["tbsCertificate"] ["SerialNumber"] nous montrera le numéro de série de ce certificat. De même, vous pouvez "collecter" des objets complexes en travaillant avec eux comme avec des listes, des dictionnaires, puis appelez simplement la fonction pyasn1.codec.der.encoder.encode et obtenez une représentation sérialisée du document.
Cependant, des faiblesses, des problèmes et des limites ont été révélés. Il y avait, et malheureusement encore, des erreurs dans pyasn1: au moment de la rédaction, dans pyasn1, l'un des types de base, GeneralizedTime, est
mal décodé et encodé.
Dans nos projets, pour économiser de l'espace, nous ne stockons souvent que le chemin d'accès au fichier, le décalage et la longueur en octets de l'objet auquel nous voulons nous référer. Par exemple, un fichier signé arbitrairement sera très probablement situé dans la structure CMS SignedData ASN.1:
0 [1,3,1018] ContentInfo SEQUENCE 4 [1,1, 9] . contentType: ContentType OBJECT IDENTIFIER 1.2.840.113549.1.7.2 (id_signedData) 19-4 [0,0,1003] . content: [0] EXPLICIT [UNIV 16] ANY 19 [1,3, 999] . . DEFINED BY id_signedData: SignedData SEQUENCE 23 [1,1, 1] . . . version: CMSVersion INTEGER v3 (03) 26 [1,1, 19] . . . digestAlgorithms: DigestAlgorithmIdentifiers SET OF [...] 47 [1,3, 769] . . . encapContentInfo: EncapsulatedContentInfo SEQUENCE 51 [1,1, 8] . . . . eContentType: ContentType OBJECT IDENTIFIER 1.3.6.1.5.5.7.12.2 (id_cct_PKIData) 65-4 [1,3, 751] . . . . eContent: [0] EXPLICIT OCTET STRING 751 bytes OPTIONAL 751 820 [1,2, 199] . . . signerInfos: SignerInfos SET OF 823 [1,2, 196] . . . . 0: SignerInfo SEQUENCE 826 [1,1, 1] . . . . . version: CMSVersion INTEGER v3 (03) 829 [0,0, 22] . . . . . sid: SignerIdentifier CHOICE subjectKeyIdentifier [...] 956 [1,1, 64] . . . . . signature: SignatureValue OCTET STRING 64 bytes . . . . . . C1:B3:88:BA:F8:92:1C:E6:3E:41:9B:E0:D3:E9:AF:D8 . . . . . . 47:4A:8A:9D:94:5D:56:6B:F0:C1:20:38:D2:72:22:12 . . . . . . 9F:76:46:F6:51:5F:9A:8D:BF:D7:A6:9B:FD:C5:DA:D2 . . . . . . F3:6B:00:14:A4:9D:D7:B5:E1:A6:86:44:86:A7:E8:C9
et nous pouvons obtenir le fichier signé original à un décalage de 65 octets, 751 octets de long. pyasn1 ne stocke pas ces informations dans ses objets décodés. Le soi-disant TLVSeeker a été écrit - une petite bibliothèque qui vous permet de décoder les balises et les longueurs des objets, dans l'interface dont nous avons commandé "aller à la balise suivante", "aller à l'intérieur de la balise" (aller à l'intérieur de la SÉQUENCE de l'objet), "aller à la balise suivante", "dire à votre décalage et la longueur de l'objet où nous sommes. " Il s'agissait d'une marche «manuelle» sur les données sérialisées ASN.1 DER. Mais il n'était pas possible de travailler avec des données sérialisées BER de cette façon, car, par exemple, la chaîne d'octets OCTET STRING pouvait être codée en plusieurs blocs.
Un autre inconvénient de nos tâches pyasn1 est l'incapacité de comprendre à partir d'objets décodés si un champ donné était présent dans SEQUENCE ou non. Par exemple, si la structure contient le champ Field SEQUENCE OF Smth OPTIONAL, alors il pourrait être complètement absent des données reçues (OPTIONAL), mais il pourrait être présent, mais il pourrait être de longueur nulle (liste vide). Dans le cas général, cela n'a pas pu être clarifié. Et cela est nécessaire pour un contrôle rigoureux de la validité des données reçues. Imaginez qu'une autorité de certification émette un certificat avec des données valides "pas entièrement" du point de vue des schémas ASN.1! Par exemple, l'autorité de certification TÜRKTRUST Elektronik Sertifika Hizmet Sağlayıcısı dans son certificat racine est allée au-delà des limites
RFC 5280 autorisées pour la longueur du composant en question - il ne peut pas être honnêtement décodé selon le schéma. Le codec DER exige qu'un champ dont la valeur est DEFAULT ne soit pas codé pendant la transmission - de tels documents sont rencontrés dans la vie, et la première version de PyDERASN autorisait même consciemment un tel comportement invalide (du point de vue DER) pour des raisons de compatibilité descendante.
Une autre limitation est l'impossibilité de savoir facilement sous quelle forme (BER / DER) un ou un autre objet a été codé dans la structure. Par exemple, la norme CMS indique que le message est codé BER, mais le champ signéAttrs, sur lequel la signature cryptographique est formée, doit être dans DER. Si nous décodons avec le DER, alors nous tomberons sur le traitement du CMS lui-même, si nous décodons avec le BER, nous ne saurons pas sous quelle forme a été signéAttrs. Par conséquent, il sera nécessaire que TLVSeeker (dont l'analogue ne figure pas dans pyasn1) recherche l'emplacement de chacun des champs signéAttrs, et il devra être décodé séparément par DER à partir de la vue sérialisée.
La possibilité d'un traitement automatique des champs DEFINED BY, qui sont très courants, était très souhaitable pour nous. Après décodage de la structure ASN.1, il peut nous rester de nombreux champs ANY, qui doivent être traités plus avant selon le schéma sélectionné sur la base de l'IDENTIFICATEUR D'OBJET spécifié dans le champ de structure. En code Python, cela signifie écrire un if puis appeler le décodeur pour le champ ANY.
L'avènement de PyDERASN
Dans Atlas, nous avons régulièrement, après avoir trouvé des problèmes ou modifié les programmes gratuits utilisés, envoyer des correctifs au sommet. Dans pyasn1, nous avons envoyé plusieurs fois des améliorations, mais le code pyasn1 n'est pas le plus facile à comprendre, et des changements d'API incompatibles s'y sont parfois produits, ce qui nous a frappés. De plus, nous avons l'habitude d'écrire des tests avec des tests génératifs, ce qui n'était pas le cas dans pyasn1.
Un beau jour, j'ai décidé que je devais endurer cela et il était temps d'essayer d'écrire ma propre bibliothèque avec __slot __s, offset s et des blobs magnifiquement affichés! Il ne suffit pas de créer un codec ASN.1 - vous devez y transférer tous nos projets dépendants, et ce sont des centaines de milliers de lignes de code dans lesquelles il y a beaucoup de travail avec les structures ASN.1. C'est une des conditions requises: facilité de traduction du code pyasn1 actuel. Ayant passé toutes mes vacances, j'ai écrit cette bibliothèque, y ai transféré tous les projets. Puisqu'ils ont une couverture de près de 100% par les tests, cela signifiait également que la bibliothèque était pleinement opérationnelle.
PyDERASN, de même, a une couverture de test de presque 100%. Les tests génératifs sont utilisés avec la merveilleuse bibliothèque d'
hypothèses . Un
pygarflage à fuzz a également été réalisé sur 32 machines nucléaires. Malgré le fait qu'il ne reste presque plus de code Python2, PyDERASN conserve toujours la compatibilité avec lui et pour cette raison il a une seule dépendance à
six . De plus, il est testé par rapport à la
suite de tests de conformité ASN.1: 2008 .
Le principe de travailler avec lui est similaire à pyasn1 - travailler avec des objets Python de haut niveau. La description des circuits ASN.1 est similaire.
class TBSCertificate(Sequence): schema = ( ("version", Version(expl=tag_ctxc(0), default="v1")), ("serialNumber", CertificateSerialNumber()), ("signature", AlgorithmIdentifier()), ("issuer", Name()), ("validity", Validity()), ("subject", Name()), ("subjectPublicKeyInfo", SubjectPublicKeyInfo()), ("issuerUniqueID", UniqueIdentifier(impl=tag_ctxp(1), optional=True)), ("subjectUniqueID", UniqueIdentifier(impl=tag_ctxp(2), optional=True)), ("extensions", Extensions(expl=tag_ctxc(3), optional=True)), )
Cependant, PyDERASN a un semblant de typage fort. Dans pyasn1, si le champ était de type CMSVersion (INTEGER), alors il pourrait être affecté d'un int ou INTEGER. PyDERASN exige strictement que l'objet assigné soit exactement CMSVersion. En plus d'écrire du code Python3, nous utilisons
des annotations de frappe , donc nos fonctions n'auront pas d'arguments incompréhensibles comme def func (série, contenu), mais def func (série: CertificateSerialNumber, contents: EncapsulatedContentInfo), et PyDERASN aide à garder une trace de telles code.
Dans le même temps, PyDERASN a des concessions extrêmement pratiques pour ce typage même. pyasn1 n'a pas autorisé SubjectKeyIdentifier (). subtype (implicitTag = Tag (...)) à affecter un objet SubjectKeyIdentifier () (sans le TAG IMPLICIT requis) et a souvent dû copier et recréer des objets uniquement en raison des balises IMPLICIT / EXPLICIT modifiées. PyDERASN n'observe strictement que le type de base - il remplacera automatiquement les balises d'une structure ASN.1 existante. Cela simplifie considérablement le code d'application.
Si une erreur se produit pendant le décodage, alors dans pyasn1, il n'est pas facile de comprendre exactement où elle s'est produite. Par exemple, dans le certificat turc déjà mentionné, nous obtenons cette erreur: UTF8String (tbsCertificate: issuer: rdnSequence: 3: 0: valeur: DEFINED BY 2.5.4.10:utf8String) (à 138) limites non satisfaites: 1 ⇐ 77 ⇐ 64 lors de l'écriture de l'ASN .1 structure les gens peuvent faire des erreurs, et il est plus facile de déboguer les applications ou de trouver des problèmes de documents codés du côté opposé.
La première version de PyDERASN ne supportait pas l'encodage BER. Il est apparu beaucoup plus tard et le traitement UTCTime / GeneralizedTime avec fuseaux horaires n'est toujours pas pris en charge. Cela viendra à l'avenir, car le projet est écrit principalement en temps libre.
De plus, dans la première version, il n'y avait pas de travail avec les champs DEFINED BY. Quelques mois plus tard, cette
opportunité est apparue et a commencé à être utilisée activement, réduisant considérablement le code d'application - en une seule opération de décodage, il a été possible de démonter la structure entière en profondeur. Pour ce faire, dans le schéma, quels champs sont définis qui "déterminent". Par exemple, une description d'un schéma CMS:
class ContentInfo(Sequence): schema = ( ("contentType", ContentType(defines=((("content",), { id_authenticatedData: AuthenticatedData(), id_digestedData: DigestedData(), id_encryptedData: EncryptedData(), id_envelopedData: EnvelopedData(), id_signedData: SignedData(), }),))), ("content", Any(expl=tag_ctxc(0))), )
indique que si contentType contient un OID avec id_signedData, le champ de contenu (situé dans la même SEQUENCE) doit être décodé à l'aide du schéma SignedData. Pourquoi y a-t-il tant de crochets? Un champ peut «définir» plusieurs champs en même temps, comme c'est le cas dans les structures EnvelopedData. Les champs définis sont identifiés par le chemin dit de décodage - il définit l'emplacement exact de tout élément dans toutes les structures.
Il n'est pas toujours souhaitable ou pas toujours possible d'introduire immédiatement ces définitions dans le circuit. Il peut y avoir des cas spécifiques à l'application où les OID et les structures ne sont connus que dans un projet tiers. PyDERASN offre la possibilité de spécifier ces définitions juste au moment du décodage de la structure:
ContentInfo().decode(data, ctx={"defines_by_path": (( ( "content", DecodePathDefBy(id_signedData), "certificates", any, "certificate", "tbsCertificate", "extensions", any, "extnID", ), ((("extnValue",), { id_ce_authorityKeyIdentifier: AuthorityKeyIdentifier(), id_ce_basicConstraints: BasicConstraints(), [...] id_ru_subjectSignTool: SubjectSignTool(), }),), ),)})
Ici, nous disons que dans CMS SignedData pour tous les certificats attachés, décodez toutes leurs extensions (AuthorityKeyIdentifier, BasicConstraints, SubjectSignTool, etc.). Nous indiquons à travers le chemin de décodage quel élément à "substituer" définit, comme s'il était défini dans le circuit.
Enfin, PyDERASN a la capacité de travailler à partir de la
ligne de commande pour décoder les fichiers ASN.1 et possède une
jolie impression riche. Vous pouvez décoder un ASN.1 arbitraire, ou vous pouvez spécifier un schéma clairement défini et voir quelque chose comme ceci:
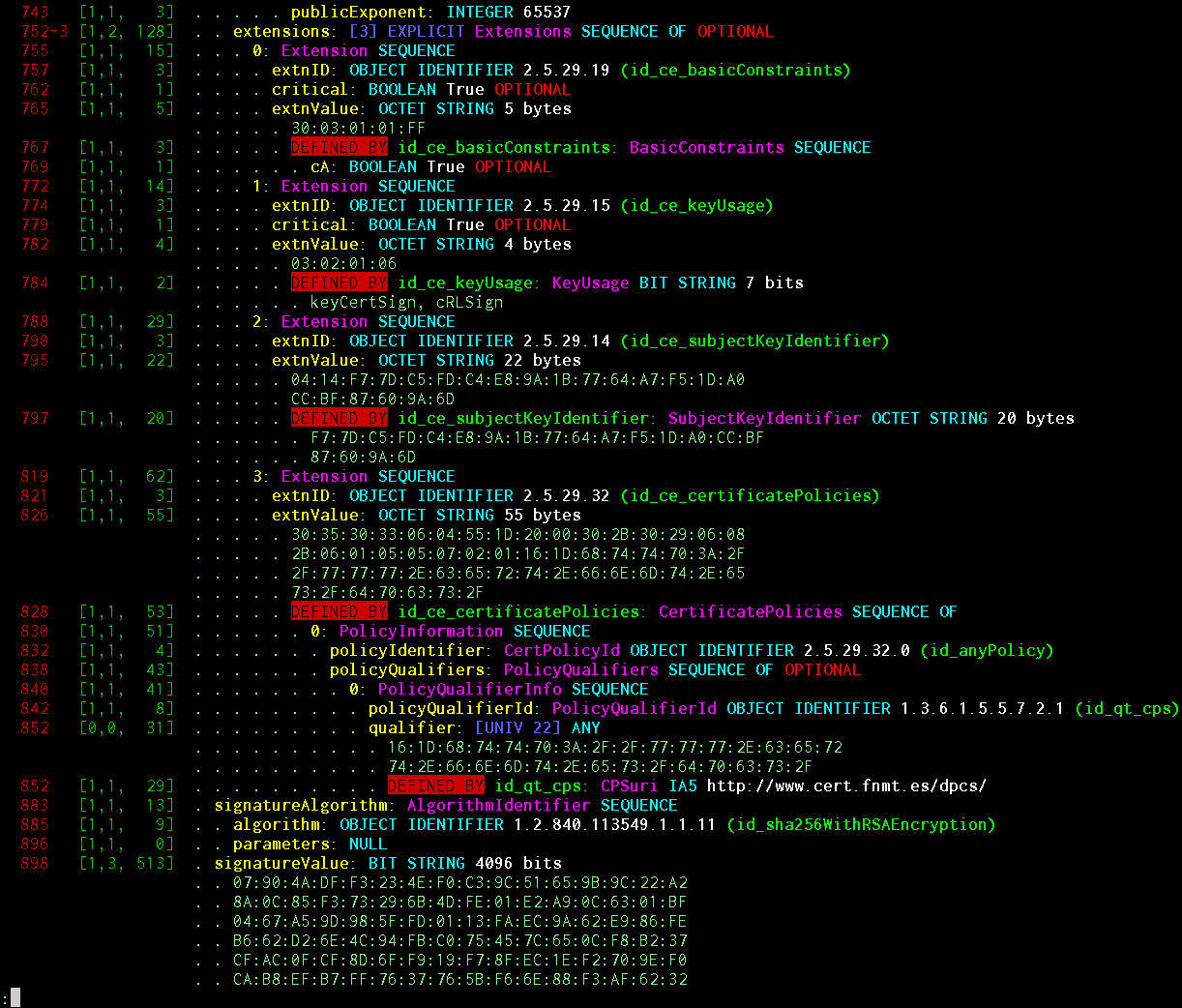
Informations affichées: décalage d'objet, longueur d'étiquette, longueur de longueur, longueur de contenu, présence d'EOC (fin d'octets), indicateur de codage BER, indicateur de codage de longueur indéfinie, longueur et décalage d'étiquette EXPLICIT (le cas échéant), profondeur d'imbrication d'objet dans structures, valeur de balise IMPLICIT / EXPLICIT, nom d'objet selon le schéma, son type ASN.1 de base, numéro de série à l'intérieur de SEQUENCE / SET OF, valeur CHOICE (le cas échéant), nom lisible par l'homme INTEGER / ENUMERATED / BIT STRING selon le schéma, valeur de tout type de base , Indicateur DEFAULT / OPTIONAL du circuit, signe que l'objet a été automatiquement décodé comme DEFINED BY et après g de OID et il est arrivé, OID chelovekochitaemy.
Le joli système d'impression est spécialement conçu pour générer une séquence d'objets PP déjà visualisés par des moyens séparés. La capture d'écran montre le rendu en texte brut. Il existe des rendus au format JSON / HTML afin que cela puisse être vu avec une mise en évidence dans le navigateur ASN.1 comme dans le projet
asn1js .
Autres bibliothèques
Ce n'était pas l'objectif, mais PyDERASN était significativement
plus rapide que pyasn1. Par exemple, le décodage de fichiers CRL de taille mégaoctet peut prendre si longtemps que vous devez penser à des formats intermédiaires pour stocker des données (rapidement) et changer l'architecture des applications. pyasn1 décode CRL
CACert.org sur mon ordinateur portable pendant plus de 20 minutes, tandis que PyDERASN en seulement 28 secondes! Il existe un projet
asn1crypto visant à travailler rapidement avec des structures cryptographiques: il décode (complètement, pas paresseusement) la même CRL en 29 secondes, mais il consomme presque deux fois plus de RAM lorsqu'il fonctionne sous Python3 (983 Mio contre 498), et 3,5 fois sous Python2 (1677 contre 488), tandis que pyasn1 consomme jusqu'à 4,3 fois plus (2093 contre 488).
asn1crypto, que j'ai mentionné, nous ne l'avons pas considéré, car le projet n'en était qu'à ses balbutiements, et nous n'en avions pas entendu parler. Maintenant, ils ne commenceraient pas non plus à regarder dans sa direction, puisque j'ai immédiatement découvert que le même GeneralizedTime ne prenait pas un aspect arbitraire, et lors de la sérialisation, il supprimait silencieusement des fractions de seconde. Ceci est acceptable pour travailler avec des certificats X.509, mais en général cela ne fonctionnera pas.
À l'heure actuelle, PyDERASN est le plus strict des décodeurs DER Python / Go gratuits que je connaisse. Dans la bibliothèque encoding / asn1 de mon Go préféré, il n'y a
pas de contrôle strict sur les chaînes OBJECT IDENTIFIER et UTCTime / GeneralizedTime. Parfois, la rigueur peut interférer (principalement en raison de la rétrocompatibilité avec les anciennes applications que personne ne corrigera), donc dans PyDERASN pendant le décodage, vous pouvez passer
divers paramètres affaiblissant les vérifications.
Le code du projet essaie d'être aussi simple que possible. La bibliothèque entière est un seul fichier. Le code est écrit en mettant l'accent sur la facilité de compréhension, sans performances inutiles et optimisations de code SEC. Comme je l'ai déjà dit, il ne prend pas en charge le décodage BER à part entière des chaînes UTCTime / GeneralizedTime, ainsi que les types de données REAL, RELATIVE OID, EXTERNAL, INSTANCE OF, EMBEDDED PDV, CHARACTER STRING. Dans tous les autres cas, personnellement, je ne vois aucune raison d'utiliser d'autres bibliothèques en Python.
Comme tous mes projets, tels que
PyGOST ,
GoGOST ,
NNCP ,
GoVPN , PyDERASN est
un logiciel entièrement
gratuit distribué sous les termes de
LGPLv3 + , et est disponible en téléchargement gratuit. Des exemples d'utilisation sont
ici dans les
tests PyGOST .
Sergey Matveev ,
banque de chiffrement , membre de
l' Open Society Foundation Foundation , développeur Python / Go, spécialiste en chef de
FSUE «STC Atlas» .