
Bonjour à tous! Je m'appelle Sergey Kostanbaev, à la Bourse, je développe le cœur du système commercial.
Lorsque la Bourse de New York est présentée dans des films hollywoodiens, cela ressemble toujours à ceci: des foules de gens criant quelque chose, agitant du papier, il y a un chaos complet. Nous n'avons jamais eu cela à la Bourse de Moscou, car presque depuis le tout début, le trading a été effectué par voie électronique et est basé sur deux plates-formes principales - Spectra (marché des dérivés) et ASTS (devise, bourse et marchés monétaires). Et aujourd'hui, je veux parler de l'évolution de l'architecture du système de négociation et de compensation ASTS, de diverses solutions et conclusions. L'histoire sera longue, j'ai donc dû la diviser en deux parties.
Nous sommes l'une des rares bourses au monde à négocier des actifs de toutes classes et à fournir une gamme complète de services de change. Par exemple, l'an dernier, nous avons pris la deuxième place au monde en termes de volume de transactions obligataires, la 25e place parmi toutes les bourses, la 13e place par capitalisation parmi les bourses publiques.
Pour les soumissionnaires professionnels, des paramètres tels que le temps de réponse, la stabilité de la distribution du temps (gigue) et la fiabilité de l'ensemble du complexe sont essentiels. Actuellement, nous traitons des dizaines de millions de transactions par jour. Le traitement de chaque transaction par le cœur du système prend des dizaines de microsecondes. Bien sûr, avec les opérateurs mobiles du Nouvel An ou avec les moteurs de recherche, la charge elle-même est plus élevée que la nôtre, mais en termes de charge, associée aux caractéristiques ci-dessus, peu de gens peuvent nous comparer, comme il me semble. Dans le même temps, il est important pour nous que le système ne ralentisse pas pendant une seconde, fonctionne de manière absolument stable et que tous les utilisateurs soient dans des conditions égales.
Un peu d'histoire
En 1994, le système australien ASTS a été lancé sur le Moscow Interbank Currency Exchange (MICEX), et à partir de ce moment, vous pouvez compter l'histoire russe du commerce électronique. En 1998, l'architecture de la bourse a été modernisée pour l'introduction du commerce sur Internet. Depuis lors, la vitesse d'introduction de nouvelles solutions et de changements architecturaux dans tous les systèmes et sous-systèmes ne fait que s'accélérer.
Au cours de ces années, le système d'échange a fonctionné sur du matériel haut de gamme - les serveurs HP Superdome 9000 très fiables (construits sur l'
architecture PA-RISC ), dans lesquels absolument tout était dupliqué: sous-systèmes d'entrée-sortie, réseau, RAM (en fait, il y avait une matrice RAID à partir de RAM ), processeurs (échange à chaud pris en charge). Il était possible de changer n'importe quel composant du serveur sans arrêter la machine. Nous comptions sur ces appareils, les considérions comme pratiquement sans problème. Le système d'exploitation était HP UX de type Unix.
Mais depuis environ 2010, un phénomène tel que le trading à haute fréquence (HFT) ou le trading à haute fréquence, tout simplement, des robots d'échange, est apparu. En seulement 2,5 ans, la charge sur nos serveurs a augmenté de 140 fois.
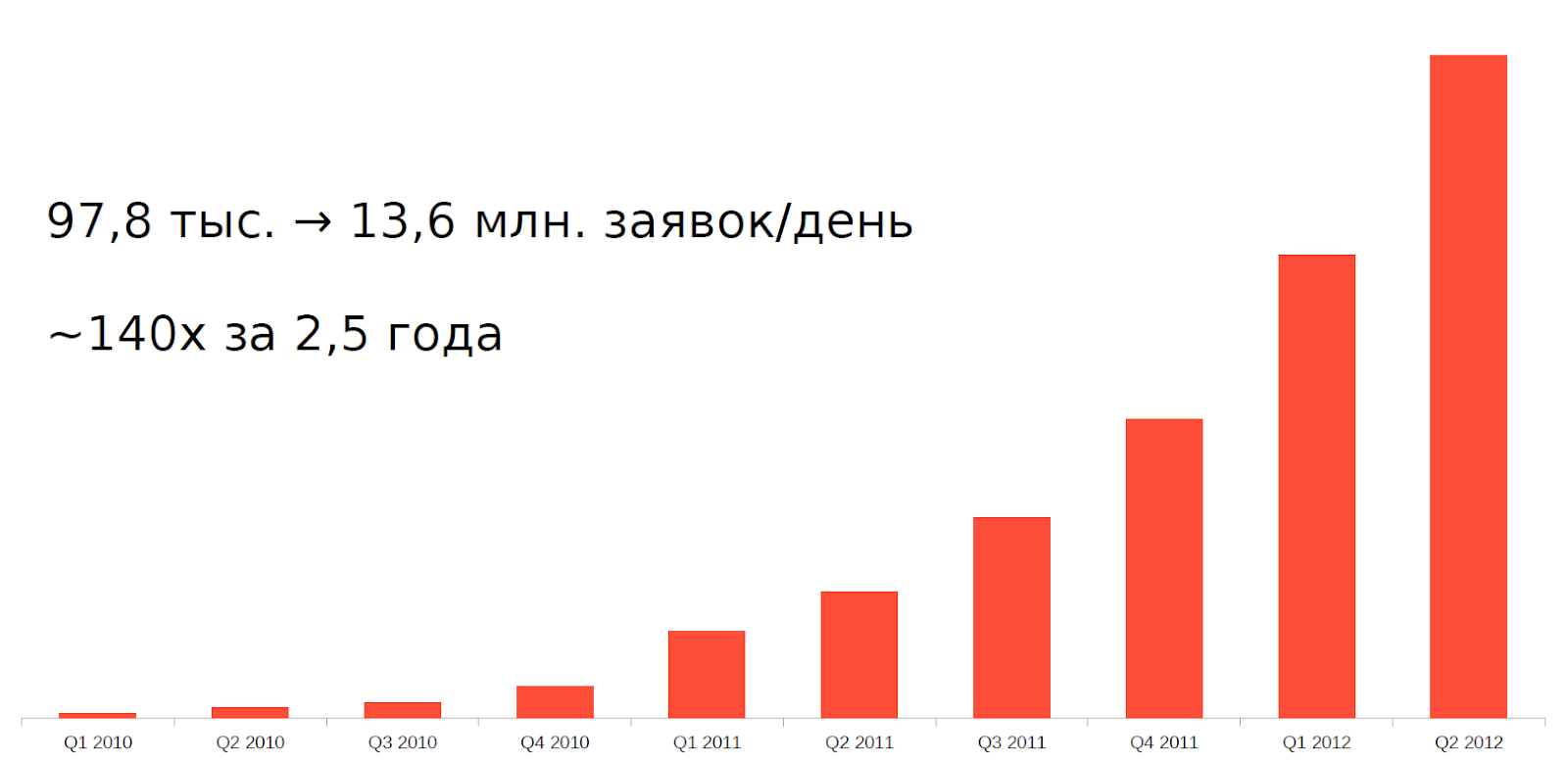
Il était impossible de supporter une telle charge avec l'ancienne architecture et l'équipement. Il fallait s'adapter d'une manière ou d'une autre.
Commencer
Les demandes au système d'échange peuvent être divisées en deux types:
- Les transactions Si vous souhaitez acheter des dollars, des actions ou autre chose, envoyez une transaction au système commercial et obtenez une réponse sur le succès.
- Demandes d'informations. Si vous souhaitez connaître le prix actuel, consultez le carnet de commandes ou les index, puis envoyez des demandes d'informations.
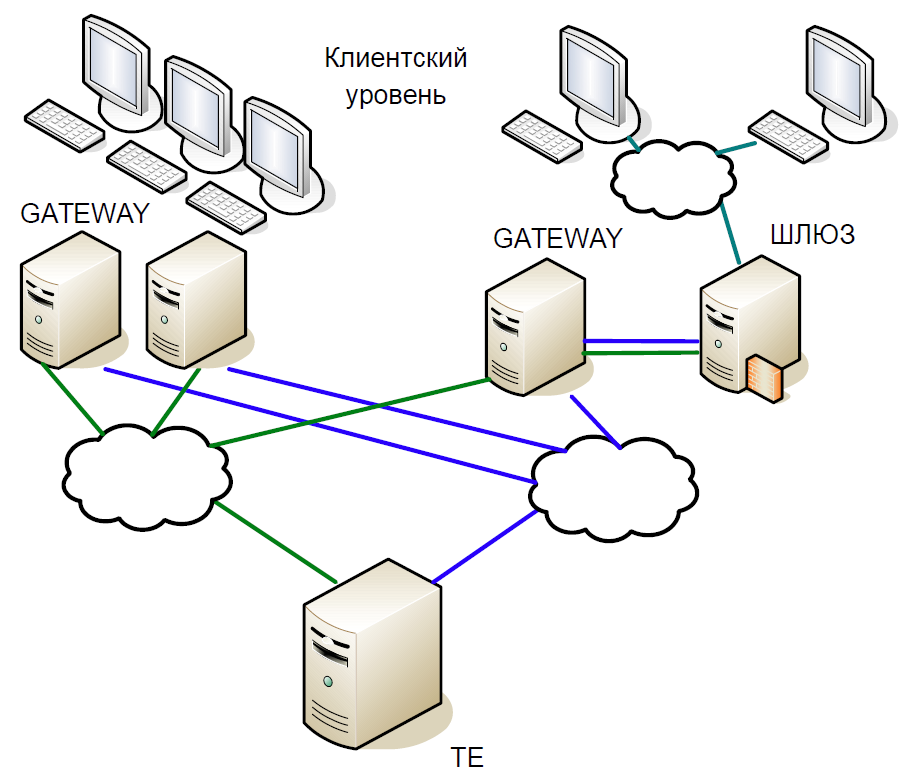
Schématiquement, le cœur du système peut être divisé en trois niveaux:
- Le niveau client auquel les courtiers et les clients travaillent. Tous interagissent avec les serveurs d'accès.
- Les serveurs d'accès (passerelles) sont des serveurs de mise en cache qui traitent localement toutes les demandes d'informations. Vous voulez savoir à quel prix les actions Sberbank sont désormais négociées? La demande va au serveur d'accès.
- Mais si vous souhaitez acheter des actions, la demande est déjà sur le serveur central (Trade Engine). Il existe un tel serveur pour chaque type de marché, ils jouent un rôle crucial et c'est pour eux que nous avons créé ce système.
Le cœur du système commercial est une base de données délicate en mémoire dans laquelle toutes les transactions sont des transactions d'échange. La base a été écrite en C, des dépendances externes il n'y avait que la bibliothèque libc et il n'y avait aucune allocation dynamique de mémoire. Pour réduire le temps de traitement, le système commence par un ensemble statique de tableaux et par une relocalisation statique des données: tout d'abord, toutes les données de la journée en cours sont chargées en mémoire, puis aucun accès au disque, tout le travail se fait uniquement en mémoire. Lorsque le système démarre, toutes les données de référence sont déjà triées, la recherche fonctionne donc très efficacement et prend peu de temps à l'exécution. Toutes les tables sont constituées de listes et d'arborescences intrusives pour les structures de données dynamiques afin qu'elles ne nécessitent pas d'allocation de mémoire lors de l'exécution.
Passons brièvement en revue l'histoire du développement de notre système de trading et de compensation.
La première version de l'architecture du système de négociation et de compensation a été construite sur la soi-disant interaction Unix: la mémoire partagée, les sémaphores et les files d'attente ont été utilisés, et chaque processus était composé d'un thread. Cette approche était répandue au début des années 90.
La première version du système contenait deux niveaux de passerelle et un serveur central du système commercial. Le plan de travail était le suivant:
- Le client envoie une demande qui atteint la passerelle. Il vérifie la validité du format (mais pas les données elles-mêmes) et rejette la mauvaise transaction.
- Si une demande d'informations a été envoyée, elle est exécutée localement; s'il s'agit d'une transaction, elle est redirigée vers le serveur central.
- Ensuite, le moteur de négociation traite la transaction, modifie la mémoire locale et envoie une réponse à la transaction, et elle-même - à la réplication à l'aide d'un mécanisme de réplication distinct.
- La passerelle reçoit une réponse du nœud central et la redirige vers le client.
- Après un certain temps, la passerelle reçoit la transaction à l'aide du mécanisme de réplication, et cette fois, elle l'exécute localement, modifiant ses structures de données afin que les demandes d'informations suivantes affichent les données réelles.
En fait, le modèle de réplication est décrit ici, dans lequel Gateway a complètement répété les actions effectuées dans le système commercial. Un canal de réplication distinct a fourni le même ordre d'exécution des transactions sur plusieurs nœuds d'accès.
Étant donné que le code était monothread, un schéma classique avec des processus fourchus a été utilisé pour servir de nombreux clients. Cependant, la création d'un fork pour la base de données entière était très coûteuse, par conséquent, des processus de service légers ont été utilisés pour collecter les paquets des sessions TCP et les transférer dans une file d'attente (SystemV Message Queue). Gateway et Trade Engine ne fonctionnaient qu'avec cette file d'attente, prenant les transactions pour exécution à partir de là. Il était déjà impossible d'y répondre, car il n'est pas clair quel processus de service devrait le lire. Nous avons donc eu recours à une astuce: chaque processus bifurqué a créé une file d'attente de réponses pour lui-même et lorsqu'une demande est arrivée dans la file d'attente entrante, une balise pour la file d'attente de réponses y a été immédiatement ajoutée.
La copie constante de la file d'attente vers la file d'attente de grandes quantités de données a créé des problèmes, particulièrement caractéristiques des demandes d'informations. Par conséquent, nous avons profité d'une autre astuce: en plus de la file d'attente de réponses, chaque processus a également créé de la mémoire partagée (SystemV Shared Memory). Les packages eux-mêmes y ont été placés et seule la balise a été enregistrée dans la file d'attente, vous permettant de trouver le package source. Cela a aidé à stocker des données dans le cache du processeur.
SystemV IPC comprend des utilitaires pour afficher l'état des objets de file d'attente, de mémoire et de sémaphore. Nous l'avons utilisé activement afin de comprendre ce qui se passe dans le système à un moment particulier, où les paquets s'accumulent, qui sont bloqués, etc.
Première modernisation
Tout d'abord, nous nous sommes débarrassés de la passerelle à processus unique. Son inconvénient majeur était qu'il pouvait traiter une transaction de réplication ou une demande d'informations d'un client. Et avec une charge croissante, la passerelle traitera les demandes plus longtemps et ne pourra pas traiter le flux de réplication. De plus, si le client a envoyé une transaction, il vous suffit de vérifier sa validité et de la transmettre. Par conséquent, nous avons remplacé un processus de passerelle par de nombreux composants pouvant fonctionner en parallèle: des informations multithread et des processus transactionnels qui fonctionnent indépendamment les uns des autres avec une zone de mémoire commune utilisant RW-lock. Et en même temps, nous avons introduit des processus de planification et de réplication.
L'impact du trading haute fréquence
La version ci-dessus de l'architecture a duré jusqu'en 2010. Pendant ce temps, nous n'étions plus satisfaits des performances des serveurs HP Superdome. De plus, l'architecture PA-RISC est en fait morte; le fournisseur n'a pas proposé de mises à jour importantes. En conséquence, nous avons commencé à passer de HP UX / PA RISC à Linux / x86. La transition a commencé avec l'adaptation des serveurs d'accès.
Pourquoi avons-nous dû changer l'architecture à nouveau? Le fait est que le trading à haute fréquence a considérablement modifié le profil de charge du cœur du système.
Supposons que nous ayons une petite transaction qui a provoqué un changement significatif de prix - quelqu'un a acheté un demi-milliard de dollars. Après quelques millisecondes, tous les acteurs du marché le remarquent et commencent à apporter une correction. Naturellement, les demandes s'alignent dans une énorme file d'attente, que le système va ratisser pendant longtemps.

À cet intervalle de 50 ms, la vitesse moyenne est d'environ 16 000 transactions par seconde. Si vous réduisez la fenêtre à 20 ms, nous obtenons une vitesse moyenne de 90 000 transactions par seconde, et au pic il y aura 200 000 transactions. En d'autres termes, la charge est instable, avec des éclats brusques. Et la file d'attente des demandes doit toujours être traitée rapidement.
Mais pourquoi y a-t-il une file d'attente? Ainsi, dans notre exemple, de nombreux utilisateurs ont remarqué un changement de prix et envoient les transactions correspondantes. Ceux-ci viennent à Gateway, il les sérialise, définit un certain ordre et les envoie au réseau. Les routeurs mélangent les paquets et les transfèrent. Dont le paquet est venu plus tôt, cette transaction a «gagné». En conséquence, les clients d'échange ont commencé à remarquer que si la même transaction était envoyée depuis plusieurs passerelles, les chances de son traitement rapide augmentaient. Bientôt, des robots d'échange ont commencé à bombarder Gateway de demandes, et une avalanche de transactions est survenue.

Un nouveau cycle d'évolution
Après des tests et des recherches approfondis, nous sommes passés au noyau temps réel du système d'exploitation. Pour ce faire, ils ont choisi RedHat Enterprise MRG Linux, où MRG signifie messagerie en temps réel. L'avantage des correctifs en temps réel est qu'ils optimisent le système pour une exécution la plus rapide possible: tous les processus sont organisés dans une file d'attente FIFO, vous pouvez isoler les noyaux, pas de pertes, toutes les transactions sont traitées dans un ordre strict.
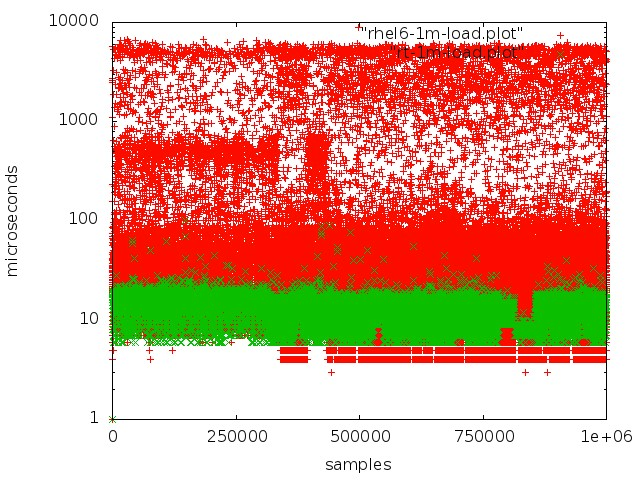 Rouge - fonctionne avec une file d'attente dans un noyau régulier, vert - fonctionne dans un noyau en temps réel.
Rouge - fonctionne avec une file d'attente dans un noyau régulier, vert - fonctionne dans un noyau en temps réel.Mais atteindre une faible latence sur les serveurs réguliers n'est pas si simple:
- Le mode SMI, qui dans l'architecture x86 est au cœur du travail avec des périphériques importants, interfère considérablement. Le traitement de divers événements matériels et la gestion des composants et des périphériques sont effectués par le micrologiciel en mode SMI transparent, dans lequel le système d'exploitation ne voit pas du tout ce que fait le micrologiciel. En règle générale, tous les principaux fournisseurs proposent des extensions spéciales pour les serveurs de micrologiciels, ce qui permet de réduire la quantité de traitement SMI.
- Il ne doit pas y avoir de contrôle dynamique de la fréquence du processeur, ce qui entraîne des temps d'arrêt supplémentaires.
- Lorsque le journal du système de fichiers est réinitialisé, certains processus se produisent dans le noyau et entraînent des retards imprévisibles.
- Vous devez faire attention à des choses telles que l'affinité CPU, l'affinité d'interruption, NUMA.
Je dois dire que le sujet de la configuration du matériel et du noyau Linux pour le traitement en temps réel mérite un article séparé. Nous avons passé beaucoup de temps sur des expériences et des recherches avant d'obtenir un bon résultat.
Lors du passage des serveurs PA-RISC à x86, nous n'avons pratiquement pas eu à changer beaucoup le code système, nous l'avons seulement adapté et reconfiguré. En même temps, plusieurs bugs ont été corrigés. Par exemple, les conséquences sont rapidement apparues que PA RISC était un système Big Endian et x86 un système Little Endian: par exemple, les données n'étaient pas lues correctement. Un bug plus délicat était que PA RISC utilise
un accès mémoire
séquentiellement cohérent , tandis que x86 peut réorganiser les opérations de lecture, de sorte que le code qui est absolument valide sur une plate-forme devient inopérant sur une autre.
Après le passage à x86, la productivité a presque triplé, le temps de traitement moyen des transactions a diminué à 60 μs.
Examinons maintenant de plus près quels changements clés ont été apportés à l'architecture du système.
Hot Standby Epic
En ce qui concerne les serveurs de base, nous savions qu'ils sont moins fiables. Par conséquent, lors de la création d'une nouvelle architecture, nous avons a priori supposé la possibilité de défaillance d'un ou plusieurs nœuds. Par conséquent, nous avions besoin d'un système de secours automatique capable de basculer très rapidement vers des machines de sauvegarde.
De plus, il y avait d'autres exigences:
- Vous ne devez en aucun cas perdre les transactions traitées.
- Le système doit être absolument transparent pour notre infrastructure.
- Les clients ne devraient pas voir les coupures de connexion.
- La réservation ne doit pas introduire de retard important, car il s'agit d'un facteur critique pour l'échange.
Lors de la création d'un système de secours automatique, nous n'avons pas considéré de tels scénarios comme des doubles échecs (par exemple, le réseau sur un serveur a cessé de fonctionner et le serveur principal s'est bloqué); n'a pas envisagé la possibilité d'erreurs dans le logiciel, car elles sont détectées lors des tests; et n'a pas considéré le dysfonctionnement du fer.
En conséquence, nous sommes arrivés au schéma suivant:
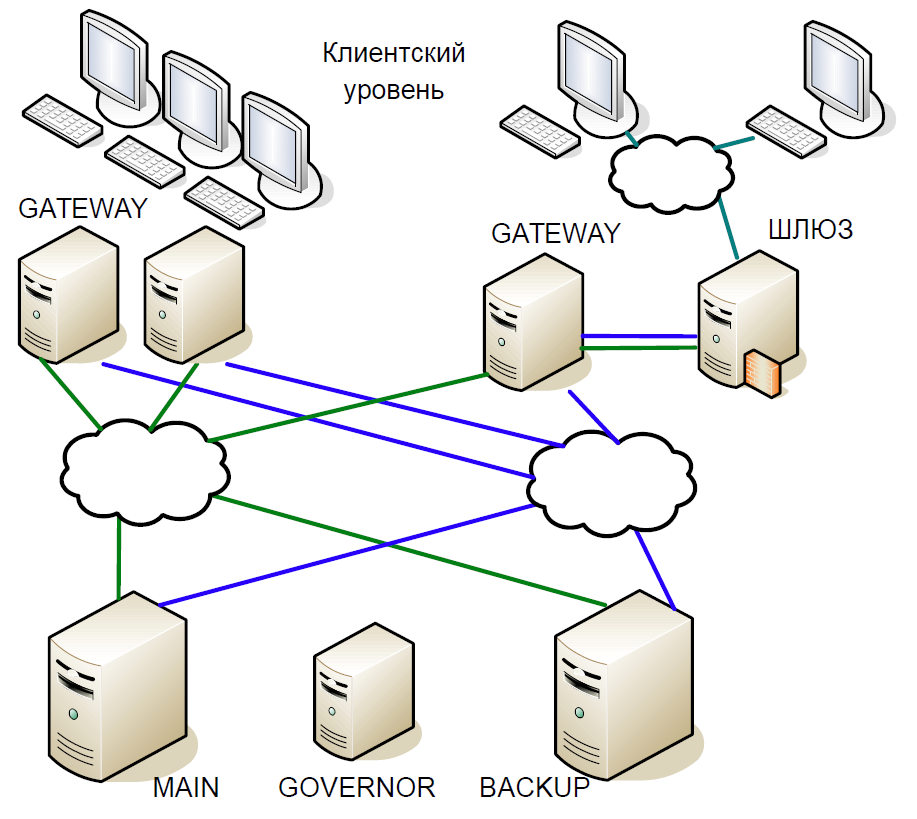
- Le serveur principal a interagi directement avec les serveurs de passerelle.
- Toutes les transactions reçues sur le serveur principal ont été instantanément répliquées sur le serveur de sauvegarde via un canal séparé. L'arbitre (gouverneur) a coordonné le changement en cas de problème.
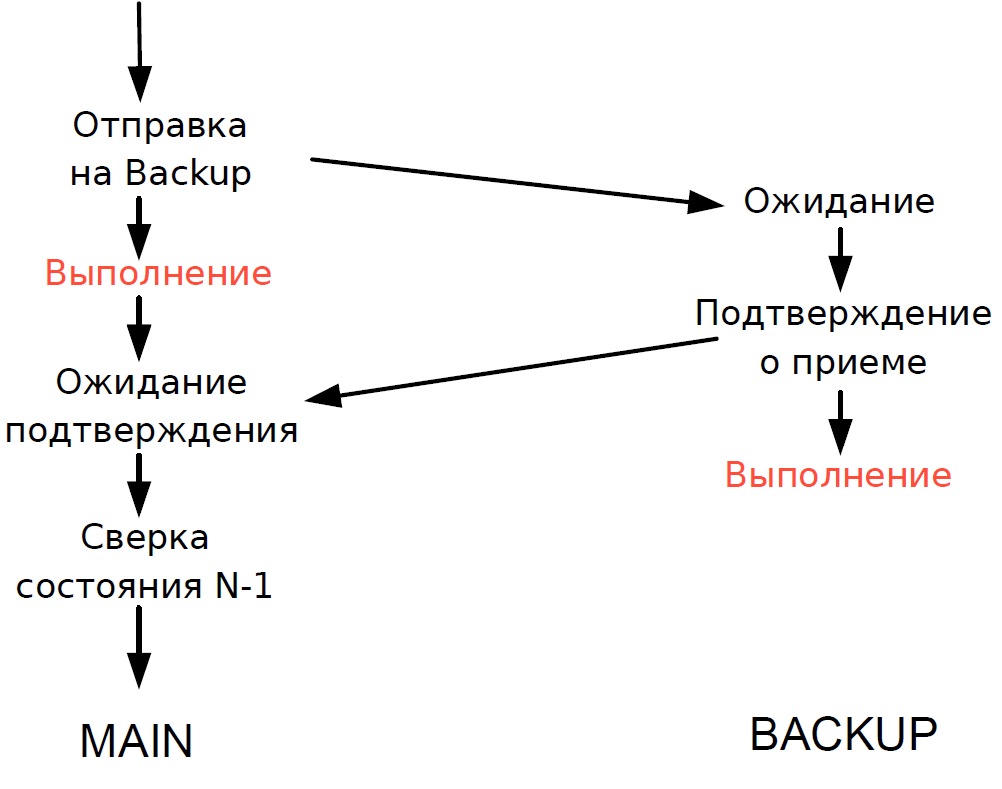
- Le serveur principal a traité chaque transaction et a attendu la confirmation du serveur de sauvegarde. Pour minimiser le retard, nous avons refusé d'attendre la fin de la transaction sur le serveur de sauvegarde. La durée de la transaction sur le réseau étant comparable à la durée de la transaction, aucun retard supplémentaire n'a été ajouté.
- Nous n'avons pu vérifier l'état de traitement du serveur principal et du serveur de sauvegarde que pour la transaction précédente, et l'état de traitement de la transaction en cours était inconnu. Étant donné que les processus à thread unique étaient toujours utilisés ici, l'attente d'une réponse de Backup ralentirait l'ensemble du flux de traitement, et nous avons donc fait un compromis raisonnable: nous avons vérifié le résultat de la transaction précédente.

Le schéma a fonctionné comme suit.
Supposons que le serveur principal cesse de répondre, mais que la passerelle continue de communiquer. Sur le serveur de sauvegarde, un délai d'attente est déclenché, il se tourne vers Governor, et il lui attribue le rôle de serveur principal, et toutes les passerelles basculent vers le nouveau serveur principal.
Si le serveur principal est de nouveau opérationnel, un délai d'expiration interne est également déclenché sur celui-ci, car pendant un certain temps, il n'y a eu aucun appel au serveur à partir de la passerelle. Puis il se tourne également vers le gouverneur, et il l'exclut du régime. En conséquence, l'échange fonctionne avec un serveur jusqu'à la fin de la période de négociation. Étant donné que la probabilité de panne d'un serveur est plutôt faible, un tel schéma a été considéré comme tout à fait acceptable, il ne contenait pas de logique complexe et a été facilement testé.
À suivre.