
Il s'agit de la continuation d'une longue histoire sur notre chemin épineux vers la création d'un système puissant et hautement chargé qui assure le fonctionnement de la Bourse.
La première partie est ici .
Erreur mystérieuse
Après de nombreux tests, le système de trading et de compensation mis à jour a été mis en service et nous avons rencontré un bug sur lequel il était juste d'écrire une histoire de détective mystique.
Peu de temps après le démarrage sur le serveur principal, l'une des transactions a été traitée avec une erreur. Dans le même temps, tout était en ordre sur le serveur de sauvegarde. Il s'est avéré qu'une simple opération mathématique de calcul de l'exposant sur le serveur principal a donné un résultat négatif à partir d'un argument valide! Les relevés se sont poursuivis et dans le registre SSE2, ils ont trouvé une différence d'un bit, qui est responsable de l'arrondi lors de l'utilisation de nombres à virgule flottante.
Ils ont écrit un utilitaire de test simple pour calculer l'exposant avec l'ensemble de bits d'arrondi. Il s'est avéré que dans la version de RedHat Linux que nous utilisions, il y avait un bug dans le travail avec une fonction mathématique lorsque le bit malheureux a été inséré. Nous l'avons signalé à RedHat, après un certain temps, nous avons reçu un patch de leur part et l'avons roulé. L'erreur ne s'est plus produite, mais il n'était pas clair d'où venait ce bit? La fonction
fesetround de C. en était responsable Nous avons soigneusement analysé notre code à la recherche de l'erreur alléguée: vérifié toutes les situations possibles; pris en compte toutes les fonctions utilisant l'arrondi; essayé de jouer une session qui a échoué; utilisé différents compilateurs avec différentes options; utilisé l'analyse statique et dynamique.
La cause de l'erreur est introuvable.
Ensuite, ils ont commencé à vérifier le matériel: ils ont effectué des tests de charge des processeurs; vérifié la RAM; même exécuté des tests pour un scénario très improbable d'une erreur multi-bits dans une cellule. En vain.
En fin de compte, ils se sont installés sur des théories du monde de la physique des hautes énergies: des particules de haute énergie ont pénétré dans notre centre de données, ont traversé la paroi du boîtier, ont frappé le processeur et ont fait que le verrou de déclenchement se bloque dans le même morceau. Cette théorie absurde était appelée "neutrino". Si vous êtes loin de la physique des particules élémentaires: les neutrinos n'interagissent guère avec le monde extérieur, et certainement ils ne sont pas capables d'affecter le processeur.
Puisqu'il n'a pas été possible de trouver la cause de la panne, au cas où ils auraient exclu le serveur «délinquant» de fonctionner.
Après un certain temps, nous avons commencé à améliorer le système de redondance d'UC: nous avons introduit les soi-disant «réserves chaudes» (répliques asynchrones). Ils ont reçu un flux de transactions pouvant se trouver dans différents centres de données, mais warm ne prend pas en charge l'interaction active avec d'autres serveurs.
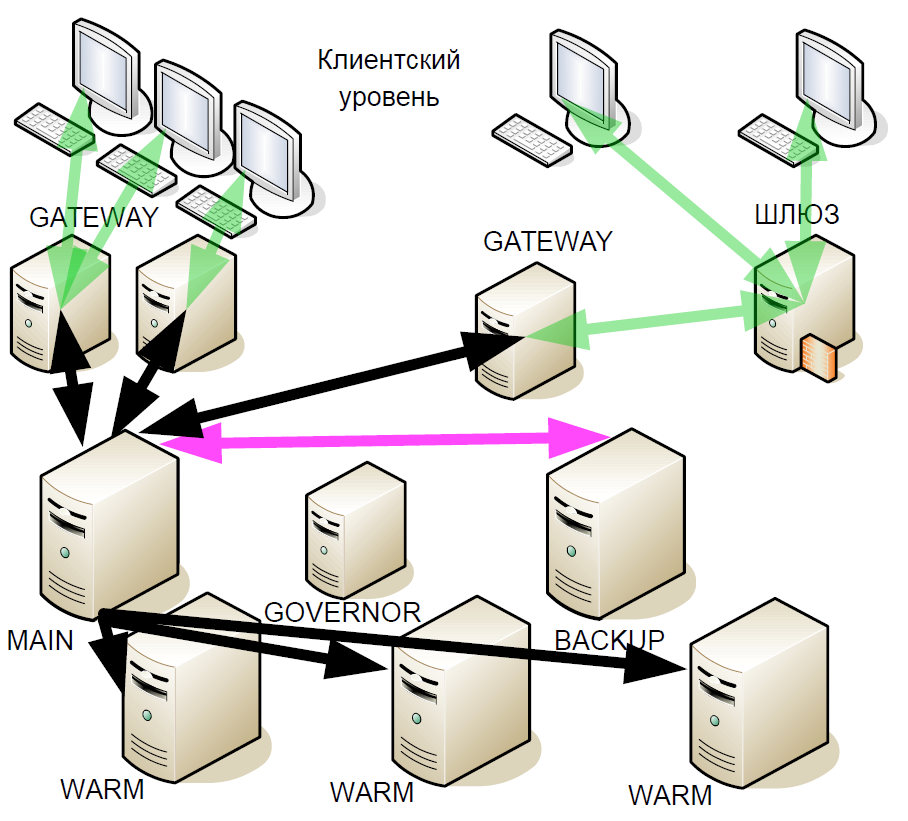
Pourquoi cela at-il été fait? Si le serveur de sauvegarde échoue, la liaison à chaud avec le serveur principal devient la nouvelle sauvegarde. Autrement dit, après une panne, le système ne reste pas jusqu'à la fin de la session de trading avec un serveur principal.
Et lorsque la nouvelle version du système a été testée et mise en service, une erreur avec un bit d'arrondi s'est à nouveau produite. De plus, avec l'augmentation du nombre de serveurs chauds, l'erreur a commencé à apparaître plus souvent. Dans ce cas, le vendeur n'avait rien à présenter, car il n'y a aucune preuve concrète.
Lors de la prochaine analyse de la situation, la théorie a émergé que le problème pourrait être lié à l'OS. Nous avons écrit un programme simple qui appelle la fonction
fesetround dans une boucle sans fin, se souvient de l'état actuel et le vérifie pendant le sommeil, et cela se fait dans de nombreux threads concurrents. Après avoir sélectionné les paramètres de sommeil et le nombre de threads, nous avons commencé à reproduire de manière stable l'échec du bit après environ 5 minutes d'utilisation. Cependant, le support Red Hat n'a pas pu le reproduire. Les tests de nos autres serveurs ont montré que seuls ceux avec certains processeurs installés sont affectés par l'erreur. Dans le même temps, la transition vers un nouveau noyau a résolu le problème. En fin de compte, nous venons de remplacer le système d'exploitation et la véritable cause du bogue n'est toujours pas claire.
Et soudain, l'année dernière, un article est paru sur Habré «
Comment j'ai trouvé un bug dans les processeurs Intel Skylake ». La situation qui y est décrite était très similaire à la nôtre, mais l'auteur a avancé plus avant dans l'enquête et avancé la théorie selon laquelle l'erreur était en microcode. Et lors de la mise à jour des noyaux Linux, les fabricants mettent également à jour le microcode.
Poursuite du développement du système
Bien que nous nous soyons débarrassés de l'erreur, cette histoire nous a fait reconsidérer l'architecture du système. Après tout, nous n'étions pas protégés contre la répétition de tels bugs.
Les principes suivants ont constitué la base de nouvelles améliorations du système de sauvegarde:
- Vous ne pouvez faire confiance à personne. Les serveurs peuvent ne pas fonctionner correctement.
- Redondance majoritaire.
- Création d'un consensus. Comme complément logique à la redondance majoritaire.
- Des doubles échecs sont possibles.
- Vitalité. Le nouveau système de disques de rechange ne devrait pas être pire que le précédent. Le commerce devrait se dérouler sans heurts jusqu'au dernier serveur.
- Une légère augmentation du retard. Tout temps d'arrêt entraîne d'énormes pertes financières.
- Interaction minimale avec le réseau afin que le retard soit aussi faible que possible.
- Sélectionnez un nouveau serveur maître en quelques secondes.
Aucune des solutions disponibles sur le marché ne nous convenait, et le protocole Raft n'en était qu'à ses balbutiements, nous avons donc créé notre propre solution.

Connectivité réseau
En plus du système de sauvegarde, nous avons commencé à moderniser la connectivité réseau. Le sous-système d'E / S était une multitude de processus qui, de la pire façon, affectaient la gigue et le retard. Ayant des centaines de processus qui traitent les connexions TCP, nous avons été obligés de basculer constamment entre eux, et à l'échelle microseconde, c'est une opération assez longue. Mais le pire est que lorsqu'un processus a reçu un paquet à traiter, il l'a envoyé à une file d'attente SystemV, puis a attendu les événements d'une autre file d'attente SystemV. Cependant, avec un grand nombre de nœuds, l'arrivée d'un nouveau paquet TCP dans un processus et la réception de données dans une file d'attente dans un autre représentent deux événements concurrents pour l'OS. Dans ce cas, si aucun processeur physique n'est disponible pour les deux tâches, un sera traité et le second se trouvera dans la file d'attente. Il est impossible de prévoir les conséquences.
Dans de telles situations, vous pouvez appliquer un contrôle de priorité de processus dynamique, mais cela nécessitera l'utilisation d'appels système gourmands en ressources. En conséquence, nous sommes passés à un thread en utilisant le epoll classique, ce qui a considérablement augmenté la vitesse et réduit le temps de traitement de la transaction. Nous nous sommes également débarrassés de certains processus d'interaction réseau et d'interaction via SystemV, avons considérablement réduit le nombre d'appels système et avons commencé à contrôler les priorités des opérations. En utilisant un seul sous-système d'E / S, il a été possible d'économiser environ 8 à 17 microsecondes, selon le scénario. Ce schéma à thread unique a depuis été appliqué sans changement, un flux epoll avec une marge suffit pour desservir toutes les connexions.
Traitement des transactions
La charge croissante de notre système a nécessité la modernisation de presque tous ses composants. Mais, malheureusement, la stagnation de l'augmentation de la vitesse d'horloge du processeur ces dernières années ne nous a plus permis de faire évoluer les processus «de front». Par conséquent, nous avons décidé de diviser le processus Engine en trois niveaux, le plus chargé étant le système de vérification des risques, qui évalue la disponibilité des fonds dans les comptes et crée les transactions elles-mêmes. Mais l'argent peut être dans différentes devises, et il était nécessaire de déterminer sur quel principe diviser le traitement des demandes.
La solution logique est de diviser par devise: un serveur se négocie en dollars, un autre en livres et un troisième euro. Mais si, avec un tel schéma, deux transactions sont envoyées pour acheter des devises différentes, alors il y aura un problème de portefeuilles désynchronisés. Et la synchronisation est difficile et coûteuse. Par conséquent, il sera correct de tailler séparément sur les portefeuilles et séparément sur les outils. Soit dit en passant, dans la plupart des échanges occidentaux, la tâche de vérification des risques n'est pas aussi aiguë que la nôtre, donc le plus souvent, cela se fait hors ligne. Nous devions mettre en place une vérification en ligne.
Illustrons par un exemple. Le trader veut acheter 30 $, et la demande va valider la transaction: on vérifie si ce trader est autorisé à ce mode de trading, s'il a les droits nécessaires. Si tout est en ordre, la demande est transmise au système de vérification des risques, c'est-à-dire vérifier la suffisance des fonds pour conclure une transaction. Il est à noter que le montant requis est actuellement bloqué. De plus, la demande est redirigée vers le système de trading, qui approuve ou n'approuve pas cette transaction. Disons que la transaction est approuvée - alors le système de vérification des risques note que l'argent est débloqué et que les roubles sont convertis en dollars.
En général, le système de vérification des risques contient des algorithmes complexes et effectue une grande quantité de calculs très gourmands en ressources, et ne vérifie pas seulement le «solde du compte», comme cela peut sembler à première vue.
Lorsque nous avons commencé à diviser le processus Engine en niveaux, nous avons rencontré un problème: le code qui était disponible à l'époque aux étapes de validation et de vérification utilisait activement le même tableau de données, ce qui nécessitait de réécrire la base de code entière. En conséquence, nous avons emprunté une méthodologie pour le traitement des instructions des processeurs modernes: chacun d'eux est divisé en petites étapes et plusieurs actions sont effectuées en parallèle dans un cycle.
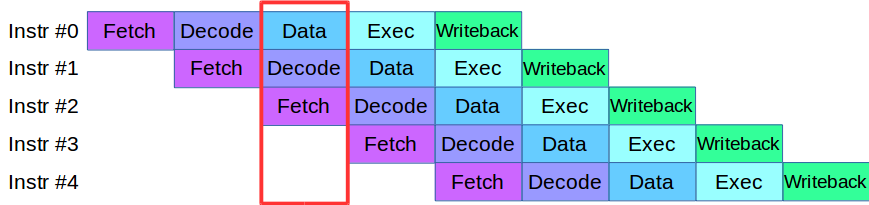
Après une petite adaptation du code, nous avons créé un pipeline pour le traitement parallèle des transactions, dans lequel la transaction a été divisée en 4 étapes du pipeline: interaction réseau, validation, exécution et publication du résultat

Prenons un exemple. Nous avons deux systèmes de traitement, série et parallèle. La première transaction arrive et dans les deux systèmes, elle est validée. Ensuite, la deuxième transaction arrive: dans un système parallèle, elle est immédiatement mise au travail, et dans un système séquentiel, elle est mise en file d'attente en attendant que la première transaction passe par l'étape de traitement en cours. Autrement dit, le principal avantage du pipelining est que nous traitons la file d'attente de transactions plus rapidement.
Nous avons donc obtenu le système ASTS +.
Certes, avec les convoyeurs aussi, tout n'est pas si lisse. Supposons que nous ayons une transaction qui affecte les tableaux de données dans une transaction voisine, c'est une situation typique pour l'échange. Une telle transaction ne peut pas être exécutée dans le pipeline, car elle peut affecter d'autres personnes. Cette situation est appelée risque de données, et ces transactions sont simplement traitées séparément: lorsque les transactions «rapides» dans la file d'attente se terminent, le pipeline s'arrête, le système traite la transaction «lente», puis redémarre le pipeline. Heureusement, la part de ces transactions dans le flux total est très faible, de sorte que le pipeline s'arrête si rarement qu'il n'affecte pas les performances globales.

Ensuite, nous avons commencé à résoudre le problème de la synchronisation de trois threads d'exécution. En conséquence, un système basé sur un tampon circulaire avec des cellules de taille fixe est né. Dans ce système, tout est soumis à la vitesse de traitement, les données ne sont pas copiées.
- Tous les paquets réseau entrants entrent dans la phase d'allocation.
- Nous les plaçons dans un tableau et marquons qu'ils sont disponibles pour l'étape n ° 1.
- La deuxième transaction est arrivée, elle est à nouveau disponible pour l'étape n ° 1.
- Le premier flux de traitement voit les transactions disponibles, les traite et les transfère à l'étape suivante du deuxième flux de traitement.
- Ensuite, il traite la première transaction et marque la cellule correspondante avec l'indicateur
deleted - il est maintenant disponible pour une nouvelle utilisation.
Ainsi, la file d'attente entière est traitée.
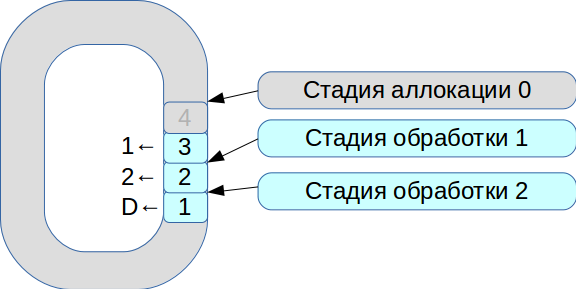
Le traitement de chaque étape prend des unités ou des dizaines de microsecondes. Et si vous utilisez des schémas de synchronisation de système d'exploitation standard, nous perdrons plus de temps sur la synchronisation elle-même. Par conséquent, nous avons commencé à utiliser spinlock. Cependant, c'est une très mauvaise tonalité dans un système en temps réel, et RedHat recommande fortement de ne pas le faire, nous utilisons donc le verrouillage de spin pendant 100 ms, puis passons en mode sémaphore pour exclure la possibilité d'un blocage.
En conséquence, nous avons atteint une performance d'environ 8 millions de transactions par seconde. Et à peine deux mois plus tard, dans un
article sur le disjoncteur LMAX, ils ont vu la description d'un circuit avec la même fonctionnalité.
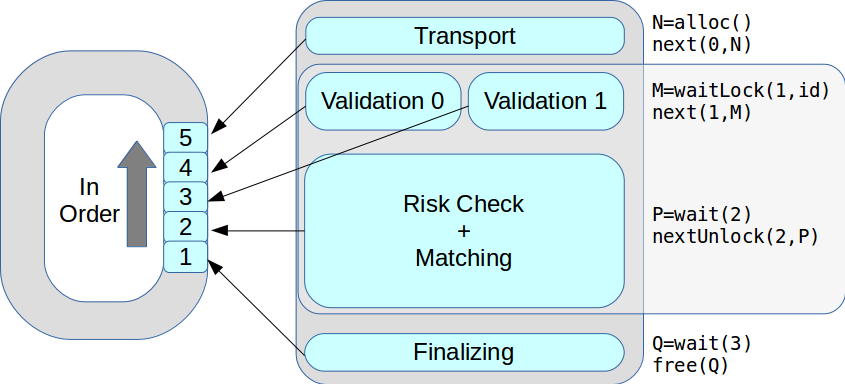
Maintenant, à un moment donné, il pourrait y avoir plusieurs fils d'exécution. Toutes les transactions ont été traitées successivement, dans l'ordre reçu. En conséquence, les performances de pointe sont passées de 18 000 à 50 000 transactions par seconde.
Système de gestion des risques de change
Il n'y a pas de limite à la perfection, et bientôt nous avons recommencé à nous moderniser: dans le cadre d'ASTS +, nous avons commencé à transférer les systèmes de gestion des risques et les opérations de règlement en composants autonomes. Nous avons développé une architecture moderne flexible et un nouveau modèle de risque hiérarchique, essayé dans la mesure du possible d'utiliser la classe
fixed_point au lieu de
double .
Mais aussitôt le problème s'est posé: comment synchroniser toute la logique métier qui fonctionne depuis de nombreuses années et la transférer vers le nouveau système? En conséquence, la première version du prototype du nouveau système a dû être abandonnée. La deuxième version, qui travaille actuellement en production, est basée sur le même code qui fonctionne à la fois dans la partie trading et dans la partie risque. Pendant le développement, le plus difficile a été de faire fusionner git entre les deux versions. Notre collègue Evgeny Mazurenok a effectué cette opération chaque semaine et maudit à chaque fois très longtemps.
Lors de la sélection d'un nouveau système, nous avons immédiatement dû résoudre le problème d'interaction. Lors du choix d'un bus de données, il était nécessaire d'assurer une gigue stable et un retard minimal. Pour cela, le réseau InfiniBand RDMA est le mieux adapté: le temps de traitement moyen est 4 fois inférieur à celui des réseaux Ethernet 10 G. Mais la vraie différence était dans les centiles - 99 et 99,9.
Bien sûr, InfiniBand a ses propres difficultés. Tout d'abord, une autre API est ibverbs au lieu de sockets. Deuxièmement, il n'y a presque pas de solutions de messagerie open source largement disponibles. Nous avons essayé de fabriquer notre prototype, mais cela s'est avéré très difficile, nous avons donc choisi une solution commerciale - Confinity Low Latency Messaging (anciennement IBM MQ LLM).
Le problème s'est alors posé de séparer correctement le système de risques. Si vous retirez simplement le moteur de risque et ne créez pas de nœud intermédiaire, les transactions provenant de deux sources peuvent être mélangées.
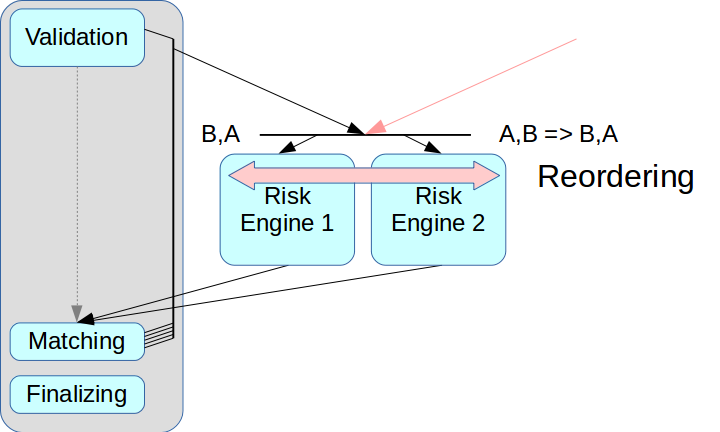
Les solutions dites à très faible latence ont un mode de réorganisation: les transactions à partir de deux sources peuvent être organisées dans le bon ordre à la réception, ceci est réalisé en utilisant un canal séparé pour échanger des informations sur la séquence. Mais nous n'appliquons pas encore ce mode: il complique tout le processus, et dans certaines solutions il n'est pas du tout supporté. De plus, chaque transaction devrait se voir attribuer les horodatages appropriés, et dans notre schéma, ce mécanisme est très difficile à mettre en œuvre correctement. Par conséquent, nous avons utilisé le schéma classique avec Message Broker, c'est-à-dire avec un répartiteur qui distribue les messages entre Risk Engine.
Le deuxième problème était lié à l'accès client: s'il existe plusieurs passerelles de risque, le client doit se connecter à chacune d'entre elles, et pour cela, vous devrez apporter des modifications à la couche client. Nous voulions nous éloigner de cela à ce stade, donc dans le schéma actuel de Risk Gateway, ils traitent l'intégralité du flux de données. Cela limite considérablement le débit maximal, mais simplifie considérablement l'intégration du système.
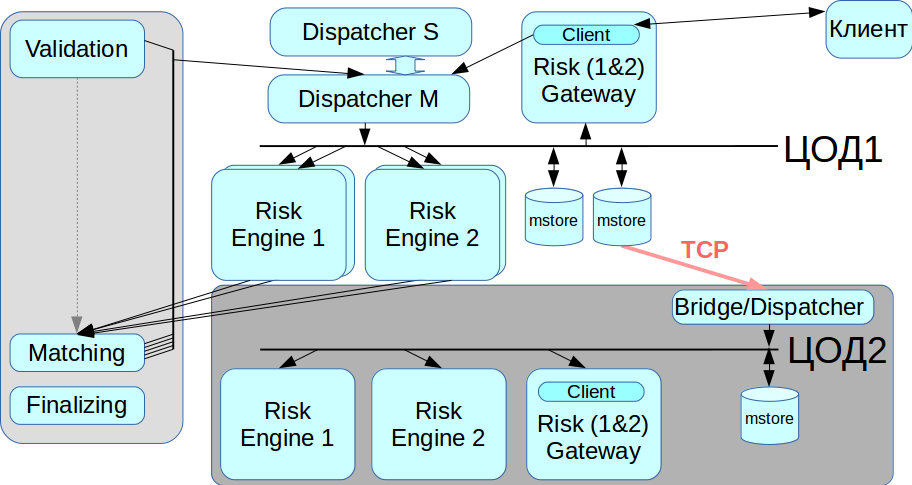
Duplication
Notre système ne doit pas avoir un seul point de défaillance, c'est-à-dire que tous les composants doivent être dupliqués, y compris un courtier de messages. Nous avons résolu ce problème en utilisant le système CLLM: il contient un cluster RCMS dans lequel deux répartiteurs peuvent travailler en mode maître-esclave, et quand l'un échoue, le système bascule automatiquement vers l'autre.
Travailler avec un centre de données de sauvegarde
InfiniBand est optimisé pour fonctionner comme un réseau local, c'est-à-dire pour connecter des équipements montés en rack, et il n'y a aucun moyen de disposer un réseau InfiniBand entre deux centres de données géographiquement distribués. Par conséquent, nous avons implémenté un pont / répartiteur qui se connecte à la mémoire de messages via des réseaux Ethernet réguliers et relaie toutes les transactions vers le deuxième réseau IB. Lorsque vous avez besoin d'une migration à partir du centre de données, nous pouvons choisir avec quel centre de données travailler maintenant.
Résumé
Tout cela n'a pas été fait en même temps, il a fallu plusieurs itérations du développement d'une nouvelle architecture. Nous avons créé le prototype en un mois, mais il a fallu plus de deux ans pour finaliser les conditions de travail. Nous avons essayé de trouver le meilleur compromis entre l'augmentation de la durée du traitement des transactions et l'augmentation de la fiabilité du système.
Depuis que le système a été fortement mis à jour, nous avons implémenté la récupération de données à partir de deux sources indépendantes. Si, pour une raison quelconque, la mémoire de messages ne fonctionne pas correctement, vous pouvez extraire le journal des transactions d'une deuxième source - à partir de Risk Engine. Ce principe est respecté dans l'ensemble du système.
Entre autres choses, nous avons réussi à conserver l'API client afin que ni les courtiers ni personne d'autre ne nécessitent une modification importante de la nouvelle architecture. J'ai dû changer certaines interfaces, mais je n'ai pas eu besoin d'apporter de modifications importantes au modèle de travail.
Nous avons appelé la version actuelle de notre plate-forme Rebus - comme abréviation pour les deux innovations les plus notables en architecture, Risk Engine et BUS.
Initialement, nous voulions mettre en évidence uniquement la partie compensation, mais le résultat était un énorme système distribué. Désormais, les clients peuvent interagir avec Trading Gateway, ou avec compensation, ou avec les deux à la fois.
Ce que nous avons finalement réalisé:

Réduction du niveau de retard. Avec un petit volume de transactions, le système fonctionne de la même manière que la version précédente, mais résiste en même temps à une charge beaucoup plus élevée.
Le pic de productivité est passé de 50 000 à 180 000 transactions par seconde. Un autre flux d'informations entrave la poursuite de la croissance.
: matching Gateway. Gateway , .
, -: