Aux États-Unis seulement, 3 millions de personnes handicapées ne peuvent pas quitter leur domicile. Des robots auxiliaires capables de parcourir automatiquement de longues distances peuvent rendre ces personnes plus indépendantes en leur apportant de la nourriture, des médicaments et des emballages. Des études montrent que l'apprentissage en profondeur avec renforcement (OP) est bien adapté pour comparer des données et des actions d'entrée brutes, par exemple, pour apprendre à
capturer des objets ou à
déplacer des robots , mais généralement les
agents OP ne comprennent pas les grands espaces physiques nécessaires pour une orientation sûre à longue distance distances sans aide humaine et adaptation à un nouvel environnement.
Dans trois travaux récents, «La
course d'orientation à partir de zéro avec AOP », «
PRM-RL: mise en œuvre de l'orientation robotique sur de longues distances en utilisant une combinaison d'apprentissage par renforcement et de planification basée sur les modèles » et «
Orientation à longue distance avec PRM-RL », nous avons Nous étudions des robots autonomes qui s'adaptent facilement à un nouvel environnement, combinant une OP profonde avec une planification à long terme. Nous enseignons aux agents de planification locaux comment effectuer les actions de base nécessaires à l'orientation et comment se déplacer sur de courtes distances sans collision avec des objets en mouvement. Les planificateurs locaux effectuent des observations environnementales bruyantes à l'aide de capteurs tels que des lidars unidimensionnels qui fournissent la distance à un obstacle et fournissent des vitesses linéaires et angulaires pour contrôler le robot. Nous formons le planificateur local aux simulations utilisant l'apprentissage automatique par renforcement (AOP), une méthode qui automatise la recherche de récompenses pour l'OP et l'architecture du réseau de neurones. Malgré la portée limitée de 10 à 15 m, les planificateurs locaux s'adaptent bien à la fois à l'utilisation dans de vrais robots et à de nouveaux environnements jusque-là inconnus. Cela vous permet de les utiliser comme blocs de construction pour l'orientation sur de grands espaces. Ensuite, nous construisons une feuille de route, un graphique où les nœuds sont des sections distinctes, et les bords connectent les nœuds uniquement si des planificateurs locaux, imitant bien de vrais robots utilisant des capteurs et des contrôles bruyants, peuvent se déplacer entre eux.
Apprentissage automatique par renforcement (AOP)
Dans
notre premier travail, nous formons un planificateur local dans un petit environnement statique. Cependant, lors de l'apprentissage avec l'algorithme OP profond standard, par exemple le gradient déterministe profond (
DDPG ), il y a plusieurs obstacles. Par exemple, le véritable objectif des planificateurs locaux est d'atteindre un objectif donné, grâce auquel ils reçoivent de rares récompenses. En pratique, cela oblige les chercheurs à consacrer un temps considérable à la mise en œuvre pas à pas de l'algorithme et à l'ajustement manuel des bourses. Les chercheurs doivent également prendre des décisions sur l'architecture des réseaux de neurones sans avoir de recettes claires et réussies. Enfin, des algorithmes tels que DDPG apprennent de manière instable et présentent souvent un
oubli catastrophique .
Pour surmonter ces obstacles, nous avons automatisé le deep learning avec renforcement. AOP est un wrapper automatique évolutif autour d'un OP profond, recherchant des récompenses et une architecture de réseau neuronal grâce
à une optimisation hyperparamétrique à
grande échelle . Il fonctionne en deux temps, la recherche de récompenses et la recherche d'architecture. Pendant la recherche de récompenses, AOP forme simultanément la population d'agents DDPG pendant plusieurs générations, et chacun a sa propre fonction de récompense légèrement modifiée, optimisée pour la vraie tâche du planificateur local: atteindre le point final du chemin. À la fin de la phase de recherche de récompense, nous en sélectionnons une qui conduit le plus souvent les agents à l'objectif. Dans la phase de recherche de l'architecture du réseau neuronal, nous répétons ce processus, en utilisant le prix sélectionné pour cette course et en ajustant les couches du réseau, en optimisant le prix cumulatif.
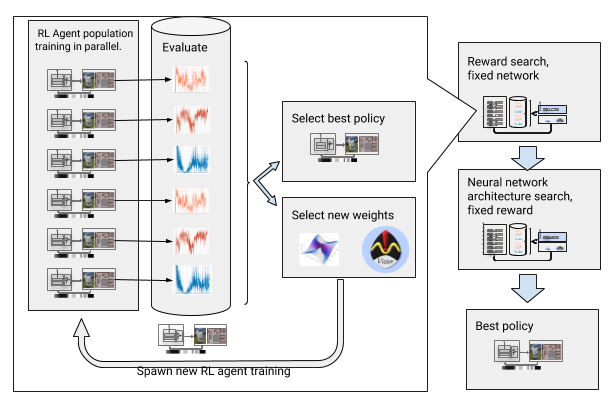 AOP à la recherche de prix et d'architecture du réseau neuronal
AOP à la recherche de prix et d'architecture du réseau neuronalCependant, ce processus étape par étape rend l'AOP inefficace en termes de nombre d'échantillons. La formation AOP avec 10 générations de 100 agents nécessite 5 milliards d'échantillons, soit 32 ans d'études! L'avantage est qu'après AOP, le processus d'apprentissage manuel est automatisé et DDPG n'a pas d'oubli catastrophique. Plus important encore, la qualité des politiques finales est plus élevée - elles résistent au bruit provenant du capteur, du lecteur et de la localisation, et sont bien généralisées à de nouveaux environnements. Notre meilleure politique est 26% plus efficace que les autres méthodes d'orientation sur nos sites de test.
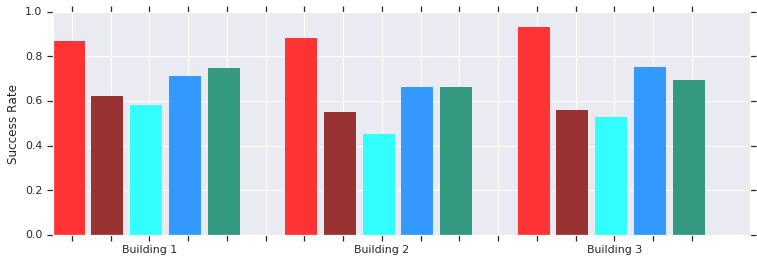 Rouge - Succès de l'AOP sur de courtes distances (jusqu'à 10 m) dans plusieurs bâtiments jusque-là inconnus. Comparaison avec DDPG entraîné manuellement (rouge foncé), champs de potentiel artificiel (bleu), fenêtre dynamique (bleu) et clonage de comportement (vert).La politique du planificateur AOP local fonctionne bien avec les robots dans des environnements réels non structurés
Rouge - Succès de l'AOP sur de courtes distances (jusqu'à 10 m) dans plusieurs bâtiments jusque-là inconnus. Comparaison avec DDPG entraîné manuellement (rouge foncé), champs de potentiel artificiel (bleu), fenêtre dynamique (bleu) et clonage de comportement (vert).La politique du planificateur AOP local fonctionne bien avec les robots dans des environnements réels non structurésEt bien que ces politiciens ne soient capables que d'une orientation locale, ils résistent aux obstacles mobiles et sont bien tolérés par de vrais robots dans des environnements non structurés. Et bien qu'ils aient été formés aux simulations avec des objets statiques, ils gèrent efficacement les objets en mouvement. L'étape suivante consiste à combiner les politiques AOP avec une planification basée sur des échantillons afin d'élargir leur domaine de travail et leur apprendre à naviguer sur de longues distances.
Orientation longue distance avec PRM-RL
Les planificateurs basés sur des modèles fonctionnent avec une orientation à longue distance, rapprochant les mouvements du robot. Par exemple, un robot crée
des feuilles de route probabilistes (PRM) en dessinant des chemins de transition entre les sections. Dans notre
deuxième travail , qui a remporté le prix lors de la conférence
ICRA 2018 , nous combinons PRM avec des programmateurs OP locaux réglés manuellement (sans AOP) pour former des robots localement, puis les adapter à d'autres environnements.
Tout d'abord, pour chaque robot, nous formons la politique du planificateur local dans une simulation généralisée. Ensuite, nous créons un PRM prenant en compte cette politique, le soi-disant PRM-RL, basé sur une carte de l'environnement où il sera utilisé. La même carte peut être utilisée pour tout robot que nous souhaitons utiliser dans le bâtiment.
Pour créer un PRM-RL, nous combinons des nœuds à partir d'échantillons uniquement si le planificateur OP local peut se déplacer de manière fiable et répétée entre eux. Cela se fait dans une simulation Monte Carlo. La carte résultante s'adapte aux capacités et à la géométrie d'un robot particulier. Les cartes pour robots ayant la même géométrie, mais avec différents capteurs et lecteurs, auront une connectivité différente. Étant donné que l'agent peut tourner autour du coin, des nœuds qui ne sont pas en ligne de vue directe peuvent également être inclus. Cependant, les nœuds adjacents aux murs et aux obstacles seront moins susceptibles d'être inclus dans la carte en raison du bruit du capteur. Au moment de l'exécution, l'agent OP se déplace sur la carte d'une section à l'autre.
 Une carte est créée avec trois simulations de Monte Carlo pour chaque paire de nœuds sélectionnée au hasard
Une carte est créée avec trois simulations de Monte Carlo pour chaque paire de nœuds sélectionnée au hasard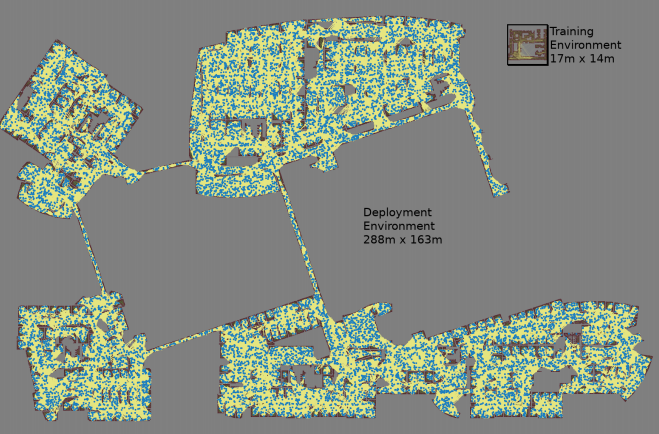 La plus grande carte mesurait 288 x 163 m et contenait près de 700 000 bords. 300 travailleurs l'ont récupéré pendant 4 jours, après avoir effectué 1,1 milliard de contrôles de collision.Le troisième ouvrage
La plus grande carte mesurait 288 x 163 m et contenait près de 700 000 bords. 300 travailleurs l'ont récupéré pendant 4 jours, après avoir effectué 1,1 milliard de contrôles de collision.Le troisième ouvrage apporte plusieurs améliorations au PRM-RL d'origine. Premièrement, nous remplaçons le DDPG réglé manuellement par des ordonnanceurs AOP locaux, ce qui améliore l'orientation sur de longues distances. Deuxièmement, des
cartes de localisation et de marquage simultanés (
SLAM ) sont ajoutées, que les robots utilisent au moment de l'exécution comme source pour créer des feuilles de route. Les cartes SLAM sont sujettes au bruit, ce qui comble le «fossé entre le simulateur et la réalité», un problème bien connu en robotique, à cause duquel les agents formés aux simulations se comportent bien pire dans le monde réel. Notre niveau de réussite dans la simulation coïncide avec le niveau de réussite de vrais robots. Enfin, nous avons ajouté des cartes de construction réparties, afin de pouvoir créer de très grandes cartes contenant jusqu'à 700 000 nœuds.
Nous avons évalué cette méthode avec l'aide de notre agent AOP, qui a créé des cartes basées sur des dessins de bâtiments qui ont dépassé l'environnement d'entraînement de 200 fois dans la zone, y compris uniquement les côtes, qui ont été réussies dans 90% des cas en 20 tentatives. Nous avons comparé PRM-RL avec différentes méthodes à des distances allant jusqu'à 100 m, ce qui dépassait considérablement la portée du planificateur local. PRM-RL a obtenu un succès 2 à 3 fois plus souvent que les méthodes conventionnelles grâce à la connexion correcte des nœuds, adaptée aux capacités du robot.
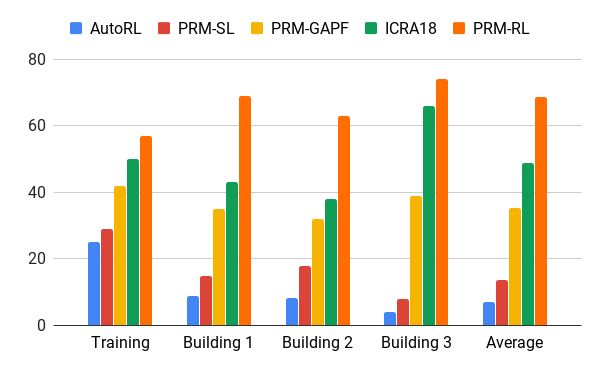 Taux de réussite du déplacement de 100 m dans différents bâtiments. Bleu - planificateur AOP local, premier travail; rouge - PMR d'origine; jaune - champs potentiels artificiels; le vert est le deuxième emploi; rouge - le troisième travail, PRM avec AOP.
Taux de réussite du déplacement de 100 m dans différents bâtiments. Bleu - planificateur AOP local, premier travail; rouge - PMR d'origine; jaune - champs potentiels artificiels; le vert est le deuxième emploi; rouge - le troisième travail, PRM avec AOP.Nous avons testé PRM-RL sur de nombreux robots réels dans de nombreux bâtiments. Voici l'une des suites de tests; le robot se déplace de manière fiable presque partout, à l'exception des endroits et des zones les plus en désordre qui dépassent la carte SLAM.

Conclusion
L'orientation machine peut sérieusement augmenter l'indépendance des personnes à mobilité réduite. Cela peut être réalisé en développant des robots autonomes qui peuvent facilement s'adapter à l'environnement et aux méthodes disponibles pour la mise en œuvre dans le nouvel environnement sur la base des informations existantes. Cela peut être fait en automatisant la formation d'orientation de base sur de courtes distances avec AOP, puis en utilisant les compétences acquises avec des cartes SLAM pour créer des feuilles de route. Les feuilles de route sont constituées de nœuds reliés par des nervures, sur lesquels les robots peuvent se déplacer de manière fiable. En conséquence, une politique de comportement du robot est développée qui, après une formation, peut être utilisée dans différents environnements et émettre des feuilles de route spécialement adaptées pour un robot particulier.