Salut Je m'appelle Andrey, je suis un étudiant diplômé dans l'une des universités techniques de Moscou et à temps partiel très modeste entrepreneur et développeur novice. Dans cet article, j'ai décidé de partager mon expérience de passage de PHP (que j'aimais autrefois en raison de sa simplicité, mais que j'ai finalement détesté - j'explique pourquoi sous la coupe) à NodeJS. Des tâches très triviales et apparemment élémentaires peuvent être données ici, que j'ai néanmoins été personnellement curieux de résoudre lors de ma connaissance de NodeJS et des fonctionnalités de développement côté serveur en JavaScript. J'essaierai d'expliquer et de démontrer clairement que PHP est finalement entré dans le coucher du soleil et a cédé la place à NodeJS. Peut-être qu'il sera même utile pour quelqu'un d'apprendre certaines fonctionnalités du rendu des pages HTML dans Node, qui ne sont pas du tout adaptées à cela à partir du mot.
Présentation
Lors de l'écriture du moteur, j'ai utilisé les techniques les plus simples. Pas de gestionnaires de paquets, pas de routage. Seuls les dossiers inconditionnels, dont le nom correspond à l'itinéraire demandé, et index.php dans chacun d'eux, configurés par PHP-FPM pour prendre en charge le pool de processus. Plus tard, il est devenu nécessaire d'utiliser Composer et Laravel, qui a été la dernière goutte pour moi. Avant de passer à l'histoire de la raison pour laquelle j'ai même décidé de tout réécrire, de PHP à NodeJS, je vais vous parler un peu de l'arrière-plan.
Gestionnaire de paquets
Fin 2018, il m'est arrivé de travailler sur un projet écrit en Laravel. Il a fallu corriger plusieurs bugs, apporter des modifications aux fonctionnalités existantes, ajouter quelques nouveaux boutons dans l'interface. Le processus a commencé par l'installation du package et du gestionnaire de dépendances. En PHP, Composer est utilisé pour cela. Ensuite, le client a fourni un serveur avec 1 cœur et 512 mégaoctets de RAM et c'était ma première expérience avec Composer. Lors de l'installation de dépendances sur un serveur privé virtuel avec 512 mégaoctets de mémoire, le processus s'est bloqué en raison d'un manque de mémoire.

Pour moi, en tant que personne familière avec Linux et expérimentée dans le travail avec Debian et Ubuntu, la solution à ce problème était évidente - installer un fichier SWAP (un fichier d'échange - pour ceux qui ne sont pas familiers avec l'administration Linux). Un développeur novice et inexpérimenté qui a installé sa première distribution Laravel sur Digital Ocean, par exemple, va simplement au panneau de contrôle et augmente le tarif jusqu'à ce que l'installation des dépendances s'arrête avec une erreur de segmentation de la mémoire. Et NodeJS?
Et NodeJS a son propre gestionnaire de packages - npm. Il est beaucoup plus facile à utiliser, plus compact, peut fonctionner même dans un environnement avec un minimum de RAM. En général, il n'y a rien à reprocher à Composer contre NPM, cependant, en cas d'erreur lors de l'installation des packages, Composer se bloquera comme une application PHP ordinaire et vous ne saurez jamais quelle partie du package a été installée et si elle a été installée à la fin se termine. En général, pour l'administrateur Linux, l'installation dpkg --configure -a = flashbacks en mode Rescue et dpkg --configure -a . Au moment où ces «surprises» m'ont dépassé, je n'aimais pas PHP, mais ce sont les derniers clous dans le cercueil de mon grand amour pour PHP.
Problème de support et de version à long terme
Rappelez-vous quel type de battage médiatique et d'étonnement a causé PHP7 lorsque les développeurs l'ont présenté pour la première fois? Augmentation de la productivité de plus de 2 fois, et dans certains composants jusqu'à 5 fois! Rappelez-vous quand la septième version de PHP est née? Et à quelle vitesse WordPress a gagné! C'était en décembre 2015. Saviez-vous que PHP 7.0 est désormais considéré comme une version obsolète de PHP et il est fortement recommandé de le mettre à jour ... Non, pas à la version 7.1, mais à la version 7.2. Selon les développeurs, la version 7.1 est déjà privée de support actif et ne reçoit que des mises à jour de sécurité. Et après 8 mois, cela s'arrêtera. Il cessera, avec le support actif et la version 7.2. Il s'avère qu'à la fin de cette année, PHP n'aura qu'une seule version actuelle - 7.3.

En fait, ce ne serait pas compliqué et je n'attribuerais pas cela aux raisons de mon départ de PHP si les projets que j'ai écrits en PHP 7.0. Revenons au projet où l'installation des dépendances s'est écrasée. Il s'agit d'un projet écrit en 2015 sur Laravel 4 avec PHP 5.6. Il semblait que seulement 4 ans s'étaient écoulés, mais non - un tas d'avertissements de dépréciation, des modules obsolètes, l'impossibilité de mettre à niveau vers Laravel 5 normalement en raison d'un tas de mises à jour du moteur racine.
Et cela ne s'applique pas seulement à Laravel. Essayez d'obtenir n'importe quelle application PHP écrite pendant le support actif des premières versions de PHP 7.0 et préparez-vous à passer votre soirée à chercher des solutions aux problèmes survenus dans les modules PHP obsolètes. Enfin, un fait intéressant: la prise en charge de PHP 7.0 a été interrompue plus tôt que la prise en charge de PHP 5.6. Une seconde.
Et NodeJS? Je ne dirais pas que tout va bien mieux ici et que les périodes de support pour NodeJS sont fondamentalement différentes de PHP. Non, c'est à peu près la même chose ici - chaque version LTS est prise en charge pendant 3 ans. Mais NodeJS a un peu plus de ces versions les plus récentes.
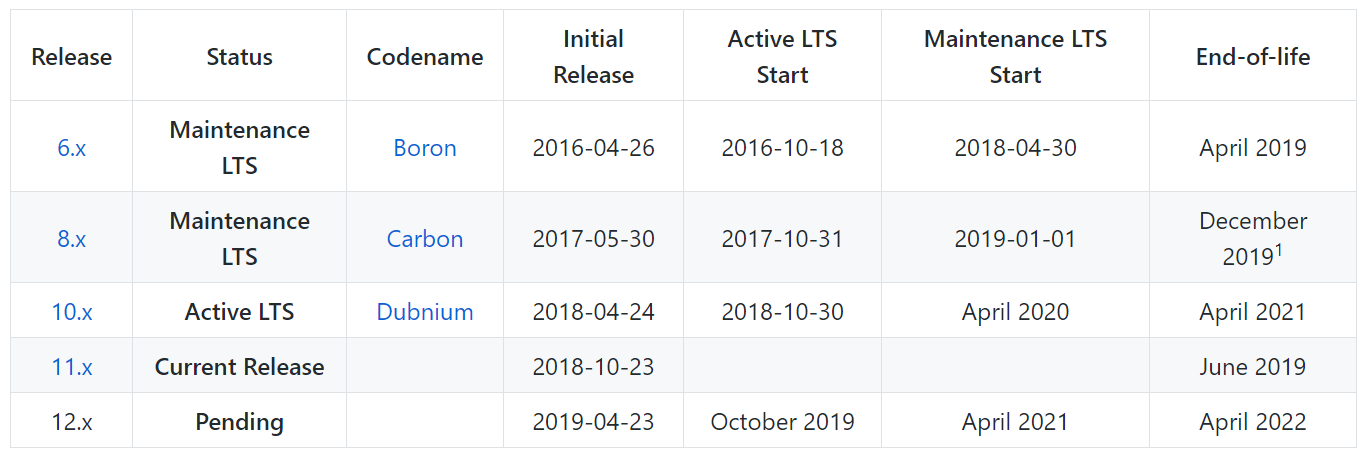
Si vous devez déployer une application écrite en 2016, assurez-vous que vous n'aurez absolument aucun problème avec cela. Par ailleurs, la version 6. * ne sera plus prise en charge uniquement en avril de cette année. Et devant, il y a 8, 10, 11 et les 12 prochains.
Difficultés et surprises lors du passage à NodeJS
Je vais peut-être commencer par la question la plus intéressante pour moi sur la façon de rendre les pages HTML dans NodeJS. Mais rappelons-nous d'abord comment cela se fait en PHP:
- Intégrez du HTML directement dans le code PHP. Il en va de même pour tous les débutants qui n'ont pas encore atteint MVC. Et c'est donc fait dans WordPress, ce qui est absolument horrible.
- Utilisez MVC, qui devrait simplifier l'interaction du développeur et fournir une sorte de division du projet en parties, mais en réalité, cette approche ne fait que tout compliquer à certains moments.
- Utilisez un moteur de modèle. L'option la plus pratique, mais pas en PHP. Regardez simplement la syntaxe suggérée dans Twig ou Blade avec des accolades et des pourcentages bouclés.
Je suis un ardent opposant à la combinaison ou à la fusion de plusieurs technologies. HTML doit exister séparément, les styles séparément, JavaScript séparément (dans React, cela semble généralement monstrueux - HTML et JavaScript sont mélangés). C'est pourquoi l'option idéale pour les développeurs ayant des préférences comme la mienne est un moteur de modèle. Je n'ai pas eu à le rechercher depuis longtemps pour une application web sur NodeJS et j'ai opté pour Jade (PugJS). Appréciez simplement la simplicité de sa syntaxe:
div.row.links div.col-lg-3.col-md-3.col-sm-4 h4.footer-heading . div.copyright div.copy-text 2017 - #{current_year} . div.contact-link span : a(href='mailto:hello@flaut.ru') hello@flaut.ru
Tout est assez simple ici: j'ai écrit un modèle, je l'ai téléchargé dans l'application, je l'ai compilé une fois et je l'utilise ensuite à n'importe quel endroit et à n'importe quel moment. À mon avis, les performances de PugJS sont environ 2 fois meilleures que le rendu en incorporant du HTML dans du code PHP. Si auparavant, en PHP, une page statique était générée par le serveur en environ 200-250 millisecondes, cette fois-ci est d'environ 90-120 millisecondes (nous ne parlons pas du rendu dans PugJS, mais du temps pris entre la demande de page et la réponse du serveur au client avec le code HTML prêt) ) Voici à quoi ressemble le chargement et la compilation de modèles et de leurs composants au stade du lancement de l'application:
const pugs = {} fs.readdirSync(__dirname + '/templates/').forEach(file => { if(file.endsWith('.pug')) { try { var filepath = __dirname + '/templates/' + file pugs[file.split('.pug')[0]] = pug.compile(fs.readFileSync(filepath, 'utf-8'), { filename: filepath }) } catch(e) { console.error(e) } } })
Cela semble incroyablement simple, mais avec Jade, il y avait un peu de complexité au stade du travail avec du code HTML déjà compilé. Le fait est que pour implémenter des scripts sur la page, une fonction asynchrone est utilisée, qui prend tous les fichiers .js du répertoire et ajoute la date de leur dernière modification à chacun d'eux. La fonction a la forme suivante:
for(let i = 0; i < files.length; i++) { let period = files[i].lastIndexOf('.')
En sortie, nous obtenons un tableau d'objets avec deux propriétés - le chemin d'accès au fichier et l'heure de sa dernière modification dans l'horodatage (pour la mise à jour du cache client). Le problème est que même au stade de la collecte des fichiers de script à partir d'un répertoire, ils sont tous chargés en mémoire strictement alphabétiquement (car ils sont situés dans le répertoire lui-même et les fichiers y sont collectés de haut en bas - du premier au dernier). Cela a conduit au fait que le fichier app.js a été chargé en premier, et déjà après il est venu le fichier core.min.js avec des polyfills et vendor.min.js à la toute fin. Ce problème a été résolu tout simplement - tri très banal:
scripts.sort((a, b) => { if(a.path.includes('core.min.js')) { return -1 } else if(a.path.includes('vendor.min.js')) { return 0 } return 1 })
En PHP, tout cela avait une apparence monstrueuse sous la forme de chemins vers des fichiers JS pré-écrits dans une chaîne. Simple mais peu pratique.
NodeJS conserve son application en RAM
C'est un énorme avantage. Tout est arrangé pour moi pour que sur le serveur en parallèle et indépendamment l'un de l'autre il y ait deux sites distincts - la version pour le développeur et la version de production. Imaginez que j'ai apporté des modifications aux fichiers PHP sur le site de développement et que j'ai besoin de déployer ces modifications en production. Pour ce faire, vous devez arrêter le serveur ou mettre un stub "désolé, tech. Work" et à ce moment copier les fichiers individuellement du dossier développeur vers le dossier de production. Cela provoque une sorte de temps d'arrêt et peut entraîner une perte de conversions. L'avantage de l' application en mémoire dans NodeJS est pour moi que toutes les modifications apportées aux fichiers du moteur ne seront effectuées qu'après son redémarrage. C'est très pratique, car vous pouvez copier tous les fichiers nécessaires avec les modifications, puis redémarrer le serveur. Le processus ne prend pas plus de 1 à 2 secondes et ne provoque pas de temps d'arrêt.
La même approche est utilisée dans nginx, par exemple. Vous modifiez d'abord la configuration, vérifiez-la avec nginx -t puis apportez des modifications avec le service nginx reload
Mise en cluster d'une application NodeJS
NodeJS a un outil très pratique - gestionnaire de processus pm2 . Comment exécutons-nous généralement les applications dans Node? Nous allons dans la console et écrivons le node index.js . Dès que nous fermons la console, l'application se ferme. C'est du moins ce qui se passe sur un serveur avec Ubuntu. Pour éviter cela et maintenir l'application toujours opérationnelle, ajoutez-la simplement à pm2 avec la simple commande pm2 start index.js --name production . Mais ce n'est pas tout. L'outil permet la surveillance ( pm2 monit ) et le clustering d'applications.
Rappelons-nous comment les processus sont organisés en PHP. Supposons que nginx traite les requêtes http et que nous devons transmettre la requête à PHP. Vous pouvez soit le faire directement, puis à chaque demande, un nouveau processus PHP apparaîtra et, une fois terminé, il sera tué. Ou vous pouvez utiliser un serveur fastcgi. Je pense que tout le monde sait ce que c'est et il n'est pas nécessaire d'entrer dans les détails, mais juste au cas où, je préciserai que PHP-FPM est le plus souvent utilisé comme fastcgi et sa tâche consiste à générer de nombreux processus PHP prêts à accepter et à traiter une nouvelle demande à tout moment. Quel est l'inconvénient de cette approche?
La première est que vous ne savez jamais combien de mémoire votre application consommera. Deuxièmement, vous serez toujours limité dans le nombre maximal de processus, et en conséquence, avec un bond important du trafic, votre application PHP utilisera toute la mémoire disponible et plantera, ou reposera sur la limite autorisée de processus et commencera à tuer les anciens. Cela peut être évité en définissant Je ne me souviens pas quel paramètre dans le fichier de configuration PHP-FPM en dynamique , puis autant de processus seront générés que nécessaire à ce stade. Mais encore une fois, une attaque DDoS élémentaire va consommer toute la RAM et mettre votre serveur. Ou, par exemple, un script de bogue va manger toute la RAM et le serveur se fige pendant un certain temps (il y avait des précédents dans le processus de développement).
La différence fondamentale dans NodeJS est que l'application ne peut pas consommer plus de 1,5 gigaoctets de RAM. Il n'y a aucune restriction de processus, il n'y a qu'une limite de mémoire. Cela vous encourage à écrire des programmes aussi légers que possible. De plus, il est très simple de calculer le nombre de clusters que nous pouvons nous permettre, en fonction de la ressource CPU disponible. Il est recommandé de ne pas suspendre plus d'un cluster sur chaque cœur (exactement comme dans nginx, pas plus d'un travailleur par cœur de processeur).

Un avantage de cette approche est que PM2 recharge successivement tous les clusters. Revenons au paragraphe précédent, qui parlait de 1 à 2 secondes d'arrêt pendant le redémarrage. En mode cluster, lorsque vous redémarrez le serveur, votre application ne connaîtra pas une milliseconde de temps d'arrêt.
NodeJS est un bon couteau suisse
Maintenant, il y a une telle situation où PHP agit comme un langage pour écrire des sites, et Python agit comme un outil pour explorer ces sites. NodeJS est 2 en 1, d'une part est une fourchette, de l'autre est une cuillère. Vous pouvez écrire des applications et des robots d'indexation rapides et puissants sur le même serveur au sein de la même application. Cela semble tentant. Mais comment cela peut-il se réaliser, demandez-vous? Google lui-même a déployé l'API Chromium officielle - Puppeteer. Vous pouvez lancer Headless Chrome (un navigateur sans interface utilisateur - Chrome "sans tête") et obtenir le plus large accès possible à l'API du navigateur pour explorer les pages. La façon la plus simple et la plus accessible de travailler avec Puppeteer .
Par exemple, dans notre groupe VKontakte, il y a régulièrement des remises et des offres spéciales vers diverses destinations à partir des villes de la CEI. Nous générons des images pour les articles en mode automatique, et pour les rendre belles, nous avons besoin de belles images. Je n'aime pas associer différentes API et créer des comptes sur des dizaines de sites.J'ai donc écrit une application simple qui imite un utilisateur ordinaire avec le navigateur Google Chrome qui parcourt le site avec des images stock et récupère au hasard l'image trouvée par le mot clé. J'avais l'habitude d'utiliser Python et BeautifulSoup pour cela, mais maintenant ce n'est plus nécessaire. Et la principale caractéristique et avantage de Puppeteer est que vous pouvez facilement tricher même sur les sites SPA, car vous avez à votre disposition un navigateur complet qui comprend et exécute le code JavaScript sur les sites. C'est douloureusement simple:
const browser = await puppeteer.launch({headless: true, args:['--no-sandbox']}) const page = (await browser.pages())[0] await page.goto(`https://pixabay.com/photos/search/${imageKeyword}/?cat=buildings&orientation=horizontal`, { waitUntil: 'networkidle0' })
Donc, en 3 lignes de code, nous avons lancé le navigateur et ouvert la page du site avec des images de stock. Maintenant, nous pouvons sélectionner un bloc aléatoire avec l'image sur la page et y ajouter une classe, dans laquelle plus tard nous pouvons tourner de la même manière et aller à la page directement avec l'image elle-même pour un chargement supplémentaire:
var imagesLength = await page.evaluate(() => { var photos = document.querySelectorAll('.search_results > .item') if(photos.length > 0) { photos[Math.floor(Math.random() * photos.length)].className += ' --anomaly_selected' } return photos.length })
Rappelez-vous combien de code il faudrait pour écrire ceci dans PhantomJS (qui, incidemment, a fermé et est entré en étroite collaboration avec l'équipe de développement de Puppeteer). Un outil aussi merveilleux peut-il empêcher quiconque de passer à NodeJS?
NodeJS fournit une asynchronie fondamentale
Cela peut être considéré comme un énorme avantage de NodeJS et JavaScript, en particulier avec l'avènement de l'async / wait dans ES2017. Contrairement à PHP, où tout appel est effectué de manière synchrone. Je vais donner un exemple simple. Auparavant, dans le moteur de recherche, des pages étaient générées sur le serveur, mais quelque chose devait être affiché sur la page déjà dans le client à l'aide de JavaScript, mais à ce moment-là, Yandex n'était pas encore en mesure d'utiliser JavaScript sur les sites Web et devait implémenter un mécanisme d'instantané (instantanés de page) spécifiquement pour cela. en utilisant Prerender. Des instantanés ont été stockés sur notre serveur et ont été envoyés au robot sur demande. Le dilemme était que ces images ont été générées en 3 à 5 secondes, ce qui est totalement inacceptable et peut affecter le classement du site dans les résultats de recherche. Pour résoudre ce problème, un algorithme simple a été inventé: lorsque le robot demande une page, un instantané dont nous disposons déjà, nous lui donnons simplement l'instantané existant, après quoi nous effectuons l'opération pour créer un nouvel instantané en arrière-plan et le remplacer déjà disponible. Comment cela a été fait en PHP:
exec('/usr/bin/php ' . __DIR__ . '/snapshot.php -a ' . $affiliation_type . ' -l ' . urlencode($full_uri) . ' > /dev/null 2>/dev/null &');
Ne fais jamais ça.
Dans NodeJS, cela peut être réalisé en appelant la fonction asynchrone:
async function saveSnapshot() { getSnapshot().then((res) => { db.saveSnapshot().then((status) => { if(status.err) console.error(err) }) }) } saveSnapshot()
En bref, vous n'essayez pas de contourner le synchronisme, mais vous décidez quand utiliser l'exécution de code synchrone et quand utiliser asynchrone. Et c'est vraiment pratique. Surtout lorsque vous découvrez les possibilités de Promise.all ()
Le moteur de recherche de vols lui-même est conçu de telle manière qu'il envoie une demande à un deuxième serveur qui collecte et agrège les données, puis se tourne vers lui pour des données prêtes à être émises. Les pages de direction sont utilisées pour attirer du trafic organique.
Par exemple, pour la requête "Vols Moscou Saint-Pétersbourg", une page sera émise avec l'adresse / tickets / moscou / saint-petersburg / , et elle a besoin de données:
- Prix des compagnies aériennes dans cette direction pour le mois en cours
- Prix des compagnies aériennes dans cette direction pour l'année à venir (prix moyen pour chaque mois pour les 12 prochains mois)
- Planifiez des vols dans cette direction
- Destinations populaires de la ville d'expédition - de Moscou (pour la liaison)
- Les destinations populaires de la ville d'arrivée sont de Saint-Pétersbourg (pour la liaison)
En PHP, toutes ces requêtes ont été exécutées de manière synchrone - l'une après l'autre. Le temps de réponse API moyen par demande est de 150 à 200 millisecondes. Nous multiplions 200 par 5 et obtenons, en moyenne, une seconde seulement pour répondre aux demandes du serveur avec des données. NodeJS a une grande fonction appelée Promise.all , qui exécute toutes les demandes en parallèle, mais écrit le résultat un par un. Par exemple, le code d'exécution pour les cinq demandes ci-dessus ressemblerait à ceci:
var [montlyPrices, yearlyPrices, flightsSchedule, originPopulars, destPopulars] = await Promise.all([ getMontlyPrices(), getYearlyPrices(), getFlightSchedule(), getOriginPopulars(), getDestPopulars() ])
Et nous obtenons toutes les données en 200-300 millisecondes, réduisant le temps de génération de données pour la page de 1-1,5 secondes à ~ 500 millisecondes.
Conclusion
Le passage de PHP à NodeJS m'a aidé à me familiariser avec le JavaScript asynchrone, à apprendre à travailler avec les promesses et à asynchroniser / attendre. Après la réécriture du moteur, la vitesse de chargement des pages a été optimisée et différait considérablement des résultats affichés par le moteur en PHP. Dans cet article, nous pourrions également parler de la façon dont les modules simples sont utilisés pour travailler avec le cache (Redis) et pg-promise (PostgreSQL) dans NodeJS et pour les comparer avec Memcached et php-pgsql, mais cet article s'est avéré assez volumineux. Et connaissant mon "talent" pour l'écriture, elle s'est également avérée mal structurée. Le but de cet article est d'attirer l'attention des développeurs qui travaillent toujours avec PHP et ne sont pas conscients des délices de NodeJS et du développement d'applications Web sur celui-ci en utilisant un exemple d'un projet réel qui a été écrit en PHP, mais à cause des préférences son propriétaire est allé sur une autre plateforme.
J'espère avoir pu transmettre mes pensées et plus ou moins structurées pour les exprimer dans ce matériel. Au moins j'ai essayé :)
Écrivez des commentaires - amicaux ou en colère. Je répondrai à tout constructif.