Pourquoi pourriez-vous avoir besoin d'émuler l'infrastructure de services Web Amazon?
Tout d'abord, c'est une économie - un gain de temps pour le développement et le débogage, et ce qui est tout aussi important - une économie sur le budget du projet. Il est clair que l'émulateur ne sera pas 100% identique à l'environnement d'origine que nous essayons d'émuler. Mais dans le but d'accélérer le développement et l'automatisation du processus, les similitudes existantes devraient suffire. La chose la plus d'actualité qui s'est produite en 2018 avec AWS a été le blocage par les fournisseurs IP des adresses IP des sous-réseaux AWS dans la Fédération de Russie. Et ces verrous ont affecté notre infrastructure située dans le cloud Amazon. Si vous prévoyez d'utiliser la technologie AWS et de placer le projet dans ce cloud, le développement et les tests d'émulation sont plus que payants.
Dans la publication, je vais vous expliquer comment nous avons réussi à réaliser une telle astuce avec les services S3, SQS, RDS PostgreSQL et Redshift lors de la migration d'un entrepôt de données existant vers AWS pendant de nombreuses années.
Ceci n'est qu'une partie de ma
réunion de l'année dernière sur la
carte , qui correspond aux thèmes des hubs AWS et Java. La deuxième partie concerne les bases de données PostgreSQL, Redshift et colonnes, et sa version texte peut être publiée dans les hubs correspondants, les vidéos et les diapositives sont sur
le site Web de la conférence .
Lors du développement d'une application pour AWS lors du blocage des sous-réseaux AWS, l'équipe ne les a pratiquement pas remarqués dans le processus quotidien de développement de nouvelles fonctionnalités. Les tests ont également fonctionné et vous pouvez déboguer l'application. Et ce n'est qu'en essayant de consulter les journaux d'application dans les entrées de journal, les mesures dans SignalFX ou l'analyse des données dans Redshift / PostgreSQL RDS ont été déçues - les services n'étaient pas disponibles via le réseau du fournisseur russe. L'émulation AWS nous a aidés à ne pas le remarquer et à éviter des retards beaucoup plus importants lorsque vous travaillez avec le cloud Amazon via un réseau VPN.
Chaque fournisseur de cloud «sous le capot» a beaucoup de dragons et vous ne devez pas céder à la publicité. Vous devez comprendre pourquoi tout cela est nécessaire pour le fournisseur de services. Bien sûr, l'infrastructure existante d'Amazon, Microsoft et Google présente des avantages. Et quand ils vous disent que tout n'est fait que pour vous faciliter le développement, ils essaient très probablement de vous mettre sur votre aiguille et de donner la première dose gratuitement. Pour que plus tard, ils ne sortent pas de l'infrastructure et de la technologie spécifique. Par conséquent, nous essaierons d'éviter le blocage des fournisseurs. Il est clair qu'il n'est pas toujours possible de s'abstraire complètement de décisions spécifiques et je pense que très souvent il est possible d'abstraire près de 90% dans un projet. Mais les 10% restants du projet, liés à un fournisseur de technologies très importantes, consistent soit à optimiser les performances des applications, soit à proposer des fonctionnalités uniques nulle part ailleurs. Ils doivent toujours se souvenir des avantages et des inconvénients des technologies et se protéger autant que possible, ne pas "s'asseoir" sur une API spécifique d'un fournisseur d'infrastructure cloud.
Amazon écrit sur le
traitement des messages sur son site Web. L'essence et l'abstraction des technologies d'échange de messages sont les mêmes partout, bien qu'il y ait des nuances - le message passant par des files d'attente ou par des sujets. Ainsi, AWS recommande d'utiliser l'Apache ActiveMQ fourni et géré par eux pour migrer les applications à partir d'un courtier de messagerie existant et pour les nouvelles applications Amazon SQS / SNS. Ceci est un exemple de liaison à leur propre API, au lieu de l'API JMS standardisée et des protocoles AMQP, MMQT, STOMP. Il est clair que ce fournisseur avec sa solution peut avoir des performances plus élevées, il prend en charge l'évolutivité, etc. De mon point de vue, si vous utilisez leurs bibliothèques et non des API standardisées, il y aura beaucoup plus de problèmes.
AWS possède une base de données Redshift. Il s'agit d'une base de données distribuée avec une architecture parallèle massive. Vous pouvez télécharger une grande quantité de vos données dans des tableaux sur plusieurs sites Redshft sur Amazon et effectuer des requêtes analytiques sur de grands ensembles de données. Ce n'est pas un système OLTP où il est important pour vous d'effectuer de petites requêtes sur un petit nombre d'enregistrements assez souvent avec des garanties ACID. Lorsque vous travaillez avec Redshift, il est supposé que vous n'avez pas un grand nombre de requêtes par unité de temps, mais ils peuvent lire des agrégats sur une très grande quantité de données. Ce système est positionné par le fournisseur pour
mettre à
niveau votre entrepôt de données (entrepôt) sur AWS et promettre un chargement de données simple. Ce qui n'est pas du tout vrai.
Un extrait de la documentation sur les
types pris en charge par Amazon Redshift. C'est un ensemble plutôt maigre, et si vous avez besoin de quelque chose pour stocker et traiter des données qui ne sont pas répertoriées ici, il vous sera difficile de travailler. Par exemple, un GUID.
Question de la salle, "Et JSON?"
- JSON ne peut être écrit qu'en VARCHAR et il existe plusieurs fonctions pour travailler avec JSON.
Commentaire du public: "Postgres a un support JSON normal."
- Oui, il prend en charge ce type de données et de fonctions. Mais
Redshift est basé sur PostgreSQL 8.0.2. Il y avait un projet ParAccel, si je ne me trompe pas, cette technologie de 2005 est un fork de postgres qui a un ordonnanceur pour les requêtes distribuées basées sur une architecture massivement parallèle. 5-6 ans se sont écoulés et ce projet a été autorisé pour la plate-forme Amazon Web Servces et nommé Redshift. Quelque chose a été supprimé des Postgres d'origine, beaucoup a été ajouté. Ils ont ajouté que liés à l'authentification / autorisation dans AWS, avec les rôles, la sécurité dans Amazon fonctionne bien. Mais si vous devez, par exemple, vous connecter de Redshift à une autre base de données à l'aide d'une source de données étrangère, vous ne le trouverez pas. Il n'y a pas de fonctions pour travailler avec XML, des fonctions pour travailler avec JSON deux fois et mal calculées.
Lors du développement d'une application, essayez de
ne pas dépendre d'implémentations spécifiques et le code d'application ne dépend que des abstractions. Vous pouvez créer ces façades et abstractions vous-même, mais dans ce cas, il existe de nombreuses bibliothèques prêtes à l'emploi - des façades. Qui soustraient le code à des implémentations spécifiques, à des cadres spécifiques. Il est clair qu'elles ne prennent pas en charge toutes les fonctionnalités en tant que «dénominateur commun» des technologies. Il est préférable de développer des logiciels reposant sur des abstractions pour simplifier les tests.
Pour émuler AWS, je mentionnerai deux options. Le premier est plus honnête et correct, mais il fonctionne plus lentement. Le second est sale et rapide. Je vais vous parler de l'option de piratage - nous essayons de créer toute l'infrastructure en un seul processus - les tests et l'option multiplateforme fonctionneront plus rapidement avec le travail sous Windows (où Docker n'est pas toujours en mesure de gagner de l'argent avec vous).
La première méthode est parfaite si vous développez sur linux / macos et que vous avez un docker, il serait préférable d'utiliser
atlassian localstack . Il est pratique d'utiliser des
conteneurs de
test pour intégrer localstack dans la JVM.
Ce qui m'a empêché d'utiliser lockalstack dans docker sur le projet, c'est que le développement était sous Windows et que personne ne garantissait la version alpha de docker lorsque ce projet a démarré ... Il est également possible qu'ils ne soient pas autorisés à installer une machine virtuelle avec linux et docker dans toute entreprise sérieuse à propos de à la sécurité de l'information. Je ne parle pas de travailler dans un environnement sécurisé dans les banques d'investissement et d'interdire presque tous les pare-feu de circulation là-bas.
Examinons les options pour émuler le stockage simple S3. Ce n'est pas un système de fichiers Amazon ordinaire, mais plutôt un magasin d'objets distribués. Dans lequel vous mettez vos données en BLOB, sans possibilité de modification et d'ajout de données. Il existe des stockages distribués à part entière similaires d'autres fabricants. Par exemple, le stockage d'objets distribués Ceph vous permet de travailler avec ses fonctionnalités en utilisant le
protocole S3 REST et le client existant avec un minimum de modifications. Mais c'est une solution plutôt lourde pour le développement et le test d'applications Java.
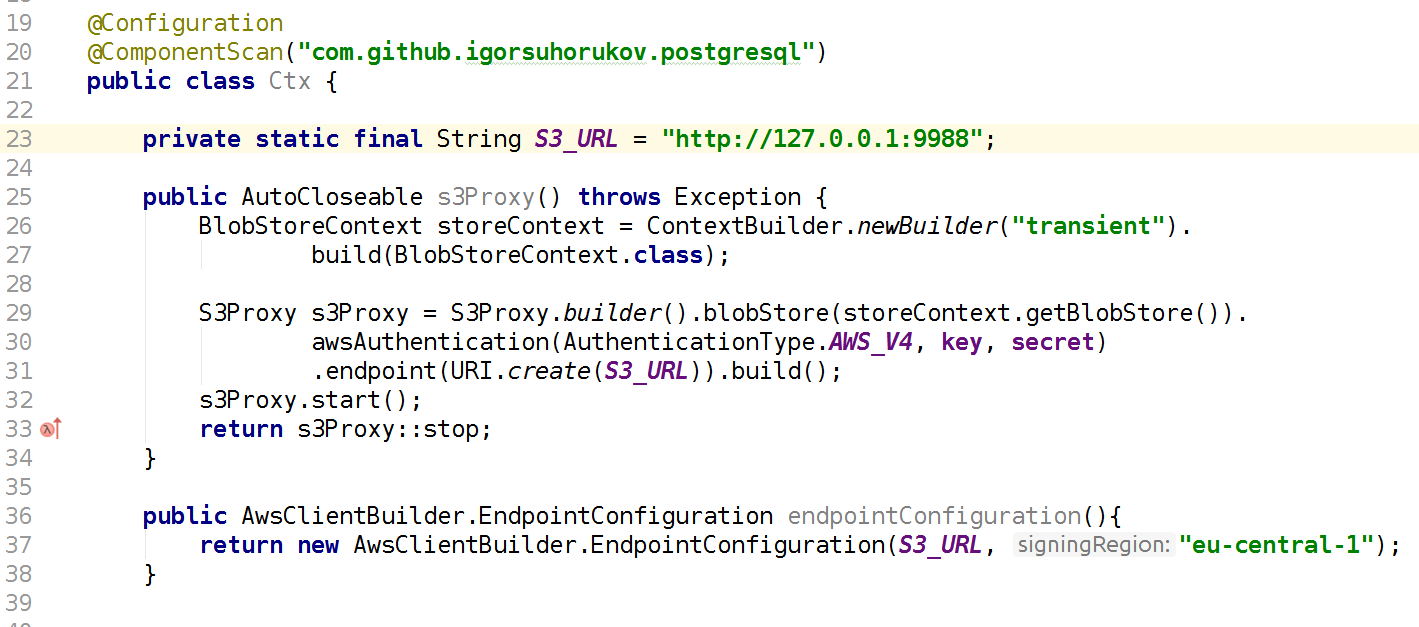
Un projet plus rapide et plus adapté est la bibliothèque java
s3proxy . Il émule le protocole S3 REST et le traduit en appels API
jcloud correspondants et vous permet d'utiliser de nombreuses implémentations pour une lecture et un stockage réels des données. Il peut diffuser des appels vers l'API Google App Engine, l'API Microsoft Azure, mais pour les tests, il est plus pratique d'utiliser le stockage transitoire jcloud dans la RAM. Il est également nécessaire de configurer la version du protocole d'authentification AWS S3 et de spécifier la clé et les valeurs secrètes, de configurer également le point de terminaison - le port et l'interface sur lesquels ce proxy S3 écoutera. Par conséquent, votre code utilisant le client AWS SDK doit être connecté lors des tests au point de terminaison S3 AWS, et non à la région AWS. Encore une fois, n'oubliez pas que s3proxy ne prend pas en charge toutes les fonctionnalités de l'API S3, mais tous nos scénarios d'utilisation émulent parfaitement! Même le téléchargement en plusieurs parties pour les fichiers volumineux est pris en charge par s3proxy.
Amazon Simple Queue Service est un service de mise en file d'attente. Il existe un
service de file d'attente
élastiquemq écrit en scala et il peut être présenté à votre application à l'aide du protocole Amazon SQS. Je ne l'ai pas utilisé dans le projet, je vais donc donner le code d'initialisation, en faisant confiance aux informations de ses développeurs.
Dans le projet, je suis allé dans l'autre sens et le code dépend des abstractions spring-jms de JmsTemplate et JmsListener et les dépendances du projet spécifient le pilote JMS pour SQS com.amazonaws: amazon-sqs-java-messaging-lib. C'est ce qui concerne le code d'application principal.

Dans les tests, nous connectons Artemis-jms-server en tant que serveur JMS intégré pour les tests, et dans le contexte de test Spring, au lieu de la fabrique de connexions SQS, nous utilisons la fabrique de connexions Artemis. Artemis est la prochaine version d'Apache ActiveMQ, un middleware orienté message moderne et complet - pas seulement une solution de test. Peut-être que nous passerons à son utilisation à l'avenir, pas seulement dans les autotests. Ainsi, en utilisant les abstractions JMS conjointement avec Spring, nous avons simplifié à la fois le code de l'application et la possibilité de le tester facilement. Il vous suffit d'ajouter les dépendances org.springframework.boot: spring-boot-starter-artemis et org.apache.activemq: artemis-jms-server.
Dans certains tests, PostgreSQL peut être émulé en le remplaçant par
H2Database . Cela fonctionnera si les tests ne sont pas acceptés et n'utilisent pas de fonctions PG spécifiques. Dans le même temps, H2 peut émuler un sous-ensemble du protocole de connexion PostgreSQL sans prise en charge des types de données et des fonctions. Dans notre projet, nous utilisons Foreing Data Wrapper, donc cette méthode ne fonctionne pas pour nous.
Vous pouvez exécuter de vrais PostgreSQL.
postgresql-embedded télécharge la vraie distribution, ou plutôt l'archive avec des fichiers binaires pour la plate-forme avec laquelle nous fonctionnons, la décompresse. Sous linux sur tempfs en RAM, sous windows dans% TEMP%, le processus serveur postgresql démarre, configure les paramètres du serveur et les paramètres de la base de données. En raison des fonctionnalités de distribution de distribution, les versions antérieures à PG 11 ne fonctionnent pas sous Linux. Pour ma part, j'ai créé une
bibliothèque wrapper qui vous permet d'obtenir des assemblages binaires PostgreSQL non seulement à partir d'un serveur HTTP mais également à partir du référentiel maven. Ce qui peut être très utile lorsque vous travaillez dans des réseaux isolés et que vous construisez sur un serveur CI sans accès à Internet. Une autre commodité de travailler avec mon wrapper est l'annotation du composant CDI, ce qui facilite l'utilisation du composant dans le contexte Spring par exemple. L'implémentation de l'interface du serveur AutoClosable est apparue plus tôt que dans le projet d'origine. Pas besoin de vous souvenir d'arrêter le serveur, il s'arrêtera lorsque le contexte Spring se fermera automatiquement.
Au démarrage, vous pouvez créer une base de données basée sur des scripts, complétant le contexte Spring avec les propriétés appropriées. Nous créons maintenant un schéma de base de données à l'aide de scripts de
voie de migration pour migrer le schéma de base de données, qui sont lancés chaque fois que la base de données est créée dans des tests.
Pour vérifier les données après l'exécution des tests, nous utilisons la bibliothèque spring-test-dbunit. Dans les annotations aux méthodes de test, nous indiquons avec quels chargements pour comparer l'état de la base de données. Cela élimine le besoin d'écrire du code pour fonctionner avec dbunit, il vous suffit d'ajouter le programme d'écoute de la bibliothèque au code de test. Vous pouvez spécifier dans quel ordre les données des tables sont supprimées une fois la méthode de test terminée, si le contexte de la base de données est réutilisé entre les tests. En 2019, il existe une approche plus moderne mise en œuvre dans Database-Rider qui fonctionne avec Junit5. Vous pouvez voir un exemple d'utilisation, par exemple
ici .
La chose la plus difficile a été d'émuler Amazon Redshift. Il existe un projet
redshift-fake-driver qui se concentre sur l'émulation du chargement de données par lots dans la base de données analytiques à partir d'AWS. Dans l'émulateur de protocole jdbc: postgresqlredshift, les commandes COPY, UNLOAD sont implémentées, toutes les autres commandes sont déléguées au pilote JDBC PostgreSQL standard.
Par conséquent, les tests ne fonctionneront pas de la même manière que dans Redshift, l'opération de mise à jour, qui utilise une autre table comme source de données pour la mise à jour (la syntaxe diffère dans Redshift et PostgreSQL 9+. J'ai également remarqué une interprétation différente de la citation de ligne dans les commandes SQL entre ces bases de données.
En raison de l'architecture d'une véritable base de données Redshift, les opérations d'insertion, de mise à jour et de suppression de données sont plutôt lentes et «coûteuses» en termes d'E / S. Il est possible d'insérer des données avec des performances acceptables uniquement dans de grands "paquets" et la commande COPY vous permet simplement de télécharger des données à partir d'un système de fichiers S3 distribué. Cette commande dans la base de données prend en charge plusieurs formats de données AVRO, CSV, JSON, Parquet, ORC et TXT. Et le projet d'émulation se concentre sur CSV, TXT, JSON.
Ainsi, pour émuler Redshift dans les tests, vous devrez démarrer la base de données PostgreSQL comme décrit précédemment et démarrer l'émulation du référentiel S3, et lors de la création d'une connexion au postgres, il vous suffit d'ajouter redshift-fake-driver dans le chemin de classe et de spécifier la classe de pilote jp.ne.opt.redshiftfake.postgres. FakePostgresqlDriver. Après cela, vous pouvez utiliser la même voie de migration pour migrer le schéma de base de données, et dbunit est déjà familier pour comparer les données après avoir exécuté les tests.
Je me demande combien de lecteurs utilisent AWS et Redshift dans leur travail? Écrivez dans les commentaires sur votre expérience.
En utilisant uniquement des projets Open Source, l'équipe a pu accélérer le développement dans l'environnement AWS, économiser de l'argent sur le budget du projet et ne pas empêcher l'équipe de travailler lorsque les sous-réseaux AWS étaient bloqués par Roskomnadzor.