En décembre 2015 , PHP 7.0 a été publié. Les entreprises qui sont passées au «sept» ont noté que la productivité avait augmenté et que la charge sur le serveur avait diminué. Les premiers à passer aux sept ont été Vebia et Etsy, et nous avons Badoo, Avito et OLX. Pour Badoo, le passage aux sept a coûté 1 million de dollars en économies de serveur. Grâce à PHP 7 dans OLX, la charge moyenne du serveur a diminué de 3 fois, augmentant l'efficacité et les économies de ressources.
Dmitry Stogov de Zend Technologies a
parlé à
HighLoad ++ , ce qui a augmenté la productivité. En décodage: sur la structure interne de PHP, sur les idées au cœur de la version 7.0, sur les changements dans les structures de données de base et les algorithmes qui ont déterminé le succès.
Avertissement: En mars 2019, 80% des sites fonctionnaient sur PHP et 70% d'entre eux fonctionnaient sur PHP 5, bien que cette version ne soit plus prise en charge depuis le 1er janvier 2019 . Le rapport de Dmitry de 2016 sur les principes en raison desquels il y a eu un double saut de productivité entre PHP 5 et 7 est également pertinent en mars 2019. Pour la moitié des sites, bien sûr.À propos de l'orateur: Dmitry Stogov a commencé à programmer dans les années 80: «Electronics B3-34», Basic, assembleur. En 2002, Dmitry s'est familiarisé avec PHP et a rapidement commencé à l'améliorer: il a développé Turck MMCache pour PHP, a géré le projet PHPNG et a joué un rôle important dans le travail sur JIT pour PHP. Les 14 dernières années d'ingénieur principal chez Zend Technologies.
Zend Technologies développe PHP et des solutions commerciales basées sur lui. En 1999, il a été fondé par les programmeurs israéliens Andy Gutmans et Zeev Suraski, qui ont créé il y a deux ans PHP 3. Ces personnes étaient à la pointe du développement PHP et ont largement déterminé l'apparence actuelle du langage et le succès de la technologie.
Zend Technologies développe le noyau PHP et ses applications, et pendant le travail, j'ai dû écrire des extensions, entrer dans tous les sous-systèmes et même m'engager dans des projets commerciaux, parfois pas du tout connectés avec PHP. Mais le sujet le plus intéressant pour moi a toujours été la
performance .
J'ai commencé à chercher des moyens d'accélérer PHP avant même de rejoindre Zend, travaillant sur mon propre projet en concurrence avec l'entreprise. Pendant le travail sur le projet, j'ai bien compris le langage et réalisé que ne pas travailler avec le projet mainstream, vous ne pouvez influencer que certains aspects de l'exécution du script, et tous les plus intéressants et efficaces ne peuvent être créés
que dans le noyau . Cette compréhension et cette coïncidence m'ont conduit à Zend.
Une petite parenthèse dans l'histoire de PHP
PHP n'est pas seulement et
pas seulement un langage de programmation . PHP signifie Personal Home Page - un outil pour créer des pages Web personnelles et des sites Web dynamiques. La langue n'est qu'une de ses principales parties. PHP est une énorme bibliothèque de fonctions, de nombreuses extensions pour travailler avec d'autres bibliothèques tierces, par exemple, pour accéder à la base de données ou aux analyseurs XML, ainsi qu'un ensemble de modules pour communiquer avec divers serveurs Web.
Le programmeur danois
Rasmus Lerdorf a introduit PHP
en juin 1995 . À l'époque, ce n'était qu'une
collection de scripts CGI écrits en Perl . En avril 96, Rasmus a introduit PHP / FI, et en juin PHP / FI 2.0 a été publié. Par la suite, cette version a été substantiellement retravaillée par Andy Gutmans et Zeev Surasky, et dans la 98e version PHP 3.0. En 2000, le langage est devenu le type que nous avons l'habitude de voir aujourd'hui à la fois en termes de langage et d'architecture interne - PHP 4, basé sur le moteur Zend.
Depuis la version 4, PHP a évolué. Le tournant a été la sortie de PHP 5 en 2004, lorsque le
modèle objet a été complètement mis à jour . C'est elle qui a ouvert l'ère des frameworks PHP et soulevé la question des performances à un nouveau niveau. Anticipant cela, immédiatement après la sortie de la version 5.0, chez Zend, nous avons pensé à accélérer PHP et avons commencé à travailler sur l'amélioration de la productivité.
La version 7.1, sortie en novembre 2016 sur des tests synthétiques,
est 25 fois plus rapide que la version 2002 . Selon le graphique des changements de performances dans différentes branches, les principales percées sont visibles en 5.1 et 7.0.

Dans la version 5.1, nous venons de commencer à travailler sur les performances, et tout ce que nous avons obtenu a été obtenu, mais après 5.3 nous sommes tombés sur un mur, toutes les tentatives pour améliorer l'interpréteur ont échoué.
Néanmoins, nous avons trouvé où creuser et avons obtenu encore plus que prévu - une accélération de 2,5 fois par rapport à la version précédente 5,6 lors des tests. Mais le plus intéressant est que nous avons obtenu la même accélération de 2,5 fois sur des applications réelles inchangées. C'est un phénomène, car nous avons développé le facteur 2 précédent tout au long de la vie des cinq en 10 ans.
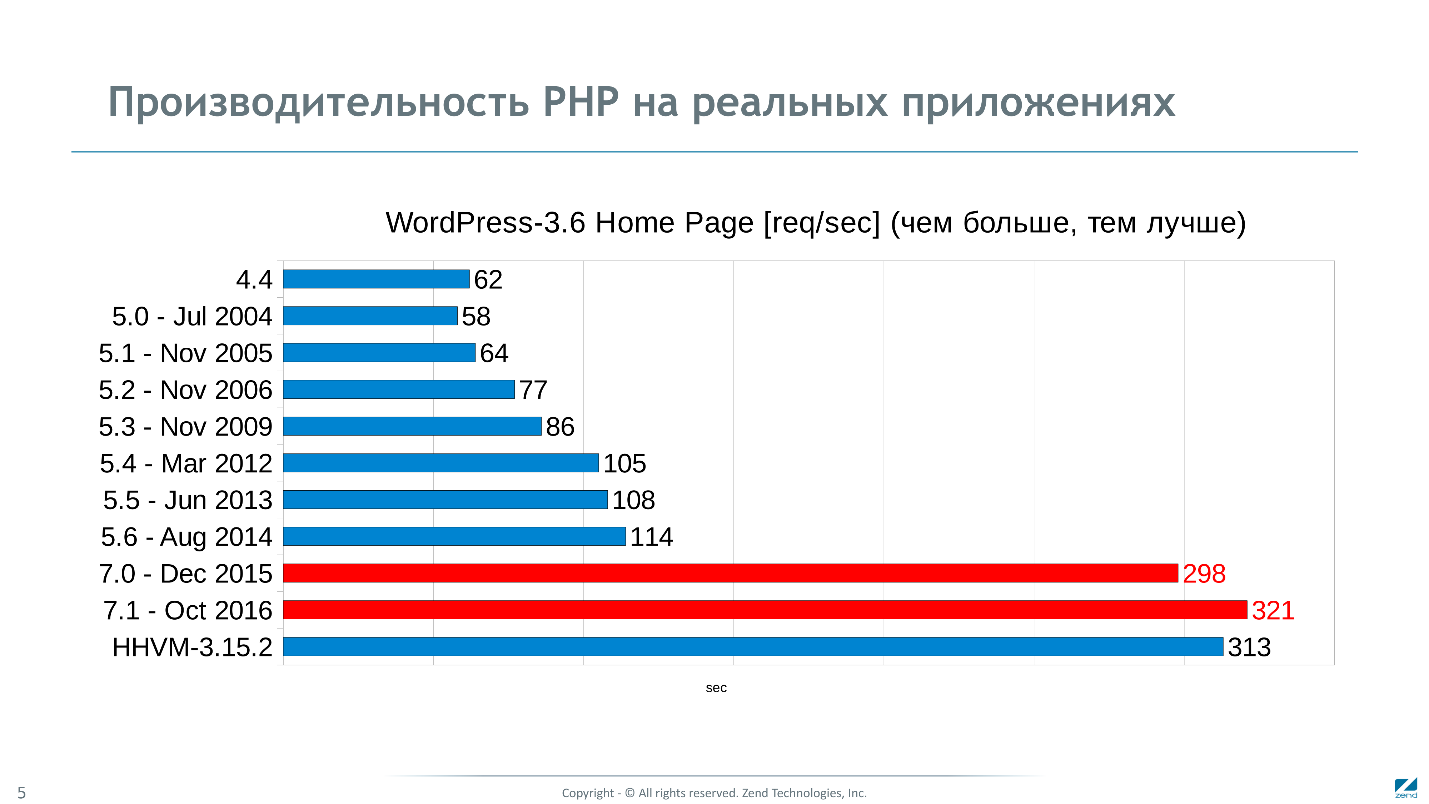
L'énorme saut en 5.1 sur les tests synthétiques n'est pas perceptible sur les applications réelles. La raison en est qu'avec des utilisations différentes, les performances PHP reposent sur les freins associés à différents sous-systèmes.
L'histoire de PHP 7 commence par une stagnation de trois ans qui a commencé en 2012 et s'est terminée en 2015 avec la sortie de la septième version. Puis nous avons réalisé que nous ne pouvions plus augmenter la productivité avec de petites améliorations de notre interprète et nous nous sommes tournés vers le côté JIT.
Se promener dans JIT
Près de deux ans, nous avons passé sur le prototype JIT pour PHP-5.5. Au début, nous avons généré un code très simple - une séquence d'appels pour les gestionnaires standard, quelque chose comme un code Fort assemblé. Ensuite, ils ont écrit leur propre
assembleur d'exécution , en ligne un code séparé pour les solutions de contournement, mais ont réalisé que ces
optimisations de bas niveau ne donnaient pas d' effet
pratique même sur les tests.
Nous avons ensuite pensé à dériver des types de variables à l'aide de méthodes d'analyse statique. Ayant réalisé la conclusion, nous avons immédiatement reçu
une accélération double dans les tests. Encouragés, ils ont essayé d'écrire des allocateurs de registres mondiaux, mais ont échoué. Nous avons utilisé une représentation assez élevée et il était presque impossible de l'utiliser pour l'allocation des registres.
Pour éviter les problèmes avec un niveau bas, nous avons décidé d'essayer LLVM, et après un an nous avons eu une
accélération 10x pour bench.php , mais rien sur les applications réelles. De plus, la compilation des applications réelles prenait maintenant quelques minutes, par exemple, la première
demande à Wordpress prenait 2 minutes et ne donnait pas d'accélération. Bien sûr, cela n'était pas du tout adapté à une pratique réelle.
Un bon code est possible avec une prédiction de type appropriée, qui fonctionne mal dans des applications réelles, et l'utilisation de structures de données PHP rend le code généré inefficace.
Qu'est-ce qui ralentit?
Nous avons repensé les raisons des échecs et décidé à nouveau de voir pourquoi PHP est lent. L'image montre le résultat du profilage de plusieurs demandes vers la page d'accueil de Wordpress.
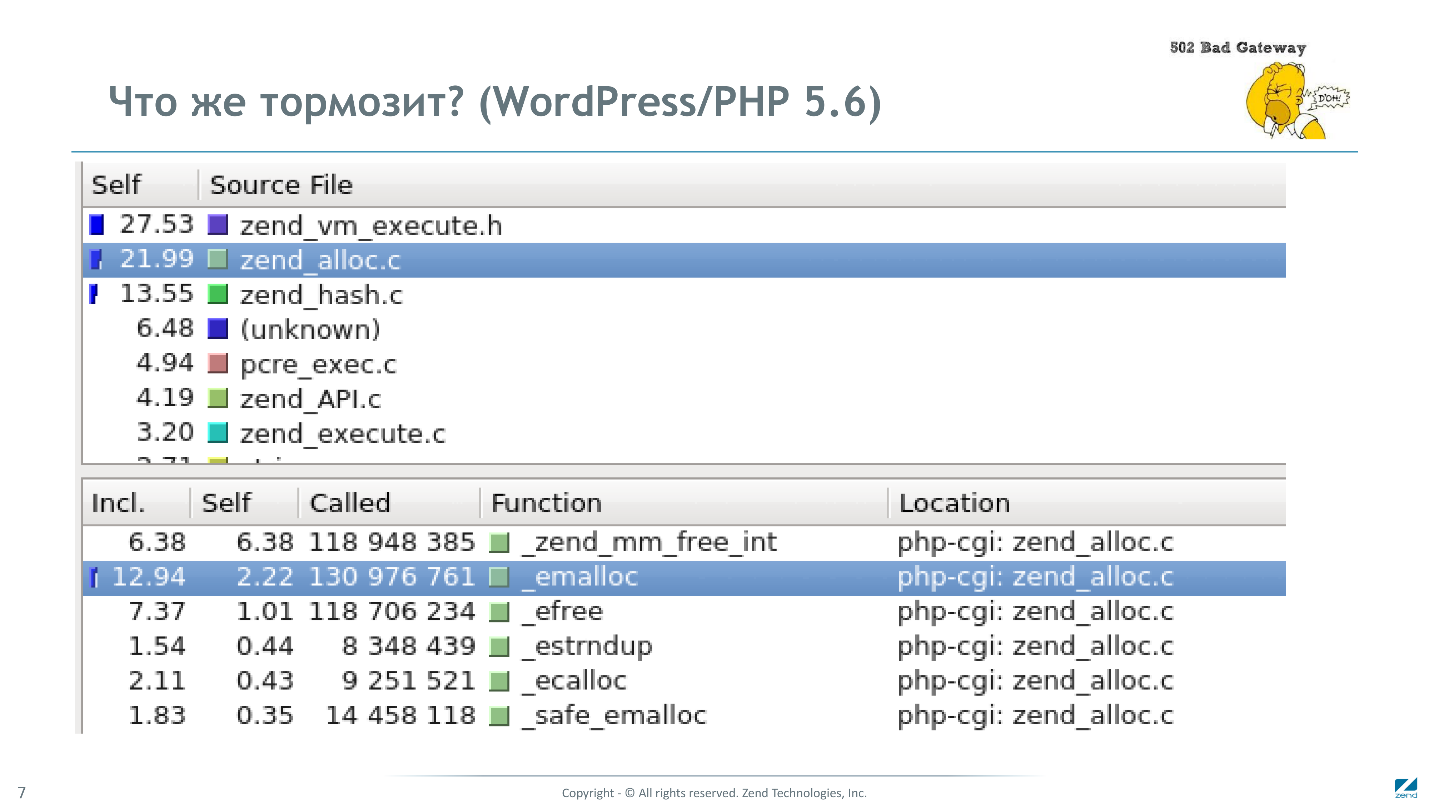
Moins de 30% sont dépensés pour interpréter le bytecode, 20% est la surcharge du gestionnaire de mémoire, 13% travaille avec des tables de hachage et 5% travaille avec des expressions régulières.
En travaillant chez JIT, nous ne nous sommes débarrassés que des premiers 30%, et tout le reste était mort. Presque partout, nous avons été obligés d'utiliser des structures de données PHP standard, ce qui entraînait des frais généraux: allocation de mémoire, comptage de références, etc. Cette compréhension a conduit à la conclusion qu'il est nécessaire de remplacer les structures de données clés en PHP. Avec cette
substitution de la fondation , le projet
PHPNG a
commencé.Phpng Nouvelle génération
Le projet a été développé après des tentatives infructueuses de création de JIT pour PHP. L'objectif principal est
d'atteindre un nouveau niveau de productivité et de jeter les bases d'améliorations futures .
Nous nous sommes promis pendant un certain temps de ne plus utiliser de tests synthétiques pour mesurer les performances - ce sont généralement de petits programmes informatiques qui utilisent une quantité limitée de données qui tient entièrement dans le cache du processeur. Les applications réelles, en revanche, sont soumises aux freins associés à la mémoire du sous-système, et une seule lecture dans la mémoire peut coûter 100 instructions de calcul.
Le projet PHPNG est une refactorisation des structures de données PHP clés pour optimiser l'accès à la mémoire . Aucune innovation, 100% compatible PHP 5.
Comment changer ces structures était clair. Mais le volume des changements dépendants était énorme, car le
cœur de PHP lui
- même
est de 150 000 lignes , et presque chaque tiers devait être changé. Ajoutez une centaine d'extensions supplémentaires incluses dans la distribution de base, une douzaine de modules pour différents serveurs Web et vous réaliserez la grandeur du projet.
Nous n'étions même pas sûrs de terminer le projet. Par conséquent, ils ont lancé le projet en secret et ne l'ont ouvert que lorsque les premiers résultats optimistes sont apparus. Il a fallu deux semaines pour simplement
compiler le noyau . Deux semaines plus tard, bench.php a gagné. Nous avons passé un mois et demi pour soutenir Wordpress. Un mois plus tard, nous avons ouvert le projet - c'était en mai 2014. À cette époque, nous avions une
accélération de 30% sur Wordpress . Cela semblait déjà être un grand événement.
PHPNG a immédiatement suscité une vague d'intérêt, et en août 2014, il a été
adopté comme base pour l'avenir de PHP 7 . C'était déjà un autre projet, avec un ensemble d'objectifs différents, où la productivité n'était que l'un d'entre eux.
PHP 7.0
La version numéro 7 elle-même était dans le doute. La version précédente était la cinquième. Et le sixième a été développé il y a plusieurs années et était entièrement consacré au support
Unicode natif, mais les décisions infructueuses prises aux premiers stades de développement ont conduit à une complexité excessive du code du noyau et de chaque extension. Finalement, il a été décidé de geler le projet.
À cette époque, une grande quantité de matériel consacré à PHP 6 avait déjà été accumulé: discours lors de conférences, livres publiés. Afin de ne dérouter personne, nous avons appelé le projet PHP 7, en sautant PHP 6. Cette version était beaucoup plus chanceuse - PHP 7 est sorti en décembre 2015, presque comme prévu.
En plus des performances, certaines innovations recherchées depuis longtemps sont apparues dans PHP 7:
- Possibilité de définir des types scalaires de paramètres et des valeurs de retour.
- Exceptions au lieu d'erreurs - nous pouvons maintenant les détecter et les traiter.
Zero-cost assert() , classes anonymes, incohérences de nettoyage, nouveaux opérateurs et fonctions (<=>, ??) sont apparus.
L'innovation est bonne, mais revenons aux changements internes. Parlons du chemin que PHP 7 a suivi et où ce chemin peut nous mener.
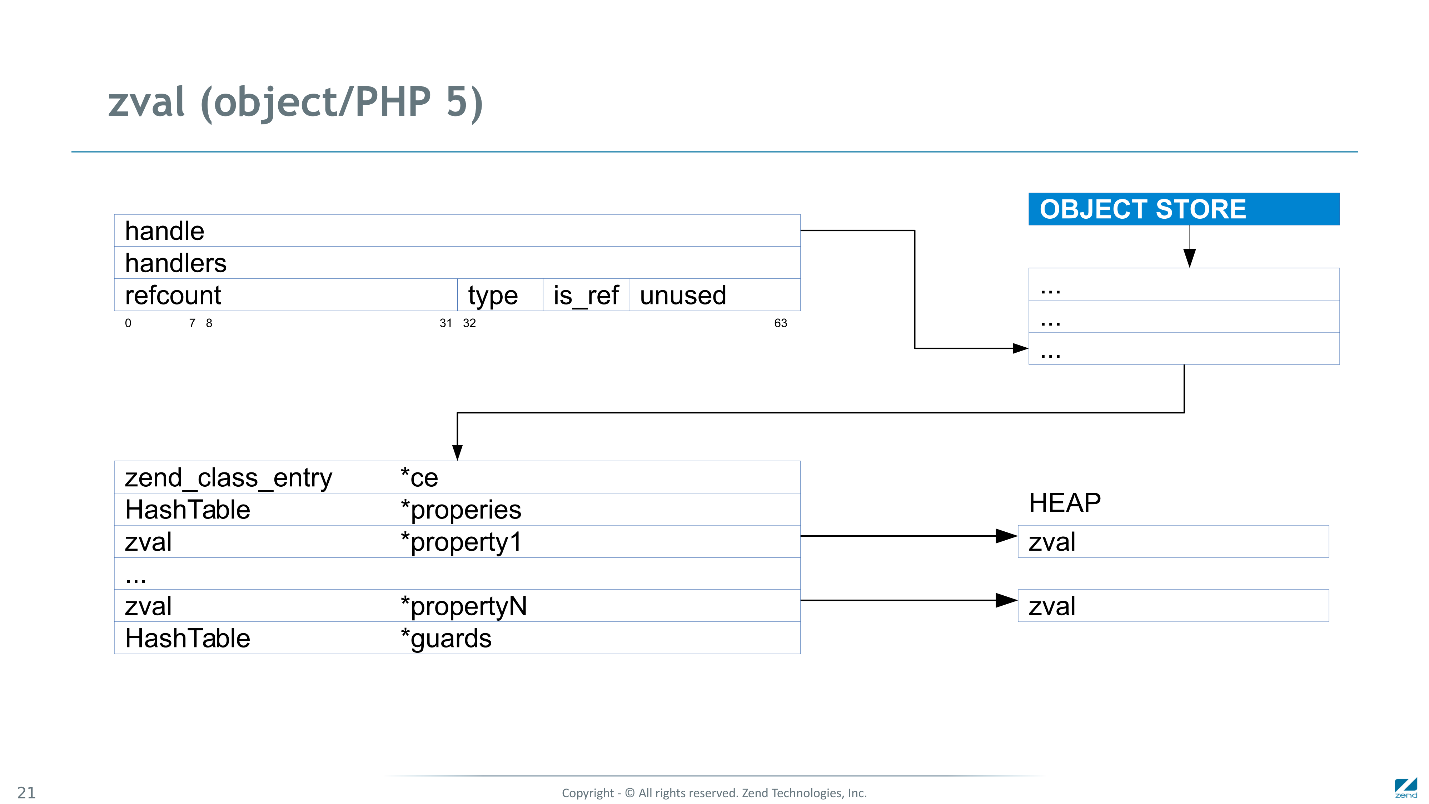
zval
Il s'agit de la structure de base des données PHP. Il est utilisé pour
représenter n'importe quelle valeur en PHP . Puisque notre langage est typé dynamiquement et que le type de variables peut changer pendant l'exécution du programme, nous devons stocker un champ de type (type zend_uchar), qui peut prendre les valeurs IS_NULL, IS_BOOL, IS_LONG, IS_DOUBLE, IS_ARRAY, IS_OBJECT, etc., et en fait la valeur représentée par union (valeur), où un entier, un nombre réel, une chaîne, un tableau ou un objet peuvent être stockés.
zval en PHP 5
La mémoire de chacune de ces structures a été allouée séparément dans Heap. En plus du type et de la valeur, il contenait également un compteur de références à la structure. La structure a donc pris 24 octets, sans compter les frais généraux du gestionnaire de mémoire et le pointeur vers celui-ci.
L'image en haut à droite montre les structures de données qui ont été créées dans la mémoire de PHP 5 pour un script simple.

Sur la pile, de la mémoire a été allouée à 4 variables représentées par des pointeurs. Les valeurs elles-mêmes (zval) sont sur le tas. Dans notre cas, ce ne sont que deux zval, dont chacun est référencé par deux variables, et en conséquence leurs compteurs de référence sont définis sur 2.
Pour accéder à un type ou à une valeur scalaire, vous avez besoin d'au moins deux lectures: lisez d'abord la valeur du pointeur, puis la valeur de la structure. Si vous devez lire non pas une valeur scalaire, mais, par exemple, une partie d'une chaîne ou d'un tableau, vous aurez besoin d'au moins une autre lecture.
zval en PHP 7
Là où nous utilisions des pointeurs auparavant, dans les sept, nous avons commencé à intégrer zval. Nous nous sommes éloignés du comptage de références pour les types scalaires. Le type et la valeur des champs sont restés sans changements importants, mais quelques drapeaux supplémentaires et une place réservée ont été ajoutés, dont je parlerai un peu plus tard.

À gauche, à quoi cela ressemblait en PHP 5, et à droite, en PHP 7.

Maintenant, zval eux-mêmes sont sur la pile. Pour lire les types et les valeurs scalaires, une seule instruction machine suffit. Toutes les valeurs sont regroupées dans une zone de mémoire, ce qui signifie que lorsque nous travaillons avec des variables locales, nous n'aurons pratiquement aucune perte due à des échecs du cache du processeur. Mais la véritable puissance de la nouvelle performance est incluse lorsque la copie est nécessaire.
Copier l'enregistrement
Dans la première ligne du script, une autre affectation a été ajoutée.

En PHP5, nous avons alloué de la mémoire à partir du tas pour le nouveau zval, initialisé son int (2), changé la valeur du pointeur à la variable b et diminué le compteur de référence de la valeur à laquelle b avait précédemment fait référence.
En PHP 7, nous avons simplement
initialisé la variable b directement en place avec quelques instructions , tandis qu'en PHP 5, elle nécessitait des centaines d'instructions. Donc zval regarde maintenant en mémoire.
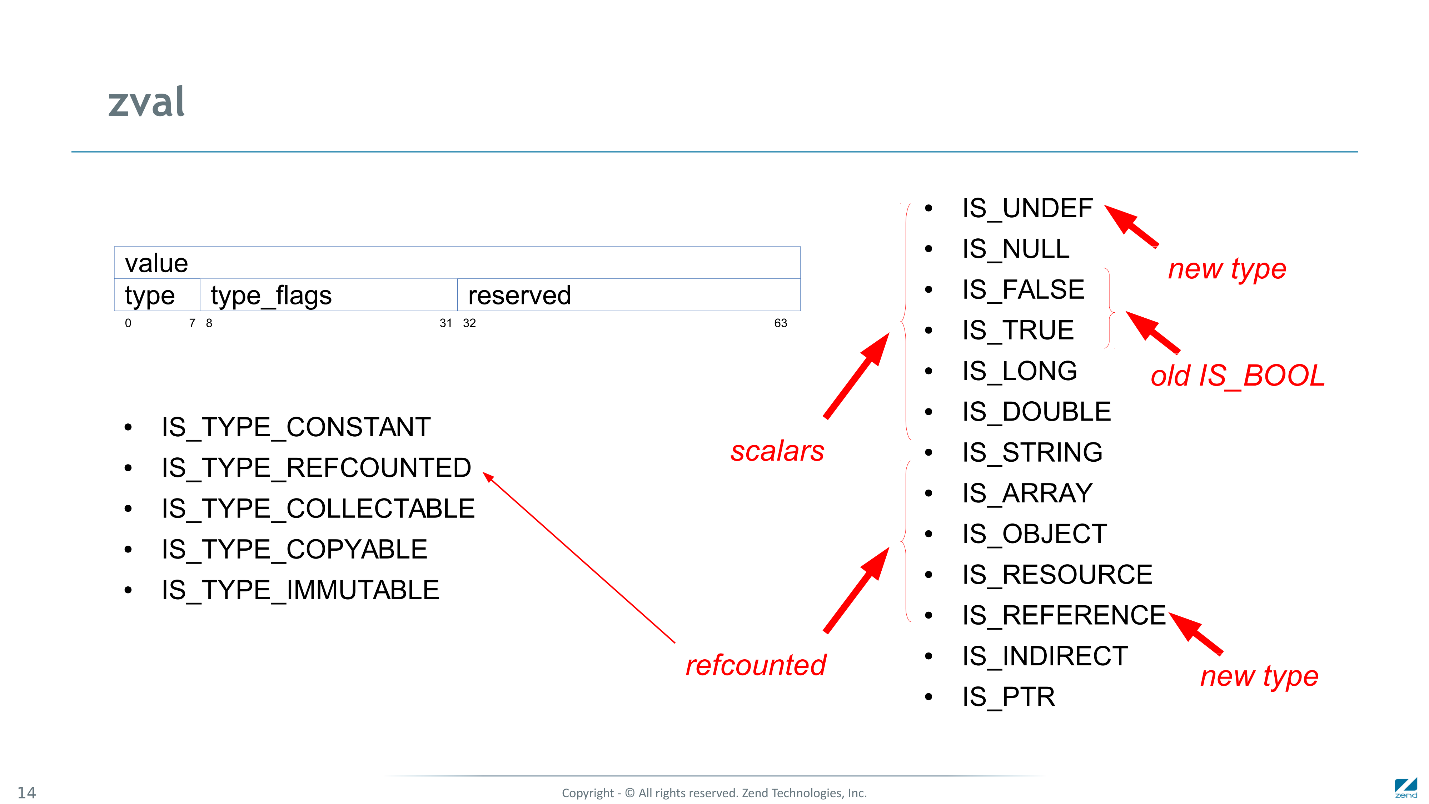
Ce sont deux mots de 64 bits. Le premier mot
signifie: entier, réel ou pointeur. Dans le deuxième mot, le
type (il indique comment interpréter le sens), les drapeaux et un emplacement réservé qui seraient encore ajoutés lors de l'alignement. Mais il ne disparaît pas, mais est utilisé par différents sous-systèmes pour stocker des valeurs indirectement liées.
Les indicateurs
sont un ensemble de bits où chaque bit indique si zval prend en charge un protocole. Par exemple, s'il s'agit de
IS_TYPE_REFCOUNTED , alors lorsque vous travaillez avec ce zval, le moteur doit prendre soin de la valeur du compteur de référence. Lors de l'affectation, augmentez; lorsque vous quittez la portée, diminuez; si le compteur de référence atteint zéro, détruisez la structure dépendante.
Parmi les types, par rapport à PHP 5, plusieurs nouveaux sont apparus.
IS_UNDEF - un marqueur d'une variable non initialisée.- L'unique
IS_BOOL remplacé par des IS_FALSE et IS_TRUE . - Ajout d'un type distinct pour les liens et quelques autres types magiques.
Les types de
IS_UNDEF à
IS_DOUBLE sont scalaires et ne nécessitent pas de mémoire supplémentaire. Pour les copier, il suffit de copier le premier mot 64 bits de la machine avec une valeur et la moitié de la seconde avec un type et des drapeaux.
Recompté
Avec d'autres types plus difficiles. Ils sont tous représentés par une structure subordonnée, et zval stocke simplement une référence à cette structure. Pour chaque type, cette structure est différente, mais en termes de POO, ils ont tous un ancêtre abstrait commun ou une structure zend_refcounted. Il détermine le format du premier
mot 64 bits , où le nombre de références et d'autres informations pour le garbage collector sont stockés.

Ce mot peut être considéré simplement comme une information pour le garbage collector, et les structures pour des types spécifiques ajoutent leurs champs après ce premier mot.
Lignes
Dans les sept de la chaîne, nous stockons la valeur calculée de la fonction de hachage, sa longueur et les caractères eux-mêmes. La taille d'une telle structure est variable et dépend de la longueur de la chaîne. La fonction de hachage est calculée une fois pour la chaîne, si nécessaire. En PHP 5, il a été recalculé à chaque besoin.

Maintenant, les chaînes sont devenues dénombrables de référence, et si en PHP 5 nous avons copié les caractères eux-mêmes, maintenant il suffit d'augmenter le nombre de références pour cette structure.
Comme en PHP 5, nous avons toujours le concept de
chaînes immuables ou internées . Ils existent généralement dans une seule instance, vivent jusqu'à la fin de la requête et peuvent se comporter comme des valeurs scalaires. Nous n'avons pas besoin de prendre soin du compteur des références à eux, et pour la copie, il suffit de copier uniquement zval lui-même à l'aide de quatre instructions machine.
Tableaux
Les tableaux sont représentés par une table de hachage intégrée et ne sont pas très différents de PHP 5. La table de hachage elle-même a changé, mais plus à ce sujet séparément.

Les tableaux sont désormais une
structure adaptative qui modifie légèrement sa structure interne et son comportement en fonction des données stockées. Si nous stockons uniquement des éléments avec des clés numériques proches, nous avons accès aux éléments directement par index avec une vitesse comparable à la vitesse des tableaux en C.Mais si vous ajoutez un élément avec une clé de chaîne au même tableau, il se transforme en un véritable hachage avec une résolution de collision.
Voici à quoi ressemble la table de hachage en PHP 5.
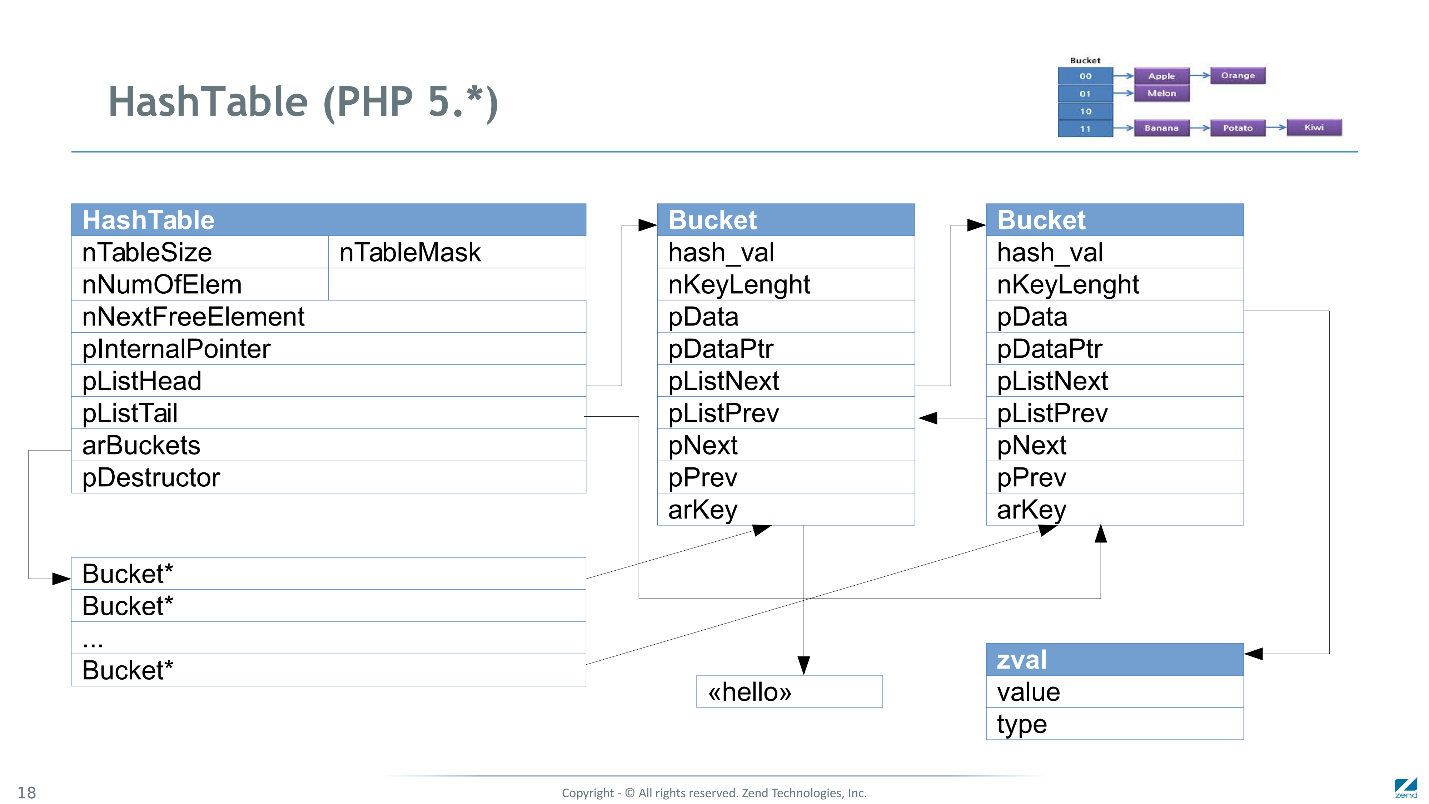
Il s'agit d'une implémentation de table de hachage classique avec une résolution de collision à l'aide de listes linéaires (affichées dans le coin supérieur droit). Chaque élément est représenté par un seau. Tous les compartiments sont liés par des listes doublement liées pour résoudre les collisions et liés par une autre liste doublement liée pour itérer dans l'ordre. Les valeurs de chaque zval sont attribuées séparément - dans Bucket, nous n'enregistrons qu'un lien vers celui-ci. De plus, les clés de chaîne peuvent être attribuées séparément.
Ainsi, pour chaque table de hachage, vous devez allouer beaucoup de petits blocs de mémoire, et pour trouver quelque chose plus tard, vous devez parcourir les pointeurs. Chacune de ces transitions peut provoquer un manque de cahce et un retard d'environ 10 à 100 cycles de processeur.
C'est ce qui s'est passé en PHP 7.

La structure logique est restée inchangée, seule la physique a changé. Maintenant, sous une table de hachage, la mémoire est allouée en une seule opération.
Dans l'image, au bas du pointeur de base, il y a des éléments, et en haut se trouve un tableau de hachage qui est adressé par une fonction de hachage. Pour les tableaux plats ou compactés, lorsque nous stockons uniquement des éléments avec des indices numériques, la partie supérieure n'est pas allouée du tout et nous adressons le Bucket directement par numéro.
Pour contourner les éléments, nous les trions séquentiellement de haut en bas ou de bas en haut, ce que les processeurs modernes font parfaitement. Les valeurs sont intégrées aux compartiments, mais l'espace réservé qu'elles contiennent est uniquement utilisé pour résoudre les collisions. Il stocke l'index d'un autre Bucket avec la même valeur de fonction de hachage ou la fin du marqueur de liste.
La mémoire pour les valeurs de chaîne des clés est allouée séparément, mais c'est toujours la même zend_string. Lors du collage dans un tableau, il suffit d'augmenter le compteur de référence de la chaîne, bien que nous devions auparavant copier les caractères directement et lors de la recherche, nous pouvons maintenant comparer non pas les caractères, mais les pointeurs vers les chaînes elles-mêmes.
Tableaux immuables
Auparavant, nous avions des chaînes immuables, mais maintenant des tableaux immuables sont également apparus. Comme les chaînes, elles n'utilisent pas le nombre de références et ne sont détruites qu'à la fin de la demande. Il s'agit d'un script simple qui crée un tableau d'un million d'éléments, et chaque élément est le même tableau avec un seul élément "bonjour".

En PHP 5, à chaque itération de boucle, un nouveau tableau vide était créé, «bonjour» y était écrit, et tout cela était ajouté au tableau résultant. En PHP 7, au stade de la compilation, nous
créons un seul tableau immuable qui se comporte comme un scalaire et l'ajoutons à celui qui en résulte. Dans l'exemple présenté, cela nous permet de réduire la consommation de mémoire de plus de 10 fois et d'accélérer de près de 10 fois.
Bien sûr, on ne trouve pas souvent des tableaux constants de millions d'éléments dans des applications réelles, mais les petits sont assez courants. Sur chacun d'eux, vous obtiendrez une petite, mais une victoire.
Les objets
Les liens vers tous les objets en PHP 5 se trouvaient dans un référentiel séparé, et dans zval, il n'y avait qu'un handle - un ID d'objet unique.
Pour arriver à l'objet, nous avons fait au moins 3 lectures. De plus, la mémoire pour la valeur de chaque propriété de l'objet a été allouée séparément, et nous avions besoin d'au moins 2 lectures supplémentaires pour le lire.
En PHP 7, nous avons pu passer à l'adressage direct.

L'adresse
zend_object est
zend_object accessible avec une seule instruction machine. Et les propriétés sont intégrées et pour les lire, vous n'avez besoin que d'une lecture supplémentaire. Ils sont également regroupés, ce qui
améliore la localisation des données et aide les processeurs modernes à ne pas trébucher.
En plus de la propriété prédéfinie, un lien vers la classe de cet objet est également stocké ici, certains gestionnaires - un analogue des tables de méthodes virtuelles et une table de hachage pour les propriétés qui n'ont pas été définies. En PHP, vous pouvez ajouter une propriété à n'importe quel objet qui n'a pas été défini à l'origine, et si plusieurs instructions machine sont suffisantes pour accéder à la propriété prédéfinie, alors pour les propriétés non prédéfinies, vous devrez utiliser une table de hachage, qui nécessitera des dizaines d'instructions machine. Bien sûr, cela coûte beaucoup plus cher.
Référence
Enfin, nous avons dû introduire un
type distinct pour représenter les liens PHP.

Il s'agit d'un type complètement transparent. Il n'est pas visible pour les scripts PHP. Les scripts voient un autre zval intégré à la structure zend_reference. Il est entendu que nous nous référons à une telle structure à partir d'au moins deux endroits, et le compteur de référence de cette structure est toujours supérieur à 1. Dès que le compteur tombe à 1, le lien se transforme en une valeur scalaire régulière. Le zval incorporé dans le lien est copié dans le dernier zval qui le référence et la structure elle-même est supprimée.
Il semble que travailler avec référence soit maintenant beaucoup plus compliqué qu'avec d'autres types (et c'est vrai), mais en fait en PHP 5 nous avons dû faire un travail de complexité comparable lors de l'accès à n'importe quelle valeur (même un entier premier). Maintenant, nous appliquons des protocoles plus complexes à un seul type et accélérons ainsi le travail avec tous les autres, en particulier avec les valeurs scalaires.
IS_FALSE et IS_TRUE
J'ai déjà dit que le type unique IS_BOOL était divisé en IS_FALSE et IS_TRUE séparés. Cette idée a été espionnée dans la mise en œuvre de LuaJIT et a été faite pour accélérer l'une des opérations les plus courantes - la transition conditionnelle.

Si en PHP 5, il fallait lire le type, vérifier le booléen, lire la valeur, savoir si elle est vraie ou fausse et faire une transition en fonction de cela, maintenant il suffit de simplement vérifier le type et de le comparer avec vrai:
- si c'est vrai, alors nous suivons une branche;
- si c'est moins que vrai, passez à une autre branche;
- s'il est plus que vrai, allez sur le soi-disant chemin lent (chemin lent) et là, nous vérifions de quel type il provient et ce qu'il faut en faire: s'il est entier, nous devons comparer sa valeur à 0, si float - à nouveau avec 0 ( mais réel), etc.
Convention d'appel
Un changement dans la convention d'appel ou la convention d'appel de fonction est une optimisation importante qui affecte non seulement les structures de données, mais également les algorithmes sous-jacents. Dans l'image de gauche est un petit script composé de la fonction foo () et de son appel. Ci-dessous se trouve le bytecode dans lequel ce script a été compilé par PHP 5.

Tout d'abord, je vais vous expliquer comment cela a fonctionné en PHP 5.
Convention d'appel en PHP 5
La première instruction
SEND_VAL été d'envoyer la valeur «3» à la fonction foo. Pour ce faire, elle a été forcée d'allouer un nouveau zval sur le tas, d'y copier la valeur (3) et d'écrire la valeur du pointeur sur cette structure sur la pile.
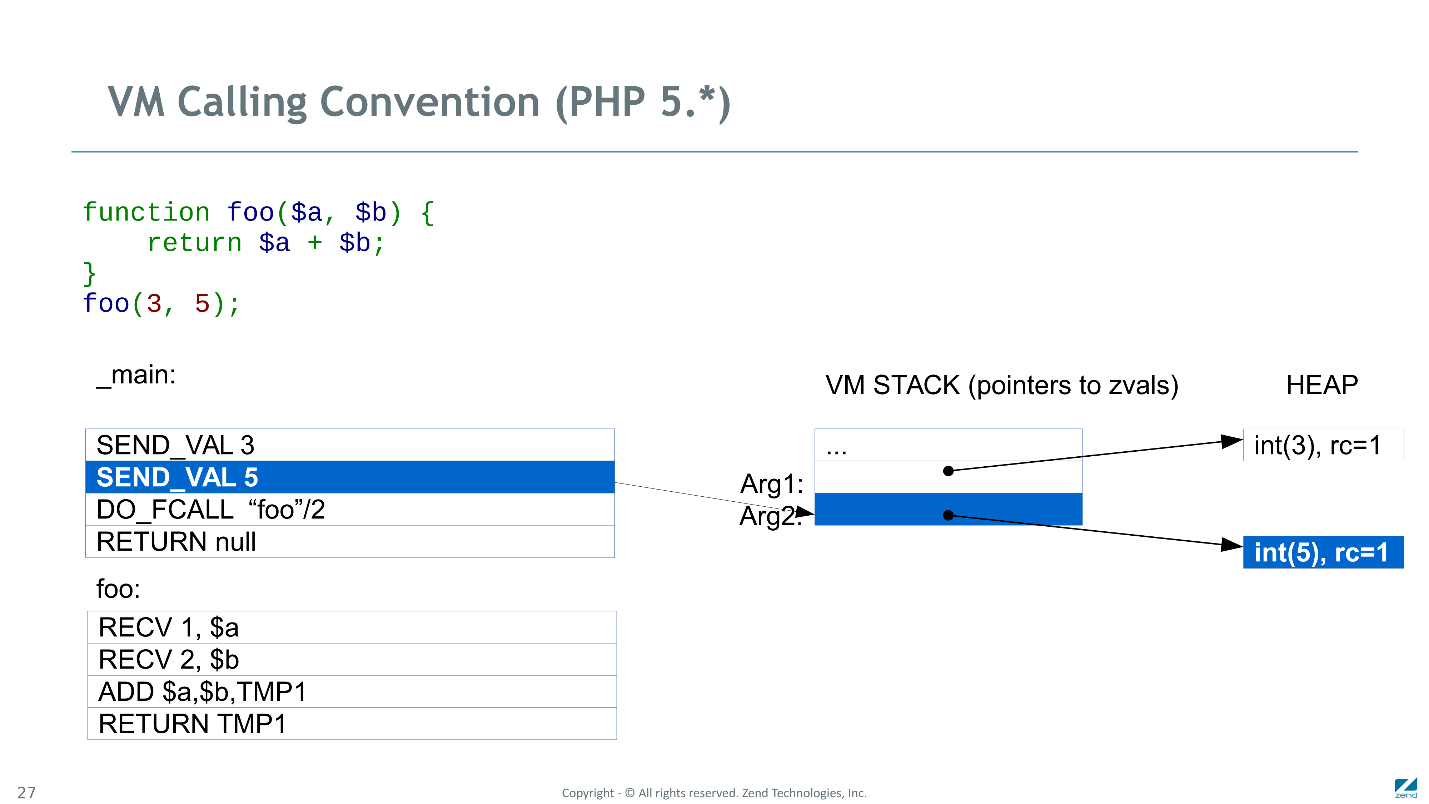
De même avec la deuxième instruction. En outre,
DO_FCALL initialisé
DO_FCALL CALL FRAME , a réservé une place pour les variables locales et temporaires et a transféré le contrôle à la fonction appelée.
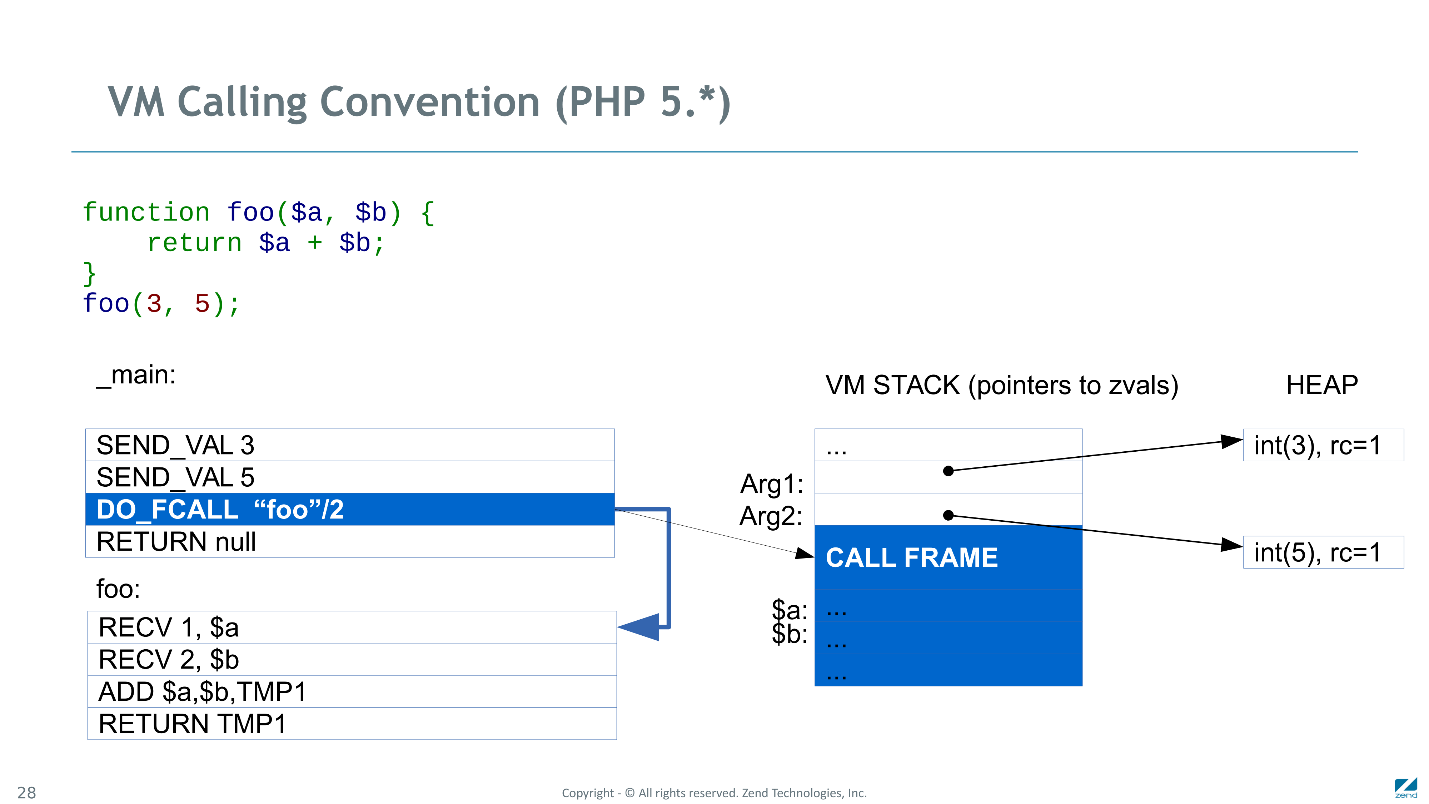
La première
RECV vérifié le premier argument et initialisé le slot sur la pile avec la variable locale correspondante ($ a). Ici, nous avons fait sans copier et simplement augmenté le compteur de référence du paramètre correspondant (zval avec une valeur de 3). De même, la deuxième
RECV établi une connexion entre la variable $ b et le paramètre 5.

Autres fonctions corporelles. L'ajout de 3 + 5 s'est produit - il s'est avéré 8. Il s'agit d'une variable temporaire et sa valeur a été stockée directement sur la pile.

RETOUR et nous revenons de la fonction.

Lors du retour, nous libérons toutes les variables et tous les arguments hors de portée. Pour ce faire, nous parcourons tous les zval référencés par les slots de la trame libérée, et pour chacun, nous diminuons le nombre de références. S'il atteint 0, détruisez la structure correspondante.
Comme vous pouvez le voir, même une opération aussi simple que l'envoi d'une constante à une fonction nécessite d'allouer de la nouvelle mémoire, de copier et d'augmenter le compteur de référence, puis de doubler la diminution et la suppression.
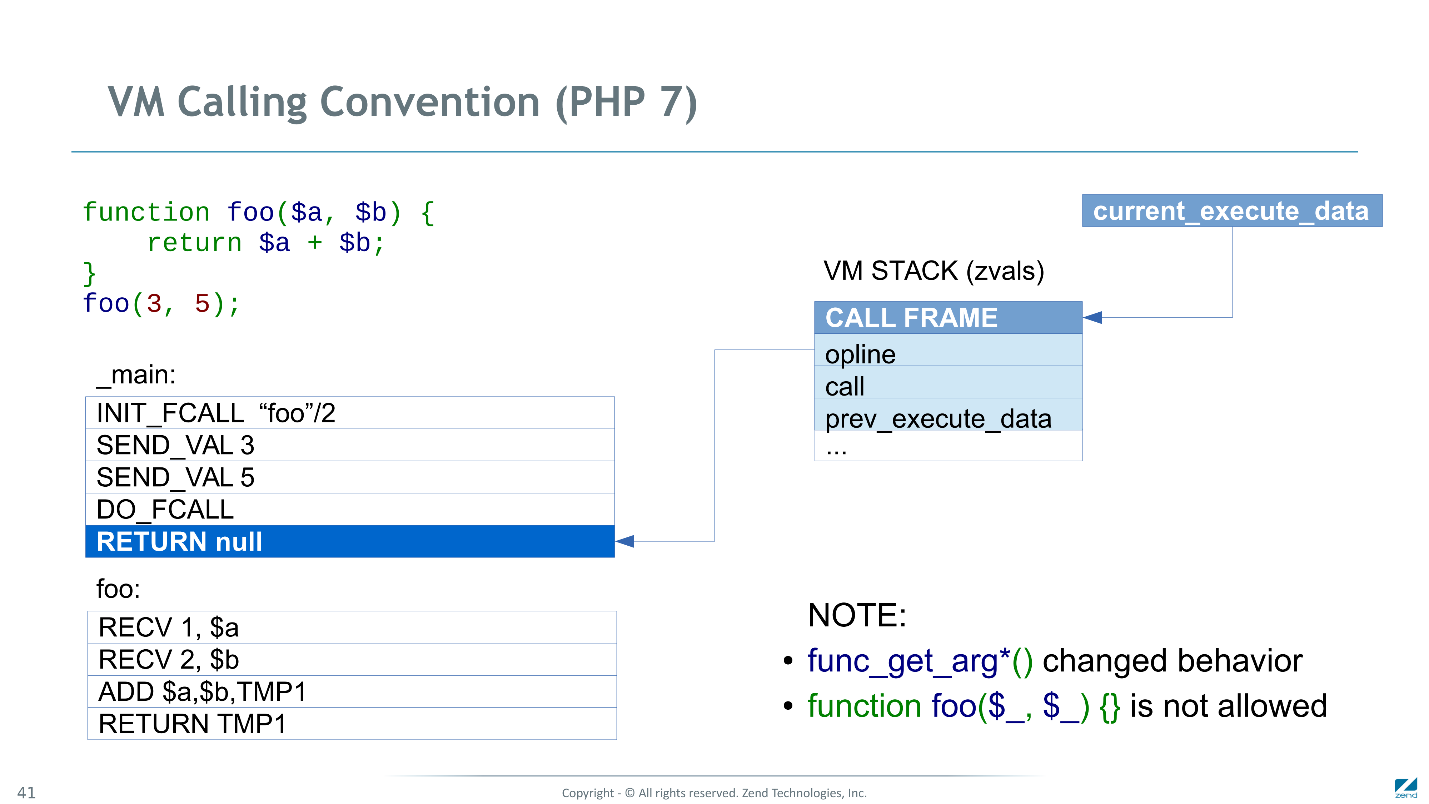
Convention d'appel en PHP 7
En PHP 7, ces problèmes ont été corrigés - maintenant sur la pile, nous stockons non pas les pointeurs zval, mais les zval eux-mêmes.

Nous avons également introduit une nouvelle instruction,
INIT_FCALL , qui est maintenant chargée d'initialiser et d'allouer de la mémoire sous
CALL FRAME , et de réserver de l'espace pour les arguments et les variables temporaires.

SEND_VAL 3 désormais l'argument dans le premier emplacement après le
CALL FRAME .
SEND_VAL 5 vers le deuxième emplacement.

Ensuite, le plus intéressant. Il semblerait que
DO_FCALL devrait passer le contrôle à la première instruction de la fonction appelée. Mais les arguments ont déjà atteint les emplacements réservés aux paramètres variables $ a et $ b, et les instructions
RECV ne font rien. Par conséquent, vous pouvez simplement les ignorer. Nous avons envoyé deux paramètres, nous sautons donc deux instructions. S'ils en avaient envoyé trois, ils en auraient manqué trois.

Nous allons donc directement au corps de la fonction, faisons l'addition et le retour.

Lors du retour, nous effaçons toutes les variables locales, mais maintenant seulement pour deux emplacements, et puisque nous avons là des scalaires, nous n'avons à nouveau rien à faire.

Mon histoire est un peu simplifiée, elle ne prend pas en compte les fonctions avec un nombre variable d'arguments et la nécessité d'une vérification de type et quelques autres points.
La nouvelle convention d'appel a un peu cassé la compatibilité . PHP a des fonctions comme
func_get_arg et
func_get_args . Si auparavant, ils renvoyaient la valeur d'origine du paramètre envoyé, ils retournent maintenant la valeur actuelle de la variable locale correspondante, car nous ne stockons tout simplement pas les valeurs d'origine. Tout comme les débogueurs C.
De plus, la fonction ne peut plus avoir plusieurs paramètres portant le même nom. Cela ne servait à rien auparavant, mais j'ai rencontré un tel code PHP
foo($_, $_) . À quoi ça ressemble? (J'ai reconnu Prolog)
Nouveau gestionnaire de mémoire
Après avoir terminé l'optimisation des structures de données et des algorithmes de base, nous avons de nouveau attiré l'attention sur tous les sous-systèmes de freinage. Le gestionnaire de mémoire en PHP 5 occupait
près de 20% du temps processeur sur Wordpress.
Une fois que nous nous sommes débarrassés de nombreuses allocations, ses frais généraux sont devenus moins importants, mais toujours importants - et non pas parce qu'il effectuait un travail important, mais parce qu'il est tombé sur la cache. Cela est dû au fait que nous avons utilisé l'algorithme malloc classique de Doug Lea, qui impliquait de trouver des emplacements de mémoire libres appropriés en voyageant à travers des liens et des arbres, et tous ces déplacements ont inévitablement causé des échecs de cache.
Aujourd'hui, il existe de nouveaux algorithmes de gestion de la mémoire qui prennent en compte les caractéristiques des processeurs modernes. Par exemple:
jemalloc et
ptmalloc de Google . Au début, nous avons essayé de les utiliser tels quels, mais nous n'avons pas obtenu gain de cause, car le manque de fonctionnalités spécifiques à PHP a rendu plus coûteuse la libération complète de la mémoire à la fin de la demande. En conséquence, nous avons abandonné dlmalloc et écrit quelque chose à nous, combinant des idées de l'ancien gestionnaire de mémoire et de jemalloc.
Nous avons
réduit la surcharge de Memory Manager à 5% , réduit la surcharge de mémoire pour les informations de service et amélioré l'utilisation du cache du processeur. Les blocs de mémoire appropriés sont désormais recherchés par bitmaps, la mémoire pour les petits blocs est allouée à partir de pages individuelles et mise en cache lors de la publication, des fonctions spécialisées pour les tailles de bloc fréquemment utilisées sont ajoutées.
De nombreuses petites améliorations
Je n'ai parlé que des améliorations les plus importantes, mais il y en a eu beaucoup plus mineures. Je peux en mentionner certains.
- API rapide pour analyser les paramètres des fonctions internes et une nouvelle API pour itérer sur HashTable.
- Nouvelles instructions VM: concaténation de chaînes, spécialisation, super-instructions.
- Certaines fonctions internes ont été transformées en instructions VM: strlen, is_int.
- Utilisation des registres CPU pour les registres VM: IP et FP.
- Optimisation de la duplication et de la suppression des tableaux.
- Utilisez le nombre de liens au lieu de copier où vous le pouvez.
- PCRE JIT.
- Optimisation des fonctions internes et sérialisation ().
- Taille de code réduite et données traitées.
Certains étaient très simples, par exemple, il n'a fallu que trois lignes de code pour activer JIT dans les expressions Perl régulières, ce qui a immédiatement apporté une accélération visible (2-3%) à presque toutes les applications. D'autres optimisations ont touché certains aspects étroits de certaines fonctions PHP et ne sont pas particulièrement intéressantes, bien que la contribution totale de toutes ces améliorations mineures soit assez importante.
Où es-tu venu
C'est la contribution de divers sous-systèmes sur WordPress / PHP 7.0.
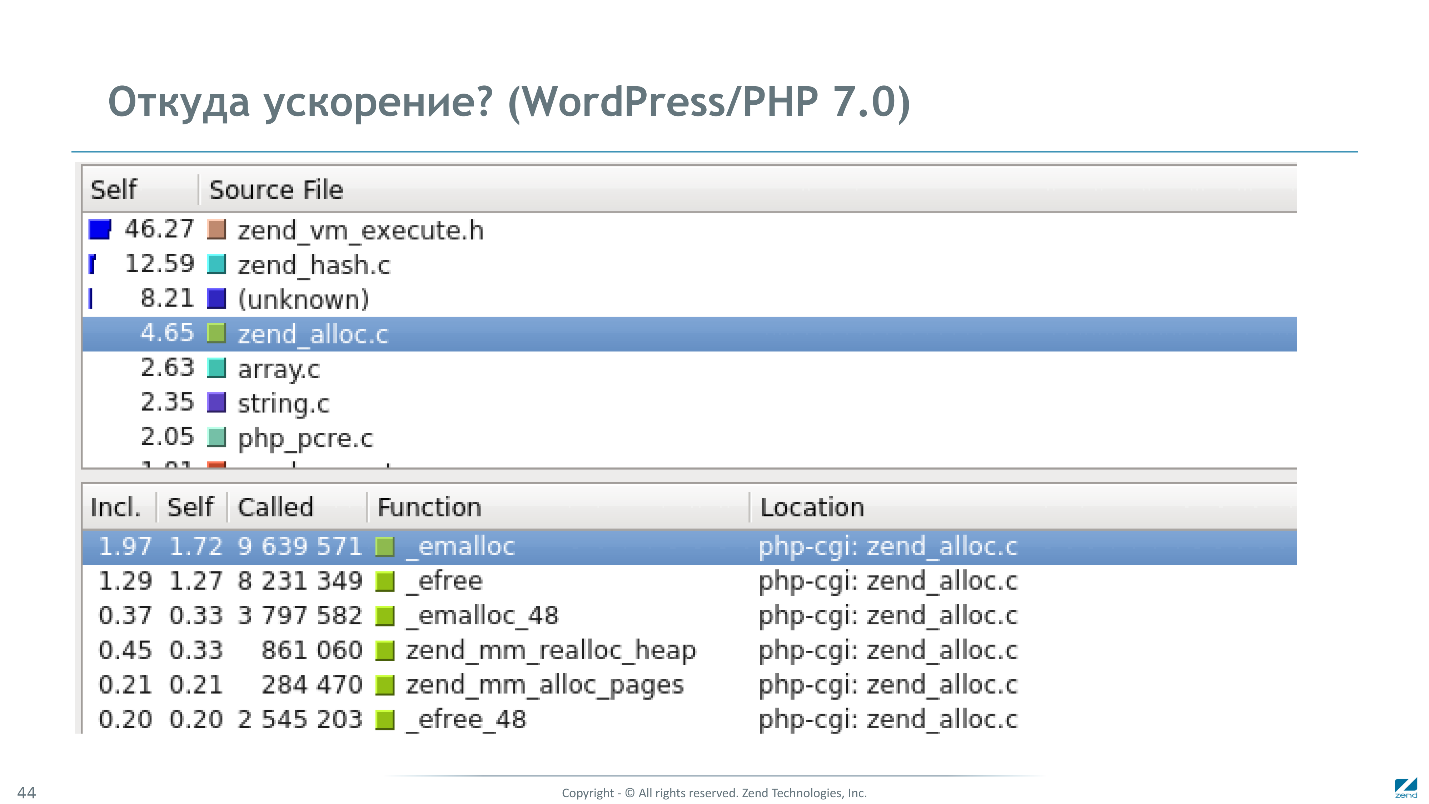
La contribution des machines virtuelles est passée à 50%. Memory Manager 5% — Memory Manager, . 130 . , 10 . , Memory Manager , .

:
- 2 .
- MM 17 .
- - 4 .
- WordPress 3,5 .
2,5- , . ? , , CPU time, — , . PHP , .
PHP 7
WordPress 3.6 — . - , PHP 7 mysql, , .

, PHPNG. 2/3 . , .
, WordPress, , — 1,5 2- .
PHP 7 HHVM
HHVM.
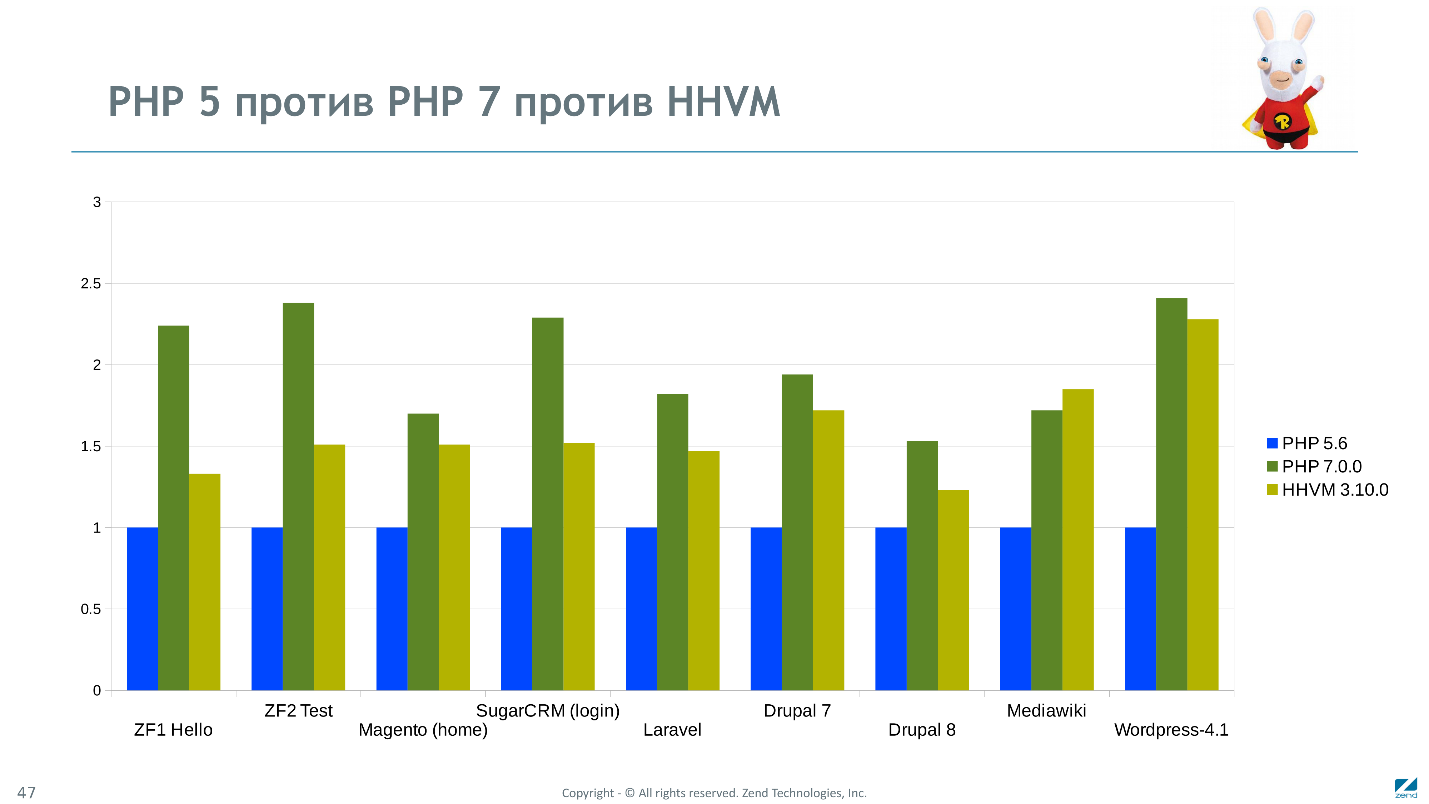
— . . Facebook . HHVM . , , , , .

PHP 7 — . Vebia, Etsy Badoo. Highload- , .
PHP 7.0 Etsy Badoo -. Badoo
.
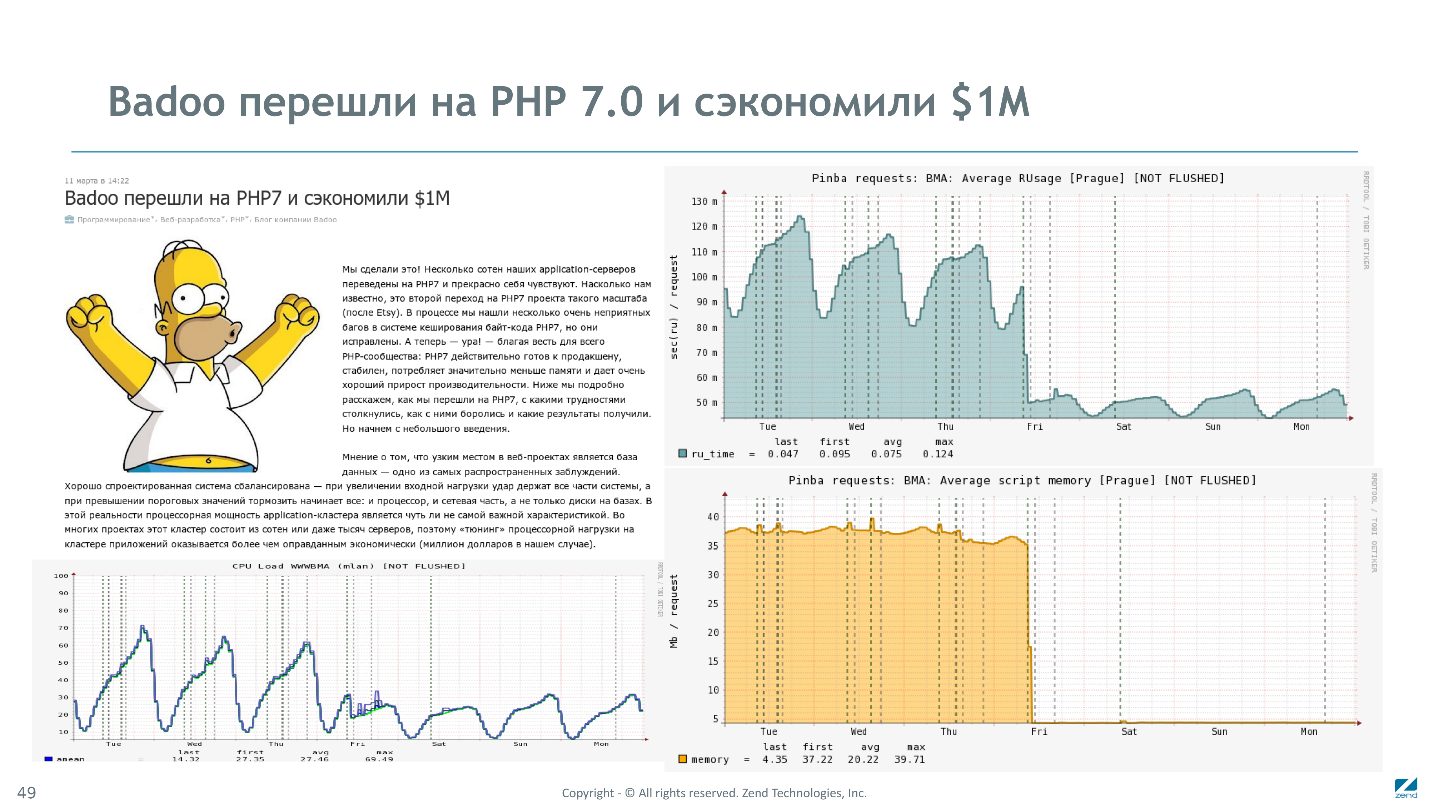
, 2 , — 7 .
PHP 7.0.
, PHP 7.1, .
PHP Russia PHP 8 . PHP, , , — 1 . , , — , , , .