
Ceci est une brève introduction à notre nouvelle pile technologique orientée données (
DOTS ). Nous partagerons quelques idées pour vous aider à comprendre comment et pourquoi Unity est devenu exactement comme ça aujourd'hui, et vous indiquerons également dans quelle direction nous prévoyons de nous développer. À l'avenir, nous prévoyons de publier de nouveaux articles sur le blog DOTS sur le blog Unity.
Parlons de C ++. C'est la langue dans laquelle l'Unité moderne est écrite.
L'un des problèmes les plus complexes qu'un développeur de jeux doit gérer d'une manière ou d'une autre est le suivant: le programmeur doit fournir un fichier exécutable avec des instructions claires pour le processeur cible, et lorsque le processeur exécute ces instructions, le jeu doit démarrer.
Dans la partie du code qui est sensible aux performances, nous savons à l'avance quelles devraient être les instructions finales. Nous avons juste besoin d'un moyen simple qui nous permette de décrire de manière cohérente notre logique, puis de vérifier et de nous assurer que les instructions dont nous avons besoin sont générées.
Nous pensons que le langage C ++ n'est pas trop bon pour cette tâche. Par exemple, je veux que ma boucle soit vectorisée, mais il peut y avoir un million de raisons pour lesquelles le compilateur ne pourra pas la vectoriser. Soit aujourd'hui elle est vectorisée, mais demain elle ne l'est pas, en raison d'un changement apparemment insignifiant. Il est même difficile de s’assurer que tous mes compilateurs C / C ++ vont même vectoriser mon code.
Nous avons décidé de développer notre propre «moyen très pratique de générer du code machine» qui répondrait à tous nos souhaits. Il serait possible de passer beaucoup de temps à plier légèrement toute la séquence de conception C ++ dans la direction dont nous avons besoin, mais nous avons décidé qu'il serait beaucoup plus raisonnable d'investir notre force dans le développement d'une chaîne d'outils qui résoudrait complètement tous les problèmes de conception auxquels nous sommes confrontés. Nous le développerions en tenant compte précisément des tâches que le développeur du jeu doit résoudre.
Quels facteurs priorisons-nous?
- Performance = correcte. Je devrais pouvoir dire: "si pour une raison quelconque cette boucle n'est pas vectorisée, alors ce doit être une erreur de compilation, et non une situation de la catégorie" oh, le code a commencé à fonctionner seulement huit fois plus lentement, mais donne toujours vraies valeurs, affaires quelque chose!
- Plateforme croisée. Le code d'entrée que j'écris doit rester exactement le même quelle que soit la plate-forme cible - que ce soit iOS ou Xbox.
- Nous devrions avoir une boucle d'itération soignée dans laquelle je peux facilement voir le code machine généré pour n'importe quelle architecture lorsque je change mon code source. Le "visualiseur" de code machine devrait être d'une grande aide pour la formation / explication lorsque vous avez besoin de comprendre ce que font toutes ces instructions machine.
- La sécurité En règle générale, les développeurs de jeux ne placent pas la sécurité en haut de leur liste de priorités, mais nous pensons que l'une des fonctionnalités les plus intéressantes d'Unity est qu'il est vraiment très difficile d'endommager la mémoire. Il devrait y avoir un tel mode dans lequel nous exécutons n'importe quel code - et nous corrigeons sans ambiguïté une erreur par laquelle une grande lettre affiche un message sur ce qui s'est passé ici: par exemple, j'ai dépassé les limites lors de la lecture / écriture ou essayé de déréférencer zéro.
Donc, après avoir compris ce qui est important pour nous, passons à la question suivante: dans quelle langue est-il préférable d'écrire des programmes à partir desquels un tel code machine sera ensuite généré? Disons que nous avons les options suivantes:
- Propre langue
- Une certaine adaptation / sous-ensemble de C ou C ++
- Sous-ensemble de c #
Quoi, C #? Pour nos boucles internes dont les performances sont particulièrement critiques? Oui C # est un choix tout à fait naturel, avec lequel dans le contexte d'Unity il y a beaucoup de choses très agréables:
- C'est la langue avec laquelle nos utilisateurs travaillent déjà aujourd'hui.
- Il a un excellent IDE, à la fois pour l'édition / refactoring et pour le débogage.
- Il existe déjà un compilateur qui convertit C # en IL intermédiaire (nous parlons du compilateur Roslyn pour C # de Microsoft), et vous pouvez simplement l'utiliser au lieu d'écrire le vôtre. Nous avons une riche expérience dans la conversion d'un langage intermédiaire en IL, nous avons donc juste besoin de générer du code et de post-traiter un programme spécifique.
- C # est dépourvu de nombreux problèmes C ++ (enfer avec l'inclusion d'en-têtes, de modèles PIMPL, long temps de compilation)
J'aime moi-même vraiment écrire du code en C #. Cependant, le C # traditionnel n'est pas le meilleur langage en termes de performances. L'équipe de développement C #, les équipes responsables de la bibliothèque standard et de l'exécution au cours des deux dernières années ont fait d'énormes progrès dans ce domaine. Cependant, en travaillant avec C #, il est impossible de contrôler exactement où se trouvent vos données en mémoire. Et c'est précisément ce problème que nous devons résoudre pour augmenter la productivité.
De plus, la bibliothèque standard de ce langage est organisée autour d '«objets sur le tas» et «d'objets qui ont des pointeurs vers d'autres objets».
Dans le même temps, en travaillant avec un fragment de code dans lequel les performances sont critiques, vous pouvez presque complètement vous passer d'une bibliothèque standard (au revoir à Linq, StringFormatter, List, Dictionary), interdire les opérations de sélection (= pas de classes, seulement les structures), la réflexion, désactiver le garbage collector et le virtuel et ajoutez quelques nouveaux conteneurs autorisés à utiliser (NativeArray et compagnie). Dans ce cas, les éléments restants du langage C # semblent déjà très bien. Voir le blog Aras pour des exemples, où il décrit un projet de traçage de fortune.
Un tel sous-ensemble nous aidera à faire face facilement à toutes les tâches pertinentes lors de l'utilisation de cycles chauds. Comme il s'agit d'un sous-ensemble complet de C #, vous pouvez travailler avec lui comme avec C # normal. Nous pouvons recevoir des erreurs associées à un déplacement à l'étranger lors de l'accès, nous obtiendrons d'excellents messages d'erreur, nous prendrons en charge le débogueur et la vitesse de compilation sera telle que vous l'avez déjà oublié lorsque vous travaillez avec C ++. Nous appelons souvent ce sous-ensemble le High Performance C # ou HPC #.
Compilateur Burst: quoi aujourd'hui?
Nous avons écrit un générateur / compilateur de code appelé Burst. Il est disponible dans
Unity version
2018.1 et supérieure en tant que package en mode "aperçu". Beaucoup de travail reste à faire avec lui, mais nous sommes satisfaits de lui aujourd'hui.
Parfois, nous parvenons à travailler plus rapidement qu'en C ++, souvent - encore plus lentement qu'en C ++. La deuxième catégorie comprend les bogues de performance qui, nous en sommes convaincus, pourront y faire face.
Cependant, une simple comparaison des performances ne suffit pas. Ce qui doit être fait pour obtenir de telles performances n'est pas moins important. Exemple: nous avons pris le code d'abattage de notre moteur de rendu C ++ actuel et l'avons porté sur Burst. Les performances n'ont pas changé, mais dans la version C ++, nous avons dû faire un acte d'équilibrage incroyable pour persuader nos compilateurs C ++ de faire de la vectorisation. La version avec Burst était environ quatre fois plus compacte.
Honnêtement, toute l'histoire avec "vous devez réécrire votre code critique pour les performances en C #" à première vue n'a pas attiré personne dans l'équipe Unity interne. Pour la plupart d'entre nous, cela ressemblait à «plus proche du matériel!» Lorsque vous travaillez avec C ++. Mais maintenant, la situation a changé. En utilisant C #, nous contrôlons complètement l'ensemble du processus, de la compilation du code source à la génération du code machine, et si nous n'aimons aucun détail, nous le prenons et le corrigeons.
Nous allons porter lentement mais sûrement tout le code essentiel aux performances de C ++ vers HPC #. Dans ce langage, il est plus facile d'atteindre les performances dont nous avons besoin, plus difficile d'écrire un bogue et plus facile à utiliser.
Voici une capture d'écran de Burst Inspector, où vous pouvez facilement voir quelles instructions d'assemblage ont été générées pour vos différentes boucles actives:
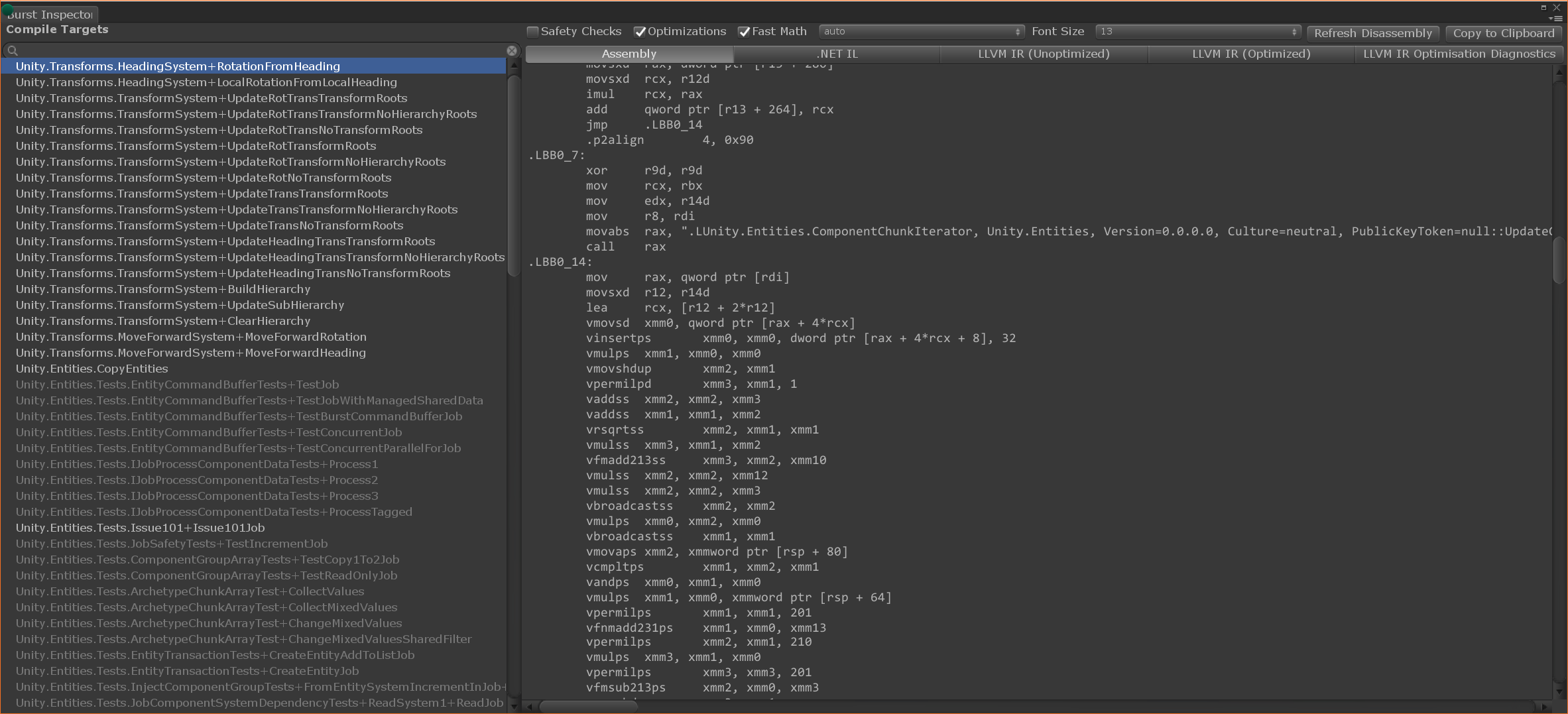
Unity a de nombreux utilisateurs différents. Certains d'entre eux peuvent se souvenir de l'ensemble des instructions arm64 de mémoire, tandis que d'autres créent simplement avec enthousiasme, même sans doctorat en informatique.
Tous les utilisateurs gagnent en accélérant la fraction du temps de trame qui est consacrée à l'exécution du code moteur (généralement 90% +). La part de travail avec le code exécutable du package Asset Store s'accélère vraiment, car les auteurs du package Asset Store adoptent HPC #.
Les utilisateurs avancés bénéficieront également du fait qu'ils peuvent écrire leur propre code haute performance sur HPC #.
Optimisation des points
En C ++, il est très difficile d'obtenir que le compilateur prenne différentes décisions de compromis sur l'optimisation du code dans différentes parties de votre projet. L'optimisation la plus détaillée sur laquelle vous pouvez compter est une indication fichier par fichier du niveau d'optimisation.
Burst est conçu pour que vous puissiez accepter la seule méthode de ce programme en entrée, à savoir: le point d'entrée vers la boucle chaude. Burst compile cette fonction, ainsi que tout ce qu'elle appelle (ces éléments appelés doivent être garantis connus à l'avance: nous n'autorisons pas les fonctions virtuelles ou les pointeurs de fonction).
Étant donné que Burst ne fonctionne que sur une partie relativement petite du programme, nous avons défini le niveau d'optimisation à 11. Burst intègre presque tous les sites d'appels. Supprimez les vérifications if, qui autrement ne seraient pas supprimées, car dans le formulaire intégré, nous obtenons des informations plus complètes sur les arguments de la fonction.
Comment cela aide-t-il à résoudre les problèmes de filetage courants?
C ++ (ainsi que C #) n'aident pas particulièrement les développeurs à écrire du code thread-safe.
Même aujourd'hui, plus d'une décennie après qu'un processeur de jeu typique a commencé à être équipé de deux cœurs ou plus, il est très difficile d'écrire des programmes qui utilisent efficacement plusieurs cœurs.
La course aux données, le non-déterminisme et les blocages sont les principaux défis qui rendent si difficile l'écriture de code multi-thread. Dans ce contexte, nous avons besoin de fonctionnalités de la catégorie "assurez-vous que cette fonction et tout ce qu'elle appelle ne commenceront jamais à lire ou à écrire l'état global". Nous voulons que toutes les violations de cette règle génèrent des erreurs de compilation et ne restent pas "des règles que nous espérons que tous les programmeurs respecteront". Burst renvoie une erreur de compilation.
Nous recommandons fortement aux utilisateurs d'Unity (et nous gardons les mêmes dans leur cercle) d'écrire du code afin que toutes les transformations de données qui y sont prévues soient divisées en tâches. Chaque tâche est «fonctionnelle» et, comme effet secondaire, gratuite. Il indique explicitement les tampons en lecture seule et les tampons en lecture / écriture avec lesquels il doit fonctionner. Toute tentative d'accès à d'autres données entraînera une erreur de compilation.
Le Planificateur de tâches garantit que personne n'écrira dans votre tampon en lecture seule pendant l'exécution de votre tâche. Et nous garantissons que pendant la durée de la tâche, personne ne lira depuis votre tampon, conçu pour la lecture et l'écriture.
Chaque fois que vous affectez une tâche qui viole ces règles, vous recevrez une erreur de compilation. Non seulement dans un événement aussi malheureux que les conditions de la course. Le message d'erreur vous expliquera que vous essayez d'affecter une tâche qui devrait lire à partir du tampon A, mais précédemment vous avez affecté une tâche qui va écrire dans A. Par conséquent, si vous voulez vraiment le faire, la tâche précédente doit être spécifiée comme une dépendance .
Nous pensons qu'un tel mécanisme de sécurité permet d'attraper un grand nombre de bogues avant qu'ils ne soient corrigés, et garantit donc l'utilisation efficace de tous les cœurs. Il devient impossible de provoquer des conditions de course ou une impasse. Les résultats sont garantis pour être déterministes, quel que soit le nombre de threads dont vous disposez, ou combien de fois un thread est interrompu en raison de l'intervention d'un autre processus.
Maîtrisez toute la pile
Lorsque nous pouvons aller au fond de tous ces composants, nous pouvons également nous assurer qu'ils sont conscients les uns des autres. Par exemple, une raison courante d'échec de la vectorisation est la suivante: le compilateur ne peut pas garantir que deux pointeurs ne pointeront pas vers le même point mémoire (aliasing). Nous savons que deux NativeArray ne se chevaucheront en aucun cas comme ça, car ils ont écrit une bibliothèque de collection, et nous pouvons utiliser cette connaissance dans Burst, donc nous ne refuserons pas d'optimiser uniquement de peur que deux pointeurs ne soient dirigés vers un seul le même morceau de mémoire.
De même, nous avons écrit la bibliothèque mathématique
Unity.Mathematics . Burst, elle est connue "à fond" Burst (à l'avenir) pourra signaler l'opt-out de l'optimisation dans des cas comme math.sin (). Puisque pour Burst math.sin () n'est pas seulement une méthode C # ordinaire qui doit être compilée, elle comprendra également les propriétés trigonométriques de sin (), elle comprendra que sin (x) == x pour les petites valeurs x (que Burst peut prouver indépendamment ), comprendra qu'il peut être remplacé par l'expansion de la série Taylor, sacrifiant en partie la précision. À l'avenir, Burst prévoit également de mettre en œuvre un déterminisme multiplateforme et de conception à virgule flottante - nous pensons que de tels objectifs sont réalisables.
Les différences entre le code du moteur de jeu et le code du jeu sont floues
Lorsque nous écrivons le code d'exécution Unity en HPC #, le moteur de jeu et le jeu en tant que tel sont tous écrits dans le même langage. Nous pouvons distribuer les systèmes d'exécution que nous avons convertis en HPC # en tant que code source. Chacun peut apprendre d'eux, les améliorer, les adapter pour lui-même. Nous aurons un terrain de jeu d'un certain niveau, et rien n'empêchera nos utilisateurs d'écrire un meilleur système de particules, une physique de jeu ou un moteur de rendu que nous avons écrit. En rapprochant nos processus de développement internes des processus de développement des utilisateurs, nous pouvons également nous sentir mieux dans la peau de l'utilisateur, nous mettrons donc tous nos efforts pour créer un seul flux de travail, plutôt que deux différents.