La dernière fois, nous avons parlé de la cohérence des données, examiné la différence entre les différents niveaux d'isolement des transactions aux yeux de l'utilisateur et compris pourquoi il était important de le savoir. Nous commençons maintenant à apprendre comment PostgreSQL implémente l'isolement basé sur les instantanés et le multi-versionnement.
Dans cet article, nous verrons comment les données sont physiquement situées dans des fichiers et des pages. Cela nous éloigne du sujet de l'isolement, mais une telle digression est nécessaire pour comprendre d'autres éléments. Nous devons comprendre le fonctionnement du stockage de données de bas niveau.
Les relations
Si vous regardez à l'intérieur des tables et des index, il s'avère qu'ils sont disposés de manière similaire. À la fois cela et un autre - objets de base qui contiennent des données constituées de lignes.
Le fait que le tableau se compose de lignes ne fait aucun doute; pour l'indice, c'est moins évident. Cependant, imaginez un arbre B: il se compose de nœuds qui contiennent des valeurs indexées et des liens vers d'autres nœuds ou vers des lignes de table. Ces nœuds peuvent être considérés comme des lignes d'index - en fait, tels quels.
En fait, il existe encore un certain nombre d'objets disposés de manière similaire: séquences (essentiellement des tables à une seule ligne), vues matérialisées (essentiellement des tables qui se souviennent de la requête). Et puis il y a les vues habituelles, qui en elles-mêmes ne stockent pas de données, mais dans tous les autres sens sont similaires aux tableaux.
Tous ces objets dans PostgreSQL sont appelés la
relation de mots communs. Le mot est extrêmement malheureux car c'est un terme de la théorie relationnelle. Vous pouvez faire un parallèle entre la relation et la table (vue), mais certainement pas entre la relation et l'index. Mais il en est ainsi: les racines académiques de PostgreSQL se font sentir. Je pense qu'au début, cela s'appelait des tables et des vues, et le reste a augmenté avec le temps.
De plus, pour plus de simplicité, nous ne parlerons que des tables et des index, mais le reste des
relations sont structurées exactement de la même manière.
Calques (fourches) et fichiers
Habituellement, chaque relation a plusieurs
couches (fourches). Les couches sont de plusieurs types et chacune contient un certain type de données.
S'il y a une couche, elle est d'abord représentée par un seul
fichier . Le nom du fichier est constitué d'un identifiant numérique auquel la fin correspondant au nom de la couche peut être ajoutée.
Le fichier augmente progressivement et lorsque sa taille atteint 1 Go, le fichier suivant de la même couche est créé (ces fichiers sont parfois appelés
segments ). Le numéro de segment est ajouté à la fin du nom de fichier.
La limite de taille de fichier de 1 Go est apparue historiquement pour prendre en charge divers systèmes de fichiers, dont certains ne peuvent pas fonctionner avec des fichiers volumineux. La restriction peut être modifiée lors de la construction de PostgreSQL (
./configure --with-segsize ).
Ainsi, plusieurs fichiers peuvent correspondre à une relation sur un disque. Par exemple, pour une petite table, il y en aura 3.
Tous les fichiers d'objets appartenant à un espace table et à une base de données seront placés dans un répertoire. Ceci doit être pris en compte car les systèmes de fichiers ne fonctionnent généralement pas très bien avec un grand nombre de fichiers dans un répertoire.
Notez simplement que les fichiers, à leur tour, sont divisés en
pages (ou
blocs ), généralement 8 Ko. Nous allons parler de la structure interne des pages ci-dessous.
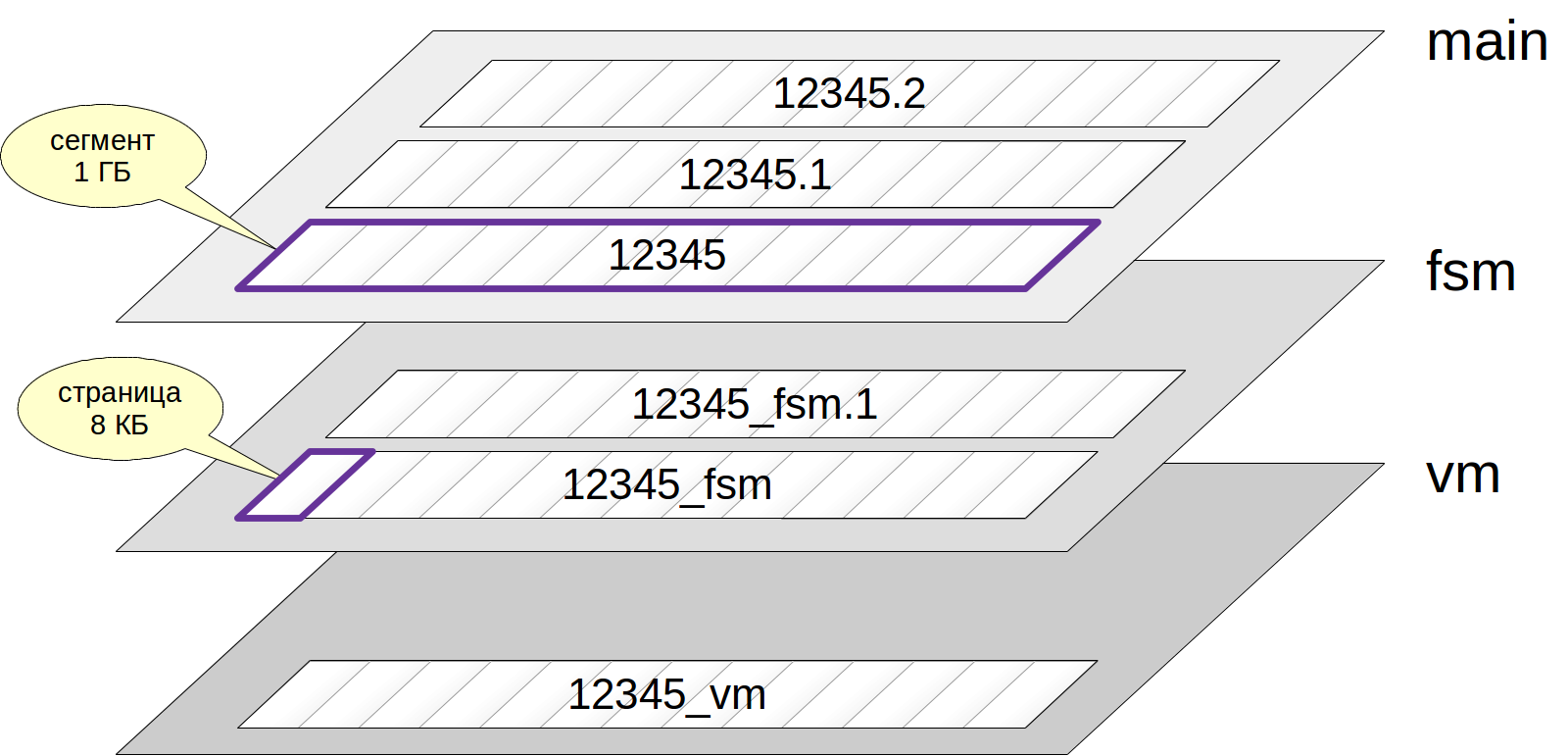
Voyons maintenant les types de calques.
La couche principale est constituée des données elles-mêmes: la même table ou les mêmes lignes d'index. La couche principale existe pour toute relation (sauf pour les représentations qui ne contiennent pas de données).
Les noms des fichiers de la couche principale ne sont constitués que d'un identifiant numérique. Voici un exemple de chemin d'accès au fichier de table que nous avons créé la dernière fois:
=> SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41496 (1 row)
D'où viennent ces identifiants? Le répertoire de base correspond au tablespace pg_default, le sous-répertoire suivant correspond à la base de données, et le fichier qui nous intéresse s'y trouve déjà:
=> SELECT oid FROM pg_database WHERE datname = 'test';
oid ------- 41493 (1 row)
=> SELECT relfilenode FROM pg_class WHERE relname = 'accounts';
relfilenode ------------- 41496 (1 row)
Le chemin est relatif, il est compté à partir du répertoire de données (PGDATA). De plus, presque tous les chemins dans PostgreSQL sont comptés à partir de PGDATA. Grâce à cela, vous pouvez transférer PGDATA en toute sécurité vers un autre endroit - il ne contient rien (sauf si vous devrez peut-être configurer le chemin d'accès aux bibliothèques dans LD_LIBRARY_PATH).
Nous regardons plus loin dans le système de fichiers:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41496
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41496
Une couche d'initialisation existe uniquement pour les tables non journalisées (créées avec UNLOGGED) et leurs index. Ces objets ne sont pas différents des objets ordinaires, sauf que les actions avec eux ne sont pas enregistrées dans le journal de pré-enregistrement. Pour cette raison, le travail avec eux est plus rapide, mais en cas de panne, il est impossible de restaurer les données dans un état cohérent. Par conséquent, lors de la récupération, PostgreSQL supprime simplement toutes les couches de ces objets et écrit la couche d'initialisation à la place de la couche principale. Le résultat est un "mannequin". Nous parlerons de la journalisation en détail, mais dans un cycle différent.
La table des comptes est journalisée, il n'y a donc pas de couche d'initialisation pour elle. Mais pour l'expérience, vous pouvez désactiver la journalisation:
=> ALTER TABLE accounts SET UNLOGGED; => SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41507 (1 row)
La possibilité d'activer et de désactiver la journalisation à la volée, comme le montre l'exemple, implique le remplacement des données dans des fichiers avec des noms différents.
La couche d'initialisation porte le même nom que la couche principale, mais avec le suffixe "_init":
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_init
-rw------- 1 postgres postgres 0 /var/lib/postgresql/11/main/base/41493/41507_init
Carte de l'espace libre (
carte de l'espace libre) - une couche dans laquelle il y a un espace vide à l'intérieur des pages. Cet endroit est en constante évolution: lorsque de nouvelles versions de chaînes sont ajoutées, elles diminuent, tout en nettoyant - elles augmentent. La carte d'espace libre est utilisée lors de l'insertion de nouvelles versions de lignes pour trouver rapidement une page appropriée sur laquelle les données à ajouter tiendront.
La carte d'espace libre a le suffixe "_fsm". Mais le fichier n'apparaît pas immédiatement, mais seulement si nécessaire. La façon la plus simple d'y parvenir est de nettoyer la table (pourquoi - parlons en temps voulu):
=> VACUUM accounts;
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_fsm
-rw------- 1 postgres postgres 24576 /var/lib/postgresql/11/main/base/41493/41507_fsm
Une carte de visibilité est une couche dans laquelle les pages qui contiennent uniquement les versions actuelles des chaînes sont marquées d'un bit. En gros, cela signifie que lorsqu'une transaction essaie de lire une ligne à partir d'une telle page, la ligne peut être affichée sans vérifier sa visibilité. Nous examinerons en détail comment cela se produit dans les articles suivants.
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_vm
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41507_vm
Pages
Comme nous l'avons déjà dit, les fichiers sont logiquement divisés en pages.
En règle générale, une page fait 8 Ko. Vous pouvez modifier la taille dans certaines limites (16 Ko ou 32 Ko), mais uniquement pendant l'assemblage (
./configure --with-blocksize ). L'instance assemblée et en cours d'exécution peut fonctionner avec des pages d'une seule taille.
Quelle que soit la couche à laquelle appartiennent les fichiers, ils sont utilisés par le serveur de la même manière. Les pages sont d'abord lues dans le cache tampon, où les processus peuvent les lire et les modifier; puis, si nécessaire, les pages sont repoussées sur le disque.
Chaque page a un balisage interne et contient généralement les sections suivantes:
0 + ----------------------------------- +
| titre |
24 + ----------------------------------- +
| tableau de pointeurs vers les chaînes de version |
inférieur + ----------------------------------- +
| espace libre |
supérieur + ----------------------------------- +
| versions de ligne |
spécial + ----------------------------------- +
| zone spéciale |
taille de page + ----------------------------------- +
La taille de ces sections est facile à découvrir avec l'extension "research" pageinspect:
=> CREATE EXTENSION pageinspect; => SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('accounts',0));
lower | upper | special | pagesize -------+-------+---------+---------- 40 | 8016 | 8192 | 8192 (1 row)
Nous regardons ici le
titre de la toute première page (zéro) du tableau. En plus de la taille des zones restantes, l'en-tête contient d'autres informations sur la page, mais cela ne nous intéresse pas encore.
Au bas de la page se trouve une
zone spéciale , dans notre cas, vide. Il n'est utilisé que pour les index, puis pas pour tout le monde. Le «bas» correspond ici à l'image; il serait peut-être plus juste de dire «à des adresses élevées».
Après la zone spéciale se trouvent
les versions de ligne - les données mêmes que nous stockons dans le tableau, ainsi que certaines informations de surcharge.
En haut de la page, immédiatement après l'en-tête, se trouve la table des matières: un
tableau de pointeurs vers la version des lignes disponibles dans la page.
Entre les versions de lignes et de pointeurs, il peut y avoir de
l'espace libre (qui est marqué sur la carte de l'espace libre). Notez qu'il n'y a pas de fragmentation à l'intérieur de la page, tout l'espace libre est toujours représenté par un fragment.
Pointeurs
Pourquoi des pointeurs vers des versions de chaînes sont-ils nécessaires? Le fait est que les lignes d'index doivent en quelque sorte faire référence à la version des lignes de la table. Il est clair que le lien doit contenir le numéro de fichier, le numéro de page dans le fichier et une indication de la version de la ligne. Un décalage par rapport au début de la page pourrait être utilisé comme une telle indication, mais cela n'est pas pratique. Nous ne pourrions pas déplacer la version de la ligne à l'intérieur de la page car cela casserait les liens existants. Et cela entraînerait une fragmentation de l'espace à l'intérieur des pages et d'autres conséquences désagréables. Par conséquent, l'index fait référence au numéro d'index et le pointeur fait référence à la position actuelle de la version de ligne dans la page. Il s'avère que l'adressage indirect.
Chaque pointeur occupe exactement 4 octets et contient:
- lien vers la version de la chaîne;
- la longueur de cette version de la chaîne;
- plusieurs bits qui déterminent l'état de version d'une chaîne.
Format des données
Le format des données sur le disque coïncide complètement avec la représentation des données en RAM. La page est lue dans le cache tampon "en l'état", sans aucune transformation. Par conséquent, les fichiers de données d'une plate-forme sont incompatibles avec d'autres plates-formes.
Par exemple, dans l'architecture x86, l'ordre des octets est adopté du moins significatif au plus élevé (little-endian), z / Architecture utilise l'ordre inverse (big-endian), et dans ARM l'ordre de commutation.
De nombreuses architectures assurent l'alignement des données au-delà des limites des mots machine. Par exemple, sur un système x86 32 bits, les entiers (type entier, occupent 4 octets) seront alignés sur la bordure des mots de 4 octets, ainsi que les nombres à virgule flottante double précision (type double précision, 8 octets). Et sur un système 64 bits, les valeurs doubles seront alignées sur la bordure des mots de 8 octets. C'est une autre raison de l'incompatibilité.
En raison de l'alignement, la taille de la ligne du tableau dépend de l'ordre des champs. Habituellement, cet effet n'est pas très visible, mais dans certains cas, il peut entraîner une augmentation significative de la taille. Par exemple, si vous placez les champs char (1) et entier mélangés, 3 octets seront généralement gaspillés entre eux. Vous pouvez en savoir plus à ce sujet dans la présentation de Nikolai Shaplov «
What's Inside It ».
Versions String et TOAST
À propos de la façon dont les versions des chaînes sont organisées de l'intérieur, nous parlerons en détail la prochaine fois. Jusqu'à présent, la seule chose importante pour nous est que chaque version doit tenir entièrement sur une seule page: PostgreSQL ne fournit pas un moyen de "continuer" la ligne sur la page suivante. Au lieu de cela, une technologie appelée TOAST (The Oversized Attributes Storage Technique) est utilisée. Le nom lui-même suggère que la chaîne peut être coupée en toasts.
Plus sérieusement, TOAST implique plusieurs stratégies. Les valeurs d'attribut «longues» peuvent être envoyées à une table de service distincte, préalablement coupées en petits morceaux de pain grillé. Une autre option consiste à compresser la valeur afin que la version de la ligne tienne toujours sur une page de table normale. Et il est possible à la fois cela et un autre: d'abord compresser, puis seulement couper et envoyer.
Pour chaque table principale, si nécessaire, une table distincte, mais une pour tous les attributs, la table TOAST (et un index spécial pour celle-ci) est créée. La nécessité est déterminée par la présence d'attributs potentiellement longs dans la table. Par exemple, si une table a une colonne de type numérique ou texte, une table TOAST sera créée immédiatement, même si les valeurs longues ne sont pas utilisées.
Étant donné que la table TOAST est essentiellement une table régulière, elle a toujours le même ensemble de couches. Et cela double le nombre de fichiers qui «servent» la table.
Initialement, les stratégies sont déterminées par les types de données de colonne. Vous pouvez les visualiser avec la commande
\d+ en psql, mais comme elle affiche également de nombreuses autres informations, nous utiliserons la requête dans le répertoire système:
=> SELECT attname, atttypid::regtype, CASE attstorage WHEN 'p' THEN 'plain' WHEN 'e' THEN 'external' WHEN 'm' THEN 'main' WHEN 'x' THEN 'extended' END AS storage FROM pg_attribute WHERE attrelid = 'accounts'::regclass AND attnum > 0;
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | extended client | text | extended amount | numeric | main (4 rows)
Les noms des stratégies ont les significations suivantes:
- plain - TOAST n'est pas utilisé (utilisé pour les types de données manifestement «courts», comme l'entier);
- étendu - la compression et le stockage dans une table TOAST distincte sont autorisés;
- externe - les valeurs longues sont stockées dans la table TOAST non compressées;
- main - les valeurs longues sont compressées en premier et uniquement dans la table TOAST si la compression n'a pas aidé.
En termes généraux, l'algorithme est le suivant. PostgreSQL veut qu'au moins 4 lignes tiennent sur une page. Par conséquent, si la taille de la ligne dépasse la quatrième partie de la page, en tenant compte de l'en-tête (avec une page normale de 8 Ko, c'est 2040 octets), TOAST doit être appliqué à une partie des valeurs. Nous agissons dans l'ordre décrit ci-dessous et nous nous arrêtons dès que la ligne cesse de dépasser le seuil:
- Tout d'abord, nous trions les attributs avec des stratégies externes et étendues, en passant du plus long au plus court. Les attributs étendus sont compressés (si cela a un effet) et, si la valeur elle-même dépasse un quart de la page, elle est immédiatement envoyée à la table TOAST. Les attributs externes sont gérés de la même manière, mais ne sont pas compressés.
- Si après la première passe, la version de la ligne ne correspond toujours pas, nous envoyons les attributs restants avec les stratégies externes et étendues à la table TOAST.
- Si cela ne vous aide pas non plus, essayez de compresser les attributs avec la stratégie principale, tout en les laissant dans la page du tableau.
- Et seulement si après cela la ligne n'est toujours pas assez courte, les principaux attributs sont envoyés à la table TOAST.
Parfois, il peut être utile de modifier la stratégie de certaines colonnes. Par exemple, s'il est connu à l'avance que les données de la colonne ne sont pas compressées, vous pouvez définir une stratégie externe pour cela - cela vous évitera des tentatives de compression inutiles. Cela se fait comme suit:
=> ALTER TABLE accounts ALTER COLUMN number SET STORAGE external;
En répétant la demande, nous obtenons:
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | external client | text | extended amount | numeric | main
Les tables et index TOAST sont situés dans un schéma pg_toast distinct et ne sont donc généralement pas visibles. Pour les tables temporaires, le schéma pg_toast_temp_
N est utilisé, similaire au pg_temp_
N. habituel
.Bien sûr, si vous le souhaitez, personne ne prend la peine de jeter un œil à la mécanique interne du processus. Supposons qu'il y ait trois attributs potentiellement longs dans la table des comptes, donc une table TOAST doit l'être. Le voici:
=> SELECT relnamespace::regnamespace, relname FROM pg_class WHERE oid = ( SELECT reltoastrelid FROM pg_class WHERE relname = 'accounts' );
relnamespace | relname --------------+---------------- pg_toast | pg_toast_33953 (1 row)
=> \d+ pg_toast.pg_toast_33953
TOAST table "pg_toast.pg_toast_33953" Column | Type | Storage ------------+---------+--------- chunk_id | oid | plain chunk_seq | integer | plain chunk_data | bytea | plain
Il est logique que pour les "toasts" dans lesquels la ligne est tranchée, la stratégie simple soit appliquée: TOAST du deuxième niveau n'existe pas.
L'index PostgreSQL se cache plus soigneusement, mais il est également facile à trouver:
=> SELECT indexrelid::regclass FROM pg_index WHERE indrelid = ( SELECT oid FROM pg_class WHERE relname = 'pg_toast_33953' );
indexrelid ------------------------------- pg_toast.pg_toast_33953_index (1 row)
=> \d pg_toast.pg_toast_33953_index
Unlogged index "pg_toast.pg_toast_33953_index" Column | Type | Key? | Definition -----------+---------+------+------------ chunk_id | oid | yes | chunk_id chunk_seq | integer | yes | chunk_seq primary key, btree, for table "pg_toast.pg_toast_33953"
La colonne client utilise la stratégie étendue: les valeurs qu'elle contient seront compressées. Vérifier:
=> UPDATE accounts SET client = repeat('A',3000) WHERE id = 1; => SELECT * FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | chunk_data ----------+-----------+------------ (0 rows)
Il n'y a rien dans la table TOAST: les caractères répétitifs sont parfaitement compressés et après cela la valeur tient dans une page de table normale.
Maintenant, laissez le nom du client composé de caractères aléatoires:
=> UPDATE accounts SET client = ( SELECT string_agg( chr(trunc(65+random()*26)::integer), '') FROM generate_series(1,3000) ) WHERE id = 1 RETURNING left(client,10) || '...' || right(client,10);
?column? ------------------------- TCKGKZZSLI...RHQIOLWRRX (1 row)
Cette séquence ne peut pas être compressée et tombe dans la table TOAST:
=> SELECT chunk_id, chunk_seq, length(chunk_data), left(encode(chunk_data,'escape')::text, 10) || '...' || right(encode(chunk_data,'escape')::text, 10) FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | length | ?column? ----------+-----------+--------+------------------------- 34000 | 0 | 2000 | TCKGKZZSLI...ZIPFLOXDIW 34000 | 1 | 1000 | DDXNNBQQYH...RHQIOLWRRX (2 rows)
Comme vous pouvez le voir, les données sont découpées en fragments de 2000 octets.
Lors de l'accès à une valeur "longue", PostgreSQL automatiquement, transparent pour l'application, restaure la valeur d'origine et la renvoie au client.
Bien sûr, beaucoup de ressources sont consacrées à la compression en tranches et à la récupération ultérieure. Par conséquent, le stockage de données volumineuses dans PostgreSQL n'est pas une bonne idée, surtout si elles sont activement utilisées et qu'aucune logique transactionnelle n'est requise pour elles (par exemple: les originaux scannés de documents comptables). Une alternative plus rentable pourrait être de stocker ces données sur le système de fichiers et, dans le SGBD, les noms des fichiers correspondants.
Une table TOAST n'est utilisée que lorsqu'elle se réfère à une valeur «longue». De plus, la table toast a son propre versioning: si la mise à jour des données n'affecte pas la valeur "longue", la nouvelle version de la ligne se référera à la même valeur dans la table TOAST - cela économise de l'espace.
Notez que TOAST ne fonctionne que pour les tables, mais pas pour les index. Cela impose une limite sur la taille des clés indexées.
Vous pouvez en savoir plus sur l'organisation des données internes dans la documentation .
À suivre .