Le paquet tidyr fait partie du noyau de l'une des bibliothèques les plus populaires du langage R - tidyverse .
L'objectif principal du package est de donner aux données une apparence soignée.
Sur Habré, il existe déjà une publication dédiée à ce package, mais elle date de 2015. Et je veux vous parler des changements les plus pertinents annoncés il y a quelques jours par son auteur Hadley Wickham.
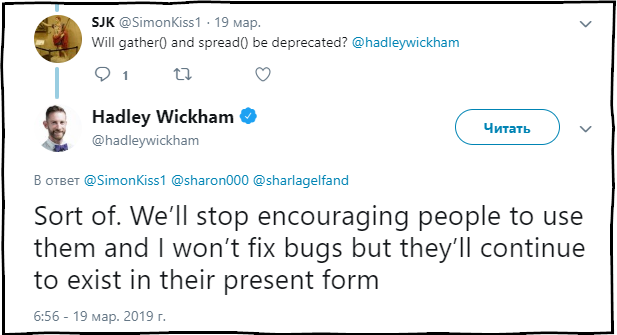
SJK : Les fonctions de collecte () et de diffusion () seront-elles obsolètes?
Hadley Wickham : Dans une certaine mesure. Nous cesserons de recommander l'utilisation de ces fonctions et corrigerons les erreurs, mais elles continueront d'être présentes dans le package dans l'état actuel.
Table des matières
Concept TidyData
Le but de tidyr est de vous aider à donner aux données une apparence soignée. Des données précises sont des données où:
- Chaque variable est dans une colonne.
- Chaque observation est une ligne.
- Chaque valeur est une cellule.
Les données qui sont données aux données bien rangées sont beaucoup plus simples et plus pratiques à utiliser pendant l'analyse.
Les principales fonctions incluses dans le paquet tidyr
tidyr contient un ensemble de fonctions pour transformer des tables:
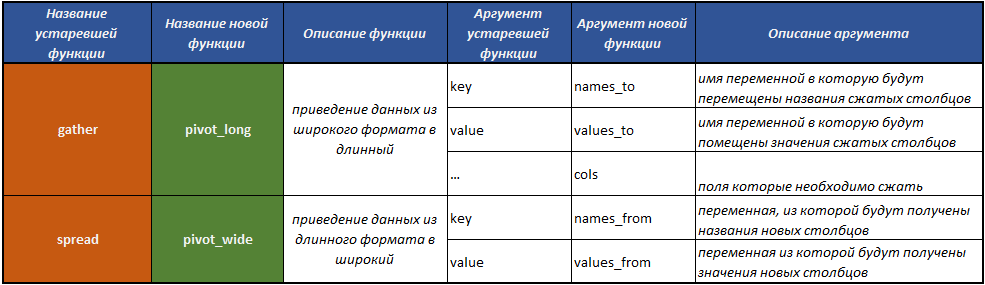
fill() - remplir les valeurs manquantes dans la colonne avec les valeurs précédentes;separate() - divise un champ en plusieurs par le biais d'un séparateur;unite() - effectue l'opération de combinaison de plusieurs champs en un seul, l'inverse de la fonction separate() ;pivot_longer() - une fonction qui convertit les données d'un format large en un format long;pivot_wider() - une fonction qui convertit les données d'un format long en format large. L'opération est l'opposé de celle effectuée par la fonction pivot_longer() .gather() obsolète - une fonction qui convertit les données d'un format large à un long;spread() obsolète - une fonction qui convertit les données d'un format long en format large. L'opération est l'opposé de celle effectuée par la fonction gather() .
Auparavant, les fonctions gather() et spread() utilisées pour ce type de transformation. Au cours des années d'existence de ces fonctions, il est devenu évident que pour la plupart des utilisateurs, y compris l'auteur du package, les noms de ces fonctions et leurs arguments n'étaient pas tout à fait évidents, et ont causé des difficultés à les trouver et à comprendre laquelle de ces fonctions fait passer le cadre de dates de large à long. format et vice versa.
À cet égard, deux nouvelles fonctions importantes ont été ajoutées à tidyr , qui sont conçues pour transformer les calendriers .
Les nouvelles fonctions pivot_longer() et pivot_wider() ont été inspirées par certaines des fonctions du package cdata créé par John Mount et Nina Zumel.
Installation de la version la plus récente de tidyr 0.8.3.9000
Pour installer la nouvelle version la plus récente du package tidyr 0.8.3.9000 , dans laquelle de nouvelles fonctions sont disponibles, utilisez le code suivant.
devtools::install_github("tidyverse/tidyr")
Au moment de l'écriture, ces fonctions ne sont disponibles que dans la version dev du package sur GitHub.
Passer à de nouvelles fonctionnalités
En fait, il n'est pas difficile de transférer d'anciens scripts pour travailler avec de nouvelles fonctions, pour une meilleure compréhension, je vais prendre un exemple de la documentation des anciennes fonctions et montrer comment ces mêmes opérations sont effectuées en utilisant les nouvelles fonctions pivot_*() .
Convertissez le format large en format long.
Exemple de code de la documentation de la fonction de collecte # example library(dplyr) stocks <- data.frame( time = as.Date('2009-01-01') + 0:9, X = rnorm(10, 0, 1), Y = rnorm(10, 0, 2), Z = rnorm(10, 0, 4) ) # old stocks_gather <- stocks %>% gather(key = stock, value = price, -time) # new stocks_long <- stocks %>% pivot_longer(cols = -time, names_to = "stock", values_to = "price")
Conversion d'un format long en large.
Exemple de code de la documentation de la fonction d'étalement # old stocks_spread <- stocks_gather %>% spread(key = stock, value = price) # new stock_wide <- stocks_long %>% pivot_wider(names_from = "stock", values_from = "price")
Parce que dans les exemples ci-dessus de travail avec pivot_longer() et pivot_wider() , dans les stocks de la table source, aucune colonne n'est répertoriée dans les arguments names_to et values_to, leurs noms doivent être indiqués entre guillemets.
Le tableau à l'aide duquel vous saurez le plus facilement comment passer au travail avec le nouveau concept tidyr .
Note de l'auteur
Tout le texte ci-dessous est adaptatif, je dirais même une traduction gratuite de la vignette du site officiel de la bibliothèque tidyverse.
pivot_longer () - pivot_longer () les ensembles de données en diminuant le nombre de colonnes et en augmentant le nombre de lignes.

Pour exécuter les exemples présentés dans l'article, vous devez d'abord connecter les packages nécessaires:
library(tidyr) library(dplyr) library(readr)
Supposons que nous ayons un tableau avec les résultats d'une enquête dans laquelle (entre autres choses) les gens étaient interrogés sur leur religion et leur revenu annuel:
#> # A tibble: 18 x 11 #> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` #> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 Agnostic 27 34 60 81 76 137 #> 2 Atheist 12 27 37 52 35 70 #> 3 Buddhist 27 21 30 34 33 58 #> 4 Catholic 418 617 732 670 638 1116 #> 5 Don't k… 15 14 15 11 10 35 #> 6 Evangel… 575 869 1064 982 881 1486 #> 7 Hindu 1 9 7 9 11 34 #> 8 Histori… 228 244 236 238 197 223 #> 9 Jehovah… 20 27 24 24 21 30 #> 10 Jewish 19 19 25 25 30 95 #> # … with 8 more rows, and 4 more variables: `$75-100k` <dbl>, #> # `$100-150k` <dbl>, `>150k` <dbl>, `Don't know/refused` <dbl>
Ce tableau contient des données sur la religion des répondants dans les lignes et les niveaux de revenu sont répartis sur les noms de colonne. Le nombre de répondants de chaque catégorie est stocké dans les valeurs des cellules à l'intersection de la religion et du niveau de revenu. Pour amener le tableau dans un format correct et correct, utilisez simplement pivot_longer() :
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count")
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count") #> # A tibble: 180 x 3 #> religion income count #> <chr> <chr> <dbl> #> 1 Agnostic <$10k 27 #> 2 Agnostic $10-20k 34 #> 3 Agnostic $20-30k 60 #> 4 Agnostic $30-40k 81 #> 5 Agnostic $40-50k 76 #> 6 Agnostic $50-75k 137 #> 7 Agnostic $75-100k 122 #> 8 Agnostic $100-150k 109 #> 9 Agnostic >150k 84 #> 10 Agnostic Don't know/refused 96 #> # … with 170 more rows
Arguments de pivot_longer()
- Le premier argument, cols , décrit les colonnes à fusionner. Dans ce cas, toutes les colonnes sauf l' heure .
- L'argument names_to donne le nom de la variable qui sera créée à partir des noms de colonne que nous avons combinés.
- values_to donne le nom de la variable qui sera créée à partir des données stockées dans les valeurs de cellule des colonnes jointes.
Spécifications techniques
Il s'agit de la nouvelle fonctionnalité du package tidyr , qui n'était pas disponible auparavant lors de l'utilisation de fonctions obsolètes.
Une spécification est un bloc de données, dont chaque ligne correspond à une colonne dans un nouveau bloc de date de sortie et à deux colonnes spéciales commençant par:
- .name contient le nom d'origine de la colonne.
- .value contient le nom de la colonne dans laquelle iront les valeurs des cellules.
Les colonnes restantes de la spécification reflètent la façon dont le nom des colonnes compressibles de .name sera affiché dans la nouvelle colonne.
La spécification décrit les métadonnées stockées dans le nom de la colonne, avec une ligne pour chaque colonne et une colonne pour chaque variable combinée avec le nom de la colonne, cette définition semble probablement confuse maintenant, mais après avoir examiné quelques exemples, tout deviendra beaucoup plus clair.
La spécification signifie que vous pouvez récupérer, modifier et définir de nouvelles métadonnées pour le bloc de données converti.
La fonction pivot_longer_spec() est pivot_longer_spec() pour travailler avec des spécifications lors de la conversion d'une table d'un format large en un format long.
Comment cette fonction fonctionne, elle prend n'importe quel cadre de date et génère ses métadonnées comme décrit ci-dessus.
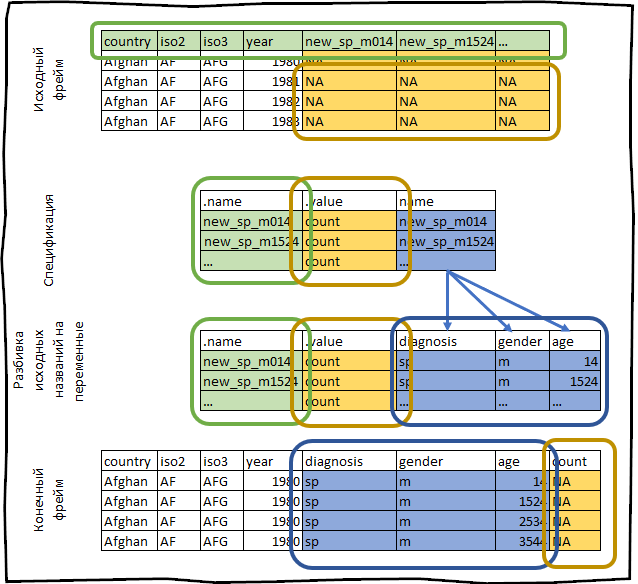
Par exemple, prenons l'ensemble de données who fourni avec le package tidyr . Cet ensemble de données contient des informations fournies par l'organisation internationale de la santé sur l'incidence de la tuberculose.
who #> # A tibble: 7,240 x 60 #> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534 #> <chr> <chr> <chr> <int> <int> <int> <int> #> 1 Afghan… AF AFG 1980 NA NA NA #> 2 Afghan… AF AFG 1981 NA NA NA #> 3 Afghan… AF AFG 1982 NA NA NA #> 4 Afghan… AF AFG 1983 NA NA NA #> 5 Afghan… AF AFG 1984 NA NA NA #> 6 Afghan… AF AFG 1985 NA NA NA #> 7 Afghan… AF AFG 1986 NA NA NA #> 8 Afghan… AF AFG 1987 NA NA NA #> 9 Afghan… AF AFG 1988 NA NA NA #> 10 Afghan… AF AFG 1989 NA NA NA #> # … with 7,230 more rows, and 53 more variables
Nous construisons sa spécification.
spec <- who %>% pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")
#> # A tibble: 56 x 3 #> .name .value name #> <chr> <chr> <chr> #> 1 new_sp_m014 count new_sp_m014 #> 2 new_sp_m1524 count new_sp_m1524 #> 3 new_sp_m2534 count new_sp_m2534 #> 4 new_sp_m3544 count new_sp_m3544 #> 5 new_sp_m4554 count new_sp_m4554 #> 6 new_sp_m5564 count new_sp_m5564 #> 7 new_sp_m65 count new_sp_m65 #> 8 new_sp_f014 count new_sp_f014 #> 9 new_sp_f1524 count new_sp_f1524 #> 10 new_sp_f2534 count new_sp_f2534 #> # … with 46 more rows
Les champs country , iso2 , iso3 sont déjà des variables. Notre tâche consiste à inverser les colonnes de new_sp_m014 à newrel_f65 .
Les noms de ces colonnes stockent les informations suivantes:
- Le préfixe
new_ indique que la colonne contient des données sur les nouveaux cas de tuberculose, le cadre de date actuel ne contient que des informations sur les nouvelles maladies, donc ce préfixe dans le contexte actuel n'a aucune signification. sp / rel / sp / ep décrit une méthode de diagnostic d'une maladie.- sexe
m / f du patient. 014 tranche d'âge du patient.
Nous pouvons séparer ces colonnes en utilisant la fonction extract() utilisant une expression régulière.
spec <- spec %>% extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")
#> # A tibble: 56 x 5 #> .name .value diagnosis gender age #> <chr> <chr> <chr> <chr> <chr> #> 1 new_sp_m014 count sp m 014 #> 2 new_sp_m1524 count sp m 1524 #> 3 new_sp_m2534 count sp m 2534 #> 4 new_sp_m3544 count sp m 3544 #> 5 new_sp_m4554 count sp m 4554 #> 6 new_sp_m5564 count sp m 5564 #> 7 new_sp_m65 count sp m 65 #> 8 new_sp_f014 count sp f 014 #> 9 new_sp_f1524 count sp f 1524 #> 10 new_sp_f2534 count sp f 2534 #> # … with 46 more rows
Notez que la colonne .name doit rester inchangée, car il s'agit de notre index dans les noms de colonne de l'ensemble de données source.
Le sexe et l'âge (colonnes sexe et âge ) ont des valeurs fixes et connues, il est donc recommandé de convertir ces colonnes en facteurs:
spec <- spec %>% mutate( gender = factor(gender, levels = c("f", "m")), age = factor(age, levels = unique(age), ordered = TRUE) )
Enfin, afin d'appliquer la spécification que nous avons créée à la date d'origine de la trame who , nous devons utiliser l'argument spec dans la fonction pivot_longer() .
who %>% pivot_longer(spec = spec)
#> # A tibble: 405,440 x 8 #> country iso2 iso3 year diagnosis gender age count #> <chr> <chr> <chr> <int> <chr> <fct> <ord> <int> #> 1 Afghanistan AF AFG 1980 sp m 014 NA #> 2 Afghanistan AF AFG 1980 sp m 1524 NA #> 3 Afghanistan AF AFG 1980 sp m 2534 NA #> 4 Afghanistan AF AFG 1980 sp m 3544 NA #> 5 Afghanistan AF AFG 1980 sp m 4554 NA #> 6 Afghanistan AF AFG 1980 sp m 5564 NA #> 7 Afghanistan AF AFG 1980 sp m 65 NA #> 8 Afghanistan AF AFG 1980 sp f 014 NA #> 9 Afghanistan AF AFG 1980 sp f 1524 NA #> 10 Afghanistan AF AFG 1980 sp f 2534 NA #> # … with 405,430 more rows
Tout ce que nous venons de faire peut être schématisé comme suit:
Spécification utilisant plusieurs valeurs (.value)
Dans l'exemple ci-dessus, la colonne de spécification .value ne contenait qu'une seule valeur, dans la plupart des cas, cela se produit.
Mais parfois, une situation peut se produire lorsque vous devez collecter des données à partir de colonnes avec différents types de données dans les valeurs. En utilisant la fonction spread() obsolète, cela serait assez difficile.
L'exemple suivant est emprunté à la vignette du package data.table .
Créons un cadre de données d'entraînement.
family <- tibble::tribble( ~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2, 1L, "1998-11-26", "2000-01-29", 1L, 2L, 2L, "1996-06-22", NA, 2L, NA, 3L, "2002-07-11", "2004-04-05", 2L, 2L, 4L, "2004-10-10", "2009-08-27", 1L, 1L, 5L, "2000-12-05", "2005-02-28", 2L, 1L, ) family <- family %>% mutate_at(vars(starts_with("dob")), parse_date)
#> # A tibble: 5 x 5 #> family dob_child1 dob_child2 gender_child1 gender_child2 #> <int> <date> <date> <int> <int> #> 1 1 1998-11-26 2000-01-29 1 2 #> 2 2 1996-06-22 NA 2 NA #> 3 3 2002-07-11 2004-04-05 2 2 #> 4 4 2004-10-10 2009-08-27 1 1 #> 5 5 2000-12-05 2005-02-28 2 1
Le cadre de date créé dans chaque ligne contient des données sur les enfants d'une famille. Les familles peuvent avoir un ou deux enfants. Pour chaque enfant, des données sur la date de naissance et le sexe sont fournies, et les données pour chaque enfant sont dans des colonnes distinctes, notre tâche consiste à amener ces données au format correct pour l'analyse.
Veuillez noter que nous avons deux variables avec des informations sur chaque enfant: son sexe et sa date de naissance (les colonnes avec le préfixe dop contiennent la date de naissance, les colonnes avec le préfixe genre contiennent le sexe de l'enfant). Dans le résultat attendu, ils devraient être placés dans des colonnes distinctes. Nous pouvons le faire en générant une spécification dans laquelle la colonne .value aura deux valeurs différentes.
spec <- family %>% pivot_longer_spec(-family) %>% separate(col = name, into = c(".value", "child"))%>% mutate(child = parse_number(child))
#> # A tibble: 4 x 3 #> .name .value child #> <chr> <chr> <dbl> #> 1 dob_child1 dob 1 #> 2 dob_child2 dob 2 #> 3 gender_child1 gender 1 #> 4 gender_child2 gender 2
Passons donc en revue les étapes effectuées par le code ci-dessus.
pivot_longer_spec(-family) - crée une spécification qui compresse toutes les colonnes disponibles sauf la colonne famille.separate(col = name, into = c(".value", "child")) - séparez la colonne .name , qui contient les noms des champs source, soulignés et placez les valeurs dans les colonnes .value et enfant .mutate(child = parse_number(child)) - convertit les valeurs du champ enfant du texte en type de données numérique.
Nous pouvons maintenant appliquer la spécification reçue à la trame de données initiale et amener le tableau à la forme souhaitée.
family %>% pivot_longer(spec = spec, na.rm = T)
#> # A tibble: 9 x 4 #> family child dob gender #> <int> <dbl> <date> <int> #> 1 1 1 1998-11-26 1 #> 2 1 2 2000-01-29 2 #> 3 2 1 1996-06-22 2 #> 4 3 1 2002-07-11 2 #> 5 3 2 2004-04-05 2 #> 6 4 1 2004-10-10 1 #> 7 4 2 2009-08-27 1 #> 8 5 1 2000-12-05 2 #> 9 5 2 2005-02-28 1
Nous utilisons l'argument na.rm = TRUE , car le formulaire de données actuel nous oblige à créer des lignes supplémentaires pour les observations inexistantes. Parce que la famille 2 n'a qu'un seul enfant, na.rm = TRUE garantit que la famille 2 aura une ligne dans la sortie.
pivot_wider() - est la transformation inverse, et vice versa augmente le nombre de colonnes dans la date de trame en réduisant le nombre de lignes.
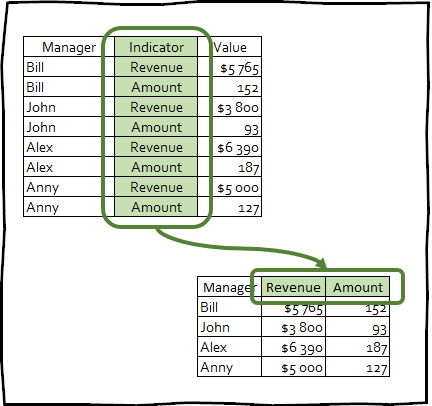
Ce type de transformation est rarement utilisé pour donner aux données une apparence soignée, mais cette technique peut être utile pour créer des tableaux croisés dynamiques utilisés dans les présentations ou pour l'intégration avec d'autres outils.
En fait, les fonctions pivot_longer() et pivot_wider() sont symétriques et effectuent des actions opposées, à savoir: df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec) et df %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec) renverra le df d'origine.
Pour démontrer le fonctionnement de la fonction pivot_wider() , nous utiliserons le jeu de données fish_encounters , qui stocke des informations sur la façon dont diverses stations enregistrent le mouvement des poissons le long de la rivière.
#> # A tibble: 114 x 3 #> fish station seen #> <fct> <fct> <int> #> 1 4842 Release 1 #> 2 4842 I80_1 1 #> 3 4842 Lisbon 1 #> 4 4842 Rstr 1 #> 5 4842 Base_TD 1 #> 6 4842 BCE 1 #> 7 4842 BCW 1 #> 8 4842 BCE2 1 #> 9 4842 BCW2 1 #> 10 4842 MAE 1 #> # … with 104 more rows
Dans la plupart des cas, ce tableau sera plus informatif et plus pratique à utiliser si vous fournissez des informations pour chaque station dans une colonne distincte.
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
fish_encounters %>% pivot_wider(names_from = station, values_from = seen) #> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 NA NA NA NA NA #> 5 4847 1 1 1 NA NA NA NA NA NA NA #> 6 4848 1 1 1 1 NA NA NA NA NA NA #> 7 4849 1 1 NA NA NA NA NA NA NA NA #> 8 4850 1 1 NA 1 1 1 1 NA NA NA #> 9 4851 1 1 NA NA NA NA NA NA NA NA #> 10 4854 1 1 NA NA NA NA NA NA NA NA #> # … with 9 more rows, and 1 more variable: MAW <int>
Cet ensemble de données enregistre des informations uniquement lorsque le poisson a été détecté par la station, c'est-à-dire si aucun poisson n'a été fixé par une station, ces données ne seront pas dans le tableau. Cela signifie que la sortie sera remplie par NA.
Cependant, dans ce cas, nous savons que l'absence d'enregistrement signifie que le poisson n'a pas été remarqué, nous pouvons donc utiliser l'argument values_fill dans la fonction pivot_wider() et remplir ces valeurs manquantes avec des zéros:
fish_encounters %>% pivot_wider( names_from = station, values_from = seen, values_fill = list(seen = 0) )
#> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 0 0 0 0 0 #> 5 4847 1 1 1 0 0 0 0 0 0 0 #> 6 4848 1 1 1 1 0 0 0 0 0 0 #> 7 4849 1 1 0 0 0 0 0 0 0 0 #> 8 4850 1 1 0 1 1 1 1 0 0 0 #> 9 4851 1 1 0 0 0 0 0 0 0 0 #> 10 4854 1 1 0 0 0 0 0 0 0 0 #> # … with 9 more rows, and 1 more variable: MAW <int>
Génération d'un nom de colonne à partir de plusieurs variables source
Imaginez que nous ayons un tableau contenant une combinaison de produit, pays et année. Pour générer une date de trame de test, vous pouvez exécuter le code suivant:
df <- expand_grid( product = c("A", "B"), country = c("AI", "EI"), year = 2000:2014 ) %>% filter((product == "A" & country == "AI") | product == "B") %>% mutate(value = rnorm(nrow(.)))
#> # A tibble: 45 x 4 #> product country year value #> <chr> <chr> <int> <dbl> #> 1 A AI 2000 -2.05 #> 2 A AI 2001 -0.676 #> 3 A AI 2002 1.60 #> 4 A AI 2003 -0.353 #> 5 A AI 2004 -0.00530 #> 6 A AI 2005 0.442 #> 7 A AI 2006 -0.610 #> 8 A AI 2007 -2.77 #> 9 A AI 2008 0.899 #> 10 A AI 2009 -0.106 #> # … with 35 more rows
Notre tâche consiste à étendre le cadre de date afin qu'une colonne contienne des données pour chaque combinaison de produit et de pays. Pour ce faire, passez simplement le vecteur contenant les noms des champs à joindre dans l'argument names_from .
df %>% pivot_wider(names_from = c(product, country), values_from = "value")
#> # A tibble: 15 x 4 #> year A_AI B_AI B_EI #> <int> <dbl> <dbl> <dbl> #> 1 2000 -2.05 0.607 1.20 #> 2 2001 -0.676 1.65 -0.114 #> 3 2002 1.60 -0.0245 0.501 #> 4 2003 -0.353 1.30 -0.459 #> 5 2004 -0.00530 0.921 -0.0589 #> 6 2005 0.442 -1.55 0.594 #> 7 2006 -0.610 0.380 -1.28 #> 8 2007 -2.77 0.830 0.637 #> 9 2008 0.899 0.0175 -1.30 #> 10 2009 -0.106 -0.195 1.03 #> # … with 5 more rows
Vous pouvez également appliquer des spécifications à la fonction pivot_wider() . Mais lorsqu'elle est alimentée à pivot_wider() spécification fait le contraire de pivot_longer() : les colonnes spécifiées dans .name sont créées en utilisant les valeurs de .value et d'autres colonnes.
Pour cet ensemble de données, vous pouvez générer une spécification utilisateur si vous souhaitez que chaque combinaison possible de pays et de produit ait sa propre colonne, et pas seulement celles qui sont présentes dans les données:
spec <- df %>% expand(product, country, .value = "value") %>% unite(".name", product, country, remove = FALSE)
#> # A tibble: 4 x 4 #> .name product country .value #> <chr> <chr> <chr> <chr> #> 1 A_AI A AI value #> 2 A_EI A EI value #> 3 B_AI B AI value #> 4 B_EI B EI value
df %>% pivot_wider(spec = spec) %>% head()
#> # A tibble: 6 x 5 #> year A_AI A_EI B_AI B_EI #> <int> <dbl> <dbl> <dbl> <dbl> #> 1 2000 -2.05 NA 0.607 1.20 #> 2 2001 -0.676 NA 1.65 -0.114 #> 3 2002 1.60 NA -0.0245 0.501 #> 4 2003 -0.353 NA 1.30 -0.459 #> 5 2004 -0.00530 NA 0.921 -0.0589 #> 6 2005 0.442 NA -1.55 0.594
Quelques exemples avancés de travail avec le nouveau concept tidyr
Apporter des données à une apparence soignée en utilisant l'ensemble de données du recensement des revenus et des loyers des États-Unis à titre d'exemple
L' ensemble de données us_rent_income contient des informations sur le revenu moyen et le loyer de chaque État des États-Unis pour 2017 (l'ensemble de données est disponible dans le package tidycensus ).
us_rent_income #> # A tibble: 104 x 5 #> GEOID NAME variable estimate moe #> <chr> <chr> <chr> <dbl> <dbl> #> 1 01 Alabama income 24476 136 #> 2 01 Alabama rent 747 3 #> 3 02 Alaska income 32940 508 #> 4 02 Alaska rent 1200 13 #> 5 04 Arizona income 27517 148 #> 6 04 Arizona rent 972 4 #> 7 05 Arkansas income 23789 165 #> 8 05 Arkansas rent 709 5 #> 9 06 California income 29454 109 #> 10 06 California rent 1358 3 #> # … with 94 more rows
Il est extrêmement gênant de travailler avec eux sous la forme dans laquelle les données de l'ensemble de données us_rent_income sont stockées.Nous aimerions donc créer un ensemble de données avec des colonnes: rent , rent_moe , come , Income_moe . Il existe de nombreuses façons de créer cette spécification, mais l'essentiel est que nous devons générer chaque combinaison des valeurs variables et estimer / moe , puis générer le nom de la colonne.
spec <- us_rent_income %>% expand(variable, .value = c("estimate", "moe")) %>% mutate( .name = paste0(variable, ifelse(.value == "moe", "_moe", "")) )
#> # A tibble: 4 x 3 #> variable .value .name #> <chr> <chr> <chr> #> 1 income estimate income #> 2 income moe income_moe #> 3 rent estimate rent #> 4 rent moe rent_moe
Fournir cette spécification à pivot_wider() nous donne le résultat que nous recherchons:
us_rent_income %>% pivot_wider(spec = spec)
#> # A tibble: 52 x 6 #> GEOID NAME income income_moe rent rent_moe #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> #> 1 01 Alabama 24476 136 747 3 #> 2 02 Alaska 32940 508 1200 13 #> 3 04 Arizona 27517 148 972 4 #> 4 05 Arkansas 23789 165 709 5 #> 5 06 California 29454 109 1358 3 #> 6 08 Colorado 32401 109 1125 5 #> 7 09 Connecticut 35326 195 1123 5 #> 8 10 Delaware 31560 247 1076 10 #> 9 11 District of Columbia 43198 681 1424 17 #> 10 12 Florida 25952 70 1077 3 #> # … with 42 more rows
Banque mondiale
Parfois, amener l'ensemble de données au bon format nécessite plusieurs étapes.
L'ensemble de données world_bank_pop contient des données de la Banque mondiale sur la population de chaque pays de 2000 à 2018.
#> # A tibble: 1,056 x 20 #> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006` #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4 #> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2 #> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5 #> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1 #> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6 #> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0 #> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7 #> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0 #> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7 #> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0 #> # … with 1,046 more rows, and 11 more variables: `2007` <dbl>, #> # `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>, #> # `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>
Notre objectif est de créer un ensemble de données soigné où chaque variable se trouve dans une colonne distincte. Il n'est pas encore clair quelles étapes sont nécessaires, mais nous commencerons par le problème le plus évident: l'année est répartie sur plusieurs colonnes.
Pour résoudre ce problème, vous devez utiliser la fonction pivot_longer() .
pop2 <- world_bank_pop %>% pivot_longer(`2000`:`2017`, names_to = "year")
#> # A tibble: 19,008 x 4 #> country indicator year value #> <chr> <chr> <chr> <dbl> #> 1 ABW SP.URB.TOTL 2000 42444 #> 2 ABW SP.URB.TOTL 2001 43048 #> 3 ABW SP.URB.TOTL 2002 43670 #> 4 ABW SP.URB.TOTL 2003 44246 #> 5 ABW SP.URB.TOTL 2004 44669 #> 6 ABW SP.URB.TOTL 2005 44889 #> 7 ABW SP.URB.TOTL 2006 44881 #> 8 ABW SP.URB.TOTL 2007 44686 #> 9 ABW SP.URB.TOTL 2008 44375 #> 10 ABW SP.URB.TOTL 2009 44052 #> # … with 18,998 more rows
— indicator.
pop2 %>% count(indicator)
#> # A tibble: 4 x 2 #> indicator n #> <chr> <int> #> 1 SP.POP.GROW 4752 #> 2 SP.POP.TOTL 4752 #> 3 SP.URB.GROW 4752 #> 4 SP.URB.TOTL 4752
SP.POP.GROW — , SP.POP.TOTL — , SP.URB. * , . : area — (total urban) (population growth):
pop3 <- pop2 %>% separate(indicator, c(NA, "area", "variable"))
#> # A tibble: 19,008 x 5 #> country area variable year value #> <chr> <chr> <chr> <chr> <dbl> #> 1 ABW URB TOTL 2000 42444 #> 2 ABW URB TOTL 2001 43048 #> 3 ABW URB TOTL 2002 43670 #> 4 ABW URB TOTL 2003 44246 #> 5 ABW URB TOTL 2004 44669 #> 6 ABW URB TOTL 2005 44889 #> 7 ABW URB TOTL 2006 44881 #> 8 ABW URB TOTL 2007 44686 #> 9 ABW URB TOTL 2008 44375 #> 10 ABW URB TOTL 2009 44052 #> # … with 18,998 more rows
variable :
pop3 %>% pivot_wider(names_from = variable, values_from = value)
#> # A tibble: 9,504 x 5 #> country area year TOTL GROW #> <chr> <chr> <chr> <dbl> <dbl> #> 1 ABW URB 2000 42444 1.18 #> 2 ABW URB 2001 43048 1.41 #> 3 ABW URB 2002 43670 1.43 #> 4 ABW URB 2003 44246 1.31 #> 5 ABW URB 2004 44669 0.951 #> 6 ABW URB 2005 44889 0.491 #> 7 ABW URB 2006 44881 -0.0178 #> 8 ABW URB 2007 44686 -0.435 #> 9 ABW URB 2008 44375 -0.698 #> 10 ABW URB 2009 44052 -0.731 #> # … with 9,494 more rows
, , , -:
contacts <- tribble( ~field, ~value, "name", "Jiena McLellan", "company", "Toyota", "name", "John Smith", "company", "google", "email", "john@google.com", "name", "Huxley Ratcliffe" )
, , , . , , ("name"), , , field “name”:
contacts <- contacts %>% mutate( person_id = cumsum(field == "name") ) contacts
#> # A tibble: 6 x 3 #> field value person_id #> <chr> <chr> <int> #> 1 name Jiena McLellan 1 #> 2 company Toyota 1 #> 3 name John Smith 2 #> 4 company google 2 #> 5 email john@google.com 2 #> 6 name Huxley Ratcliffe 3
, , :
contacts %>% pivot_wider(names_from = field, values_from = value)
#> # A tibble: 3 x 4 #> person_id name company email #> <int> <chr> <chr> <chr> #> 1 1 Jiena McLellan Toyota <NA> #> 2 2 John Smith google john@google.com #> 3 3 Huxley Ratcliffe <NA> <NA>
Conclusion
, tidyr , spread() gather() . pivot_longer() pivot_wider() .