
Le code logiciel d'apprentissage automatique est souvent complexe et assez déroutant. Détecter et éliminer les bogues est une tâche gourmande en ressources. Même les
réseaux de neurones à connexion directe les plus simples nécessitent une approche sérieuse de l'architecture du réseau, de l'initialisation des pondérations et de l'optimisation du réseau. Une petite erreur peut entraîner des problèmes désagréables.
Cet article concerne l'algorithme de débogage de vos réseaux de neurones.
Skillbox recommande: Un développeur de cours pratique Python à partir de zéro .
Nous vous rappelons: pour tous les lecteurs de «Habr» - une remise de 10 000 roubles lors de l'inscription à un cours Skillbox en utilisant le code promo «Habr».
L'algorithme comprend cinq étapes:
- démarrage simple;
- confirmation des pertes;
- vérification des résultats intermédiaires et des composés;
- diagnostic des paramètres;
- contrôle du travail.
Si quelque chose vous semble plus intéressant que les autres, vous pouvez accéder directement à ces sections.
Démarrage facile
Un réseau de neurones avec une architecture complexe, une régularisation et un planificateur de vitesse d'apprentissage est plus difficile à démarrer qu'un réseau régulier. Nous sommes un peu compliqués ici, car l'élément lui-même a une relation indirecte avec le débogage, mais c'est toujours une recommandation importante.
Un début simple consiste à créer un modèle simplifié et à le former sur un ensemble de données (point).
Nous créons d'abord un modèle simplifiéPour un démarrage rapide, créez un petit réseau avec une seule couche cachée et vérifiez que tout fonctionne correctement. Ensuite, nous compliquons progressivement le modèle, vérifions chaque nouvel aspect de sa structure (couche supplémentaire, paramètre, etc.) et continuons.
Nous formons le modèle sur un seul ensemble de données (point)Pour tester rapidement la santé de votre projet, vous pouvez utiliser un ou deux points de données pour la formation afin de vérifier si le système fonctionne correctement. Le réseau neuronal doit montrer une précision de 100% de l'entraînement et de la vérification. Si ce n'est pas le cas, alors soit le modèle est trop petit soit vous avez déjà un bug.
Même si tout va bien, préparez le modèle pour le passage d'une ou plusieurs époques avant de continuer.
Estimation des pertes
L'estimation des pertes est le principal moyen d'affiner les performances du modèle. Vous devez vous assurer que la perte correspond à la tâche et que les fonctions de perte sont évaluées sur la bonne échelle. Si vous utilisez plus d'un type de perte, assurez-vous qu'ils sont tous du même ordre et correctement mis à l'échelle.
Il est important d'être attentif aux pertes initiales. Vérifiez à quel point le résultat réel est proche de celui attendu si le modèle a commencé avec une hypothèse aléatoire. Le
travail d'Andrei Karpati suggère ce qui suit : «Assurez-vous d'obtenir le résultat attendu lorsque vous commencez à travailler avec un petit nombre de paramètres. Il est préférable de vérifier immédiatement la perte de données (avec un degré de régularisation défini sur zéro). Par exemple, pour CIFAR-10 avec le classificateur Softmax, nous nous attendons à ce que la perte initiale soit de 2,302, parce que la probabilité diffuse attendue est de 0,1 pour chaque classe (car il y a 10 classes), et la perte de Softmax est la probabilité logarithmique négative de la classe correcte comme - ln (0,1) = 2,302. "
Pour un exemple binaire, un calcul similaire est simplement effectué pour chacune des classes. Voici, par exemple, les données: 20% 0 et 80% 1. La perte initiale attendue atteindra –0,2 ln (0,5) –0,8 ln (0,5) = 0,693147. Si le résultat est supérieur à 1, cela peut indiquer que les poids du réseau neuronal ne sont pas correctement équilibrés ou que les données ne sont pas normalisées.
Vérification des résultats intermédiaires et des connexions
Pour déboguer un réseau neuronal, il est nécessaire de comprendre la dynamique des processus au sein du réseau et le rôle des couches intermédiaires individuelles, car elles sont connectées. Voici quelques erreurs courantes que vous pourriez rencontrer:
- Expressions incorrectes pour les mises à jour de dégradé
- les mises à jour de poids ne s'appliquent pas;
- disparaître ou exploser des gradients.
Si les valeurs du gradient sont nulles, cela signifie que la vitesse d'apprentissage dans l'optimiseur est trop lente ou que vous avez rencontré une expression incorrecte pour mettre à jour le gradient.
De plus, il est nécessaire de surveiller les valeurs des fonctions d'activation, les poids et les mises à jour de chacune des couches. Par exemple, la valeur des mises à jour des paramètres (poids et décalages)
doit être 1-e3 .
Il y a un phénomène appelé «Dying ReLU» ou
«Disappearing Gradient Problem» lorsque les neurones ReLU sortiront zéro après avoir étudié la grande valeur de biais négatif pour leurs poids. Ces neurones ne sont plus jamais réactivés dans aucun emplacement de données.
Vous pouvez utiliser des tests de gradient pour détecter ces erreurs en approximant le gradient à l'aide d'une approche numérique. S'il est proche des gradients calculés, alors la propagation inverse a été correctement mise en œuvre. Pour créer une vérification de gradient, consultez ces excellentes ressources CS231
ici et
ici , ainsi que le didacticiel d'Andrew Nga sur ce sujet.
Fayzan Sheikh souligne trois méthodes principales pour visualiser un réseau neuronal:
- Préliminaire - méthodes simples qui nous montrent la structure générale du modèle entraîné. Ils incluent la sortie de formes ou de filtres de couches individuelles du réseau neuronal et les paramètres de chaque couche.
- Basé sur l'activation. On y déchiffre l'activation de neurones individuels ou de groupes de neurones afin de comprendre leurs fonctions.
- Basé sur un dégradé. Ces méthodes ont tendance à manipuler les gradients qui se forment à partir du passage dans les deux sens lors de l'apprentissage du modèle (y compris les cartes de signification et les cartes d'activation de classe).
Il existe plusieurs outils utiles pour visualiser les activations et les connexions de couches individuelles, par exemple
ConX et
Tensorboard .
Diagnostic des paramètres
Les réseaux de neurones ont de nombreux paramètres qui interagissent entre eux, ce qui complique l'optimisation. En fait, cette section fait l'objet d'une recherche active par des spécialistes, donc les propositions ci-dessous ne doivent être considérées que comme des conseils, les points de départ sur lesquels vous pouvez vous appuyer.
Taille du lot - Si vous souhaitez que la taille du paquet soit suffisamment grande pour fournir des estimations précises du gradient d'erreur, mais suffisamment petite pour que la descente du gradient stochastique (SGD) rationalise votre réseau. La petite taille des packages entraînera une convergence rapide due au bruit dans le processus d'apprentissage et à l'avenir à des difficultés d'optimisation. Ceci est décrit plus en détail
ici .
Vitesse d'apprentissage - Trop lent entraînera une convergence lente ou le risque d'être coincé dans les bas locaux. Dans le même temps, une vitesse d'apprentissage élevée entraînera une divergence dans l'optimisation, car vous risquez de "sauter" à travers la partie profonde, mais en même temps étroite de la fonction de perte. Essayez d'utiliser la planification de la vitesse pour la réduire pendant l'entraînement du réseau neuronal. CS231n
a une grande section sur cette question .
Écrêtage de gradient - coupe les gradients des paramètres pendant la propagation arrière à la valeur maximale ou à la norme limite. Utile pour résoudre les problèmes de dégradés explosifs que vous pouvez rencontrer dans le troisième paragraphe.
Normalisation par lots - utilisée pour normaliser les données d'entrée de chaque couche, ce qui permet de résoudre le problème de décalage covariant interne. Si vous utilisez Dropout et Batch Norma ensemble,
consultez cet article .
Descente de gradient stochastique (SGD) - Il existe plusieurs variétés de SGD qui utilisent l'élan, les vitesses d'apprentissage adaptatives et la méthode de Nesterov. Dans le même temps, aucun d'entre eux n'a un avantage clair en termes d'efficacité de formation et de généralisation (
détails ici ).
Régularisation - est cruciale pour la construction d'un modèle généralisé, car elle ajoute une pénalité pour la complexité du modèle ou des valeurs de paramètres extrêmes. C'est un moyen de réduire la variance du modèle sans augmenter significativement son déplacement. Plus d'
informations ici .
Pour tout évaluer vous-même, vous devez désactiver la régularisation et vérifier vous-même le gradient de perte de données.
Le décrochage est un autre moyen de rationaliser votre réseau pour éviter la congestion. Pendant l'entraînement, la perte se produit uniquement en maintenant l'activité du neurone avec une certaine probabilité p (hyperparamètre) ou en la mettant à zéro dans le cas contraire. Par conséquent, le réseau doit utiliser un sous-ensemble différent de paramètres pour chaque formation, ce qui réduit les changements de certains paramètres qui deviennent dominants.
Important: si vous utilisez à la fois l'abandon et la normalisation par lots, faites attention à l'ordre de ces opérations ou même à leur utilisation conjointe. Tout cela est encore activement discuté et complété. Voici deux discussions importantes sur ce sujet
sur Stackoverflow et
Arxiv .
Contrôle du travail
Il s'agit de documenter les workflows et les expériences. Si vous ne documentez rien, vous pouvez oublier, par exemple, quel type de vitesse d'entraînement ou de poids de classe est utilisé. Grâce au contrôle, vous pouvez facilement visualiser et reproduire les expériences précédentes. Cela réduit le nombre d'expériences en double.
Il est vrai que la documentation manuelle peut être difficile en cas de grande quantité de travail. Des outils tels que Comet.ml viennent à la rescousse ici, aidant à enregistrer automatiquement les ensembles de données, les modifications de code, l'historique des expériences et les modèles de production, y compris les informations clés sur votre modèle (hyperparamètres, indicateurs de performance du modèle et informations environnementales).
Un réseau de neurones peut être très sensible aux petits changements, ce qui entraînera une diminution des performances du modèle. Le suivi et la documentation du travail est la première étape à suivre pour normaliser votre environnement et votre modélisation.
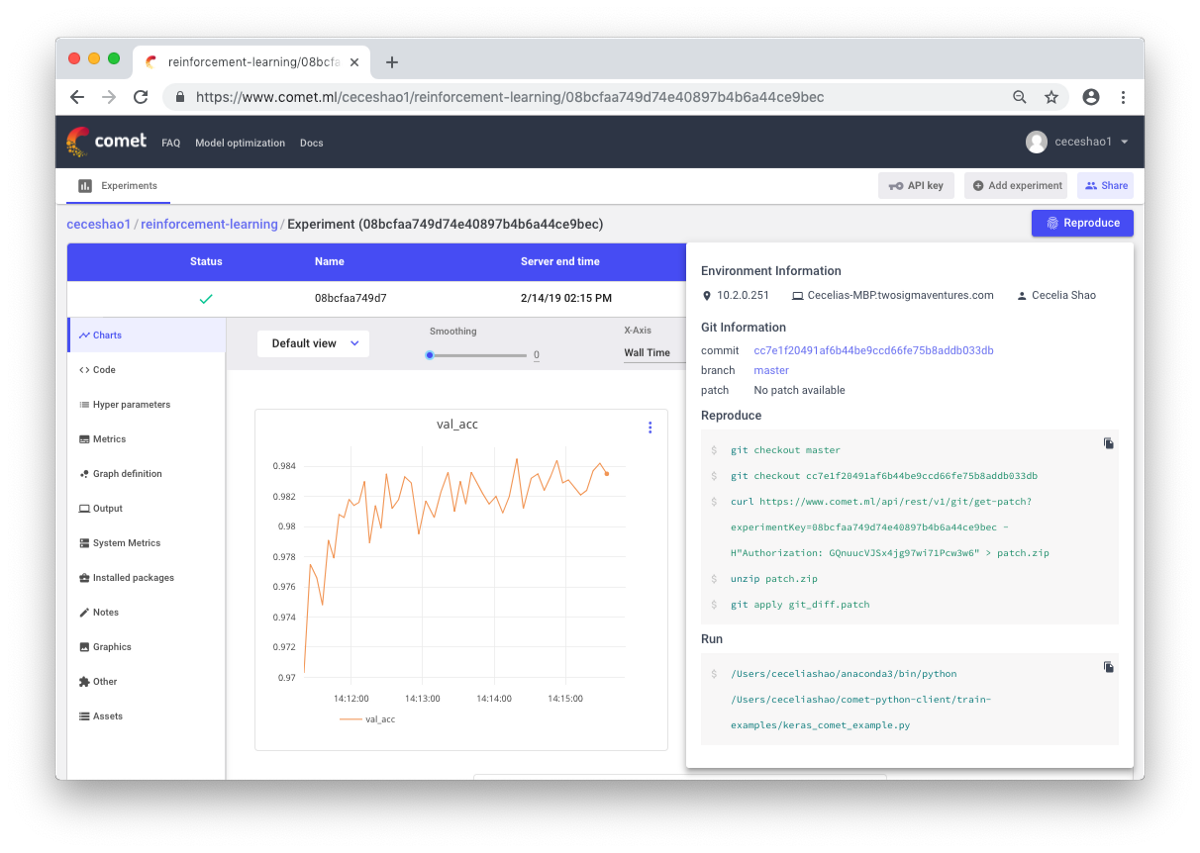
J'espère que ce message pourra devenir le point de départ à partir duquel vous commencerez à déboguer votre réseau neuronal.
Skillbox recommande: