Le processus de réflexion de toute personne est difficile à mathématiser. Toute tâche métier génère un ensemble de documents formels et informels, dont les informations sont reflétées dans le référentiel d'entreprise. Chaque tâche qui génère un processus d'information crée autour d'elle un ensemble de documents et la logique de leur traitement, peu formalisé dans l'environnement de stockage de l'entreprise. Il devrait y avoir des structures à l'intérieur de l'entrepôt de données pour effacer le flux d'informations. Le produit Oracle Enterprise Data Quality, conçu pour résoudre les tâches de nettoyage des données «sales», peut vous aider. Mais cela ne se limite pas à son utilisation.
1. Le concept d'une base de données aléatoire.Les tout premiers liens commerciaux d'une personne sont décrits par des documents formels et informels tels qu'une déclaration, une déclaration, un contrat de travail, une demande de placement, une demande de ressource. Ces documents créent des liens logiques entre les processus métier, mais, en règle générale, sont le produit de la réflexion des chefs de bureau et sont mal formalisés.
La tâche de toute optimisation compliquée au moins n'est pas seulement de comprendre les règles formelles et informelles, mais, souvent, d'apporter des connaissances disparates à une base d'informations commune.
Définition Une base de données aléatoire est un ensemble de faits, documents, notes manuelles, documents formels qui sont traités par une personne pour un processus métier spécifique, mais qui ne peuvent pas être entièrement traités automatiquement en raison de la forte influence du facteur humain.Un exemple. Le secrétaire reçoit officiellement l'appel. L'appelant est intéressé par un produit ou un service. L'appelant n'est pas connu pour CRM. Question: que doit dire l'appelant pour être entendu par un spécialiste?
Pour être plus précis: dans quelle mesure les instructions commerciales du secrétaire permettent-elles un dialogue formel sur l'entreprise si le spécialiste responsable n'est pas prêt pour ce type d'activité?
Il s'avère que nous arrivons à nouveau à la définition d'une base de données aléatoire.
Peut-être qu'il contient plus de faits que le secrétaire ne peut en savoir. Mais les informations reçues ne peuvent pas être superflues. En général, lorsque des faits aléatoires d'une base de données aléatoire arrivent à l'entrée d'un système formalisé, alors une surcharge d'informations se produit - et toute surcharge d'informations peut affecter les performances non seulement du secrétaire, mais de toute l'entreprise.
S'il est utilisé à des fins de traitement, une machine qui lit les états de ces informations arrive, sur la base de conclusions logiques, à l'état opposé à la surcharge d'informations homme. La logique humaine est plus flexible.
2. Application de la définition aux tâches réelles.Imaginez un magasin dans lequel les étiquettes de prix des marchandises aléatoires sont sensiblement élevées ou basses. Lorsque vous quittez ce magasin, dans la tête d'un client inexpérimenté avec une liste de courses sera le prix de 5-7 (ou même 3) des produits les plus populaires, dont le prix peut affecter la taille du chèque total. Il s'avère que s'il était possible de connaître la liste des produits, dont les acheteurs se souviennent le plus souvent, les autres prix pourraient varier dans une fourchette relativement large.
Vous êtes-vous déjà demandé pourquoi, avant le Carême, la viande devient d'abord nettement moins chère, puis elle peut fortement augmenter, puis disparaître? Le prix d'un produit, dont la demande peut tomber à zéro, est d'abord chauffé artificiellement, puis, dépassant un certain niveau de demande, il commence à être fixe, et après un certain temps il augmente avec force, car la cupidité ne permet pas de donner des marchandises illiquides à un prix équitable.
Une situation presque similaire existe sur le marché des données. Les informations les plus utiles sont presque toujours cachées par des hypothèses secondaires sur son applicabilité et son extractibilité.
Il suffit de présenter toute information intéressante pour 5000 à 7000 personnes sur une ressource relativement non protégée, il existe sûrement des sites de copier-coller.
Ou le fameux jeu avec les codes téléphoniques "Qui m'a appelé?". Environ un millier de sites à Runet se composent uniquement des numéros de téléphone de divers opérateurs afin d'être un peu plus élevés dans les résultats de recherche, en essayant de vendre le nom de domaine et de faire de la publicité plus cher.
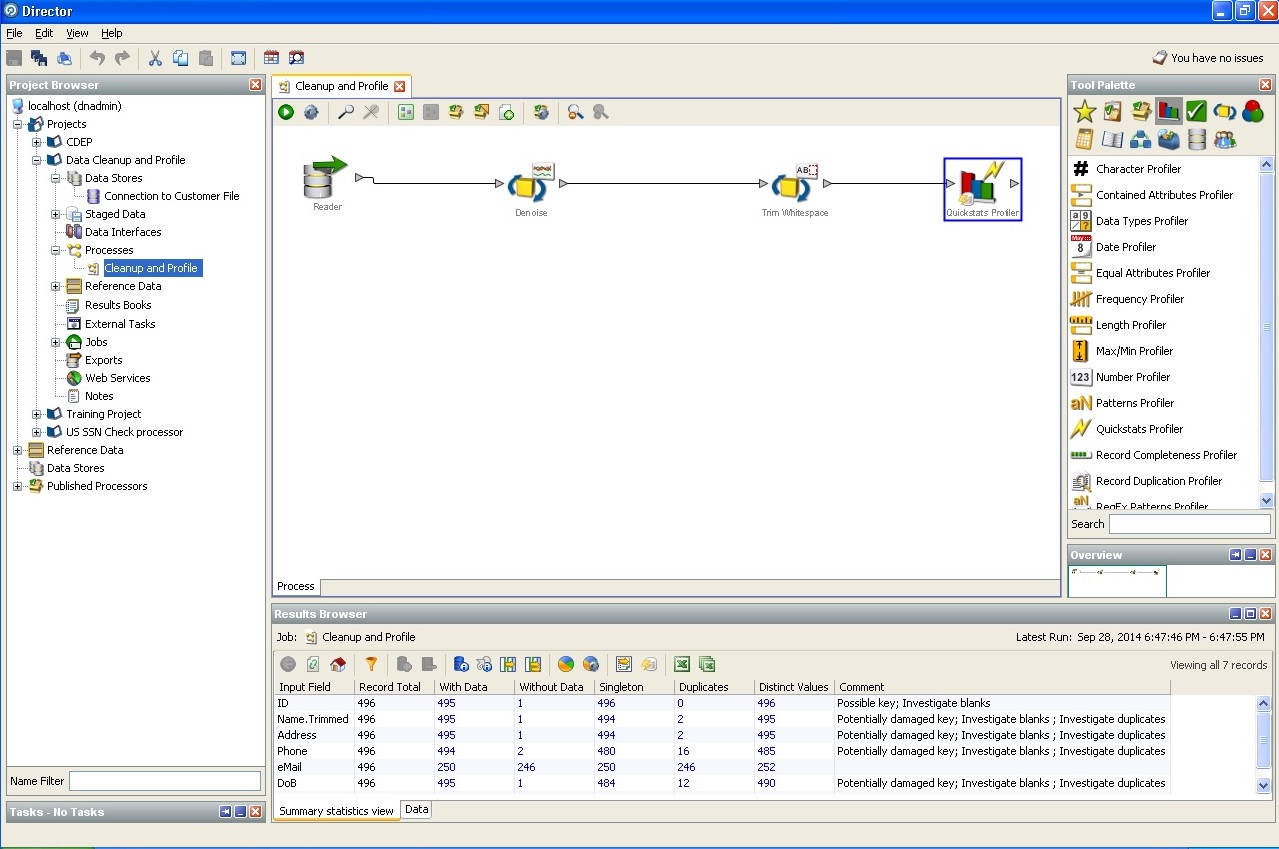
3. Le prix du problème lorsque vous travaillez avec des données "sales".Selon les recherches de l'auteur de l'article, jusqu'à 10% des ressources en main-d'œuvre de chaque projet sont consacrées à l'écriture de certaines procédures de nettoyage des données. Si vous ne vous attardez pas sur un type et une longueur complètement banaux, c'est-à-dire des identifiants uniques, des règles d'intégrité de base de données et des règles d'intégrité commerciale, des échelles d'unités quantitatives et qualitatives, des systèmes d'unités de travail et tout autre état, des influences, des transitions, dont la préparation nécessite comme d'habitude des statistiques analyse commerciale logique et sérieuse. La formalisation des exigences vient de la nécessité de formaliser la relation fait-dimension à la fois pour la création de référentiels et pour la résolution des problèmes sur le front-end.
D'accord, si les processus ETL occupent 70% du temps de travail de tout stockage, économiser 5-7% des ressources sur le nettoyage correct des données sur un stockage conditionnel de 200 000 clients est déjà un bon bonus?
Nous aborderons un peu les problèmes de données "sales" dans des systèmes prêts à l'emploi. Imaginons que vous adressiez une lettre de félicitations à l'occasion de la fête nationale à 10 000 clients par courrier. Combien de personnes jetteront votre lettre avec la meilleure carte postale dans la boîte aux lettres, si vous faites une erreur dans le nom, le prénom ou si vous remplissez le formulaire incorrectement dans le formulaire? Le prix de vos efforts peut réduire à zéro l'humeur de tout utilisateur!
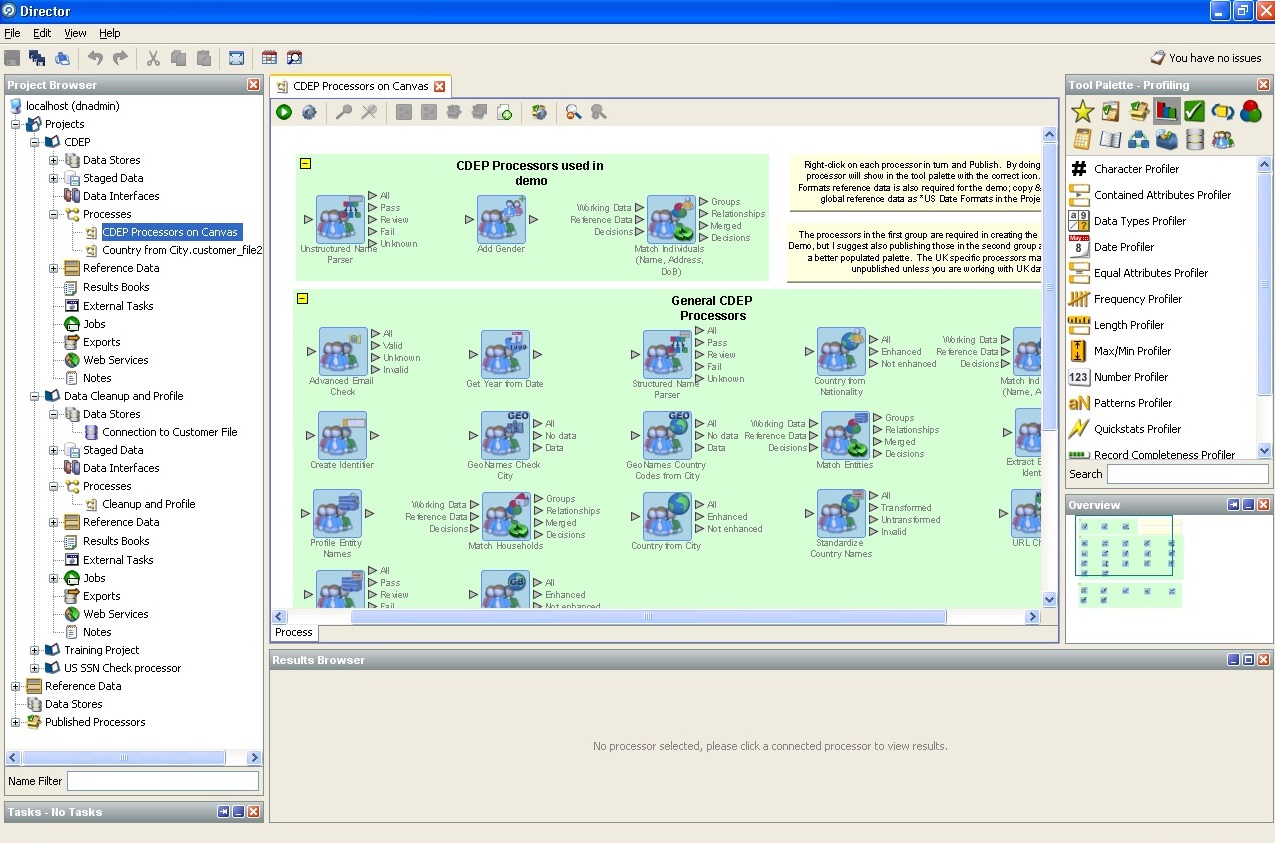
4. Oracle Enterprise Data Quality - bouclier et épée de stockage d'entreprise.Les captures d'écran que nous fournissons décrivent les capacités d'Oracle Enterprise Data Quality.
Alors, laissez quelqu'un renverser de l'eau sur votre base de données ou votre document texte.
Voici une liste de processeurs standard (unités logiques qui vous permettent d'utiliser
aux données de l'une ou l'autre hypothèse, ou rechercher la requise):
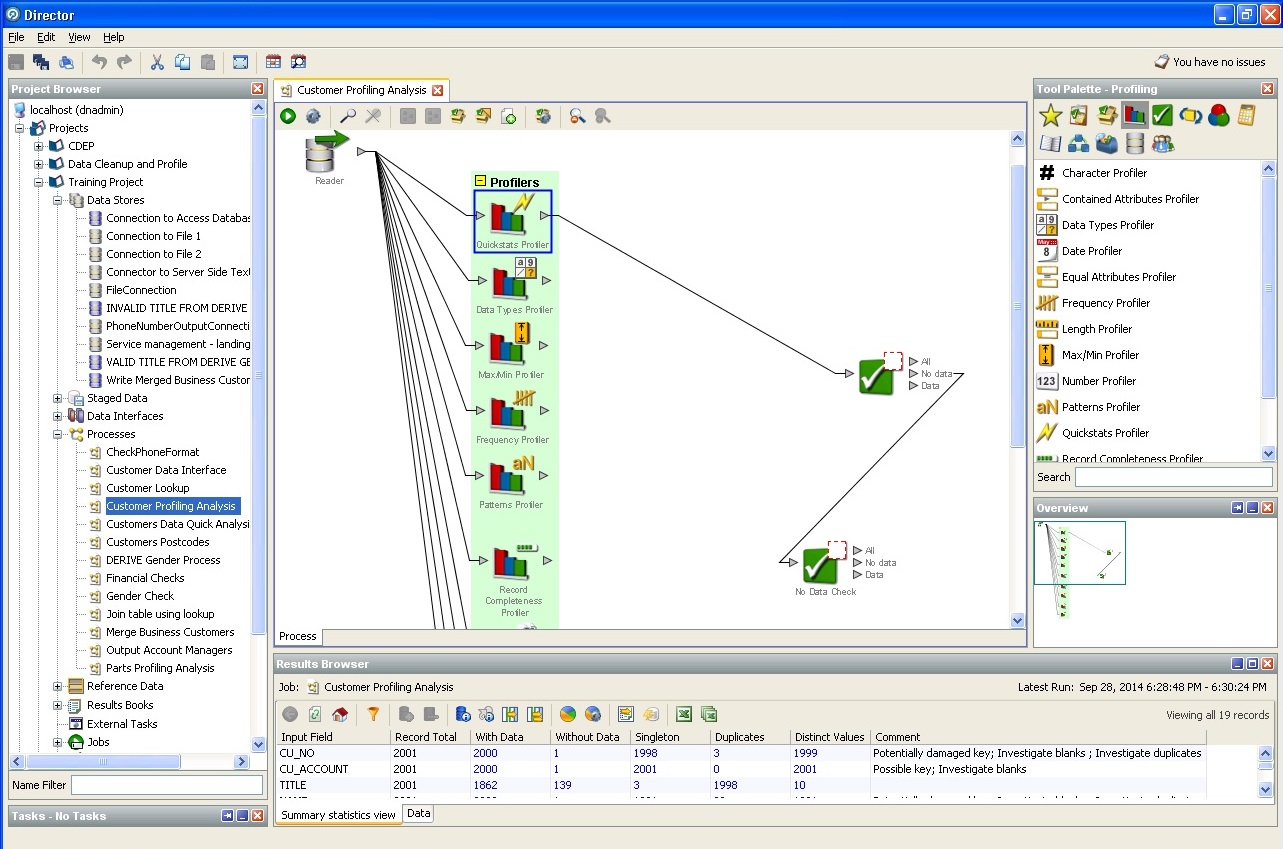
Action de profileur de base de données aléatoire:
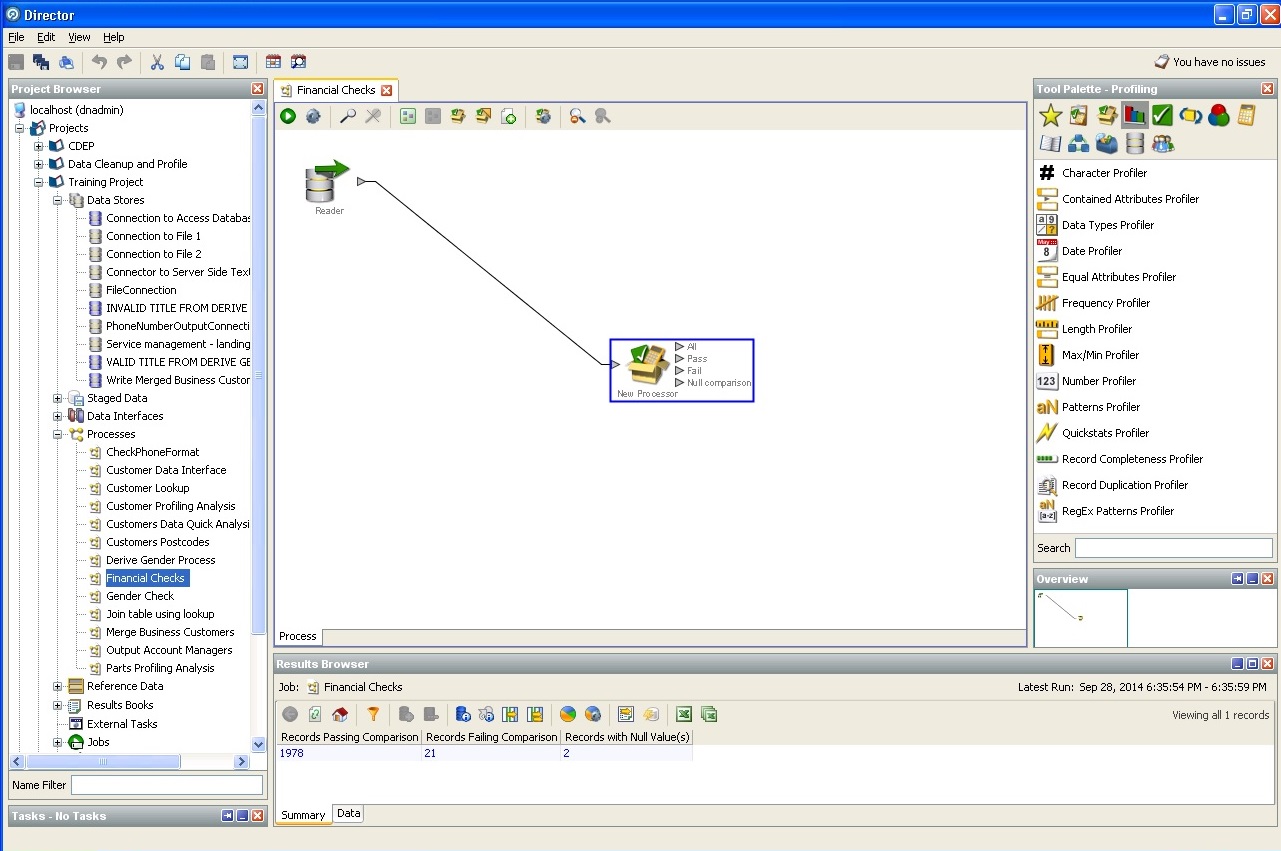
Audit élémentaire de solvabilité financière:
Travailler avec un code postal:
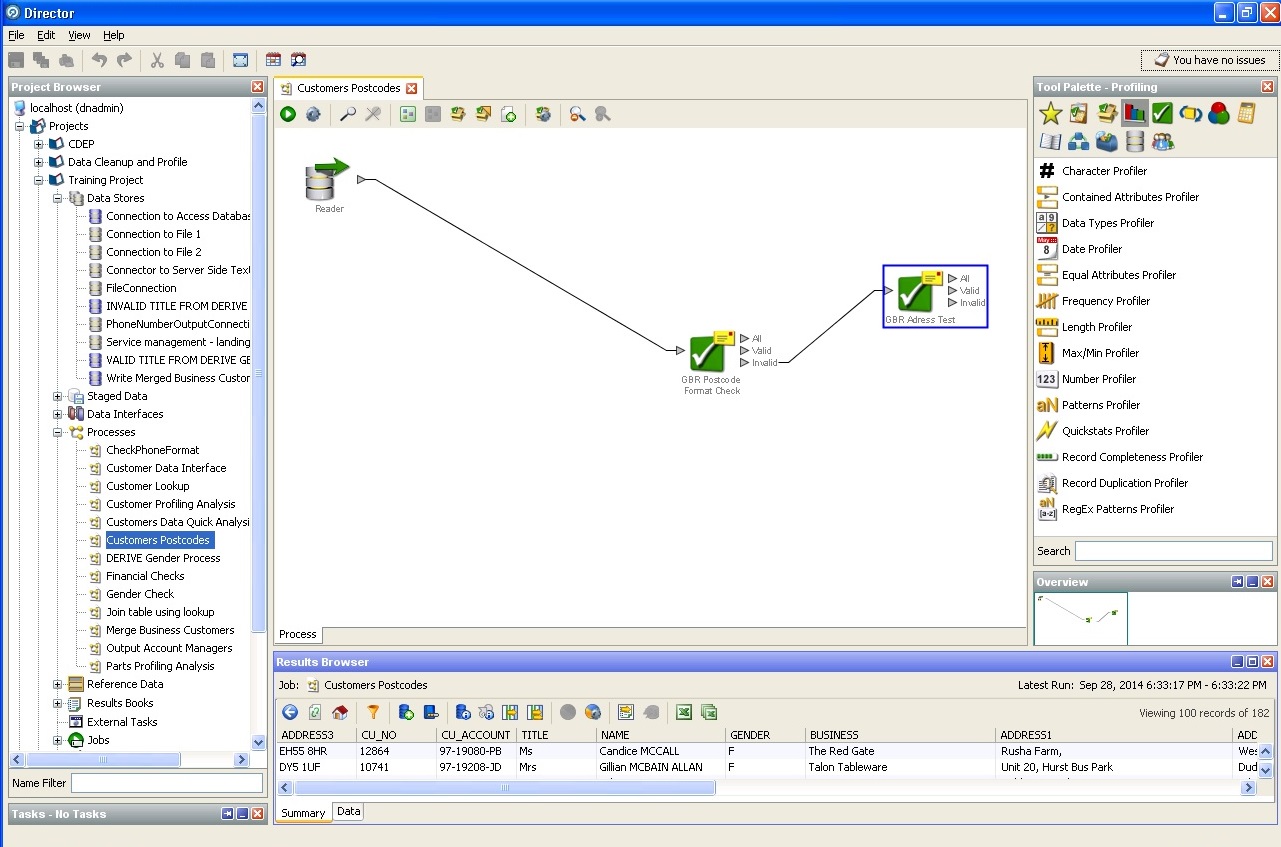
Nettoyage de l'adresse postale:
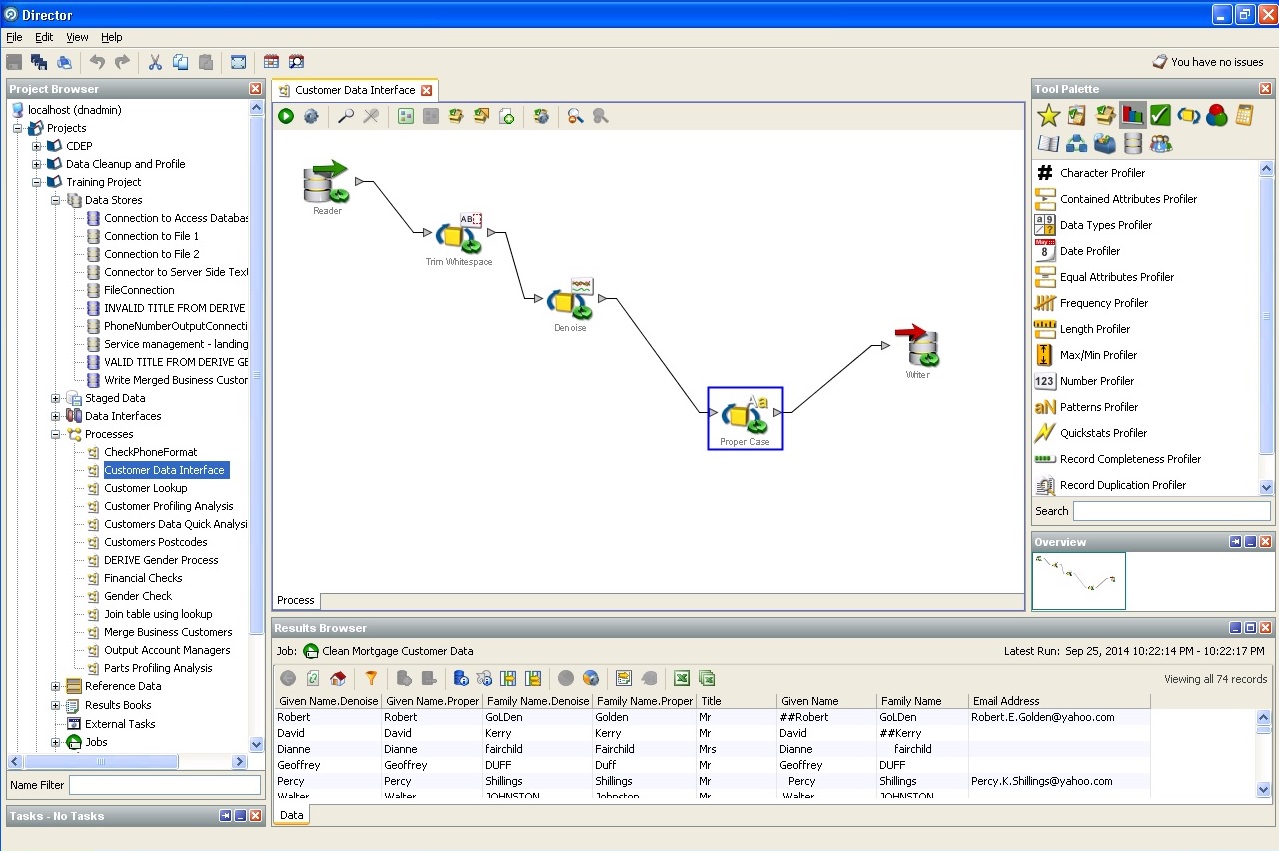
Effacement des données utilisateur:
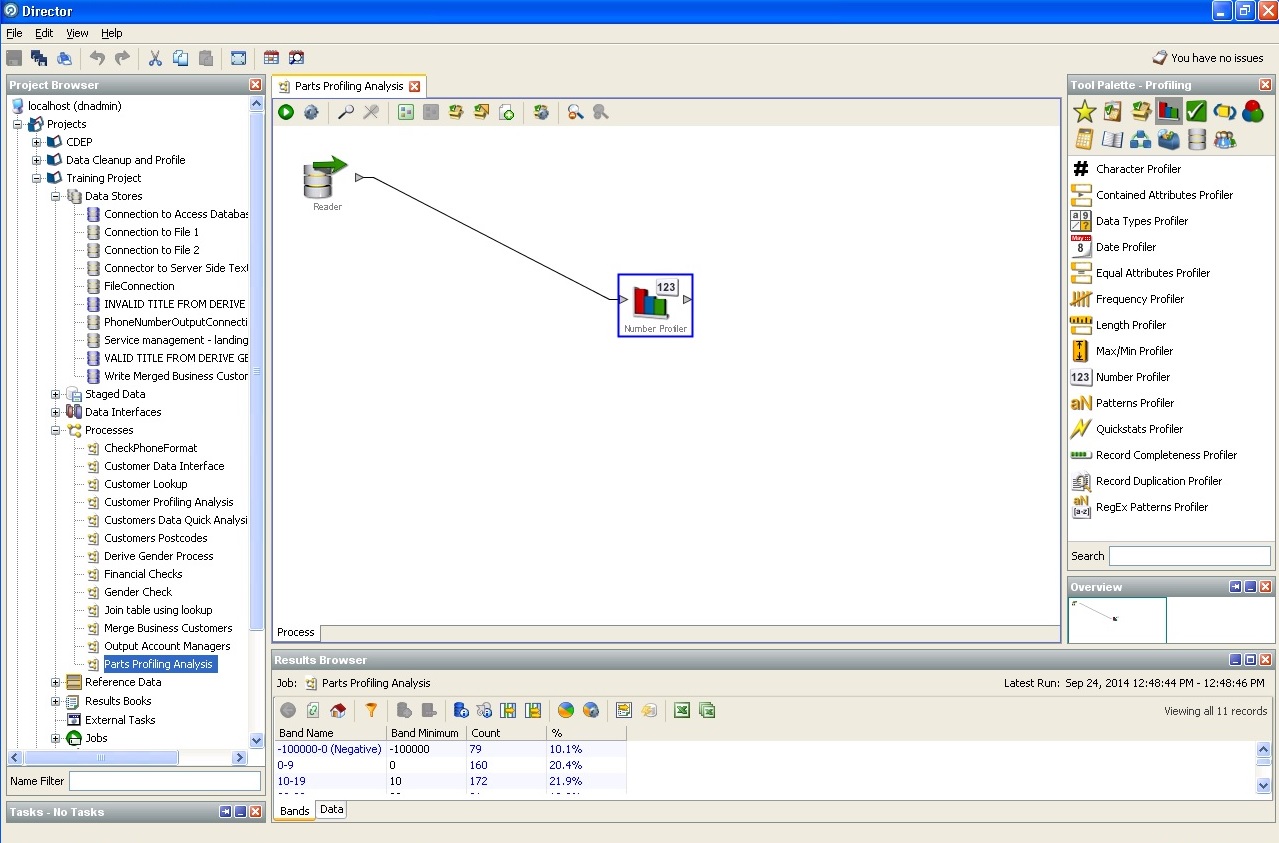
Affectation d'un enregistrement à l'un ou l'autre intervalle de confiance:
Déterminer le sexe de l'utilisateur à partir de données indirectes:
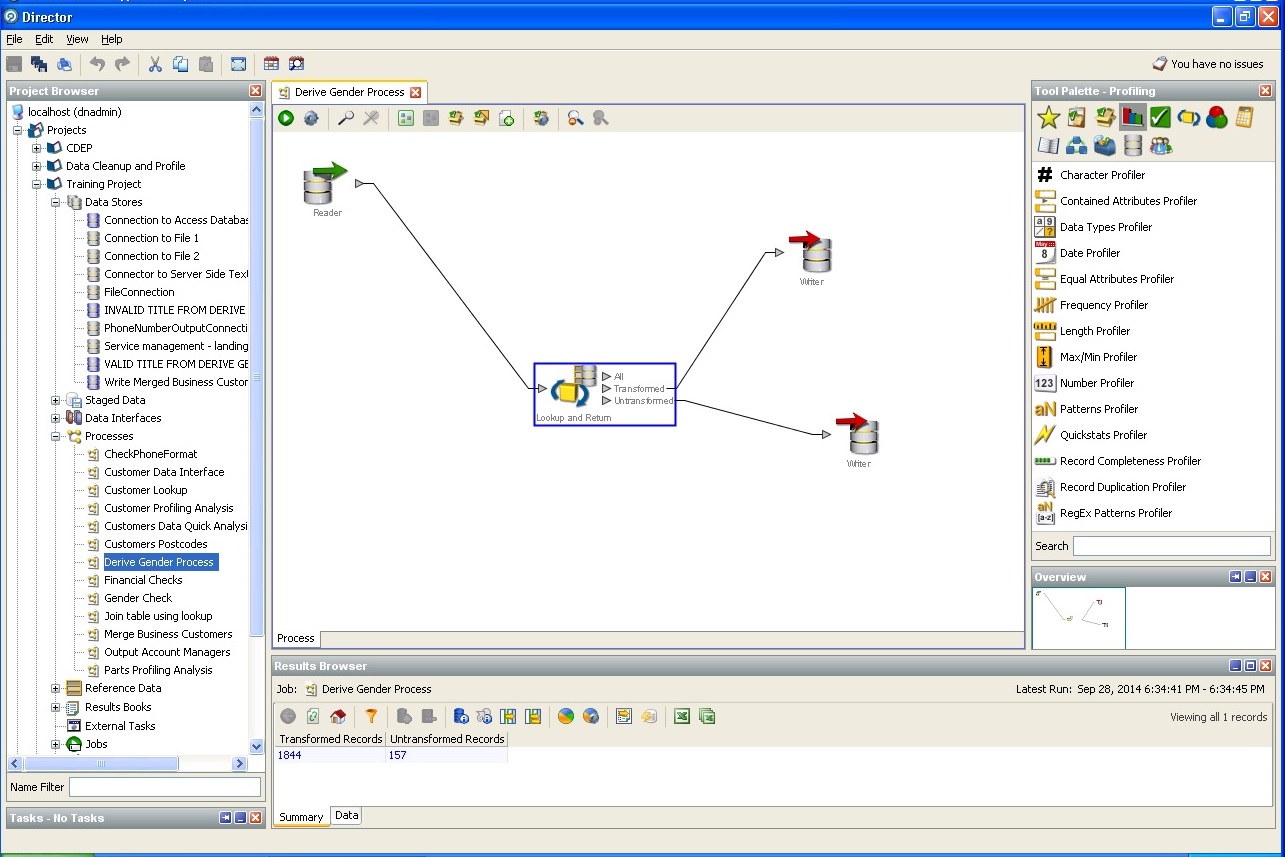
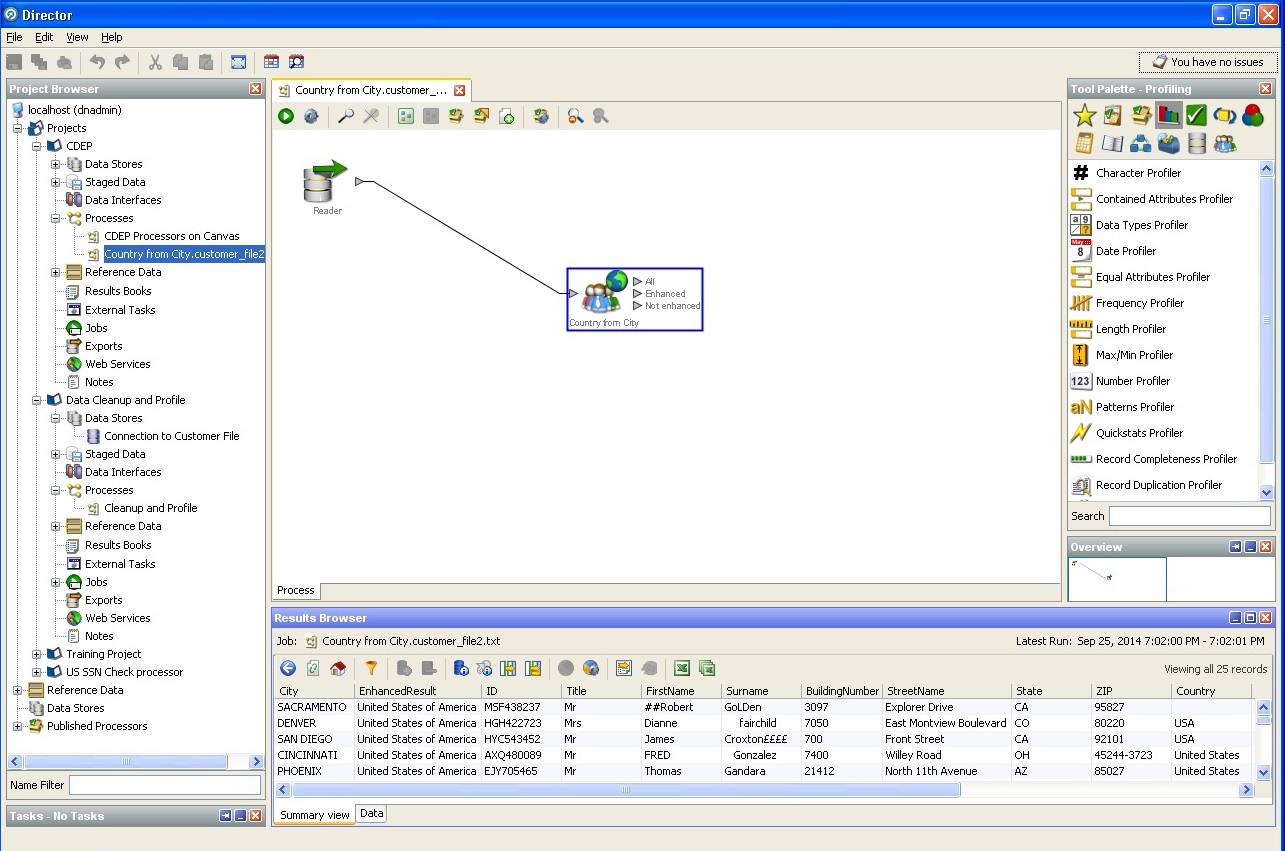
Définition d'une ville et d'un pays, état:
La recherche de clé la plus simple dans une base de données aléatoire:
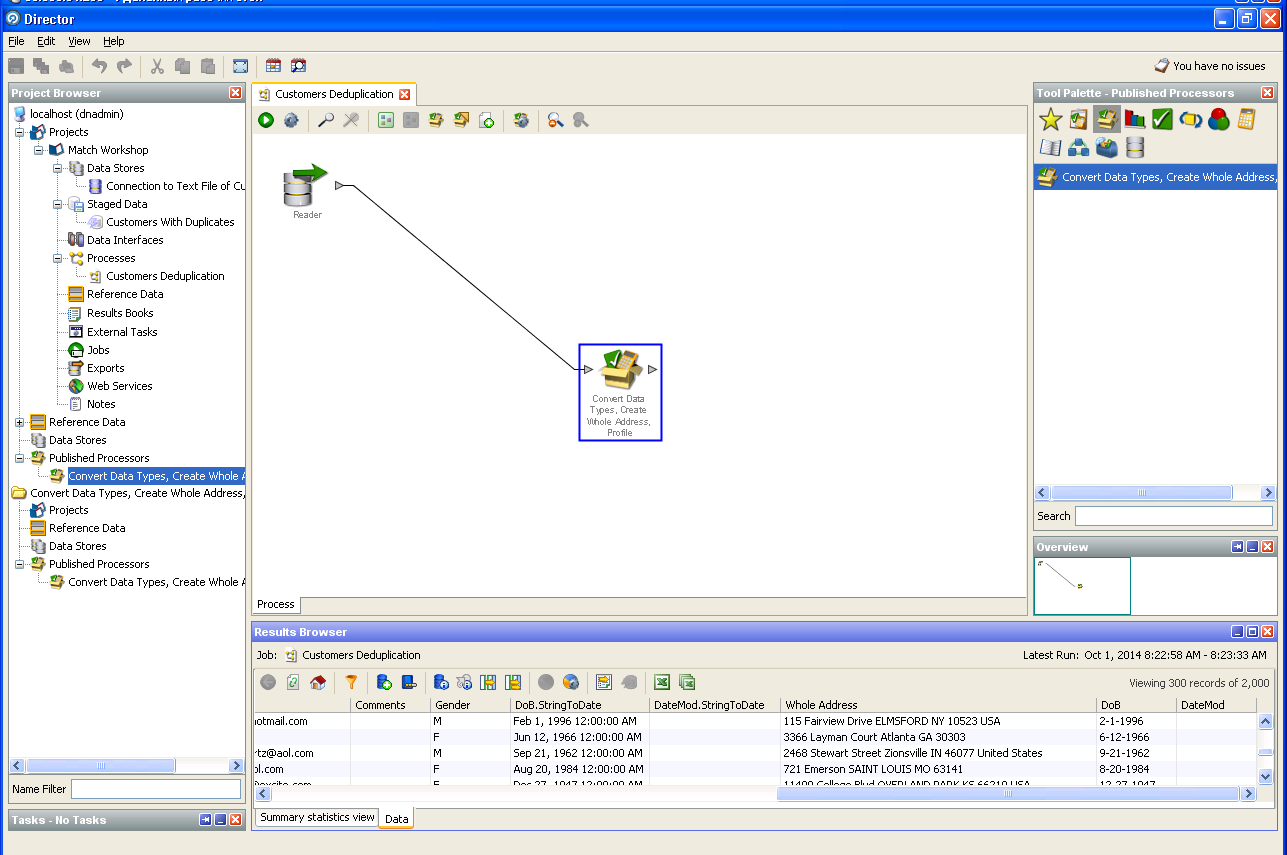
Déduplication des données utilisateur:
 5. Observations drôles faites sur les résultats des travaux sur Oracle EDQ.
5. Observations drôles faites sur les résultats des travaux sur Oracle EDQ.L'un des principes de la comparaison des contributions des écrivains et des poètes à la littérature est de comparer leurs dictionnaires poétiques et littéraires. Nous donnons un certain nombre de dictionnaires compilés en temps libre pour des tests de solutions prêtes à l'emploi sur Oracle EDQ, Python, Java. Nous serons reconnaissants aux philologues dans les commentaires de publier leurs résultats.
Nombre p.p.
| Le mot
| Fréquence d'occurrence
|
Lion
Tolstoï, guerre et paix. Fragment du tableau des fréquences
dictionnaire du droit d'auteur.
| I.
Brodsky, Urania.
| I.
Brodsky Complete works, un fragment du dictionnaire des fréquences
l'auteur.
| N.
Nekrasov, un fragment du dictionnaire des fréquences pour la collection complète
essais.
|
1.
| et
| 10351
| dans
1037
| dans
5745
| et
3420
|
3.
| dans
| 5185
| et
647
| et
4500
| dans
2108
|
4.
| pas
| 4292
| pas
391
| pas
3022
| pas
1726
|
5.
| quoi
| 3845
| sur
341
| sur
2239
| je
1040
|
6.
| il est
| 3730
| comment
329
| comment
1758
| avec
883
|
7.
| sur
| 3305
| avec
237
| avec
1674
| sur
854
|
8.
| avec
| 3030
| quoi
168
| quoi
1531
| comment
763
|
9.
| comment
| 2097
| à
148
| Et
1200
| quoi
693
|
10.
| je
| 1896
| de
147
| je
1040
| il est
644
|
11.
| son
| 1882
| de
104
| à
922
| toi
475
|
12.
| à
| 1771
| je
90
| de
810
| mais
472
|
13.
| alors
| 1600
| où
88
| tout
748
| mais
449
|
14.
| elle est
| 1564
| que
88
| par
744
| donc
383
|
15.
| mais
| 1234
| pour
76
| toi
721
| à
367
|
16.
| c'est
| 1208
| par
74
| Dans
713
| tout
344
|
17.
| dit
| 1135
| Mais
72
| pour
687
| pour
313
|
18.
| était
| 1125
| ni
70
| de
635
| pour moi
309
|
19.
| donc
| 1032
| serait
69
| mais
617
| oui
294
|
20.
| le prince
| 1012
| alors
67
| il est
592
| son
275
|
21.
| pour
| 985
| toi
67
| Mais
584
| alors
232
|
22.
| mais
| 962
| à propos
66
| alors
540
| était
229
|
23.
| à lui
| 918
| mais
63
| à propos
538
| par
224
|
24.
| tout
| 908
| est là
61
| c'est
524
| non
223
|
25.
| par
| 895
| Je suis
61
| Je suis
489
| ni
222
|
26.
| elle
| 885
|
| mais
463
| à propos
213
|
27.
| de
| 845
|
| où
449
| leur
212
|
28.
|
|
|
| que
443
| de
209
|
29.
|
|
|
| Un
428
| de
207
|
30.
|
|
|
| pareil
422
| nous sommes
206
|
Conclusion: les statistiques de la langue russe au cours des cent dernières années en termes de fréquence des mots individuels n'ont pas beaucoup changé, parmi les poètes - les mots sont plus «mélodieux». Soit dit en passant, les statistiques de Daria Dontsova coïncident à bien des égards avec Leo Tolstoy dans le domaine du dictionnaire de fréquence des œuvres complètes.
6. Plusieurs calculs formels en guise de conclusion.Environ 60 000 Ivanov Ivanov Ivanovich vivent dans notre pays. En supposant que quelque part, hypothétiquement, 100 tables sont stockées dans la base de données moyenne, 10 champs clés dans chaque table et que chaque clé peut prendre 60000 valeurs, nous obtenons que le nombre total d'états de clés uniques à l'intérieur de la base de données est d'environ 60 millions. Même si deux clés sont mélangées dans une même table, elles peuvent générer jusqu'à 20 états uniques dans une même table. Au total, jusqu'à plusieurs milliers peuvent se retrouver dans la base d'états uniques. Êtes-vous d'accord que dépenser 10% du temps de développement et 5-7% du temps d'exécution ETL pour attraper de telles bagatelles est un luxe inadmissible?
UPD1 Si vous en avez assez de faire glisser le système de contrôle pour chaque répertoire plus ou moins important de votre travail, alors les systèmes MDM (Master Data Management) viendront à votre aide. Bien sûr, nous livrons de tels systèmes sur le marché, y compris une version sur logiciel libre.
UPD2 Très souvent lors des conférences, la question est posée: «Comment créer un système de gestion de la qualité des données moins cher». Je vous demande de considérer cet article comme une petite introduction à ce problème, avec une simplification de la fonctionnalité EDQ. Oui, et pourtant, vous pouvez prendre un tas d'ODI + EDQ et faire très bien, mais c'est le sujet d'une nouvelle narration.