Bonjour à tous! Je m'appelle Denis Girko, je suis l'architecte système de la plateforme e-commerce de Lamoda. L'année dernière, j'ai pris la parole à la conférence DevConf avec un rapport que je veux partager avec vous.
Il s'agit d'un rapport d'examen sur les difficultés rencontrées par une grande boutique en ligne dans le processus de livraison des commandes et sur les solutions techniques qui peuvent aider à les surmonter (en utilisant les solutions que nous avons testées chez Lamoda à titre d'exemple).

De quoi s'agit-il? Je vais vous dire:
- À propos du processus de livraison et identifier les problèmes;
- comment stocker efficacement les territoires de livraison dans la base de données;
- comment améliorer la qualité des données que nous recevons du client;
- comment rechercher le destinataire dans la base de données d'adresses pour trouver des résultats plus précis.
Schéma général de livraison des commandes Lamoda
Lamoda est une boutique en ligne avec quatre pays de livraison: Russie, Ukraine, Kazakhstan, Biélorussie. Nous livrons les marchandises dès le lendemain du fait que nous avons notre propre service de livraison et une dizaine de partenaires tiers dont nous utilisons les services. La livraison est une grande partie de notre activité.
Lamoda accepte la commande, demande l'adresse du client au moment de l'inscription et la transmet au service de messagerie.
Et si nous n'avons pas un service de messagerie, mais plusieurs? Ensuite, l'étape suivante est ajoutée - pour déterminer quel service de livraison nous prendrons la commande.
Il peut y avoir des critères de sélection d'entreprises. Mais la première chose à penser est de savoir si ce service de messagerie a la livraison à la ville choisie par le client ou non. Par conséquent, la première étape de l'intégration d'une entreprise de messagerie dans notre système consiste à découvrir sa zone de couverture.
Ensuite, vous devez apprendre à vérifier si l'adresse du client appartient ou non à ce territoire.
Le schéma général sera amélioré et ressemblera à ceci:
- demander une adresse;
- savoir quels services de messagerie peuvent le livrer;
- sélectionnez celui que vous voulez parmi ceux disponibles.
Maintenant, un peu plus sur ces étapes.
Nous demandons l'adresse au client
Comment puis-je lui demander?
- Demandez de remplir un grand champ. Le client martèle son adresse, qui n'a en outre pas besoin de manipulations délicates. L'adresse peut être imprimée sur un morceau de papier, remis au courrier à pied, qui le découvrira lui-même.
- La deuxième option est plus compliquée. Nous demandons au client de remplir chaque composante de l'adresse dans son champ. Ici, vous pouvez déjà faire quelque chose. Par exemple, comparez la ville de Moscou avec une liste donnée de villes. Mais cela fonctionnera mal, car la ville de Moscou peut s'écrire de plusieurs manières: «g. Moscou »,« ville de Moscou »,« ville de Moscou »sans espace, etc.
- Par conséquent, il existe une option encore plus avancée. Comme la liste des villes que nous avons est limitée, vous pouvez pré-compiler une liste de villes et suggérer au client de sélectionner celle dont il a besoin. Le bonus est qu'à chaque élément d'une telle liste, nous pouvons déjà associer un identifiant ici. Nous, les développeurs, aimons travailler non pas avec des chaînes, mais avec des identifiants qui peuvent être utilisés dans tous nos systèmes comme l'équivalent de la ville sélectionnée. J'ai un index du bureau de poste central sur la diapositive comme identifiant.

Quel service de livraison transportons-nous?
Puisque nous avons un identifiant (index), alors laissez le territoire stocké dans notre base de données être représenté par une liste d'index. Dans ce cas, l'algorithme de vérification de l'entrée de la ville sur le territoire est très simple. Alors faisons-le: nous placerons les territoires de livraison reçus des services de messagerie dans la base de données sous forme d'indices.
Les indices ont leurs avantages et leurs inconvénients. Je dirai à l'avance que Lamoda a fait exactement cela au début: le résultat du choix d'un client de la ville était un index, et nos index étaient stockés dans la base de données. Pourquoi un plus? Comme je l'ai dit, un indice est une chose que tout le monde comprend. Tout gestionnaire qui vient de travailler sait ce qu'est un index. Il peut recevoir de la société de messagerie de la ville, les convertir en quelque sorte en index et les utiliser. L'inconvénient est que l'indice est l'identifiant de la poste de la poste russe. Et les colonies voisines peuvent partager le même indice.
Pourquoi les index manquent-ils?
Un exemple simple: Lyubertsy. A proximité se trouve le village de Marusino. Marusino n'a pas de bureau de poste; leur correspondance est envoyée à l'un des bureaux de poste de Lyubertsy. Si nous voulions ajouter la livraison à Lyubertsy, mais pas à Marusino, car cela pourrait ne pas être financièrement rentable pour nous, nous ne pourrions le faire que par index.
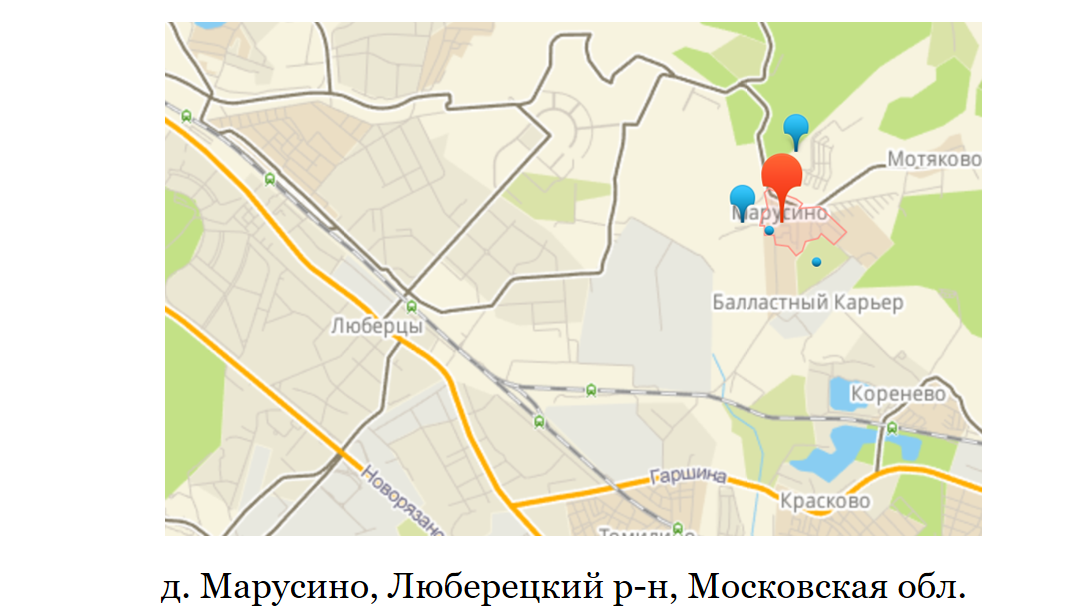
Un autre exemple est lorsque Lamoda s'est agrandi et a ouvert un deuxième entrepôt de transit à Moscou. Il fallait diviser Moscou en deux moitiés nord et sud. Et déjà au moment de passer la commande, sachez à partir de quel entrepôt de transit la livraison sera effectuée. Dans ce cas, un indice par ville ne serait pas suffisant.
Nous avons décidé d'utiliser des géo-coordonnées avec des index. Nous prenons l'adresse du client, l' exécutons via le géocodeur Yandex . En sortie, on obtient non seulement l'index, mais aussi les coordonnées. Nous utilisons des index dans les cas où le détail n'est pas important. Et les coordonnées spécifient les cas où vous devez faire une fine division du territoire.
Ils ont fourni une interface dans leur programme d'installation pour les logisticiens, qui vous permet de dessiner un polygone au-dessus de la carte. C'est simple: le point tombe dans la décharge - il y a livraison, ne tombe pas - non.
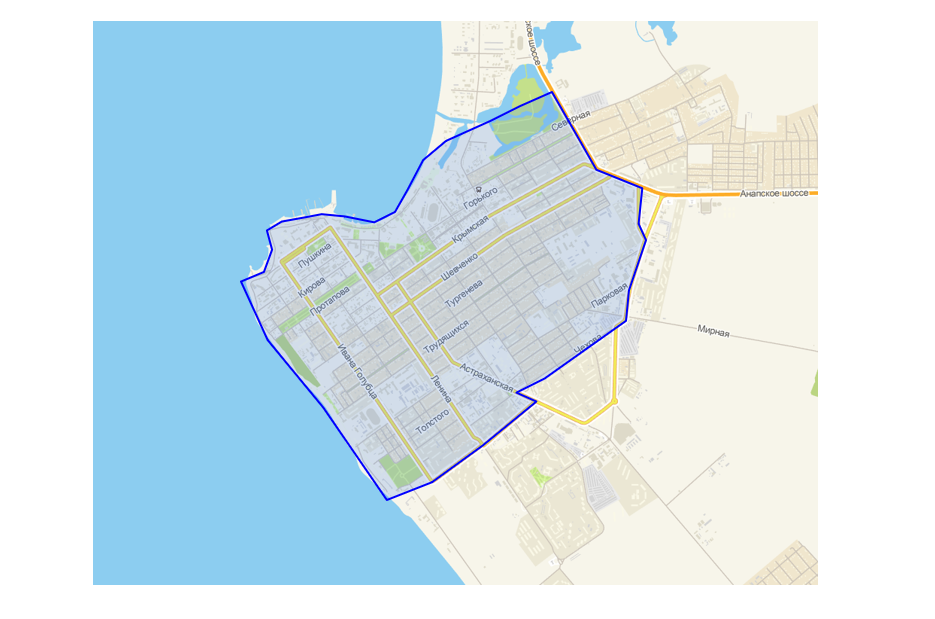
Interface de création de zone de polygone
Le bonus que nous avons des coordonnées géographiques pour chaque commande a été l'occasion d'améliorer l'interface que les logisticiens utilisent pour créer des itinéraires pour les commerciaux. L'interface affiche une carte sur laquelle les commandes des clients sont marquées. Le logisticien utilise l'outil lasso, qui combine les ordres adjacents en un seul itinéraire. De plus, cette route va à un représentant des ventes, c'est-à-dire qu'une personne n'a pas besoin d'aller d'un bout à l'autre de la ville pendant la journée pour prendre toutes ses commandes - elles sont toutes géographiquement proches.
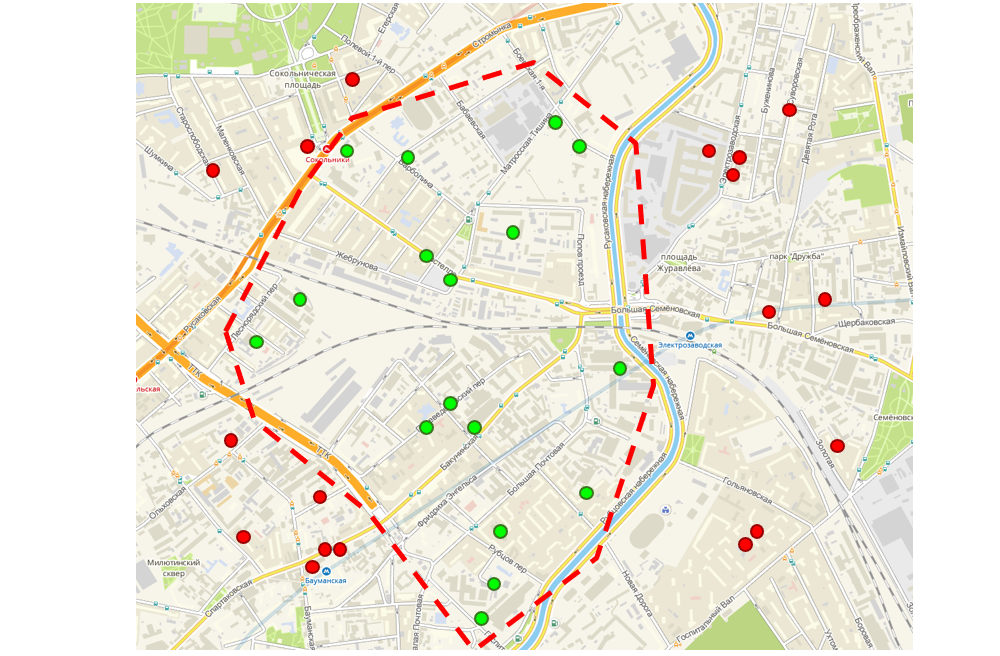
Interface de routage
L'adresse saisie par le client est convertie en coordonnées. La probabilité d'obtenir directement les coordonnées d'une adresse donnée dépend de la qualité de l'adresse saisie par le client. Par conséquent, la première chose à laquelle nous avons pensé est de savoir comment augmenter le nombre d'adresses bien reconnues. Par conséquent, vous devez aider le client à saisir la bonne adresse.
Le fait est que les clients ne suivent souvent pas les scénarios que nous leur proposons, nous avons donc acquis des bases de données d'adresses pour chacun des 4 pays dans lesquels nous livrons des commandes. Et ils ont fait un sajest non seulement pour la ville, mais aussi pour la rue, et même pour le numéro de la maison. Pour faire une liste de maisons, nous avons analysé les données ouvertes de openstreetmap.org .
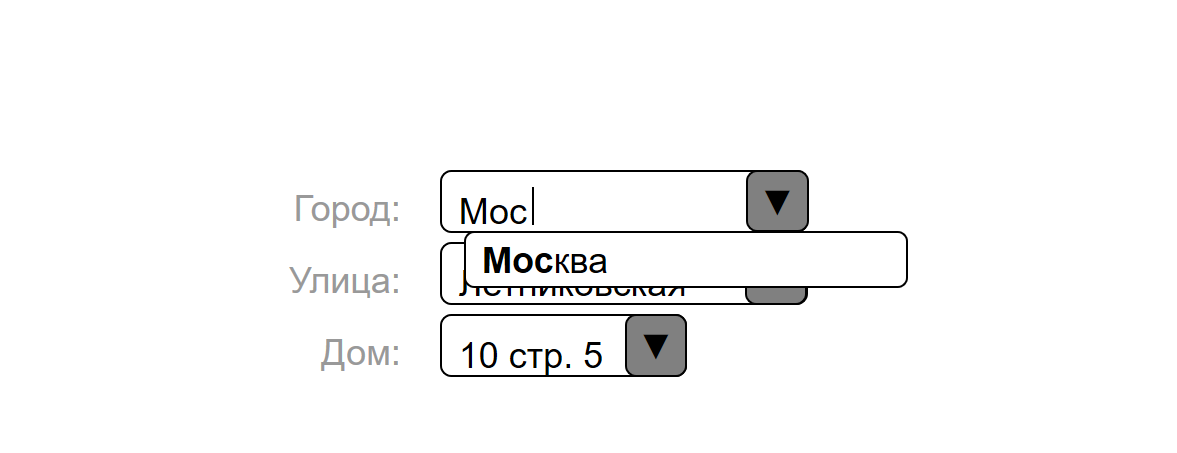
Le formulaire de paiement propose des conseils pour formaliser les données d'adresse
Base d'adresses
Pour faire une demande à la base d'adresses, vous devez la garder à la maison. Où avons-nous obtenu toutes les bases d'adresses pour nos quatre pays? En Russie, c'est FIAS , la base d'adresses qui est compilée et maintenue par notre service fiscal. Il est assez complet, mais pas sans défauts. Nos partenaires de livraison nous ont aidés avec d'autres pays.

Nous avons également un ensemble de scripts PHP qui prennent le format avec lequel la base d'adresses nous parvient, et de la même manière qu'il l'ajoute à PostgreSQL . Pourquoi sous la même forme? Parce que l'une des tâches consiste à mettre à jour périodiquement ces bases de données à partir des mêmes sources. Cela signifie que si nous prévoyions une conversion, elle devrait être répétée à chaque mise à jour. Ainsi, les données vont à PostgreSQL, et à partir de là elles sont converties et stockées dans Apache Solr ; Solr vous permet de les rechercher rapidement et de faire des sajest. Un petit serveur web PHP est capable de construire des requêtes dans Solr, en fonction de leurs résultats, une liste est créée pour le client sur le site pour une suggestion.
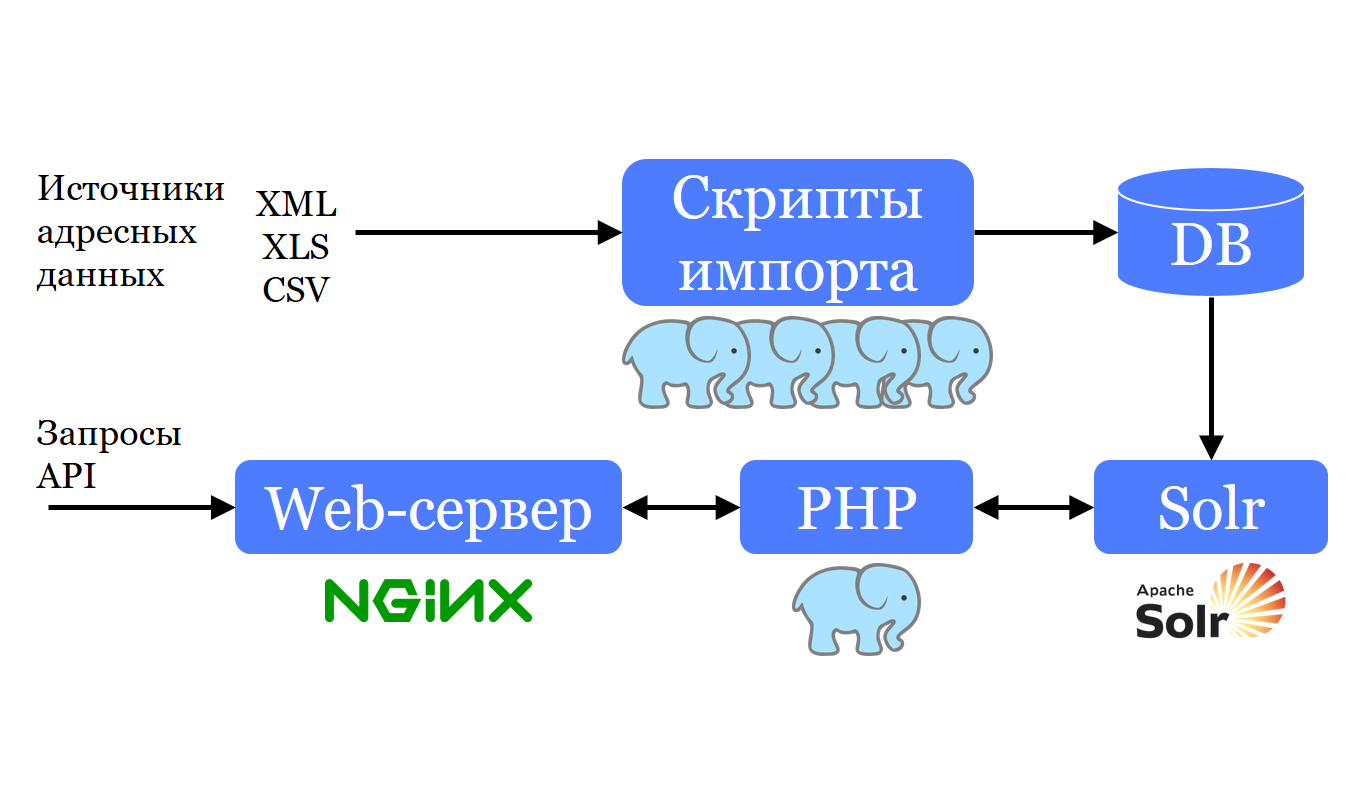
Nous téléchargeons les données de la source sous la même forme que celle dans laquelle elles nous sont parvenues. Autrement dit, avec le même ensemble de champs, avec les mêmes types de colonnes, etc. Ajoutez-les tels quels. Nous avons essayé d'utiliser les données sous cette forme dès le début, et afin de les transformer en ces structures avec lesquelles nous pouvons travailler, nous avons écrit plusieurs vues. Puisque nous avons 4 pays, tout cela a été multiplié par 4, et il a été très difficile et coûteux à supporter. Il fallait donc faire quelque chose.
La première chose dont nous nous sommes débarrassés est une structure non structurée, ou plutôt une structure spécifique , à un stade précoce. Autrement dit, dès que les données brutes ont été téléchargées, à l'aide de vues, nous les transformons en un format unifié, avec lequel toutes nos autres transformations sont davantage configurées. Cela nous a évité de multiplier par 4. Et c'est à ce moment que nous oublions la structure dans laquelle les données nous sont parvenues, et nous ne travaillons qu'avec ce que nous avons inventé pour nous-mêmes.
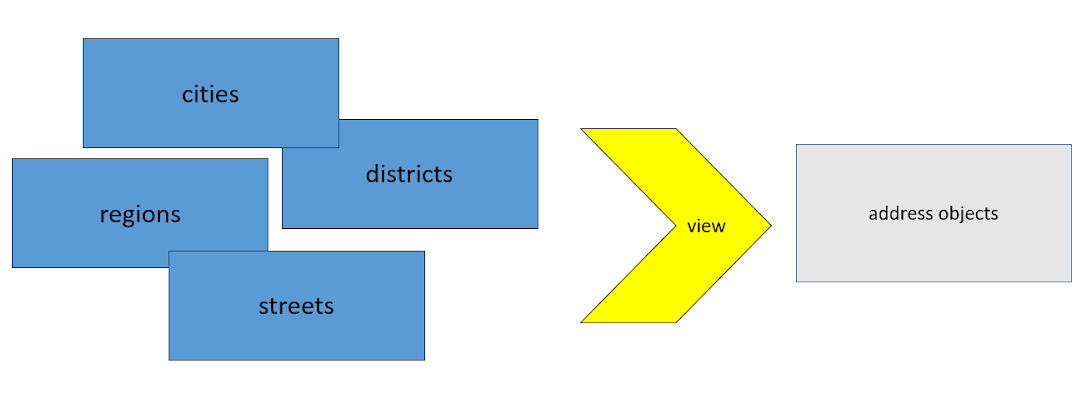
Si vous avez besoin de deux sources - veuillez télécharger. L'essentiel est que le format de cette sortie de données après la conversion en vues soit le même.
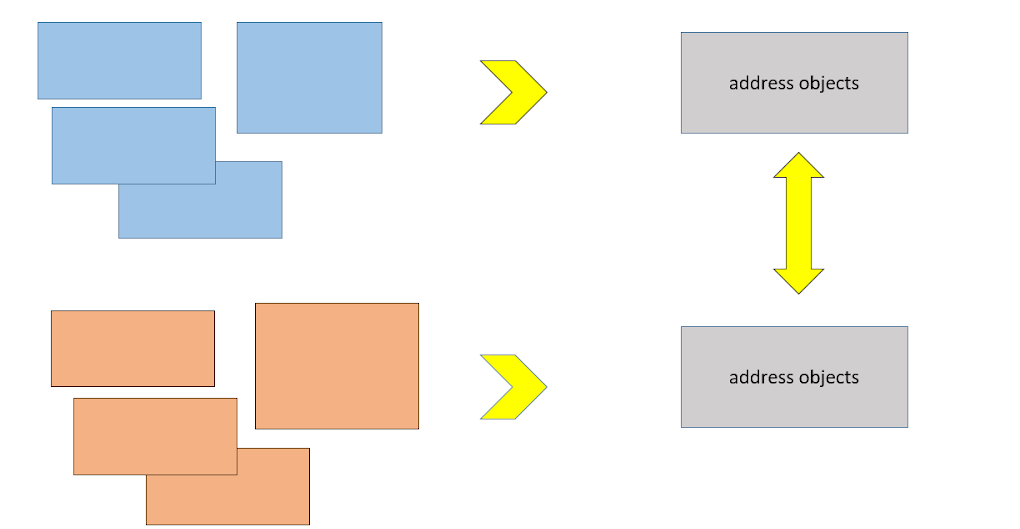
Une autre exigence pour les bases de données d'adresses chargées était qu'il était nécessaire d'y apporter des corrections ponctuelles. Un exemple simple: dans la FIAS, la République tchouvache s'appelle «Tchouvachie Rep. "Tchouvachie." Eh bien, nous voulons juste la République Tchouvache. Pourquoi avons-nous besoin de ce tiret? Et en même temps, nous ne pouvons toujours pas éviter les mises à jour périodiques des sources.
Voici les couches suivantes que nous avons dans PostgreSQL.

Les tableaux de gauche sont des données brutes téléchargées depuis la source.
Derrière eux se trouvent des vues qui convertissent les données dans un format standard.
Redéfinitions locales - nous avons un ensemble de tables qui redéfinissent ponctuellement certains attributs des données d'adresse chargées. Nous avons inclus ici, par exemple, qu'un enregistrement avec un tel identifiant devrait recevoir à la place de «Chuvash rep. - Tchouvachie »est notre nom choisi.
La table de mappage est notre référentiel d'identifiants, que nous avons nous-mêmes attribués aux objets d'adresse que nous avons téléchargés - cela a permis à nos systèmes d'être extraits de la source, des identifiants utilisés dans la source, et de ne cacher aucune source, mais même plusieurs derrière un ID. Je le dirai un peu plus tard. Tout cela est combiné et fixé dans une vue matérialisée. Ainsi, nous obtenons presque l'équivalent de la table finale, qui peut être mise à jour en exécutant une vue SQL REFRESH MATERIALIZED VIEW .
Objets d'adresse - base d'adresses formée avec toutes les corrections et ajouts.
Ainsi, en sortie, nous avons déjà corrigé des objets d'adresse, déjà avec de nouveaux noms et nos identifiants. Tout cela est transformé et dénormalisé, comme pratique pour la recherche, et additionné dans Solr.
Puisque nous avons maintenant des bases de données d'adresses, il serait intéressant de les utiliser non seulement pour faire une demande de bon de commande, mais aussi pour effectuer une recherche. Où une recherche peut-elle être utile? Il s'avère beaucoup où. Les mêmes zones de livraison que nous recevons des services de messagerie sont très souvent représentées simplement par une liste de villes. Et la liste des villes est confrontée aux mêmes problèmes que pour la saisie des utilisateurs: les villes peuvent avoir des interprétations différentes, des noms différents, etc.
J'ai une diapositive spéciale ici, une telle histoire d'horreur - que ferions-nous si nous prenions tout manuellement pour le convertir en PHP: en Tchétchénie, en République tchétchène, et donc pour chaque source de données - l'enfer est l'enfer.

Ajout: sur l'écran - un morceau de code réel du service, qui est devenu inutile uniquement en raison des solutions décrites.
Nous avons classé ces problèmes.
1) Noms équivalents des mêmes objets. Par exemple, des synonymes communs comme Tchouvachie et la République tchouvache.
2) Villes renommées. L'Ukraine est maintenant dans une phase active pour se débarrasser du passé communiste, c'est pourquoi ils modifient littéralement chaque jour le nom de leurs colonies. Pour cette raison, il peut s'avérer que dans une base de données nous avons d'anciens noms et dans une autre - de nouveaux.
3) Beaucoup d'erreurs. Souvent trompé sur le statut des colonies. Il y a un village, voici un village ou ici est un village, il y a une ferme.
4) Mots étrangers translittérés en russe, souvent le même nom est translittéré de différentes manières.
5) Il y a beaucoup d'erreurs dans la hiérarchie: Zelenograd, par habitude, appartient à la région de Moscou, bien que formellement il soit également répertorié à Moscou comme FIAS. Écrivez correctement «Ville de Moscou, Zelenograd».
Comment en est-on arrivé là?
La première chose que nous faisons est de séparer tous les composants insignifiants de l'adresse des noms. Nous ne les jetons pas, ils participent à la recherche, mais séparément des parties importantes.
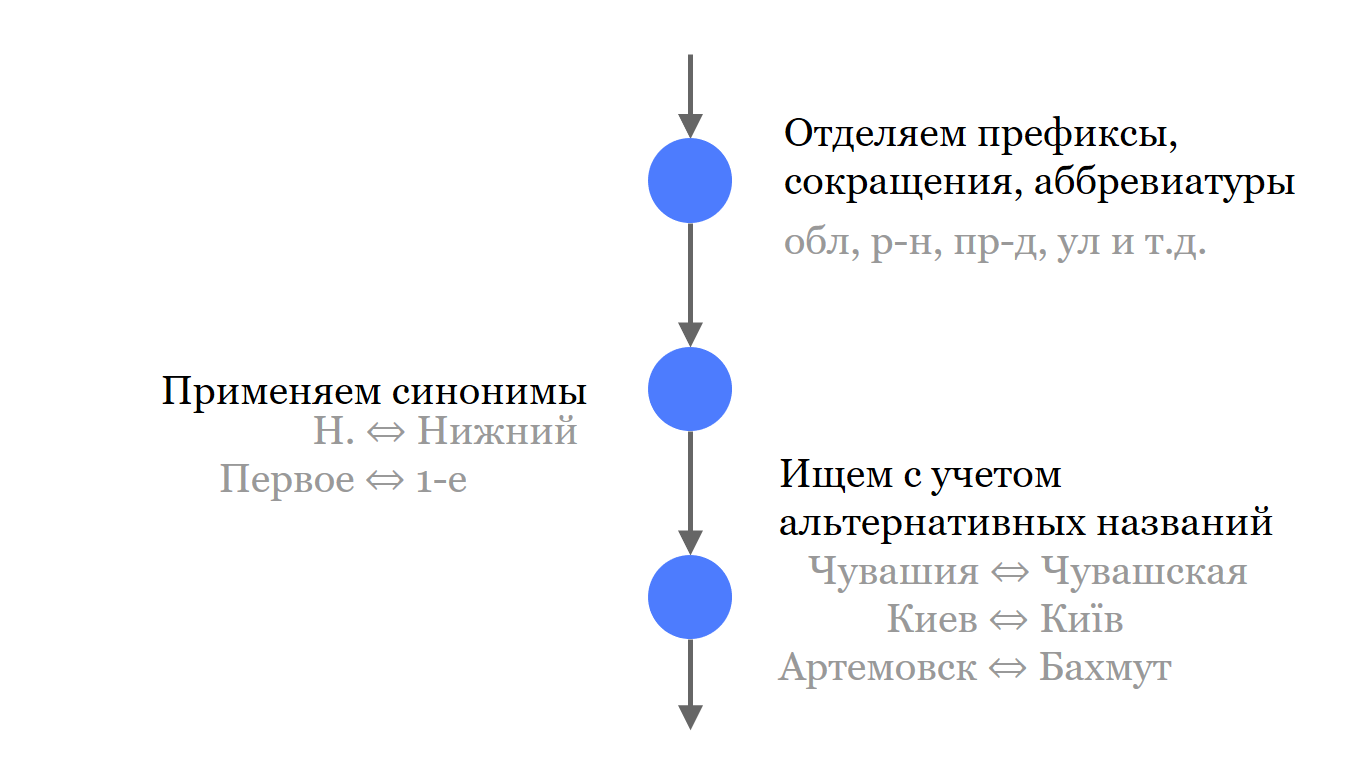
Ensuite, nous avons fait une courte liste de synonymes et d'abréviations communs qui sont utilisés dans les noms. Lorsque la source le permettait, nous avons chargé et mis tous les noms dans Solr. Non seulement les synonymes et les noms historiques les plus pertinents, mais aussi possibles.
Pour une meilleure recherche, nous jetons toutes les lettres qui peuvent introduire des écarts. Cela s'applique à la langue russe et aux langues avec lesquelles nous devons encore traiter.
Nous corrigeons les fautes de frappe et corrigeons la mise en page.
Enfin, nous avons trouvé des parents fantômes - ce sont des parents affectés à des objets. Ils sont pertinents dans la recherche, mais ne participent pas au résultat de la recherche. Par exemple, pour Zelenograd, nous avons ajouté la région de Moscou. Maintenant, vous pouvez rechercher «Région de Moscou, Zelenograd» et trouver l'objet dont nous avons besoin, mais dans les résultats de recherche, ce sera toujours le bon «Moscou, Zelenograd».
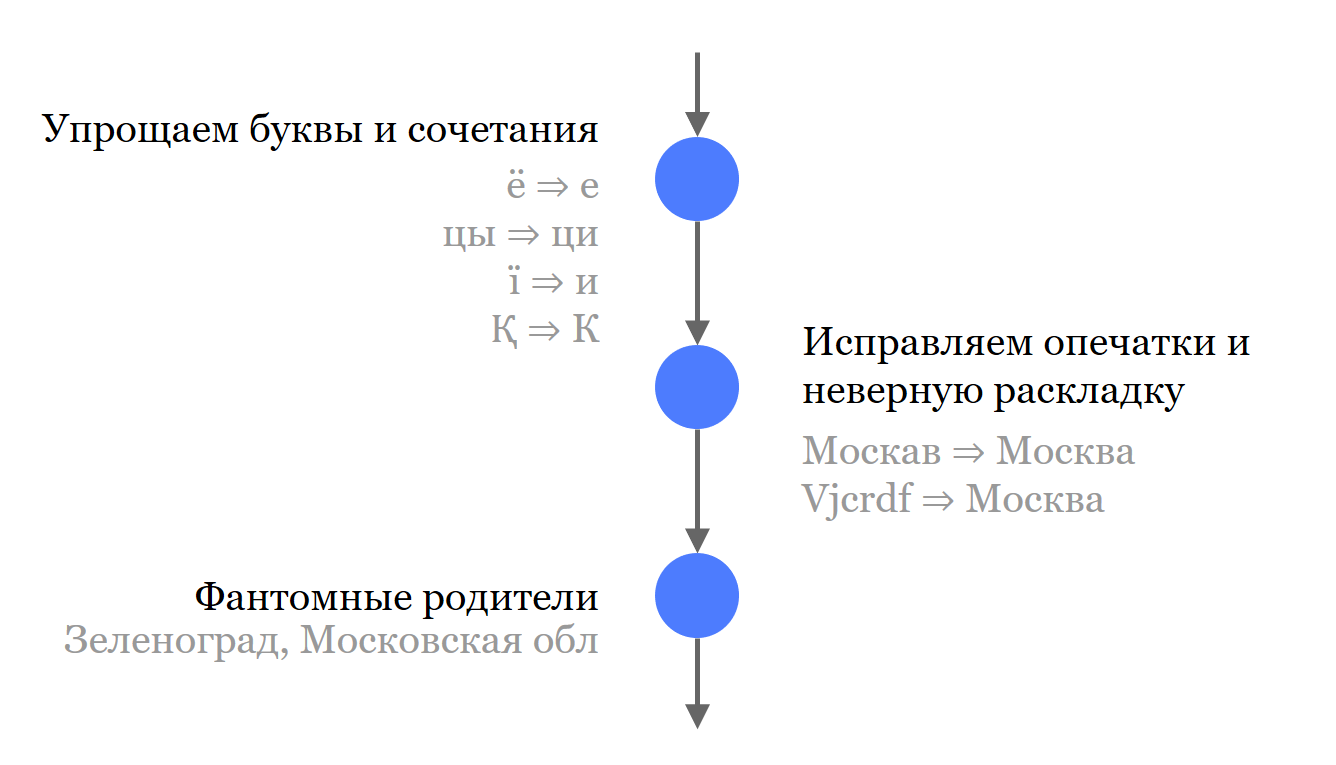
Selon les besoins de l'entreprise, une gradation différente de la précision de la recherche est nécessaire. Par conséquent, nous avons 4 degrés, chacun d'eux donne un résultat avec une probabilité plus élevée, mais avec une probabilité plus faible, ce sera exactement le résultat recherché.

Et où avons-nous trouvé une telle application de recherche?
- Encore une fois, nous exécutons l'adresse saisie par le client via une telle recherche. S'il n'a pas utilisé nos conseils sur la page de paiement, nous avons encore une chance de transformer les lignes qu'il a entrées en identifiants. Nous obtenons une adresse officielle.
- Nous parcourons cette recherche tout ce que les services de messagerie nous envoient - nous reconnaissons les villes qu'ils nous transmettent. Cela nous a permis de lancer seulement 10 pièces par jour, ce qui est pertinent pour B2B - Lamoda fournit sa livraison à des sociétés tierces, il y a donc beaucoup de nouveaux services de messagerie connectés par unité de temps.
- Cela nous a permis de «chaîne» diverses informations utiles dans nos identifiants dans les bases de données d'adresses. Par exemple, nous avons téléchargé des fuseaux horaires, des adresses IP, pour rechercher des villes par les adresses IP des clients.
- Nous avons maintenant la possibilité de masquer la base d'adresses combinée de deux sources avec l'un de nos identifiants. Autrement dit, cela a permis d'éviter les doublons et de faire correspondre les mêmes objets d'adresse dans les deux bases.
Nous ne nous arrêtons pas. C'est un processus que nous pouvons encore améliorer.
Tout d'abord, Lamoda travaille sur les index. Autrement dit, nos identifiants sont des indices, dont nous connaissons les inconvénients. Presque tous nos systèmes sont passés à la nouvelle API; ils ne fonctionnent pas avec des index, mais avec les identifiants mêmes que nous avons nous-mêmes attribués à nos objets d'adresse. Le plus est que la recherche d'une ville sur le territoire est aussi simple qu'avec des index. Cependant, il n'y a aucun inconvénient dans le fait que plusieurs colonies peuvent se cacher derrière une seule carte d'identité.
Addition: Le temps a passé depuis le moment de mon discours, et maintenant je suis heureux de me corriger: nos index ne restent maintenant que dans le cas, lorsque le courrier nous donne son territoire sous la forme d'une liste d'entre eux, par exemple, la poste russe. Dans d'autres cas, les index ont été supplantés par nos identifiants d'adresse internes.
Sur la diapositive est un morceau de l'interface qui vous permet de configurer manuellement le territoire, mais en fait tout est configuré à partir de listes d'objets d'adresse chargées par lots sous forme de chaînes.

Nous avons téléchargé les coordonnées géographiques de openstreetmap.org pour les maisons. Maintenant, dans un grand pourcentage de cas, nous n'avons pas besoin d'aller à un service externe pour connaître l'emplacement. Cela nous a permis de réduire de 10 fois le nombre de voyages à Yandex, ce qui a naturellement économisé de l'argent.
Nous nous débarrassons de PHP dans la chaîne de recherche des données d'adresse. Nous avons réécrit le code qui accédait à Solr sur Lua. Nginx remplacé par Openresty , maintenant tout est très rapide et peut supporter de lourdes charges. 95% des réponses de notre service de recherche tiennent en 10 millisecondes, ce qui est plus que suffisant pour nous.

Addition: Utiliser Openresty et Lua, qui ont séduit par leurs performances, a été une sorte d'expérience qui a porté ses fruits: le service fonctionne rapidement, est stable sous charge, et est facilement maintenu. Mais depuis lors, Lamoda a adopté Golang, qui a les mêmes qualités, que l'un des langages de programmation pour le backend chargé. Si la décision de développer le service était prise maintenant, nous la préférerions.
Conclusion
Ma moralité personnelle de tout le travail effectué est que les données d'adresse sont un domaine où vous ne pouvez pas vous attendre à une qualité de données idéale. Cela n'arrivera jamais. Nous ne recevrons jamais de données parfaites d'un client ou de sources externes. Par conséquent, vous devez tirer le maximum de ce qui est.