 ProxylessNAS optimise directement l'architecture des réseaux de neurones pour une tâche et un équipement spécifiques, ce qui peut augmenter considérablement la productivité par rapport aux approches proxy précédentes. Sur un ensemble de données ImageNet, un réseau de neurones est conçu en 200 heures GPU (200 à 378 fois plus rapide que ses homologues), et le modèle CNN conçu automatiquement pour les appareils mobiles atteint le même niveau de précision que MobileNetV2 1.4, fonctionnant 1,8 fois plus rapidement.
ProxylessNAS optimise directement l'architecture des réseaux de neurones pour une tâche et un équipement spécifiques, ce qui peut augmenter considérablement la productivité par rapport aux approches proxy précédentes. Sur un ensemble de données ImageNet, un réseau de neurones est conçu en 200 heures GPU (200 à 378 fois plus rapide que ses homologues), et le modèle CNN conçu automatiquement pour les appareils mobiles atteint le même niveau de précision que MobileNetV2 1.4, fonctionnant 1,8 fois plus rapidement.Des chercheurs du Massachusetts Institute of Technology ont développé un algorithme efficace pour la conception automatique de réseaux de neurones hautes performances pour du matériel spécifique,
écrit la publication
MIT News .
Les algorithmes de conception automatique de systèmes d'apprentissage automatique constituent un nouveau domaine de recherche dans le domaine de l'IA. Cette technique est appelée recherche d'architecture neuronale (NAS) et est considérée comme une tâche de calcul difficile.
Les réseaux de neurones conçus automatiquement ont une conception plus précise et efficace que ceux développés par les humains. Mais la recherche d'une architecture neuronale nécessite des calculs vraiment énormes. Par exemple, l'algorithme moderne NASNet-F, récemment développé par Google pour fonctionner sur des GPU, nécessite 48000 heures de calcul GPU pour créer un réseau neuronal convolutionnel, qui est utilisé pour classer et détecter des images. Bien sûr, Google peut exécuter des centaines de GPU et d'autres matériels spécialisés en parallèle. Par exemple, sur mille GPU, ce calcul ne prendra que deux jours. Mais tous les chercheurs n'ont pas de telles opportunités, et si vous exécutez l'algorithme dans le cloud informatique de Google, il peut voler dans un joli centime.
Les chercheurs du MIT ont préparé un article pour la Conférence internationale sur les représentations de l'apprentissage,
ICLR 2019 , qui se tiendra du 6 au 9 mai 2019. L'article
ProxylessNAS: Recherche directe d'architecture neuronale sur la tâche et le matériel cibles décrit l'algorithme ProxylessNAS qui peut directement développer des réseaux neuronaux convolutifs spécialisés pour des plates-formes matérielles spécifiques.
Lorsqu'il est exécuté sur un ensemble massif de données d'image, l'algorithme a conçu l'architecture optimale en seulement 200 heures de fonctionnement GPU. Ceci est deux ordres de grandeur plus rapide que le développement de l'architecture CNN en utilisant d'autres algorithmes (voir tableau).
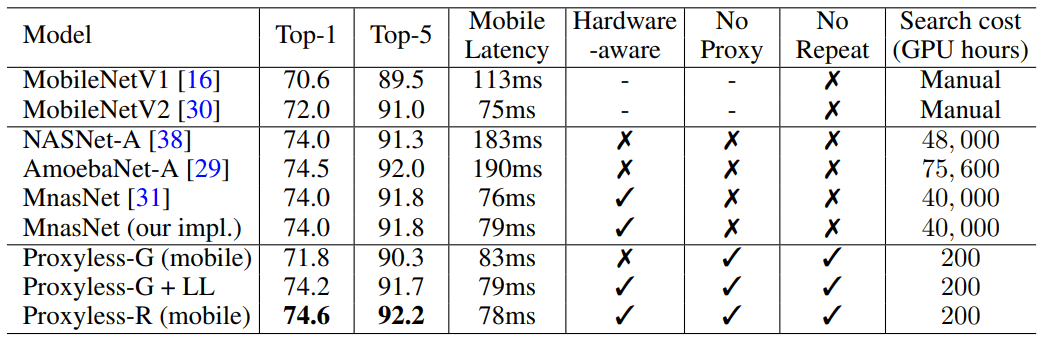
Les chercheurs et les entreprises aux ressources limitées bénéficieront de l'algorithme. Un objectif plus général est de «démocratiser l'IA», explique le co-auteur scientifique Song Han, professeur agrégé de génie électrique et d'informatique aux Microsystems Technology Laboratories du MIT.
Khan a ajouté que de tels algorithmes NAS ne remplaceront jamais le travail intellectuel des ingénieurs: "Le but est de décharger le travail répétitif et fastidieux qui accompagne la conception et l'amélioration de l'architecture des réseaux de neurones."
Dans leur travail, les chercheurs ont trouvé des moyens de supprimer les composants inutiles d'un réseau neuronal, de réduire le temps de calcul et d'utiliser uniquement une partie de la mémoire matérielle pour exécuter l'algorithme NAS. Cela garantit que le CNN développé fonctionne plus efficacement sur des plates-formes matérielles spécifiques: CPU, GPU et appareils mobiles.
L'architecture CNN est constituée de couches avec des paramètres ajustables appelés «filtres» et des relations possibles entre elles. Les filtres traitent les pixels de l'image dans des grilles carrées - telles que 3 × 3, 5 × 5 ou 7 × 7 - où chaque filtre couvre un carré. En fait, les filtres se déplacent autour de l'image et combinent les couleurs de la grille de pixels en un pixel. Dans différentes couches, les filtres sont de différentes tailles, qui sont connectés de différentes manières pour échanger des données. La sortie CNN produit une image compressée combinée à partir de tous les filtres. Étant donné que le nombre d'architectures possibles - le soi-disant «espace de recherche» - est très important, l'utilisation de NAS pour créer un réseau neuronal sur des ensembles massifs de données d'image nécessite d'énormes ressources. En règle générale, les développeurs exécutent le NAS sur des ensembles de données (proxy) plus petits et transfèrent les architectures CNN résultantes vers la cible. Cependant, cette méthode réduit la précision du modèle. De plus, la même architecture s'applique à toutes les plates-formes matérielles, ce qui entraîne des problèmes de performances.
Les chercheurs du MIT ont formé et testé le nouvel algorithme sur la tâche de classer les images directement dans l'ensemble de données ImageNet, qui contient des millions d'images dans mille classes. Tout d'abord, ils ont créé un espace de recherche qui contient tous les «chemins» possibles pour les candidats CNN afin que l'algorithme trouve parmi eux l'architecture optimale. Pour adapter l'espace de recherche à la mémoire du GPU, ils ont utilisé une méthode appelée binarisation au niveau du chemin, qui enregistre un seul chemin à la fois et économise la mémoire par ordre de grandeur. La binarisation est combinée à l'élagage au niveau du chemin, une méthode qui étudie traditionnellement les neurones d'un réseau de neurones qui peuvent être supprimés en toute sécurité sans nuire au système. Seulement au lieu de supprimer les neurones, l'algorithme NAS supprime des chemins entiers, changeant complètement l'architecture.
En fin de compte, l'algorithme coupe tous les chemins improbables et enregistre uniquement le chemin avec la probabilité la plus élevée - c'est l'architecture CNN ultime.
L'illustration montre des échantillons de réseaux de neurones pour classer les images que ProxylessNAS a développées pour les GPU, les CPU et les processeurs mobiles (de haut en bas, respectivement).
