
Les améliorations de la vitesse du processeur ralentissent, et nous voyons l'industrie des semi-conducteurs passer aux cartes accélératrices afin que les résultats continuent de s'améliorer sensiblement. Nvidia a le plus profité de cette transition, mais elle s'inscrit dans la même tendance, alimentant la recherche sur les accélérateurs de réseaux neuronaux, les FPGA et les produits tels que les TPU de Google. Ces accélérateurs ont considérablement augmenté la vitesse de l'électronique ces dernières années, et beaucoup ont commencé à espérer qu'ils représentaient une nouvelle voie de développement, en lien avec le ralentissement de la loi de Moore. Mais un nouveau travail scientifique suggère qu'en réalité, tout n'est pas aussi rose que certains le souhaiteraient.
Les architectures spéciales telles que les GPU, TPU, FPGA et ASIC, même si elles fonctionnent très différemment des CPU à usage général, utilisent toujours les mêmes nœuds fonctionnels que les processeurs x86, ARM ou POWER. Et cela signifie que l'augmentation de la vitesse de ces accélérateurs dépend également dans une certaine mesure des améliorations associées à la mise à l'échelle des transistors. Mais quelle proportion de ces améliorations dépendait de l’amélioration des technologies de production et de l’augmentation de la densité associée à la loi de Moore, et quelle part des améliorations dans les domaines cibles auxquels ces transformateurs sont destinés? Quel pourcentage d'améliorations concerne uniquement les transistors?
Le professeur agrégé de génie électrique de l'Université de Princeton, David Wenzlaf, et son étudiant diplômé Adi Fuchs ont créé un modèle qui leur permet de mesurer la vitesse de l'amélioration. Leur modèle utilise les caractéristiques de 1612 CPU et 1001 GPU de différentes capacités, fabriqués sur la base de différentes unités fonctionnelles, pour évaluer numériquement les avantages associés aux améliorations des unités. Wenzlaf et Fuchs ont créé une
métrique pour améliorer les performances liées à la progression CMOS (CMOS-Driven return, CDR), qui peut être comparée aux améliorations acquises grâce à la spécialisation des puces (CSR).
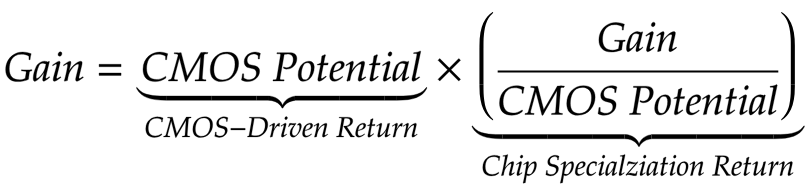
L'équipe est arrivée à une conclusion décourageante. Les avantages obtenus grâce à la spécialisation des puces sont fondamentalement liés au nombre de transistors placés dans un millimètre de silicium à long terme, ainsi qu'aux améliorations de ces transistors associées à chaque nouvelle unité fonctionnelle. Pire, il y a des limites fondamentales à la vitesse que nous pouvons extraire de l'amélioration des circuits d'accélérateur sans améliorer l'échelle du CMOS.
Il est important que tout ce qui précède s'applique à long terme. Une étude de Wenzlaf et Fuchs montre que la vitesse augmente souvent de façon spectaculaire lors de la première mise en service d'accélérateurs. Au fil du temps, lorsque les méthodes d'accélération optimales s'avèrent être étudiées et les meilleures pratiques décrites, les chercheurs arrivent à l'approche la plus optimale. De plus, sur les accélérateurs, les tâches bien définies d'une zone bien étudiée et pouvant être parallélisées (GPU) sont bien résolues. Cependant, cela signifie également que les mêmes propriétés, grâce auxquelles la tâche peut être adaptée aux accélérateurs, limitent à long terme l'avantage tiré de cette accélération. L'équipe a appelé ce problème «accélérateurs de blocage».
Et le marché de l'informatique haute performance le ressent probablement depuis un certain temps. En 2013, nous avons écrit sur la
route difficile qui mène aux anciens supercalculateurs. Et même alors, Top500 a prédit que les accélérateurs donneraient un bond ponctuel dans les cotes de performance, mais n'augmenteraient pas la vitesse d'augmentation de la vitesse.

Cependant, les conséquences de ces découvertes dépassent le marché de l'informatique haute performance. Par exemple, après avoir étudié le GPU, Wenzlaf et Fuchs ont constaté que les avantages qui ne pouvaient pas être attribués à l'amélioration du CMOS étaient très faibles.
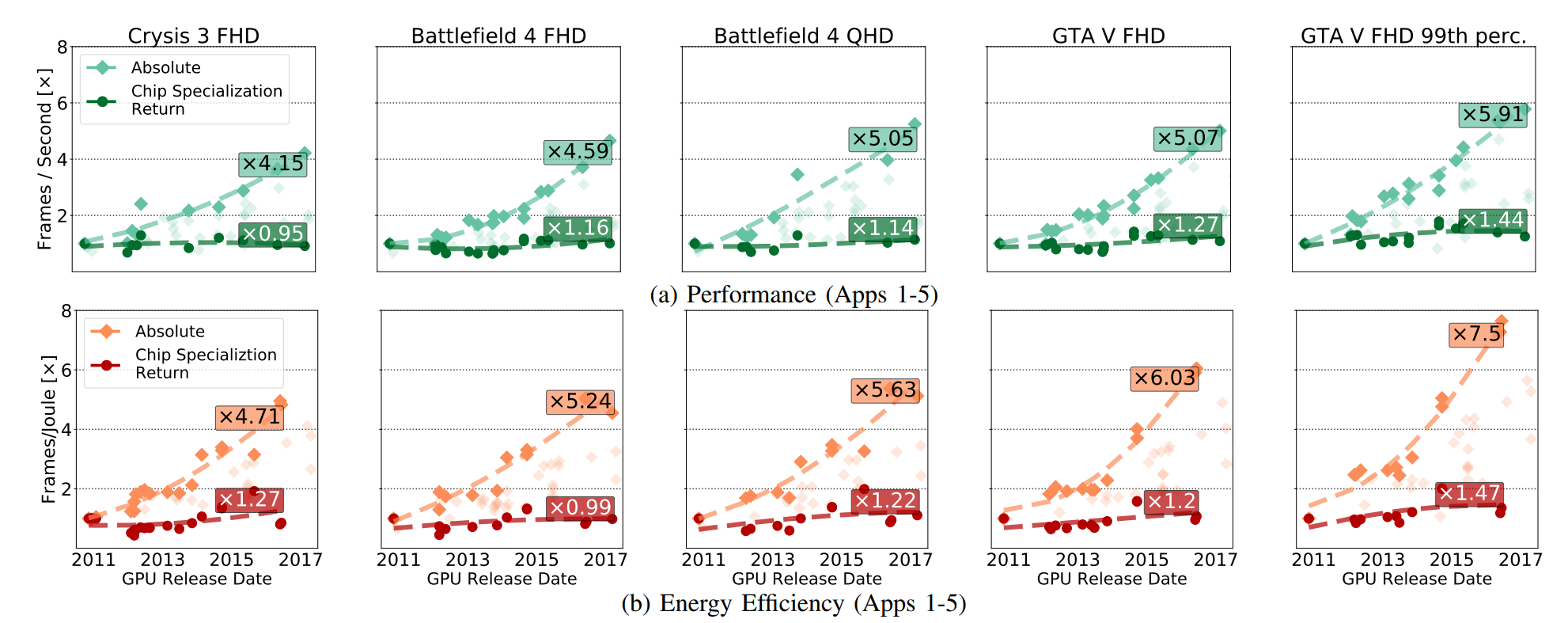
Dans la fig. La croissance des performances absolues du GPU a été démontrée (y compris les avantages tirés du développement de CMOS), et ces avantages ont émergé uniquement du développement de la RSE. Les CSR concernent les améliorations qui restent si vous supprimez toutes les percées de la technologie CMOS du circuit GPU.
La figure suivante clarifie la relation des quantités:
Diminuer la RSE ne signifie pas ralentir le GPU en chiffres absolus. Comme l'écrit Fuchs:
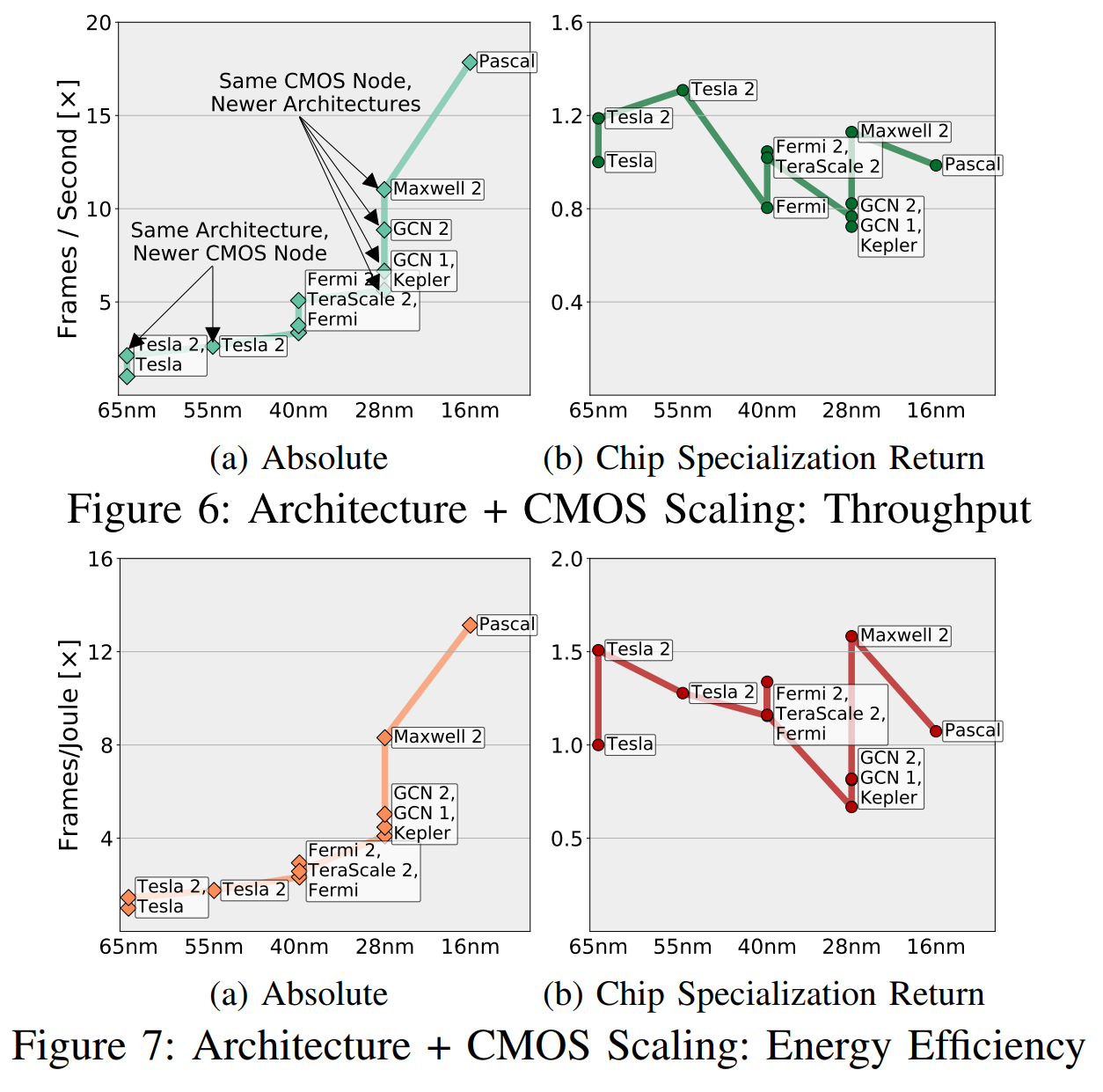
La RSE normalise le profit «en fonction du potentiel du CMOS», et ce «potentiel» prend en compte le nombre de transistors et la différence de vitesse, d'efficacité dans l'utilisation de l'énergie, de la surface, etc. (dans différentes générations de CMOS). Dans la fig. 6, nous avons donné une comparaison approximative des combinaisons «architecture + nœuds CMOS», en triangulant les vitesses mesurées de toutes les applications sur différentes combinaisons, et en utilisant des relations transitives entre ces combinaisons qui n'ont pas assez d'applications communes (moins de cinq).
Intuitivement, ces graphiques peuvent être compris comme sur la Fig. 6a montre ce que "les ingénieurs et les gestionnaires voient", et sur la fig. 6b est "ce que nous voyons, à l'exclusion du potentiel de CMOS." Je vais oser suggérer que vous vous souciez plus de savoir si votre nouvelle puce est en avance sur la précédente que si elle le fait à cause de meilleurs transistors ou à cause d'une meilleure spécialisation.
Le marché des GPU est bien défini, conçu et spécialisé, et AMD et Nvidia ont toutes les raisons de prendre de l'avance les unes sur les autres, améliorant les circuits. Mais, malgré cela, nous voyons que, pour la plupart, les accélérations sont dues à des facteurs liés au CMOS, et non à la RSE.
Les FPGA et les cartes spéciales pour le traitement des codecs vidéo, étudiés par les scientifiques, relèvent également de telles caractéristiques, même si l'amélioration relative au fil du temps est devenue plus ou moins due à la croissance du marché. Les mêmes caractéristiques qui vous permettent de répondre activement à l'accélération, limitent finalement la capacité des accélérateurs à améliorer leur efficacité. Fuchs et Wenzlaf écrivent sur le GPU: «Bien que la fréquence d'images des graphiques GPU ait augmenté de 16 fois, nous supposons que de nouvelles améliorations de la vitesse et de l'efficacité énergétique suivront respectivement 1,4-2,4 fois et 1,4-1,7 fois» . AMD et Nvidia n'ont pas d'espace de manœuvre spécial dans lequel vous pouvez augmenter la vitesse en améliorant le CMOS.
Les implications de ce travail sont importantes. Elle dit que la spécificité de leurs domaines d’architecture n’apportera plus d’améliorations significatives de la vitesse lorsque la loi de Moore cessera de fonctionner. Et même si les concepteurs de puces peuvent se concentrer sur l'amélioration des performances dans un nombre fixe de transistors, ces améliorations seront limitées par le fait que des processus bien étudiés n'ont presque nulle part à s'améliorer.
Les travaux indiquent la nécessité de développer une approche fondamentalement nouvelle de l'informatique. Une alternative potentielle est l'
architecture Intel Meso . Fuchs et Wenzlaf ont également
suggéré d' utiliser des matériaux alternatifs et d'autres solutions qui dépassent le cadre du CMOS, y compris des recherches sur la possibilité d'utiliser la mémoire non volatile comme accélérateurs.