Les systèmes interactifs utilisent de nombreux répertoires différents, des dictionnaires de données, ce sont différents statuts, codes, noms, etc., en règle générale, ils sont nombreux et chacun n'est pas grand. Dans la structure, ils ont souvent des attributs communs: Code, ID, Nom, etc. Dans le code d'application, il existe de nombreuses recherches différentes, des comparaisons par Code, par ID de référence. Les recherches peuvent être étendues, par exemple: recherche par ID, par Code, obtenir une liste par critère, trier, etc ... Et par conséquent, les répertoires sont mis en cache, ce qui réduit les accès fréquents à la base de données. Ici, je veux montrer un exemple de la façon dont les référentiels de valeurs-clés Spring Data peuvent être utiles à ces fins. L'idée principale est la suivante: une recherche avancée dans le référentiel de valeurs-clés et, en l'absence d'objet, effectuez une recherche dans les référentiels de données Spring dans la base de données, puis placez-la dans les référentiels de valeurs-clés.
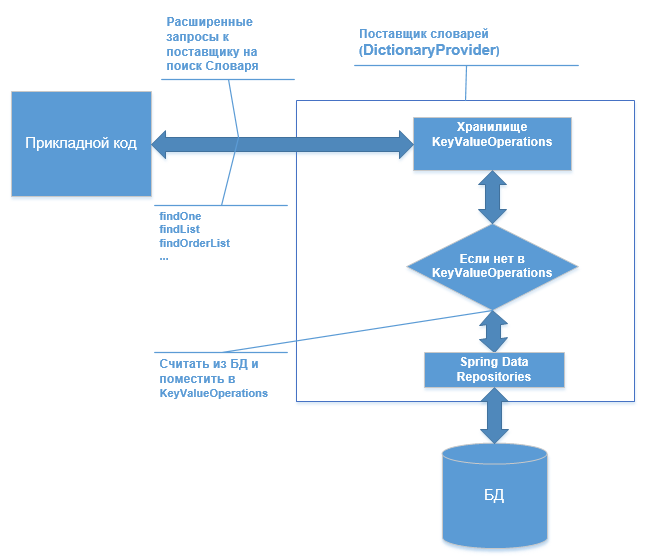
Et donc dans Spring, il y a KeyValueOperations, qui est similaire au référentiel Spring Data, mais il fonctionne sur le concept de valeur-clé et nous plaçons les données dans une structure HashMap (j'ai
écrit sur les référentiels Spring Data ici ). Les objets peuvent être de tout type, l'essentiel est que la clé soit spécifiée.
public class Status { @org.springframework.data.annotation.Id private long statusId; private String code; private String name; ....
Ici, la clé est statusId, et le chemin complet de l'annotation est spécifiquement indiqué, à l'avenir, j'utiliserai l'entité JPA, et il y a aussi un identifiant, mais déjà lié à la base de données.
KeyValueOperations a des méthodes similaires à celles des référentiels Spring Data
interface KeyValueOperations { <T> T insert(T objectToInsert); void update(Object objectToUpdate); void delete(Class<?> type); <T> T findById(Object id, Class<T> type); <T> Iterable<T> find(KeyValueQuery<?> query, Class<T> type); .... .
Vous pouvez donc spécifier la configuration java KeyValueOperations pour Spring bean
@SpringBootApplication public class DemoSpringDataApplication { @Bean public KeyValueOperations keyValueTemplate() { return new KeyValueTemplate(keyValueAdapter()); } @Bean public KeyValueAdapter keyValueAdapter() { return new MapKeyValueAdapter(ConcurrentHashMap.class); }
La classe de stockage de dictionnaire est répertoriée ici - ConcurrentHashMap
Et puisque je travaillerai avec les dictionnaires JPA Entity, j'en connecterai deux à ce projet.
Ceci est un dictionnaire de «Statut» et «Carte»
@Entity public class Status { @org.springframework.data.annotation.Id private long statusId; private String code; private String name; @Id @Column(name = "STATUS_ID") public long getStatusId() { return statusId; } .... @Entity public class Card { @org.springframework.data.annotation.Id private long cardId; private String code; private String name; @Id @Column(name = "CARD_ID") public long getCardId() { return cardId; } ...
Ce sont des entités standard qui correspondent aux tables de la base de données, j'attire l'attention sur deux annotations Id pour chaque entité, une pour JPA, l'autre pour KeyValueOperations
La structure des dictionnaires est similaire, un exemple de l'un d'eux
create table STATUS ( status_id NUMBER not null, code VARCHAR2(20) not null, name VARCHAR2(50) not null );
Référentiels Spring Data pour eux:
@Repository public interface CardCrudRepository extends CrudRepository<Card, Long> { } @Repository public interface StatusCrudRepository extends CrudRepository<Status, Long> { }
Et voici l'exemple DictionaryProvider lui-même où nous connectons les référentiels Spring Data et KeyValueOperations
@Service public class DictionaryProvider { private static Logger logger = LoggerFactory.getLogger(DictionaryProvider.class); private Map<Class, CrudRepository> repositoryMap = new HashMap<>(); @Autowired private KeyValueOperations keyValueTemplate; @Autowired private StatusCrudRepository statusRepository; @Autowired private CardCrudRepository cardRepository; @PostConstruct public void post() { repositoryMap.put(Status.class, statusRepository); repositoryMap.put(Card.class, cardRepository); } public <T> Optional<T> dictionaryById(Class<T> clazz, long id) { Optional<T> optDictionary = keyValueTemplate.findById(id, clazz); if (optDictionary.isPresent()) { logger.info("Dictionary {} found in keyValueTemplate", optDictionary.get()); return optDictionary; } CrudRepository crudRepository = repositoryMap.get(clazz); optDictionary = crudRepository.findById(id); keyValueTemplate.insert(optDictionary.get()); logger.info("Dictionary {} insert in keyValueTemplate", optDictionary.get()); return optDictionary; } ....
Les injections automatiques y sont installées pour les référentiels et pour KeyValueOperations, puis la logique simple (ici sans vérifier la valeur null, etc.), nous regardons dans le dictionnaire keyValueTemplate, s'il y en a un, puis nous revenons, sinon nous extrayons de la base de données via crudRepository et le plaçons dans keyValueTemplate, et donnons dehors.
Mais si tout cela se limitait à une recherche par clé, alors il n'y a probablement rien de spécial. Ainsi, KeyValueOperations dispose d'un large éventail d'opérations et de demandes CRUD. Voici un exemple de recherche dans le même keyValueTemplate, mais déjà par Code à l'aide de la requête KeyValueQuery.
public <T> Optional<T> dictionaryByCode(Class<T> clazz, String code) { KeyValueQuery<String> query = new KeyValueQuery<>(String.format("code == '%s'", code)); Iterable<T> iterable = keyValueTemplate.find(query, clazz); Iterator<T> iterator = iterable.iterator(); if (iterator.hasNext()) { return Optional.of(iterator.next()); } return Optional.empty(); }
Et c'est compréhensible, si plus tôt j'ai recherché par ID et que l'objet est entré dans keyValueTemplate, alors la recherche par le code du même objet le renverra déjà depuis keyValueTemplate, il n'y aura pas d'accès à la base de données. Spring Expression Language est utilisé pour décrire la demande.
Exemples de tests:
Recherche d'ID
private void find() { Optional<Status> status = dictionaryProvider.dictionaryById(Status.class, 1L); Assert.assertTrue(status.isPresent()); Optional<Card> card = dictionaryProvider.dictionaryById(Card.class, 100L); Assert.assertTrue(card.isPresent()); }
Recherche par code
private void findByCode() { Optional<Card> card = dictionaryProvider.dictionaryByCode(Card.class, "VISA"); Assert.assertTrue(card.isPresent()); }
Vous pouvez obtenir des listes de données via
<T> Iterable<T> find(KeyValueQuery<?> query, Class<T> type);
Vous pouvez spécifier le tri dans la demande
query.setSort(Sort.by(DESC, "name"));
Matériaux:
valeur-clé de données de printempsProjet Github