Yandex dispose d'un service de développement de composants de recherche qui construit une base de recherche sur MapReduce, fournit des données pour la composition pour le rendu, génère des algorithmes et des structures de données et résout les problèmes ML de croissance de la qualité. Alexey Shlyunkin, chef d'un des groupes de ce service, explique en quoi consiste le runtime de recherche et comment nous le gérons.
Vous voulez fouiller en ML - fouiner. Vous ne voulez que MapReduce - ok. Vous voulez runtime - runtime.
- Qu'est-ce qu'une recherche aujourd'hui? Yandex a commencé par faire une recherche, en la développant. 20 ans se sont écoulés. Nous avons une base de recherche pour des centaines de milliards de documents.
Nous appelons un document n'importe quelle page sur Internet, mais, en fait, non seulement cela. Pourtant - son contenu, diverses statistiques sur les utilisateurs qui aiment y aller, combien d'entre eux. Plus les données que nous avons calculées.
Ce sont aussi des dizaines de milliers d'instances qui, en réponse à chaque demande, traitent des données, recherchent quelque chose, enrichissent la réponse de recherche. Certaines instances recherchent des images, d'autres des documents texte ordinaires, d'autres des vidéos, etc. Autrement dit, des dizaines de milliers de machines sont activées pour chacune de vos demandes. Ils essaient tous de trouver quelque chose et d'améliorer le résultat qui vous est montré. En conséquence, des dizaines de milliers de machines traitent des milliers de requêtes par seconde. Ces dizaines de milliers d'instances sont combinées en des centaines de services conçus pour résoudre un problème.

Il existe un noyau de recherche - un service de recherche Web. Et il y a un service de recherche vidéo, etc. En conséquence, il y a une chose qui combine les réponses de différentes recherches et essaie de choisir quoi et dans quel ordre il est préférable de montrer à l'utilisateur. S'il s'agit d'une sorte de demande concernant la musique, il est probablement préférable de montrer d'abord Yandex.Music, puis, par exemple, une page sur ce groupe de musique. C'est ce qu'on appelle un mélangeur. Il existe déjà des centaines de ces services, et ils font également quelque chose pour chaque demande et essaient d'aider les utilisateurs d'une manière ou d'une autre. Et, bien sûr, tout cela utilise l'apprentissage automatique de toutes sortes, de quelques statistiques simples, des modèles linéaires, à des augmentations de gradient, des réseaux de neurones, etc.
Je vais parler de l'infrastructure et du ML dès maintenant.
Mon groupe s'appelle le nouveau groupe de développement d'exécution, il fait partie du service de développement de composants de recherche. Pour que vous ayez une idée, je vais vous dire un peu ce que fait notre service.

En fait, à tout le monde. Si vous soumettez une recherche, nous avons lancé nos mains dans presque tout, à partir de la création d'une base de recherche. C'est-à-dire que nous avons MapReduce, nous collectons toutes les données sur les documents, les faisons bouillir, construisons toutes sortes de structures de données, de sorte que lorsque nous les interrogons, nous pouvons calculer efficacement quelque chose. En conséquence, nous travaillons par le bas lorsque le document nous parvient, de la première étape, lorsque ces documents obtiennent quelque chose et le classent, et tout en haut, où la mise en page reçoit le JSON conditionnel et le dessine avec toutes les images et les belles choses. De bas en haut, nous développons quelque chose sur toute la pile.
Mais nous n'écrivons pas seulement du code et, par conséquent, nous faisons tout cela dans l'infrastructure. Nous formons actuellement des réseaux de neurones, CatBoost. Et d'autres choses ML que vous pouvez imaginer et graver, nous enseignons également. De plus, comme nous avons de grosses charges, des données volumineuses, nous fouillons bien sûr des algorithmes et des structures de données sans jamais nous empêcher de les introduire quelque part. Par exemple, à plusieurs endroits, nous utilisons des arbres de segments. Nous avons notre propre compression d'indices qui construisent du bore et, selon elle, nous considérons la dynamique de la meilleure façon de construire des dictionnaires.
En général, en traitant un si grand colosse comme une recherche, nous étions saturés de tâches aussi simples. Par conséquent, nous, bien sûr, adorons quelque chose de complexe, de nouveau, quelque chose qui nous interpelle. Et nous ne nous sommes pas contentés d'écrire, comme d'habitude, dix lignes de code. Nous devons penser à quelques expériences. En général, les tâches que nous nous fixons sont souvent au bord de la fiction. Parfois, vous pensez: ce n'est probablement pas possible. Mais alors vous, peut-être, avez en quelque sorte expérimenté - les expériences peuvent prendre une année entière - mais au final quelque chose se révèle. Ensuite, nous commençons à introduire, à refaire quelque chose.
Et en plus de tous les projets, compétences, etc., en général, nous sommes l'une des équipes les plus ambitieuses et à croissance rapide de Yandex. Par exemple, je suis venu il y a deux ans, était la neuvième personne à notre service. Nous avons maintenant un service de près de 60 personnes. C'est, en fait, avec les stagiaires, mais, en général, nous avons grandi quatre fois exactement en deux ans. C'est pour vous donner une idée de ce que fait notre service.
Maintenant, je veux vous parler un peu du sommet de nos tâches et de la direction que, il me semble, dans un proche avenir, nous serons de plus en plus pertinents. Mais pour cela, vous devez d'abord décrire brièvement le fonctionnement de la couche de recherche la plus élémentaire.
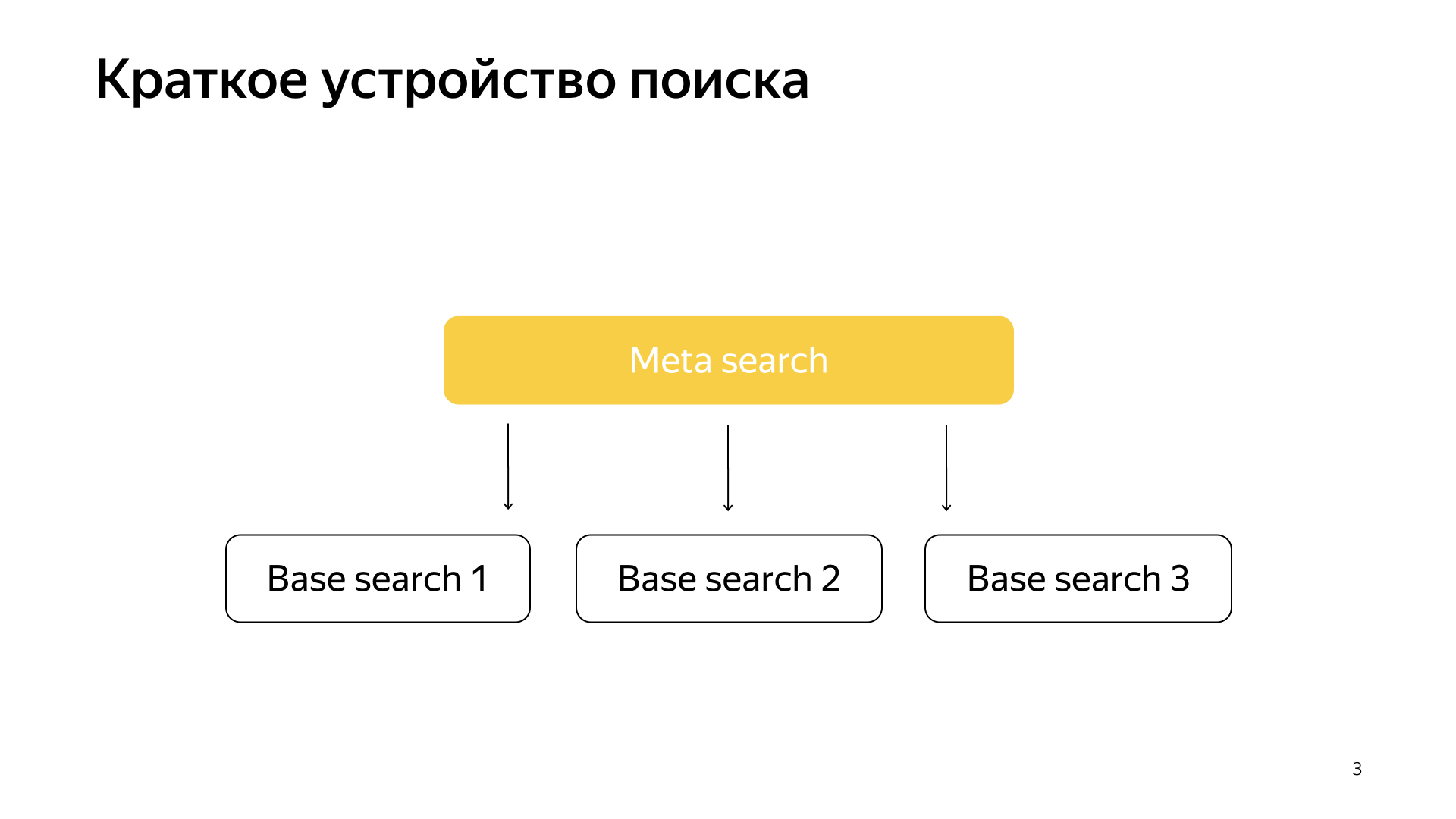
D'une manière générale, tout fonctionne très simplement. Nous avons notre base de recherche, nous avons tous les documents et nous divisons tous ces documents plus ou moins également en N morceaux. Ils sont appelés éclats. Et un programme appelé «Recherche de base» est lancé sur le fragment. Sa tâche consiste à rechercher, en conséquence, sur cette partie d'Internet. Autrement dit, elle sait comment le rechercher et ne sait rien de plus sur l'autre Internet. Et nous avons N éclats comme ça. Des recherches de base sont lancées au-dessus d'eux, et, en conséquence, il y a une méta-recherche à ce sujet. La demande de l'utilisateur y tombe et, en conséquence, elle va simplement à tous les fragments, et chaque fragment effectue une recherche, puis chacun renvoie un résultat, et il effectue une sorte de fusion et donne une réponse.
C’est ainsi que la recherche a été organisée pendant presque tous les 20 ans et, en général, pendant longtemps, ils ont pensé que cela resterait ainsi, et rien de mieux ne pouvait être fait. Mais tout change, de nouvelles technologies font leur apparition et l'apprentissage automatique vous permet non seulement d'augmenter la qualité, mais aussi de résoudre certains types de problèmes d'infrastructure. Récemment, dans notre recherche, les projets ont beaucoup tourné, juste à la jonction de l'infrastructure et du machine learning. Lorsque deux de ces mastodontes fusionnent, des résultats très intéressants sont obtenus.

Récemment, des réseaux de neurones sont apparus. Nous avons le texte de la demande, il y a le texte du document. Nous voulons obtenir un vecteur de nombres de la demande, obtenir un vecteur de nombres du document pour que le produit scalaire prédit la valeur que nous voulons. Par exemple, nous voulons entraîner le produit scalaire à prédire la probabilité qu'un utilisateur clique sur ce document. Une chose assez compréhensible.
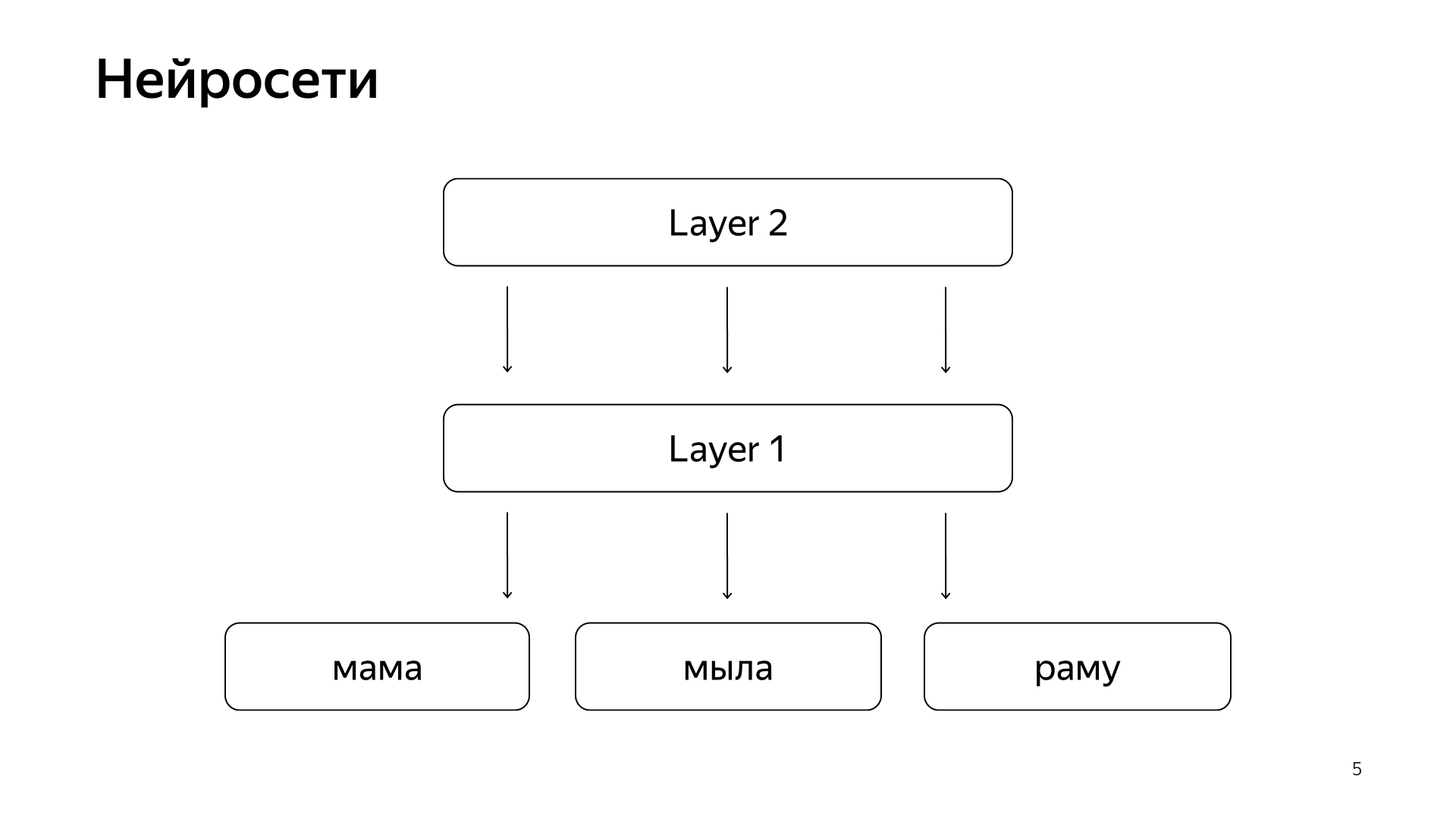
Il est disposé approximativement comme ceci. Si c'est très, très grossier, alors nous avons quelques mots sur la couche inférieure, puis il y a plusieurs couches du réseau. En fait, chaque couche prend un vecteur comme entrée. C'est-à-dire que la couche inférieure est un vecteur si clairsemé, où chaque mot est une demande. Le multiplie par une matrice, obtient une sorte de vecteur, puis, en conséquence, applique une certaine non-linéarité à chaque composant, et il le fait plusieurs fois. Et la dernière couche, c'est ce qu'on appelle juste le vecteur que nous venons de prendre la demande, appliqué de telles couches, et ici la dernière couche est le vecteur même de la demande.
En conséquence, ces réseaux de neurones ont été activement introduits dans la recherche ces dernières années, ils ont apporté de nombreux avantages pour la qualité. Mais ils ont un problème en ce que toutes les quantités que nous voulons prédire sont bonnes, mais assez grossières, car pour former un tel réseau de neurones, la couche inférieure est très grande - tous les mots proviennent de dizaines de millions de mots, vous devez donc être en mesure d'écrire elle a entré plusieurs milliards de données.
Par exemple, nous pouvons nous entraîner sur certains clics d'utilisateurs, etc. Mais le signal principal qui est considéré comme le plus important dans notre recherche est le marquage manuel par des personnes spéciales. Ils prennent la demande, prennent le document, le lisent, comprennent à quel point il est bon et mettent une marque, c'est-à-dire dans quelle mesure ce document correspond à cette demande. Pendant longtemps, nous ne pouvions pas prédire une telle ampleur par les réseaux de neurones, car nous avons encore des millions d'estimations, car engager la planète entière pour le marquer en permanence est très cher. Par conséquent, nous avons fait du hack.
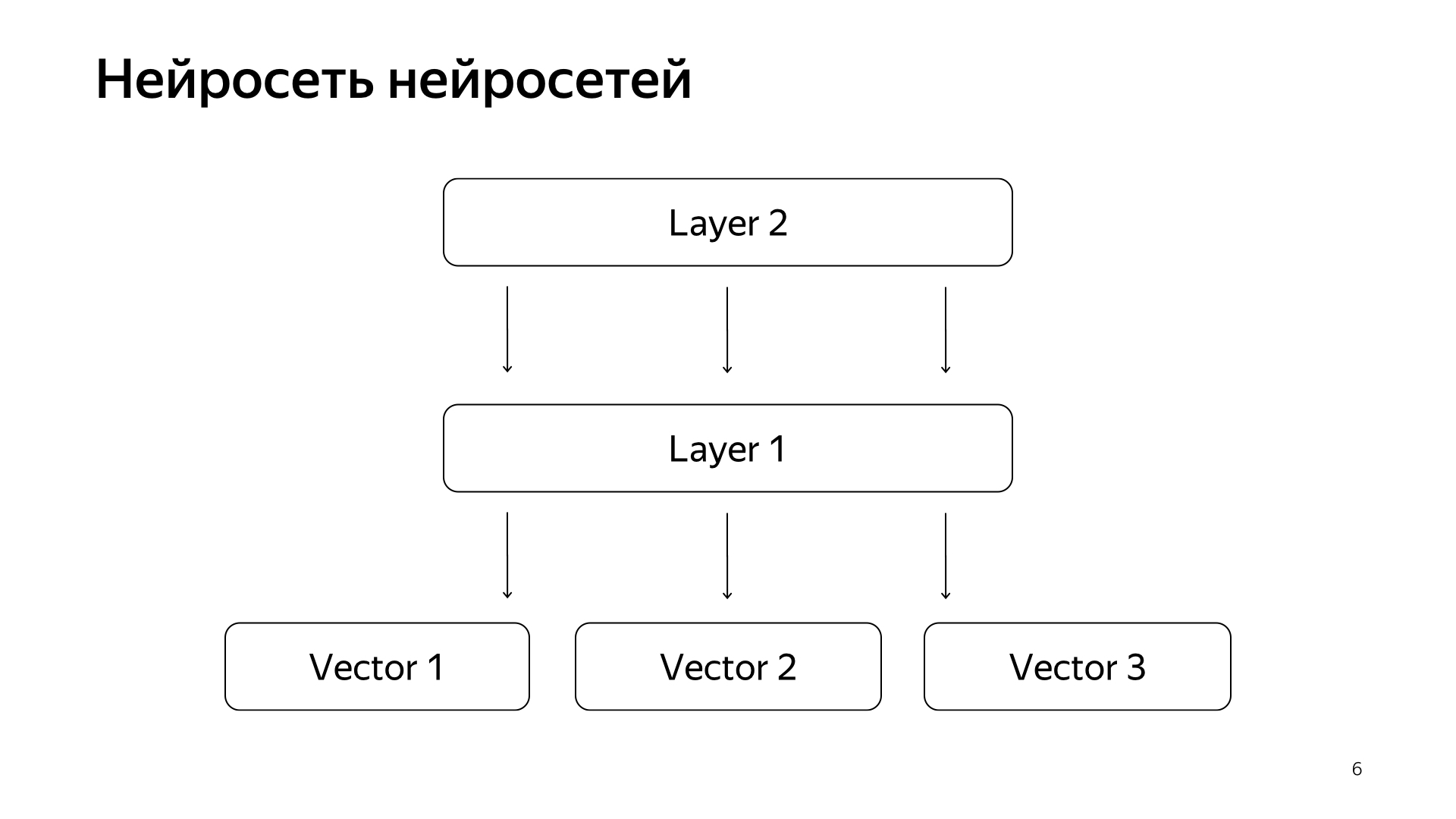
Réseau neuronal de réseaux neuronaux. Au cours des dernières années, nous avons accumulé pas mal de réseaux de neurones qui prédisent de bons signaux, mais un peu plus grossièrement que l'évaluation de personnes spéciales. En conséquence, nous avons décidé de soumettre les vecteurs prêts à l'emploi de ces réseaux à la couche inférieure, puis nous formerons le réseau neuronal pour prédire notre pertinence de recherche sur le plus petit réseau de données.
Le résultat était un très bon modèle. Elle amène les demandes de documents dans un vecteur, et leur produit scalaire prédit directement la pertinence réelle que nous avons longtemps voulu prédire.
De plus, nous avons eu une idée comment refaire un peu la recherche. Le projet s'appelle une base KNN (méthode des k-voisins les plus proches en anglais, méthode des k-voisins les plus proches).

L'idée de base est la suivante. Nous avons un vecteur de requête et un vecteur de document. Nous devons trouver le plus proche. Nous avons chaque document représenté par un vecteur. Soulignons N clusters, ceux qui caractérisent tout l'espace du document. En gros. Fortement plus petit que le nombre de documents, mais par exemple, ils caractérisent les sujets. En termes simples, il y a un groupe de chats, un groupe d'épicerie, un groupe de programmation, etc.
Par conséquent, nous ne disperserons pas les documents de manière aléatoire dans des fragments, comme auparavant, mais nous placerons le document dans ce fragment, c'est-à-dire dont le centroïde est le plus proche du document. En conséquence, ces documents seront regroupés par sujet dans un éclat.
Et de plus, juste pour une demande, maintenant nous ne pouvons pas aller à tous les fragments, mais seulement pour aller à un petit sous-ensemble de ceux qui sont les plus proches de cette demande.
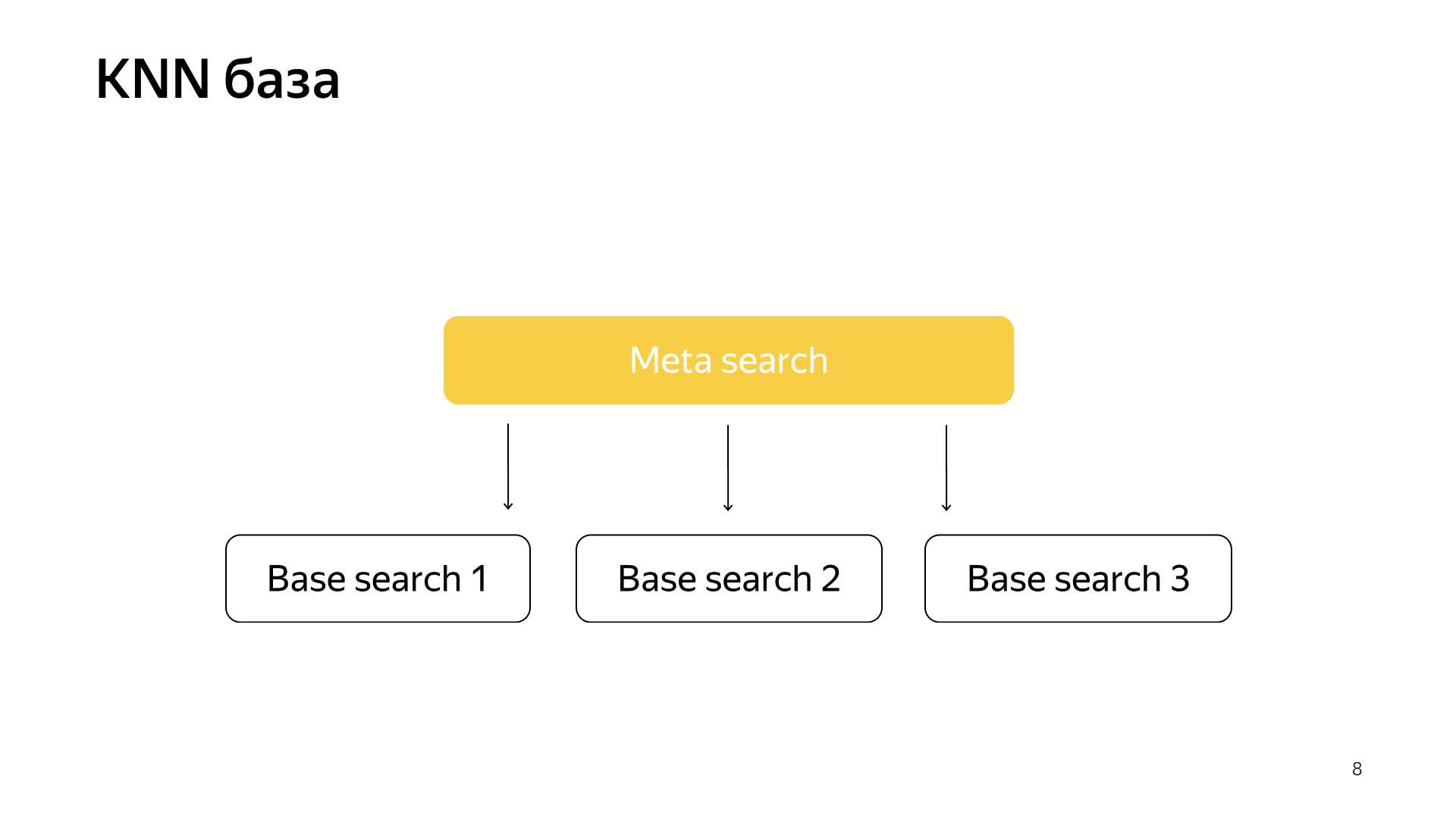
En conséquence, nous avions un tel schéma, la méta-recherche est incluse dans tous les fragments. Et maintenant, il doit aller à un nombre beaucoup plus petit, et en même temps, nous chercherons toujours les documents les plus proches.
Qu'obtenons-nous réellement de cette conception? Il réduit considérablement la consommation de ressources informatiques, tout simplement parce que nous allons à moins de clusters. Ceci, comme je l'ai déjà dit, je considère l'un des points forts de notre service, c'est l'alliage d'infrastructure et d'apprentissage automatique qui donne des résultats auxquels personne ne pouvait penser auparavant.

Et, au final, c'est juste une chose assez drôle, car vous avez les modèles ici, puis vous êtes allé, refait toute la recherche, désactivé les pétaoctets de données, et votre recherche fonctionne, cela consomme dix fois moins de ressources. Vous avez économisé un milliard de dollars pour l'entreprise, tout le monde est content.

J'ai parlé d'un des projets qui apparaît dans notre recherche et qui est mis en œuvre et fait avec toutes les expériences pendant une année suspendue. Nos autres tâches typiques consistent à doubler la base de recherche, car Internet ne cesse de croître et nous voulons le rattraper et effectuer des recherches sur toutes les pages d'Internet. Et bien sûr, c'est l'accélération de la couche de base, dans laquelle il y a le plus d'exemples, le plus de fer. Par exemple, accélérer votre recherche de base d'un pour cent signifie économiser environ un million de dollars.
Nous sommes également engagés dans la recherche d'un incubateur de startups. Je vais vous expliquer. La recherche se fait depuis 20 ans. Il a déjà fait beaucoup de choses, plusieurs fois nous nous sommes retrouvés dans une impasse et nous pensions que rien de plus ne pouvait être fait. Puis il y a eu une longue série d'expériences. Nous avons de nouveau franchi cette impasse. Et pendant ce temps, nous avons accumulé beaucoup d'expertise sur la façon de faire des choses grandes et cool. En conséquence, la plupart des nouvelles directions dans Yandex se font maintenant dans la recherche, car les personnes dans la recherche savent déjà comment faire tout cela, et il est logique de leur demander au moins de concevoir un nouveau système. Et au maximum - allez-y et faites-le vous-même.
Maintenant, j'espère que vous avez une petite idée de notre travail. Je vais rapidement raconter la partie thématique de mon histoire sur les stagiaires à notre service. Nous les aimons beaucoup. Nous en avons beaucoup, l'été dernier seulement dans mon groupe il y avait 20 stagiaires, et je pense que c'est bien. Lorsque vous prenez un ou trois stagiaires, ils se sentent un peu seuls, parfois ils ont peur de demander à des camarades plus âgés. Et quand il y en a beaucoup, ils communiquent entre eux comme des camarades malheureux. S'ils ont peur de demander quelque chose aux développeurs, ils iront, ils chuchoteront dans le coin. Une telle atmosphère aide à tout faire efficacement.
Nous avons un million de tâches, l'équipe n'est pas très grande, donc nos stagiaires sont complètement chargés. Nous ne demandons pas au stagiaire de s'asseoir sur le journal tout le temps, d'écrire des tests, de refactoriser le code, mais de donner immédiatement une sorte de tâche de production compliquée: accélérer la recherche, améliorer la compression d'index. Bien sûr, nous aidons. Nous savons que tout cela est payant, nous sommes donc heureux de partager notre expertise. Puisque notre domaine d'activité est assez étendu, chacun de nous trouvera une tâche à sa guise. Vous voulez fouiller en ML - fouiner. Vous ne voulez que MapReduce - ok. Vous voulez runtime - runtime. Il y a quelque chose.
De quoi avez-vous besoin pour nous rejoindre? Nous faisons tout principalement en C ++ et Python. Il n'est pas nécessaire de connaître les deux, on peut savoir une chose. Nous nous félicitons de la connaissance des algorithmes. Cela forme un certain style de pensée et ça aide beaucoup. Mais ce n'est pas non plus nécessaire: encore une fois, nous sommes prêts à tout enseigner, nous sommes prêts à investir notre temps, car nous savons que cela rapporte. L'exigence la plus importante que nous faisons, notre devise, est de ne pas avoir peur de quoi que ce soit et de beaucoup de chiffres. N'ayez pas peur de baisser la production, n'ayez pas peur de commencer à faire quelque chose de compliqué. Par conséquent, nous avons besoin de personnes qui n'ont peur de rien et qui sont également prêtes à tourner des montagnes. Merci beaucoup.