Dans cet article, nous parlerons d'une étude pilote de ML pour l'hypermarché en ligne d'Utkonos, où nous avons prédit le rachat de denrées périssables. Dans le même temps, nous avons pris en compte les données non seulement sur les bilans de stock, mais aussi le calendrier de production avec les week-ends et les jours fériés, et même la météo (la chaleur, la neige, la pluie et la grêle ne sont que Taft Three Weathers, mais pas les clients). Maintenant, nous savons, par exemple, que «l'âme russe mystérieuse» a particulièrement faim de viande le samedi et apprécie les œufs blancs au-dessus des œufs bruns. Mais tout d'abord.

Pilote de détail plus que pilote
Dans le commerce de détail, le machine learning est en double position. D'une part, les détaillants ont accumulé des quantités impressionnantes de données sur des périodes très impressionnantes: reçus d'achat individuels, données de cartes de fidélité ... outils BI nécessaires.
Il s'avère que la vente au détail est l'un des domaines les plus prometteurs pour les expériences de data scientist et l'introduction du machine learning, mais les entreprises envisagent tout cela avec scepticisme: est-ce vraiment bon pour moi? Après tout, il existe déjà des solutions fonctionnelles prouvées par de nombreuses années d'expérience.
Et puis il est temps de se mettre d'accord sur une étude pilote!
Les pilotes eux-mêmes, par rapport à un projet ML à part entière, ont des limites et des détails compréhensibles.
- On consacre suffisamment de temps à une étude pilote pour montrer aux clients les possibilités d'apprentissage automatique sur leurs données, mais pas au point de perdre de l'argent.
- De plus, en règle générale, les spécialistes des données n'auront plus de deuxième chance: si les premiers résultats de l'entreprise ne semblent pas intéressants, ils resteront sceptiques et fidèles aux anciennes méthodes de prévision. Vous devez donc viser avec précision.
- Au cours du projet pilote, aucune relation de confiance ne peut naître entre le client et le datacenter. Et les unités et les spécialistes qui détiennent les données importantes pour l'interprétation sont très probablement inaccessibles pendant le pilote, ainsi que les informations commercialement importantes.
Bien sûr, ces caractéristiques ne se manifestent pas dans tous les projets pilotes, mais elles constituent une part importante de ses risques.
Un peu sur la tâche
Bien avant de se familiariser avec l'apprentissage automatique, Utkonos utilisait déjà son propre système analytique, qui prévoyait le remboursement des marchandises pendant une semaine avec une très grande précision. Cependant, le détaillant est intéressé par la possibilité d'augmenter l'efficacité de la planification. Il s'agissait principalement de produits périssables, dont beaucoup sont également très chers. Fourchette traditionnelle: si vous achetez beaucoup - il y aura des pertes, si vous n'achetez pas assez - l'acheteur ira chez un concurrent pour son filet de veau bien-aimé récolté avec une pleine lune et une pluie légèrement bruine. Pour une prévision suffisamment précise pour après-demain, les solutions basées sur le machine learning sont mieux adaptées, permettant de prendre en compte plus de facteurs que les outils BI classiques. Utkonos a accepté d'être notre partenaire pour une expérience visant à tester les hypothèses d'applicabilité du Machine Learning au commerce électronique.
Pour montrer les possibilités d'apprentissage automatique pour résoudre ce problème, en accord avec l'entreprise, plusieurs noms commerciaux ont été sélectionnés:
- deux produits de la catégorie «Viande réfrigérée» - en tant que produits périssables, dont les données sont les plus importantes à mettre à jour rapidement;
- et deux produits de la catégorie «œuf de poule» - en tant que produits ayant une demande saisonnière spécifique, qui ne peuvent pas être prédits simplement comme «jeudi tout le monde achète X, et vendredi - X multiplie par un facteur». Bien que les œufs de poule ne soient pas difficiles à prédire les saisies et juste pour eux, l'horizon de planification hebdomadaire est tout à fait acceptable, c'est sur ces produits qu'il a fallu montrer que l'apprentissage automatique voit vraiment des relations complexes et construit une prévision non triviale.
Nous avons choisi des produits spécifiques à notre goût, en nous appuyant sur l'exhaustivité des données historiques. Certains produits ont été introduits dans la ligne assez récemment, certains - au contraire, ont été vendus une fois, mais pour le moment ils étaient déjà retirés de l'assortiment, de sorte que la valeur des données les concernant n'était qu'historique.
Les données fournies par Utkonos contenaient des informations sur les ventes de quatre noms de produits au cours des 2 années précédentes et sur la disponibilité de ces produits en stock au cours des périodes concernées. De l'ensemble de données générales, nous avons immédiatement «coupé» les six derniers mois, de début novembre à fin avril - ce sera notre ensemble de test. Il comprenait à la fois des mois d'automne relativement calmes et une série de vacances d'hiver et de vacances de printemps.
Une aventure courte mais passionnante nous attendait.
Les données des entrepôts: mystérieuses et nécessaires
Lorsque vous travaillez avec des données historiques, la première question qui s'est posée à nous était de savoir comment séparer les ventes réelles des «ventes maximales disponibles» (c'est-à-dire les cas où les marchandises se terminant dans l'entrepôt étaient rachetées à 100%, mais si elles étaient disponibles, le volume des ventes pouvait être plus élevé)? Ces désirs non satisfaits des acheteurs ne sont pas affichés dans les données.
Disponibilité des marchandises en stock. Soit dit en passant, d'après l'expérience des projets antérieurs dans le commerce de détail, nous nous attendions à ce qu'il s'agisse de soldes exprimés en unités de mesure. Cependant, dans ce cas, nous avions affaire à l'indicateur relatif «accessibilité», qui était mesuré en pourcentage pendant la journée. Quant à la disponibilité des marchandises dans l'entrepôt, cet indicateur est très relatif: le fait qu'il n'y ait eu aucune marchandise à aucun moment ne signifie pas qu'ils voulaient l'acheter.
Après avoir expérimenté différentes options (reconstruction de la «demande réelle» sur la base de coefficients calculés différemment et filtrage de l'ensemble de données de vente avec différents seuils d'accessibilité), nous avons finalement sélectionné le seuil optimal qui ne rendait pas l'ensemble de données trop étroit. L'idéal - la disponibilité des marchandises tout au long de la journée - a considérablement réduit les données, même pour les produits les plus vendus.
Article 1: viande réfrigérée (volaille inhabituelle)
Nous avons commencé à travailler avec de la viande réfrigérée, car nous ne doutions pas de la capacité prédictive du modèle, dès qu'il était prêt sous forme de projet. (Spoiler: mais en vain - dans l'ensemble de données avec les ventes d'oeufs, une surprise intéressante nous attendait, mais plus à ce sujet plus tard).
Afin de gagner du temps «hors de la boîte», nous avons obtenu une bibliothèque prête à l'emploi qui fonctionne bien avec les séries chronologiques - Prophet de Facebook .

Les résultats du modèle sur les données d'entraînement montrent immédiatement à la fois des avantages et des inconvénients. Le modèle capte bien la saisonnalité de la demande, mais mal. Aussi les vacances câblées par Prophète par défaut. L'écart relatif est de 31,36%, nous continuerons à l'utiliser comme résultat de base.
L'outil de visualisation de saisonnalité intégré, que Prophet voit, vous permet d'obtenir immédiatement un petit aperçu de la façon dont les achats d'un des produits ont changé sur deux ans, de leurs fonctionnalités au cours de l'année et de la semaine:

Notre viande réfrigérée a une nette tendance à la hausse dans le nombre total d'achats, le nombre d'achats augmente du lundi au samedi et baisse le dimanche, en été les achats sont sensiblement «affaissés». Il est mauvais que l'été ne tombe pas dans notre période d'essai; d'autre part, rappelez-vous que la période des vacances et des vacances est importante pour le niveau des ventes, car les vacances d'été sont loin d'être les seules en Russie.
La question logique est: est-il possible d'utiliser ce modèle immédiatement pour faire des prévisions pour les six prochains mois?
Intuitivement, il ne semble pas. L'expérience a montré que c'était le cas. Le schéma général de saisonnalité au cours de la semaine est correct. Mais il est immédiatement devenu évident qu'il y a un million d'écarts par rapport au modèle saisonnier général, à la fois vers le haut et vers le bas, et l'écart moyen de 45,71% est beaucoup plus élevé que les résultats sur les données d'entraînement. Il est clair que ce n'est pas bon.
Pour commencer, essayons de former le modèle quotidiennement, en imaginant que chaque jour après l'achèvement du magasin l'ensemble de données est complété par des ventes pour "aujourd'hui". Nous savons déjà que dans les ventes, il y a une tendance à la hausse en général - il est possible que le chiffre d'affaires sur nos données de test croisse avec une plus grande intensité en raison d'une activité de marketing plus active qu'il ne l'était sur l'ensemble de formation.
Succès relatif: avec un recyclage quotidien du modèle, l'écart relatif est de 33,79%. Nous avons complété les paramètres du modèle avec des informations sur les week-ends reportés, le jeûne religieux et les fêtes traditionnelles pour la Russie (comme le Nouvel An, Pâques et plusieurs autres). Des changements météorologiques soudains ont également été ajoutés: jours où la température a augmenté ou baissé de plus de 10 degrés ou était tout simplement sensiblement plus élevée ou plus basse que les autres jours de ce mois. Maintenant, en moyenne sur six mois, notre prévision s'est écartée des ventes réelles de 28,48%, et en général, le modèle a commencé à mieux prendre en compte les poussées de l'activité des consommateurs. Nous avons amélioré l'écart moyen de 5%! Malgré le fait que Prophet, en principe, fonctionne mal et qu'il est recommandé de les effacer, il s'agissait d'un mouvement vers l'avant notable.


Avant de montrer les résultats préliminaires, la question s'est posée: peut-on améliorer un peu plus les prévisions? Si vous regardez la corrélation des ventes de produits et son prix moyen par jour, il est clair que ce sont des caractéristiques liées et le prix n'est pas pris en compte lors de la construction du modèle. Mais à en juger par l'ensemble de données, nous ne pouvions prendre qu'un certain «prix moyen par unité»: dans les commandes, il variait souvent au cours de la même journée, c'est-à-dire a été enregistré avec une remise personnelle de l'acheteur, et les prix "vitrine" n'étaient pas inclus dans l'ensemble de données.

Le coefficient de corrélation entre le prix moyen unitaire par jour et le nombre de volumes vendus de ce type de viande réfrigérée était de ¬ - 0,61 à p <0,01. Il est clair que le «prix unitaire moyen» n'est pas un indicateur idéal: si, pendant la journée, il y avait beaucoup d'achats auprès, par exemple, de partenaires bénéficiant d'une remise importante constante, un bruit dangereux se glissera dans les données. Mais nous voulions souligner les jours où il y avait des impacts marketing: remises générales sur un groupe de produits, remises pour tous ceux qui introduisent un code promotionnel de distribution gratuite, etc.
Néanmoins, même après que les jours avec le prix moyen dans le quantile de 5% ont été attribués comme jours promotionnels, la précision du modèle n'a pas augmenté. La précision a augmenté les jours de ventes extrêmes et l'écart relatif moyen pendant six mois est resté le même.
Mais l'idée d'une relation statistique prononcée avec le prix a été conservée pour l'avenir.

Nous étions assez satisfaits du résultat préliminaire, il était temps de passer à d'autres produits avant la fin du temps alloué au projet pilote.
Point 2: Oeuf de poulet
Nous avons été immédiatement avertis que les œufs sont l'une des catégories de produits les plus indicatives en termes d'impact des événements externes. Tout d'abord, le volume des achats augmente à Pâques: les œufs sont peints et cuits avec des œufs. Mais plus, bien sûr, est peint. Ceci est facile à comprendre en comparant les ventes d'oeufs blancs et bruns.

En général, notre modèle prévoit une augmentation de la demande à Pâques, mais sa prévision est près de 2 fois inférieure à l'indicateur réel (et cet écart de ~ 100% pendant la semaine de Pâques rend l'écart moyen sur six mois incroyablement important). Pourquoi? Après tout, la semaine de Pâques se déroule chaque année - il doit y avoir un modèle dans les données des 2 années précédentes!
L'analyse de la recherche a montré qu'il n'y a pas de modèle. En 2018 (ce sont nos données de test), le pic des achats tombe toute la semaine avant Pâques jusqu'au 7 avril. À Pâques même (8 avril 2018), les achats d'œufs tombent toujours, ce que le modèle voit correctement. Mais en 2017, Pâques tombe le 16 avril, et le pic des achats dans les données historiques est le 8 avril, et cette année, le pic est d'un jour. En 2016, Pâques tombe le 1er mai. Le pic des achats est le 29 avril, avec des hausses la veille et le lendemain. En 2015, Pâques tombe le 12 avril, le pic des achats est à nouveau un jour, le 9 avril.

Notre première version a été l'influence des jours de la semaine (et l'imagination a peint les parents qui, d'ici demain, ont besoin de peindre une douzaine d'œufs, car la leçon thématique, et l'enfant l'a dit aujourd'hui). Hélas, ce n'est pas le cas. Probablement, pendant Pâques, il y a certains facteurs que nous n'avons pas encore trouvés (et que nous n'avons pas pris en compte) - à la fois externes et liés à la commercialisation de l'entreprise elle-même.
On peut faire mieux!
Cette histoire concerne le travail avec les données des détaillants pendant un temps limité, et non les techniques secrètes d'apprentissage automatique. Mais en travaillant avec des données, il est possible d'améliorer le résultat.
Après avoir travaillé avec des produits de la catégorie «œuf de poule», il est devenu clair que le modèle peut être amélioré en ajoutant des facteurs que nous n'avons pas utilisés dans le projet pilote. Par conséquent, il a été décidé de mener une petite expérience avec une forêt aléatoire et des données que nous pouvons collecter à partir de sources ouvertes. De plus, nous serons en mesure de voir comment le modèle se comporte, où les jours de vente auront un ensemble diversifié de signes, et pas seulement un ensemble de «jours spéciaux» attribués sur l'une ou l'autre base.
Les informations suivantes ont été collectées dans l'ensemble de données sur le «monde extérieur»:
- un calendrier de production complet pour chaque année;
- fonctions et fêtes religieuses, fêtes profanes;
- les conditions météorologiques et leurs écarts par rapport aux valeurs moyennes d'un mois dans la région, ainsi que les fluctuations au cours du dernier mois, jour et semaine;
- les taux de change du dollar et de l'euro pour la Banque centrale et leurs fluctuations en tant qu'indicateurs de la situation économique générale.
Séparément, des panneaux ont été ajoutés pour mener des campagnes de marketing distinctes et le prix unitaire des marchandises.
Sur l'ensemble de données étendu, nous avons à nouveau construit un modèle qui s'est entraîné quotidiennement sur de nouvelles données, en utilisant maintenant RandomForestRegressor. L'écart relatif s'est légèrement amélioré: à 27,29%. Le graphique montre que le nouveau modèle prédit mieux l'impact des campagnes marketing, mais pire - la saisonnalité hebdomadaire.

En regardant les 5 principaux signes les plus importants du point de vue du RandomForestRegressor utilisé, vous pouvez vous assurer qu'il existe déjà deux signes liés à la valeur des marchandises - le prix actuel et ses variations par rapport au mois dernier. De toute évidence, le fait que la fourchette de prix ne pouvait pas être bien définie dans le FB Prophet a affecté sa précision.
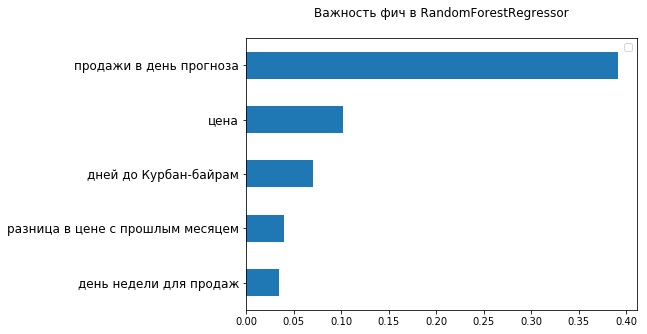
En vérifiant si nous pouvons réfléchir un peu plus et améliorer le résultat, l'étude pilote a été achevée. Les principaux objectifs ont été atteints: nous avons montré que l'apprentissage automatique est en principe applicable aux données des détaillants et donne de bons résultats même en mode «démarrage rapide».
Alexandra Tsareva, spécialiste, analyse intelligente, Jet Infosystems