Toute opération avec des données volumineuses nécessite beaucoup de puissance de calcul. Un transfert typique de données d'une base de données vers Hadoop peut prendre des semaines ou coûter autant qu'une aile d'avion. Vous ne voulez pas attendre et faire des folies? Équilibrez la charge sur différentes plates-formes. Une façon est l'optimisation du refoulement.
J'ai demandé à Alexei Ananyev, le principal formateur russe pour le développement et l'administration des produits Informatica, de parler de la fonction d'optimisation du refoulement dans Informatica Big Data Management (BDM). Avez-vous déjà appris à travailler avec les produits Informatica? Très probablement, c'est Alex qui vous a expliqué les bases de PowerCenter et expliqué comment créer des mappages.
Alexey Ananiev, responsable de la formation au groupe DIS
Qu'est-ce que le pushdown?
Beaucoup d'entre vous connaissent déjà Informatica Big Data Management (BDM). Le produit peut intégrer des données volumineuses de différentes sources, les déplacer entre différents systèmes, leur fournir un accès facile, vous permettre de les profiler et bien plus encore.
Entre des mains habiles, BDM peut faire des merveilles: les tâches seront exécutées rapidement et avec un minimum de ressources informatiques.
Tu le veux aussi? Découvrez comment utiliser la fonction déroulante de BDM pour répartir la charge de calcul entre les plates-formes. La technologie Pushdown vous permet de transformer le mappage en script et de choisir l'environnement dans lequel ce script s'exécutera. La possibilité d'un tel choix vous permet de combiner les atouts de différentes plateformes et d'atteindre leurs performances maximales.
Pour configurer l'exécution du script, sélectionnez le type de liste déroulante. Le script peut être entièrement exécuté sur Hadoop ou partiellement distribué entre la source et le récepteur. Il existe 4 types de pushdown possibles. Le mappage ne peut pas être transformé en script (natif). Le mappage peut être effectué autant que possible à la source (source) ou complètement à la source (complète). Le mappage peut également être transformé en script Hadoop (aucun).
Optimisation du refoulement
Les 4 types listés peuvent être combinés de différentes manières - optimisez le pushdown pour les besoins spécifiques du système. Par exemple, il est souvent plus judicieux d'extraire des données d'une base de données en utilisant ses propres capacités. Et pour transformer les données - par Hadoop, afin que la base de données elle-même ne soit pas surchargée.
Examinons le cas lorsque la source et le récepteur sont dans la base de données et que la plate-forme d'exécution de la transformation peut être sélectionnée: selon les paramètres, ce sera Informatica, un serveur de base de données ou Hadoop. Un tel exemple permettra de comprendre le plus précisément le côté technique de ce mécanisme. Naturellement, dans la vraie vie, cette situation ne se produit pas, mais elle est la mieux adaptée pour démontrer la fonctionnalité.
Prenez le mappage pour lire deux tables dans une seule base de données Oracle. Et laissez les résultats de lecture être écrits dans une table de la même base de données. Le schéma de mappage sera le suivant:

Sous la forme d'un mappage sur Informatica BDM 10.2.1, cela ressemble à ceci:
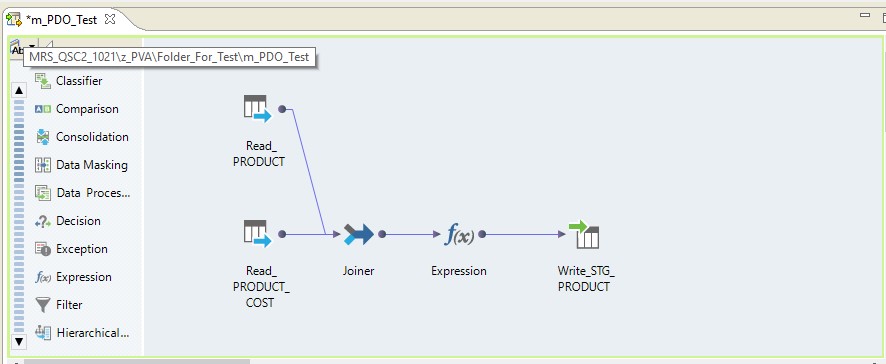
Type de liste déroulante - natif
Si nous sélectionnons le type natif pushdown, le mappage sera effectué sur le serveur Informatica. Les données seront lues à partir du serveur Oracle, transférées vers le serveur Informatica, transformées à cet endroit et transférées vers Hadoop. En d'autres termes, nous obtenons un processus ETL régulier.
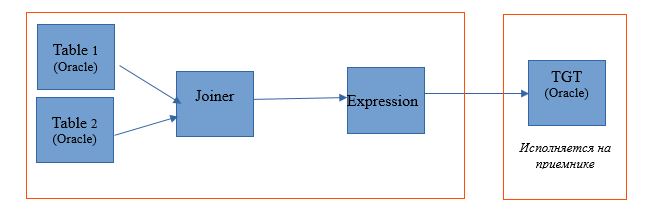
Type de liste déroulante - source
Lors du choix du type de source, nous avons la possibilité de répartir notre processus entre le serveur de base de données (DB) et Hadoop. Lors de l'exécution d'un processus avec ce paramètre, les demandes de sélection de données à partir des tables volent vers la base de données. Et le reste se fera sous forme d'étapes sur Hadoop.
Le schéma d'exécution ressemblera à ceci:
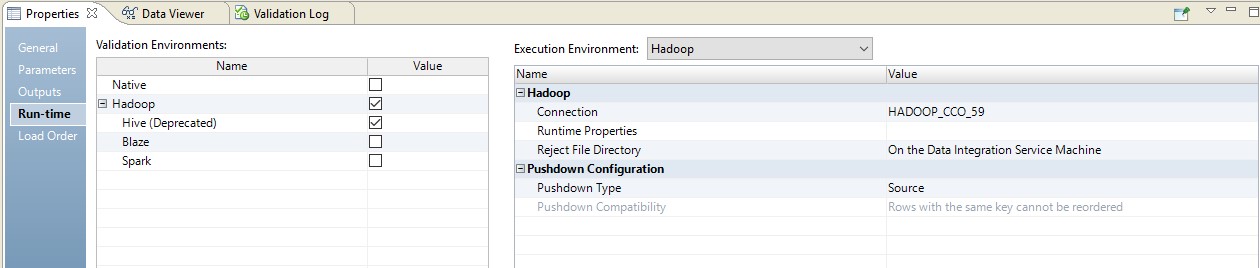
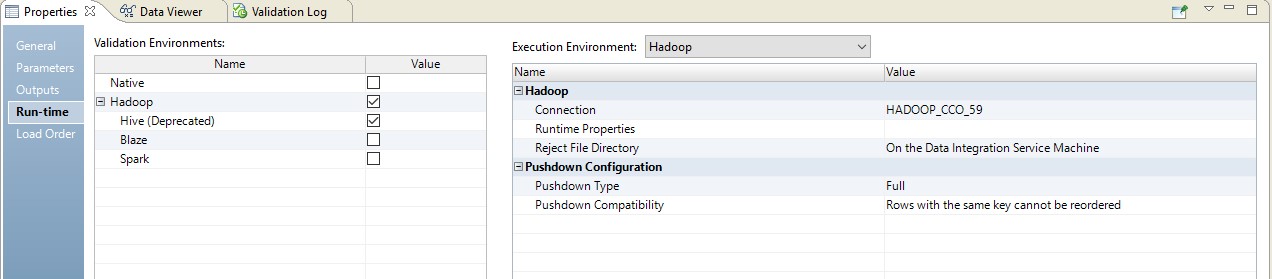
Vous trouverez ci-dessous un exemple de configuration du runtime.
Dans ce cas, le mappage sera effectué en deux étapes. Dans ses paramètres, nous verrons qu'il s'est transformé en un script qui sera envoyé à la source. De plus, la combinaison des tables et de la conversion des données sera effectuée sous la forme d'une requête remplacée à la source.
Dans l'image ci-dessous, nous voyons un mappage optimisé sur BDM et sur la source - une demande remplacée.
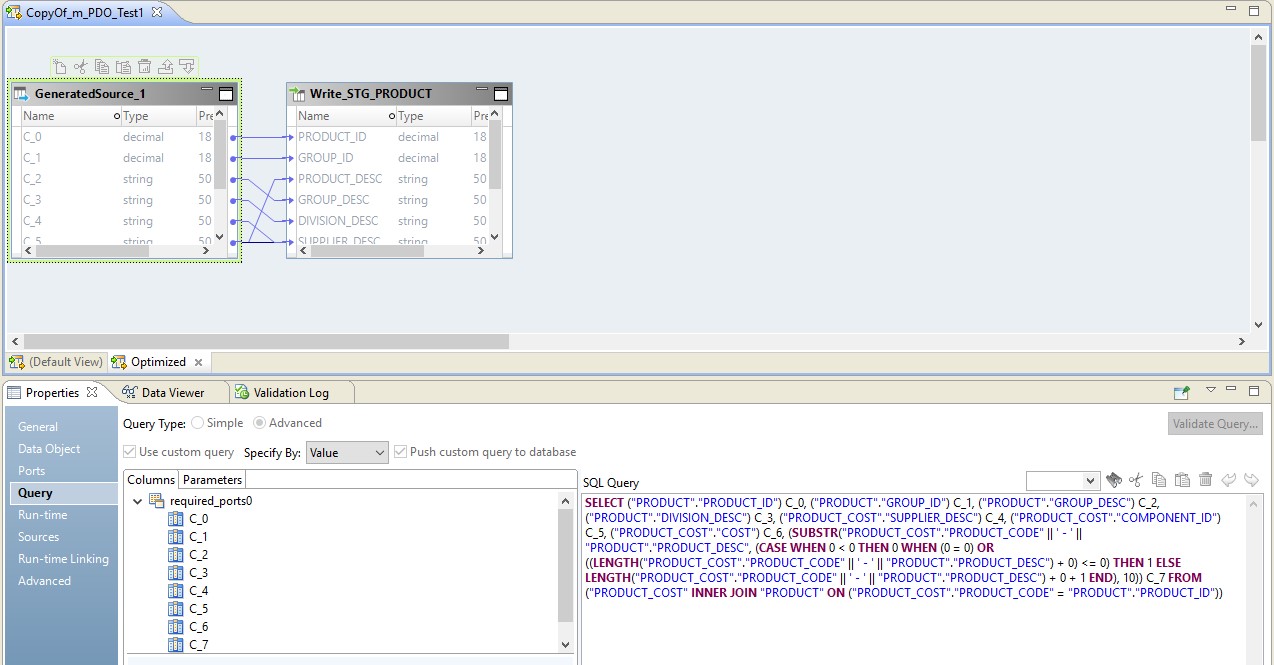
Le rôle d'Hadoop dans cette configuration se résume à gérer le flux de données - à le conduire. Le résultat de la demande sera envoyé à Hadoop. Après lecture, le fichier de Hadoop sera écrit sur le récepteur.
Type pushdown - complet
Lorsque vous choisissez le type complet, le mappage se transformera complètement en une demande de base de données. Et le résultat de la requête sera dirigé vers Hadoop. Un schéma d'un tel processus est présenté ci-dessous.
Un exemple de configuration est illustré ci-dessous.
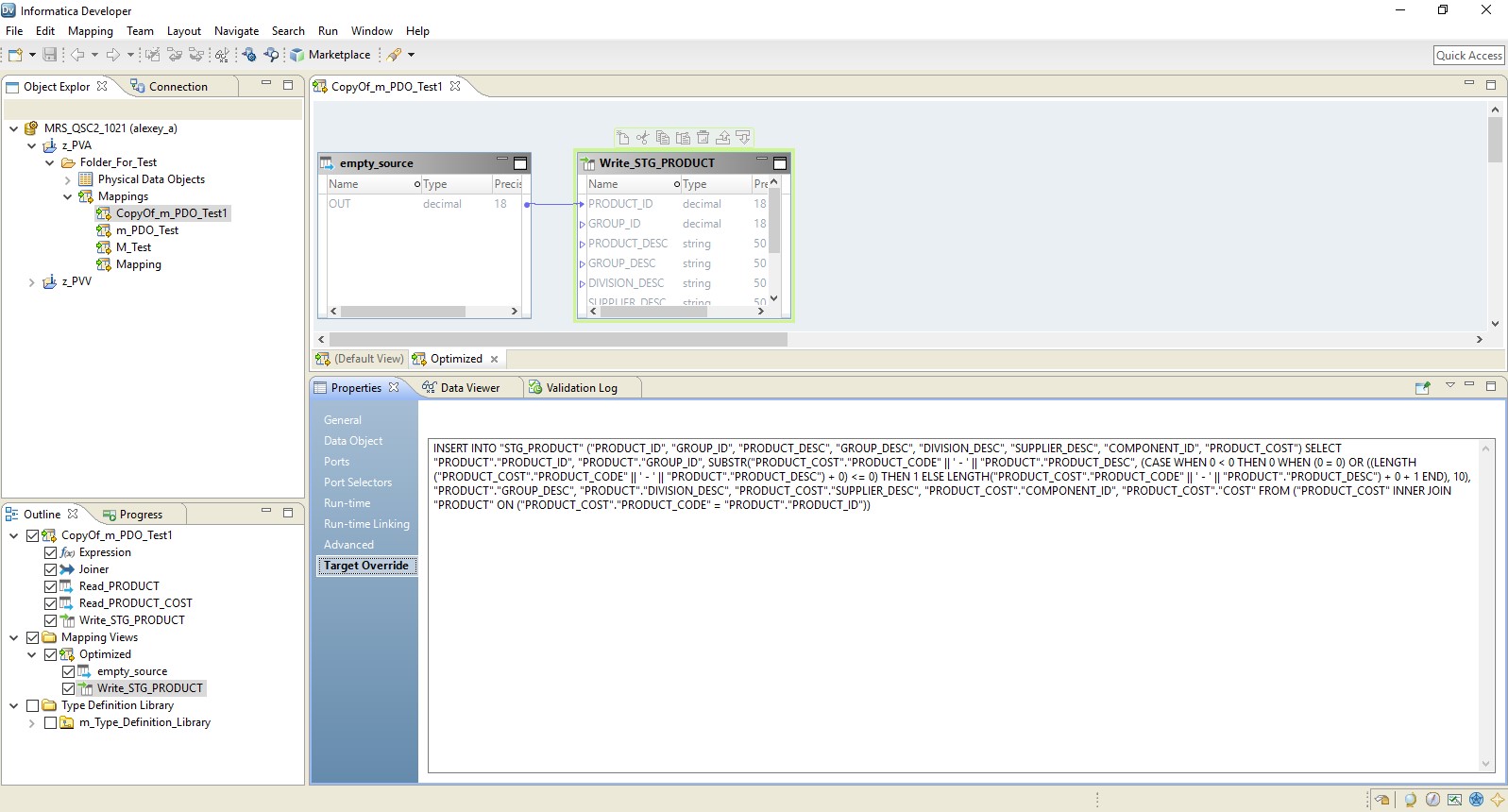
En conséquence, nous obtenons une cartographie optimisée similaire à la précédente. La seule différence est que toute la logique est transférée au récepteur sous la forme d'un remplacement de son insertion. Un exemple de cartographie optimisée est présenté ci-dessous.
Ici, comme dans le cas précédent, Hadoop agit comme chef d'orchestre. Mais ici, la source est lue dans son intégralité, puis au niveau du récepteur, la logique de traitement des données est exécutée.
Type de liste déroulante - null
Eh bien, la dernière option est le type pushdown, dans lequel notre mappage se transformera en script Hadoop.
Le mappage optimisé ressemblera maintenant à ceci:
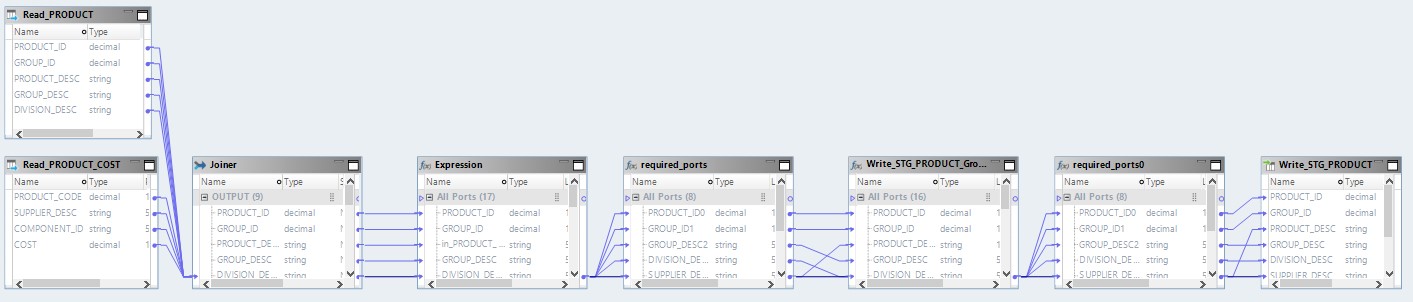
Ici, les données des fichiers source seront d'abord lues sur Hadoop. Ensuite, par ses propres moyens, ces deux fichiers seront combinés. Après cela, les données seront converties et téléchargées dans la base de données.
En comprenant les principes de l'optimisation du refoulement, vous pouvez organiser très efficacement de nombreux processus pour travailler avec le Big Data. Ainsi, tout récemment, une grande entreprise a transféré en quelques semaines de grandes données du stockage vers Hadoop, qu'elle avait collectées plusieurs années auparavant.